













Nota dell’editore: Di seguito è riportato un articolo scritto e pubblicato nel Rapporto Trend 2024 di DZone, Ingegneria dei Dati: Arricchire i Flussi di Dati, Espandere l’IA e Accelerare l’Analisi.
L’articolo esplora le strategie essenziali per sfruttare lo streaming dei dati in tempo reale per guidare insight azionabili, mentre protegge i sistemi per il futuro attraverso l’automazione dell’IA e i database vettoriali. Esso approfondisce le architetture e gli strumenti in evoluzione che consentono alle aziende di rimanere agili e competitive in un mondo guidato dai dati.
Streaming dei Dati in Tempo Reale: L’Evoluzione e le Considerazioni Chiave
Lo streaming dei dati in tempo reale è evoluto dal tradizionale processo batch, dove i dati venivano elaborati in intervalli che introducevano ritardi, a un sistema che gestisce continuamente i dati man mano che vengono generati, permettendo risposte immediate a eventi critici. Integrando l’IA, l’automazione e i database vettoriali, le aziende possono ulteriormente migliorare le loro capacità, utilizzando insight in tempo reale per prevedere esiti, ottimizzare le operazioni e gestire efficientemente dataset di grandi dimensioni e complessi.
Necessità dello Streaming in Tempo Reale
C’è la necessità di agire sui dati non appena vengono generati, in particolare in scenari come la rilevazione di frodi, l’analisi dei log o il monitoraggio del comportamento dei clienti. Lo streaming in tempo reale permette alle organizzazioni di catturare, processare e analizzare i dati istantaneamente, permettendo loro di reagire rapidamente a eventi dinamici, ottimizzare la prendere decisioni e migliorare le esperienze dei clienti in tempo reale.
Sorgenti di Dati in Tempo Reale
I dati in tempo reale originano da vari sistemi e dispositivi che generano continuamente dati, spesso in grandi quantità e in formati che possono essere complessi da processare. Le sorgenti di dati in tempo reale spesso includono:
- dispositivi IoT e sensori
- log dei server
- attività delle app
- publicità online
- eventi di modifica del database
- flussi di clic sul sito web
- piattaforme di social media
- database transazionali
Gestire e analizzare efficacemente questi flussi di dati richiede un’infrastruttura robusta in grado di gestire dati non strutturati e semi-strutturati; questo permette alle aziende di estrarre preziose informazioni e prendere decisioni in tempo reale.
Sfide Critiche nelle Pipeline di Dati Moderni
Le moderne pipeline di dati affrontano diverse sfide, tra cui mantenere la qualità dei dati, garantire trasformazioni accurate e minimizzare i tempi di inattività della pipeline:
- La scarsa qualità dei dati può portare a insight errati.
- Le trasformazioni dei dati sono complesse e richiedono scripting precisa.
- Frequente downtime interrompe le operazioni, rendendo i sistemi fault-tolerant essenziali.
Inoltre, governance dei dati è cruciale per garantire coerenza dei dati e affidabilità attraverso i processi. Scalabilità è un altro problema chiave poiché i pipeline devono gestire volumi di dati fluttuanti, e un corretto monitoraggio e alerting sono vitali per evitare guasti imprevisti e garantire un’operazione fluida.
Advanced Real-Time Data Streaming Architectures and Applications Scenarios
Questa sezione dimostra le capacità dei moderni sistemi di dati di processare e analizzare dati in movimento, fornendo alle organizzazioni gli strumenti per rispondere a eventi dinamici in millisecondi.
Passaggi per Costruire un Pipeline di Dati in Tempo Reale
Per creare un pipeline di dati in tempo reale efficace, è essenziale seguire una serie di passaggi strutturati che garantiscono un flusso fluido di dati, processing e scalabilità. Tabella 1, condivisa di seguito, outlines i passaggi chiave coinvolti nella costruzione di un pipeline di dati in tempo reale robusto:
Tabella 1. Passaggi per costruire un pipeline di dati in tempo reale
| step | activities performed |
|---|---|
| 1. Ingestione dei dati | Configura un sistema per catturare flussi di dati da diverse fonti in tempo reale |
| 2. Processing dei dati | Pulisci, convalida e trasforma i dati per garantire che siano pronti per l’analisi |
| 3. Processing in streaming | Configura i consumatori per estrarre, processare e analizzare i dati continuamente |
| 4. Storage | Archivia i dati processati in un formato adatto per l’uso a valle |
| 5. Monitoraggio e scalabilità | Implementare strumenti per monitorare le prestazioni del pipeline e assicurarsi che possa scalare con l’aumentare delle richieste di dati |
Strumenti di streaming open-source di punta
Per costruire pipeline di dati in tempo reale robusti, sono disponibili diversi strumenti open-source di punta per l’ingestione, la memorizzazione, l’elaborazione e l’analisi dei dati, ognuno dei quali gioca un ruolo cruciale nella gestione eel’elaborazione di flussi di dati su larga scala.
