













Le architetture moderne native del cloud richiedono soluzioni di elaborazione dei log robuste, scalabili e sicure per monitorare le applicazioni distribuite. Questo studio presenta una soluzione ibrida per la raccolta, l’aggregazione e l’analisi dei log utilizzando Azure Kubernetes Service (AKS) per la generazione dei log, Fluent Bit per la raccolta dei log, Azure EventHub per l’aggregazione intermedia e Splunk distribuito su un cluster Apache CloudStack on-premises per l’indicizzazione e la visualizzazione completa dei log.
Dettagliamo il design, l’implementazione e la valutazione del sistema, dimostrando come questa architettura supporti un’elaborazione dei log affidabile e scalabile per i carichi di lavoro nativi del cloud mantenendo il controllo sui dati on-premises.
Introduzione
Le soluzioni di logging centralizzato sono diventate indispensabili. Le applicazioni moderne, in particolare quelle costruite su architetture a microservizi, generano enormi quantità di log, spesso in formati diversi e da molteplici fonti. Questi log sono la fonte chiave per monitorare le prestazioni delle applicazioni, diagnosticare problemi e garantire l’affidabilità complessiva del sistema. Tuttavia, gestire volumi così elevati di dati di log presenta sfide significative, specialmente in ambienti di cloud ibrido che spaziano tra infrastrutture on-premises e basate su cloud.
Le soluzioni di logging tradizionali, sebbene efficaci per le applicazioni monolitiche, faticano a scalare di fronte alle esigenze delle architetture basate su microservizi. La natura dinamica dei microservizi, caratterizzata da distribuzioni indipendenti e aggiornamenti frequenti, produce un flusso continuo di log, ciascuno con formati e strutture variabili. Questi log devono essere inglobati, elaborati e analizzati in tempo reale per fornire insight utili. Inoltre, poiché le applicazioni operano sempre più in ambienti ibridi, garantire la sicurezza e la protezione dei dati PII diventa primario, date le varie normative e requisiti normativi.
Questo documento introduce una soluzione completa che affronta queste sfide sfruttando le capacità combinate di Azure e delle risorse di Apache CloudStack. Integrando la scalabilità e le capacità analitiche di Azure con la flessibilità e la convenienza infrastrutturale on-premises di CloudStack, questa soluzione offre un approccio unificato e robusto al logging centralizzato.
Revisione della letteratura
La raccolta centralizzata dei log nei microservizi affronta sfide come la latenza di rete, formati dati diversi e sicurezza attraverso strati multipli. Sebbene agenti leggeri come Fluent Bit e FluentD siano ampiamente utilizzati, il trasporto efficiente dei log rimane una sfida.
Soluzioni come lo stack ELK e Azure Monitor offrono l’elaborazione centralizzata dei log ma tipicamente coinvolgono implementazioni solo cloud o solo in locale, limitando la flessibilità nelle distribuzioni ibride. Le soluzioni cloud ibride consentono alle organizzazioni di sfruttare la scalabilità del cloud mantenendo il controllo sui dati sensibili negli ambienti in locale. I flussi di elaborazione dei log ibridi, specialmente quelli che utilizzano tecnologie di streaming di eventi, affrontano la necessità di trasporto e aggregazione scalabili dei log.
Architettura di Sistema
L’architettura, illustrata di seguito, integra Azure EventHub e AKS con Apache CloudStack e Splunk in locale. Ogni componente è ottimizzato per un’elaborazione efficiente dei log e un trasferimento sicuro dei dati attraverso gli ambienti.
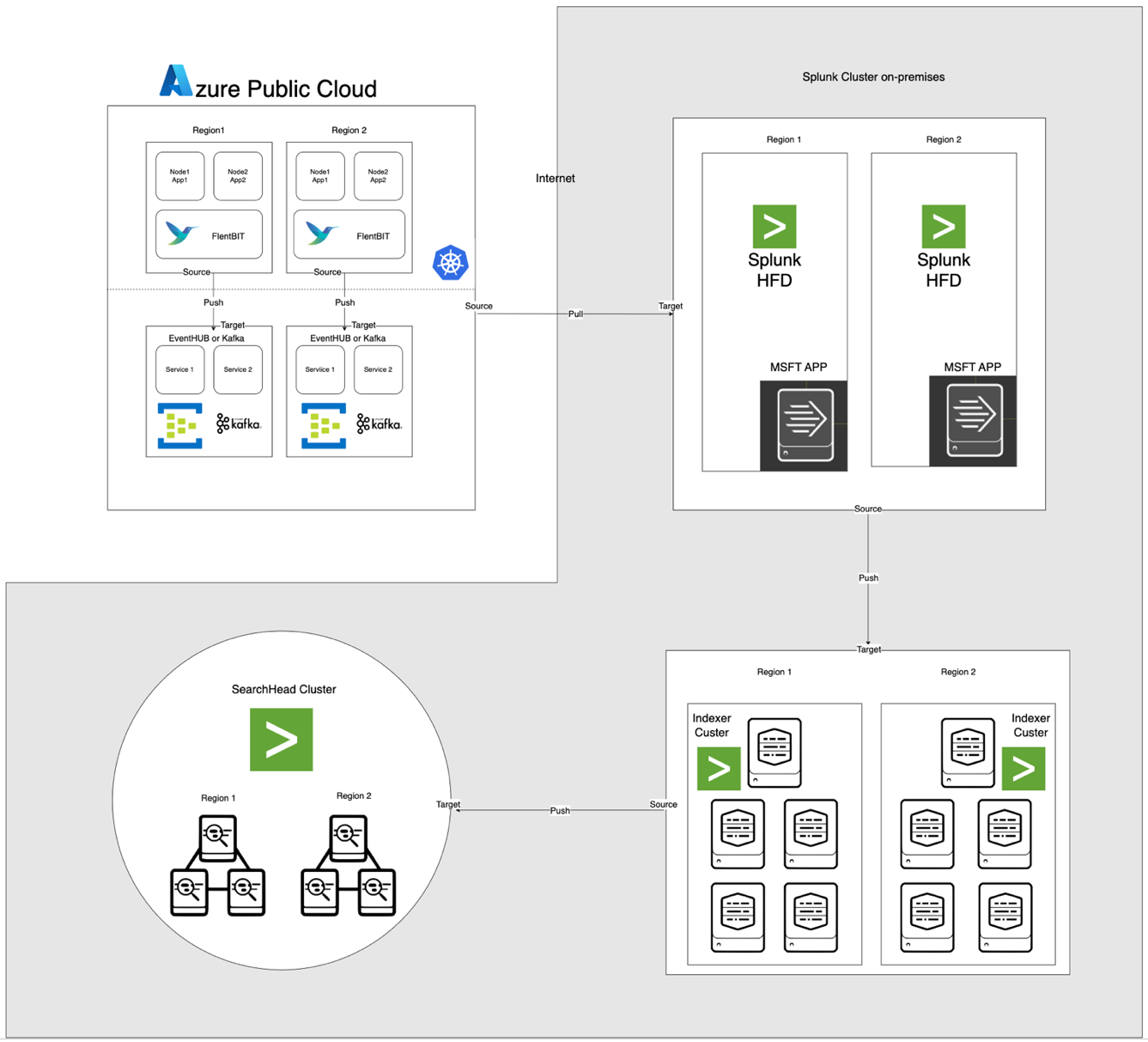
Descrizioni dei Componenti
- AKS: Ospita applicazioni in contenitori e genera log accessibili attraverso il livello di aggregazione dei log di Kubernetes.
- Fluent Bit: Implementato come DaemonSet, raccoglie i log dai nodi AKS. Ogni istanza di Fluent Bit cattura i log da /var/log/containers, li filtra e li inoltra in formato JSON ad EventHub.
- Azure EventHub: Serve come un broker di messaggi ad alta capacità, aggregando i log da Fluent Bit e memorizzandoli temporaneamente fino a quando non vengono recuperati dal Splunk Heavy Forwarder.
- Apache Kafka: Funge da ponte affidabile tra Fluent Bit e Splunk. Fluent Bit inoltra i log a Kafka utilizzando il suo plugin di output Kafka, dove i log sono archiviati e elaborati temporaneamente. Splunk quindi consuma i log da Kafka utilizzando connettori come il Sink Splunk di Kafka Connect o script personalizzati, garantendo un’architettura scalabile e disaccoppiata.