Strumenti open-source per l’ingestione dei dati:
- Apache NiFi, con la sua ultima versione 2.0.0-M3, offre una maggiore scalabilità e capacità dielaborazione in tempo reale.
- Apache Airflow viene utilizzato per orchestrare flussi di lavoro complessi.
- Apache StreamSets fornisce un monitoraggio eel’elaborazione continua del flusso di dati.
- Airbyte semplifica l’estrazione e il caricamento dei dati, rendendolo una scelta forte per gestire diverse esigenze di ingestione dei dati.
Strumenti open-source per la memorizzazione dei dati:
- Apache Kafka è ampiamente utilizzato per costruire pipeline in tempo reale e applicazioni di streaming grazie alla sua alta scalabilità, tolleranza ai guasti e velocità.
- Apache Pulsar, un sistema di messaggistica distribuita, offre una forte scalabilità e durabilità, rendendolo ideale per gestire messaggistica su larga scala.
- NATS.io è un sistema di messaggistica ad alte prestazioni, comunemente utilizzato in applicazioni IoT e cloud-native, progettato per architetture microservices e offre comunicazione leggera e veloce per esigenze di dati in tempo reale.
- Apache HBase, un database distribuito costruito sopra HDFS, fornisce una forte coerenza e un alto throughput, rendendolo ideale per memorizzare grandi quantità di dati in tempo reale in un ambiente NoSQL.
Strumenti open-source per l’elaborazione dei dati:
- Apache Spark si distingue per il suo calcolo in memoria cluster, fornendo un’elaborazione rapida sia per applicazioni batch che streaming.
- Apache Flink è progettato per l’elaborazione distribuita di stream ad alte prestazioni e supporta i lavori batch.
- Apache Storm è noto per la sua capacità di processare più di un milione di record al secondo, rendendolo estremamente veloce e scalabile.
- Apache Apex offre un’unica elaborazione di flussi e batch.
- Apache Beam fornisce un modello flessibile che lavora con più motori di esecuzione come Spark e Flink.
- Apache Samza, sviluppato da LinkedIn, si integra bene con Kafka e gestisce la gestione dei flussi con un focus sulla scalabilità e la tolleranza ai guasti.
- Heron, sviluppato da Twitter, è una piattaforma di analisi in tempo reale altamente compatibile con Storm ma offre prestazioni migliori e isolamento delle risorse, rendendolo adatto per l’elaborazione dei flussi ad alta velocità su larga scala.
Strumenti open-source per l’analisi dei dati:
- Apache Kafka permette un’elaborazione ad alta capacità e bassa latenza di flussi di dati in tempo reale.
- Apache Flink offre una potente elaborazione dei flussi, ideale per applicazioni che richiedono computazioni distribuite e con stato.
- Apache Spark Streaming integrato con l’ecosistema più ampio di Spark gestisce dati in tempo reale e in batch sulla stessa piattaforma.
- Apache Druid e Pinot fungono da database analitici in tempo reale, offrendo capacità OLAP che consentono di eseguire query su grandi set di dati in tempo reale, rendendoli particolarmente utili per dashboard e applicazioni di business intelligence.
Casi di Implementazione
Le implementazioni reali di pipeline di dati in tempo reale mostrano le diverse modalità con cui queste architetture alimentano applicazioni critiche in vari settori, migliorando le prestazioni, la prendere decisioni e l’efficienza operativa.
Stream di Dati di Mercato Finanziario per Sistemi di Trading ad Alta Frequenza
Negli sistemi di trading ad alta frequenza, dove i millisecondi possono fare la differenza tra profitto e perdita, Apache Kafka o Apache Pulsar vengono utilizzati per l’ingestione di dati ad alta attraverso. Apache Flink o Apache Storm gestiscono il processing a bassa latenza per garantire che le decisioni di trading vengano prese istantaneamente. Questi pipeline devono supportare una scalabilità estrema e una tolleranza ai guasti, poiché qualsiasi interruzione del sistema o ritardo nel processing può portare a perdite di opportunità di trading o perdite finanziarie.