- Splunk Heavy Forwarder (HF): Installato in Apache CloudStack, l’Heavy Forwarder recupera i log da Azure EventHub utilizzando l’Add-on Splunk per i Servizi Cloud di Microsoft. Questo add-on fornisce un’integrazione senza soluzione di continuità, consentendo all’Heavy Forwarder di connettersi in modo sicuro a EventHub, recuperare i log in quasi tempo reale e trasformarli come necessario prima di inoltrarli all’indicizzatore di Splunk per l’archiviazione e l’elaborazione
- Splunk su Apache CloudStack: Fornisce indicizzazione dei log, ricerca, visualizzazione e allerta
Flusso dei dati
- Raccolta log in AKS: Fluent Bit monitora i file di log in /var/log/containers, filtrando i log non necessari e contrassegnando ciascun log con metadati (ad esempio, nome del contenitore, namespace)
- Inoltro a EventHub: I log vengono inviati a EventHub tramite HTTPS utilizzando il plugin di output azure_eventhub di Fluent Bit, garantendo una trasmissione sicura dei dati.
- Apache Kafka: I log di AKS vengono raccolti da Fluent Bit, in esecuzione come DaemonSet, che li analizza e li inoltra ad Apache Kafka tramite il suo plugin di output Kafka. Kafka funge da buffer ad alta capacità, memorizzando e partizionando i log per la scalabilità. Splunk ingesta questi log da Kafka utilizzando connettori o script, consentendo l’indicizzazione, l’analisi e il monitoraggio in tempo reale.
- Recupero log con Splunk Heavy Forwarder: L’Heavy Forwarder in Apache CloudStack si connette a EventHub utilizzando l’SDK di EventHubs e recupera i log, inoltrandoli all’indicizzatore Splunk locale per memorizzazione e elaborazione.
- Memorizzazione e analisi in Splunk: I log vengono indicizzati in Splunk, consentendo ricerche in tempo reale, visualizzazioni dashboard e avvisi basati sui pattern dei log.
Metodologia
Deploy del Fluent Bit DaemonSet in AKS
La configurazione di Fluent Bit è memorizzata in un ConfigMap e distribuita come DaemonSet. Di seguito è riportata la configurazione espansa per il Fluent Bit DaemonSet:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations:
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- Convalida del record in ingresso
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- Generare una chiave univoca per il riassemblaggio basata su stream e tag
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- Gestire frammenti di log (logtag == 'P')
if record.logtag == 'P' then
-- Memorizzare il frammento nello stato di riassemblaggio
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- Gestire la fine di un log frammentato
if reassemble_state[reassemble_key] then
-- Combinare i frammenti memorizzati con il log corrente
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- Cancella lo stato memorizzato per questa chiave
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- Se non è necessario alcun riassemblaggio, inoltrare il log così com'è
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(? - [INPUT] sezione specifica la raccolta dei log dalla directory /var/log/containers.
- [FILTER] sezione arricchisce i log con i metadati di Kubernetes.
- [OUTPUT] sezione configura Fluent Bit per inoltrare i log a EventHub in formato JSON.
Configurazione Azure EventHub
EventHub richiede un namespace, un’istanza specifica di EventHub e il controllo degli accessi tramite criteri di accesso condiviso.
- Configurazione del namespace e di EventHub: Crea un namespace e un’istanza di EventHub in Azure, imposta una policy di invio e recupera la stringa di connessione.
- Configurazione per elevate prestazioni: EventHub è configurato con un alto conteggio di partizioni per supportare la scalabilità, il buffering e i flussi di dati simultanei da Fluent Bit.
Configurazione di Splunk Heavy Forwarder in Apache CloudStack
Splunk Heavy Forwarder recupera i log da EventHub e li inoltra all’indicizzatore di Splunk.
- Complemento per i Servizi Cloud Microsoft: Installa il complemento per abilitare la connettività con EventHub. Configura l’input in
inputs.conf:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- Elaborazione batch: Imposta batch_size su 500 e interval su 30 secondi per ottimizzare l’ingestione dei dati e ridurre la frequenza delle chiamate di rete.
Indicizzazione e Visualizzazione di Splunk
- Arricchimento dei dati: I log vengono arricchiti con metadati aggiuntivi in Splunk utilizzando estrazioni di campi.
- Ricerche e dashboard: Le query SPL consentono ricerche in tempo reale, e le dashboard personalizzate forniscono la visualizzazione dei modelli di log.
- Allerta: Le notifiche sono configurate per attivarsi su modelli di log specifici, come elevati tassi di errore o avvertimenti ripetuti da contenitori specifici.
Performance e Scalabilità
I test mostrano che il sistema può gestire l’ingestione di log ad alto throughput, con le capacità di buffering di EventHub che impediscono la perdita di dati durante interruzioni di rete. L’utilizzo delle risorse di Fluent Bit sui nodi AKS rimane minimo, e l’indicizzazione efficiente del volume dei log da parte dell’indicizzatore di Splunk avviene con configurazioni adeguate di indicizzazione e filtraggio.
Sicurezza
HTTPS viene utilizzato per garantire la comunicazione tra AKS ed EventHub, mentre Splunk HF utilizza chiavi sicure per autenticarsi con EventHub. Ogni componente nel flusso implementa meccanismi di riprova per mantenere l’integrità dei dati.
Utilizzo delle Risorse
- Fluent Bit ha in media 100-150 MiB di memoria e 0,2-0,3 CPU sui nodi AKS.
- L’utilizzo delle risorse di EventHub viene regolato dinamicamente in base alle configurazioni di partizione e throughput.
- Il carico di Splunk HF è bilanciato tramite l’elaborazione batch, ottimizzando il trasferimento dei dati senza sovraccaricare le risorse di Apache CloudStack.
Affidabilità e Tolleranza ai Guasti
La soluzione utilizza il buffering di EventHub per garantire la conservazione dei log in caso di guasti a valle. EventHub supporta anche le politiche di riprova, migliorando ulteriormente l’integrità e l’affidabilità dei dati.
Discussione
Vantaggi dell’Architettura Cloud Ibrida
Questa architettura fornisce flessibilità, scalabilità e sicurezza combinando i servizi Azure con il controllo in loco. Sfrutta anche le capacità di streaming e buffering basate su cloud senza compromettere la sovranità dei dati.
Limitazioni
Anche se EventHub offre un’aggregazione affidabile dei dati, i costi aumentano con le unità di throughput, rendendo essenziale ottimizzare le configurazioni di inoltro dei log. Inoltre, il trasferimento dati tra ambienti cloud e in loco introduce potenziali latenze.
Applicazioni Future
Questa architettura potrebbe essere estesa integrando l’apprendimento automatico per il rilevamento delle anomalie nei log o aggiungendo il supporto per più fornitori di cloud per ulteriori scalabilità nell’elaborazione dei log e nella resilienza multi-cloud.
Conclusione
Questo studio dimostra l’efficacia di un pipeline di elaborazione dei log ibrida che sfrutta risorse cloud e in loco. Integrando Azure Kubernetes Service (AKS), Azure EventHub e Splunk su Apache CloudStack, creiamo una soluzione scalabile e resiliente per la gestione e l’analisi centralizzata dei log. L’architettura affronta le sfide chiave nel logging distribuito, incluse l’alta velocità di trasferimento dei dati, la sicurezza e la tolleranza ai guasti.
L’uso di Fluent Bit come leggero raccoglitore di log in AKS garantisce un’efficace raccolta dati con un minimo sovraccarico delle risorse. Le capacità di buffering di Azure EventHub consentono un’affidabile aggregazione dei log e uno storage temporaneo, rendendolo adatto a gestire il traffico variabile dei log e mantenere l’integrità dei dati in caso di problemi di connettività. Il Splunk Heavy Forwarder e il deployment di Splunk in Apache CloudStack permettono alle organizzazioni di mantenere il controllo sullo storage e sull’analisi dei log, beneficiando della scalabilità e flessibilità delle risorse cloud.
Questo approccio offre significativi vantaggi per le organizzazioni che richiedono un setup di cloud ibrido, come un maggiore controllo sui dati, il rispetto dei requisiti di residenza dei dati e la flessibilità di scalare in base alla domanda. Lavori futuri potranno esplorare l’integrazione del machine learning per potenziare l’analisi dei log, il rilevamento automatico delle anomalie e l’espansione verso un setup multi-cloud per aumentare la resilienza e la versatilità. Questa ricerca fornisce un’architettura fondamentale adattabile alle esigenze in evoluzione dei moderni sistemi distribuiti negli ambienti aziendali.
Riferimenti
Azure Event Hubs e Kafka
Monitoraggio e Logging Ibridi
- Modelli di monitoraggio ibrido e multi-cloud
- Strategie di monitoraggio del cloud ibrido
Integrazione di Splunk
- Invio di Azure Event Hubs a Splunk
- Dati di Azure nella piattaforma Splunk
Implementazione di AKS
Source:
https://dzone.com/articles/bridging-cloud-and-on-premises-log-processing