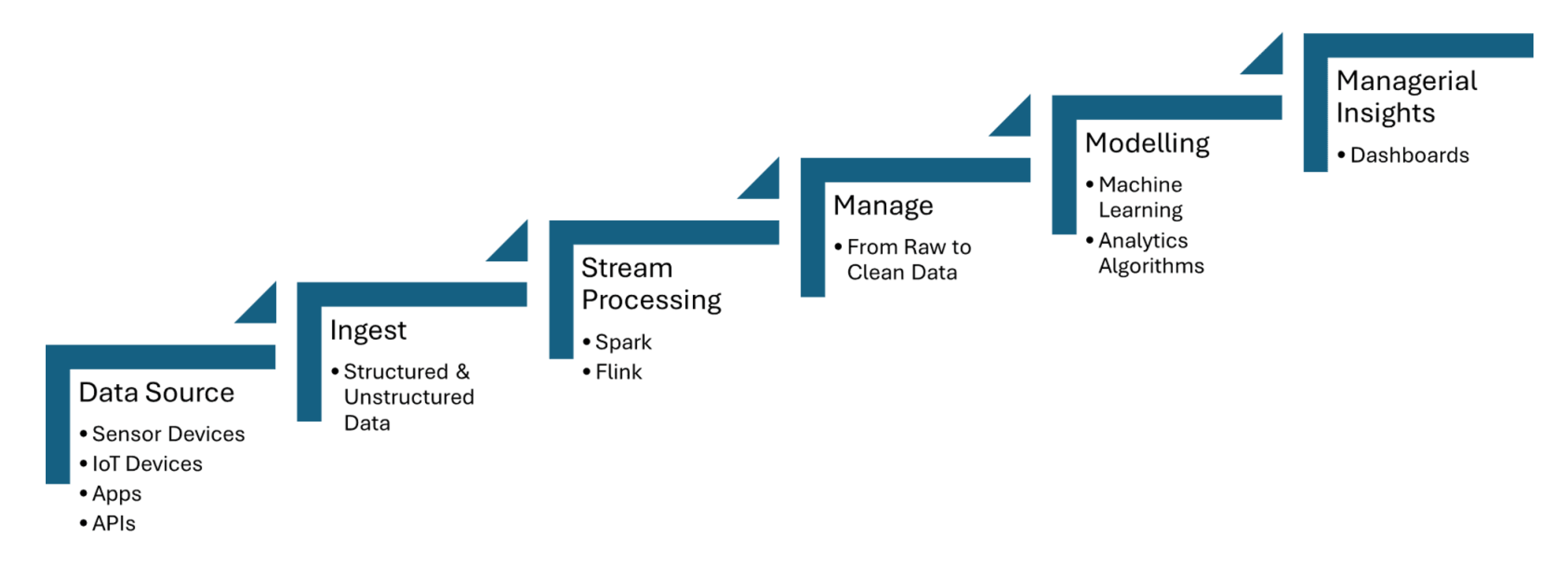
Elaborazione dei Dati dei Sensori IoT in Tempo Reale
Pipelines di dati in tempo reale ingurgitano dati dai sensori IoT, che catturano informazioni come temperatura, pressione o movimento, e poi elaborano i dati con latenza minima. Apache Kafka viene utilizzato per gestire l’ingestione dei dati dei sensori, mentre Apache Flink o Apache Spark Streaming consentono analisi e rilevamento di eventi in tempo reale. La Figura 1 condivisa di seguito mostra i passaggi del processing dei flussi di dati per IoT dai punti di origine fino ai dashboard:
Figura 1. Processing dei flussi di dati per IoT
Rilevamento di Frodi da Dati di Transazioni in Streaming
I dati delle transazioni vengono ingurgitati in tempo reale utilizzando strumenti come Apache Kafka, che gestisce elevate quantità di dati in streaming da molteplici fonti, come transazioni bancarie o gateways di pagamento. Framework di processing dei flussi come Apache Flink o Apache Spark Streaming vengono utilizzati per applicare modelli di machine learning o sistemi basati su regole che rilevano anomalie nei modelli di transazione, come comportamenti di spesa insoliti o discrepanze geografiche.
Come l’Automazione AI Sta Guidando i Pipelines Intelligenti e i Database Vettoriali
Flussi di lavoro intelligenti sfruttano il processing dei dati in tempo reale e i database vettoriali per migliorare la prendere decisioni, ottimizzare le operazioni e migliorare l’efficienza degli ambienti di dati su larga scala.
Automazione dei Pipeline di Dati
L’automazione della pipeline di dati consente la gestione efficiente di attività di ingestione, trasformazione e analisi di grandi quantità di dati senza intervento manuale. Apache Airflow garantisce che i compiti siano avviati in modo automatico al momento giusto e nella sequenza corretta. Apache NiFi facilita la gestione automatizzata del flusso di dati, permettendo l’ingestione, la trasformazione e il routing in tempo reale. Apache Kafka assicura che i dati vengano elaborati in modo continuo ed efficiente.
Framework di Orchestrazione della Pipeline
I framework di orchestrazione della pipeline sono essenziali per automatizzare e gestire i flussi di lavoro dei dati in modo strutturato ed efficiente. Apache Airflow offre funzionalità come la gestione delle dipendenze e il monitoraggio. Luigi si concentra sulla costruzione di pipeline complesse di jobs batch. Dagster e Prefect forniscono una gestione dinamica delle pipeline e un miglioramento della gestione degli errori.
Pipeline Adattive
Le pipeline adattative sono progettate per adattarsi dinamicamente a cambiamenti nell’ambiente dei dati, come fluttuazioni nel volume, nella struttura o nelle fonti dei dati. Apache Airflow o Prefect consentono una risposta in tempo reale automatizzando le dipendenze dei compiti e la programmazione in base alle attuali condizioni della pipeline. Queste pipeline possono sfruttare framework come Apache Kafka per lo streaming di dati scalabile e Apache Spark per l’elaborazione dei dati adattativa, garantendo un uso efficiente delle risorse.
Pipeline di Streaming
Una pipeline di streaming per popolare un database vettoriale per la generazione aumentata in tempo reale (RAG) può essere costruita interamente utilizzando strumenti come Apache Kafka e Apache Flink. I dati di streaming elaborati vengono poi convertiti in embedding e memorizzati in un database vettoriale, permettendo una ricerca semantica efficiente. Questa architettura in tempo reale garantisce che i grandi modelli linguistici (LLMs) abbiano accesso a informazioni aggiornate e contestualmente rilevanti, migliorando l’accuratezza e la affidabilità delle applicazioni basate su RAG come chatbot o motori di raccomandazione.
Data Streaming come Data Fabric per l’AI Generativa
Lo streaming dei dati in tempo reale consente l’ingestione, l’elaborazione e il recupero in tempo reale di enormi quantità di dati che i LLMs richiedono per generare risposte accurate e aggiornate. Mentre Kafka aiuta nello streaming, Flink elabora questi flussi in tempo reale, garantendo che i dati siano arricchiti e contestualmente rilevanti prima di essere immessi nei database vettoriali.
La Strada per il Futuro: Proteggere le Pipeline dei Dati per il Futuro
L’integrazione di flussi di dati in tempo reale, automazione AI e database vettoriali offre un potenziale trasformativo per le imprese. Per l’automazione AI, l’integrazione di flussi di dati in tempo reale con framework come TensorFlow o PyTorch permette decisioni in tempo reale e aggiornamenti continui dei modelli. Per il recupero di dati contestuali in tempo reale, sfruttare database come Faiss o Milvus aiuta nelle ricerche semantiche rapide, cruciali per applicazioni come RAG.
Conclusione
I punti chiave includono il ruolo cruciale di strumenti come Apache Kafka e Apache Flink per flussi di dati scalabili e a bassa latenza, insieme a TensorFlow o PyTorch per l’automazione AI in tempo reale, e FAISS o Milvus per la ricerca semantica rapida in applicazioni come RAG. Assicurare la qualità dei dati, automatizzare i flussi di lavoro con strumenti come Apache Airflow e implementare meccanismi robusti di monitoraggio e tolleranza ai guasti aiuteranno le imprese a rimanere agili in un mondo guidato dai dati e a ottimizzare le loro capacità decisionali.
Risorse aggiuntive:
- AI Automation Essentials di Tuhin Chattopadhyay, DZone Refcard
- Essenziali di Apache Kafka di Sudip Sengupta, DZone Refcard
- Iniziare con i Grandi Modelli Linguistici di Tuhin Chattopadhyay, DZone Refcard
- Iniziare con le Banche Dati Vettoriali di Miguel Garcia, DZone Refcard
Questo è un estratto dal Rapporto Trend 2024 di DZone,
Ingegneria dei Dati: Arricchire le Pipeline dei Dati, Espandere l’IA e Accelerare l’Analisi.
Source:
https://dzone.com/articles/the-data-pipeline-movement