













ארכיטקטורות מודרניות מבוססות ענן דורשות פתרונות לעיבוד יומנים שמספקים עמידות, יכולת הרחבה ואבטחה כדי לנטר יישומים מפוזרים. מחקר זה מציע פתרון היברידי לאיסוף, אגירה וניתוח של יומנים באמצעות שירות Kubernetes של Azure (AKS) ליצירת יומנים, Fluent Bit לאיסוף יומנים, Azure EventHub לאגירה ביניים ו-Splunk המופעל על קלאסטר Apache CloudStack מקומי לאינדוקס ויזואליזציה של יומנים באופן מקיף.
אנו מפרטים את העיצוב, היישום וההערכה של המערכת, ומדגימים כיצד ארכיטקטורה זו תומכת בעיבוד יומנים אמין וניתן להרחבה עבור עומסי עבודה מבוססי ענן תוך שמירה על שליטה על הנתונים במתקן.
מבוא
פתרונות רישום מרכזיים הפכו להיות בלתי נפרדים. יישומים מודרניים, במיוחד אלו שנבנים על ארכיטקטורות מיקרו-שירותים, מייצרים כמויות עצומות של יומנים, לעיתים בפורמטים מגוונים וממקורות שונים. יומנים אלו הם המקור המרכזי לנטר את ביצועי היישום, לאבחן בעיות ולוודא את האמינות הכוללת של המערכת. עם זאת, ניהול כמויות כה גבוהות של נתוני יומנים מציב אתגרים משמעותיים, במיוחד בסביבות ענן היברידיות שמכילות תשתיות גם במתקן וגם בענן.
פתרונות רישום מסורתיים, למרות שהם יעילים עבור יישומים מונוליתיים, מתקשים להתרחב תחת הדרישות של ארכיטקטורות מבוססות מיקרו-שירותים. האופי הדינמי של מיקרו-שירותים, המתאפיין בהפצות עצמאיות ועדכונים תכופים, מייצר זרם מתמשך של יומנים, שכל אחד מהם משתנה במבנה ובפורמט. יומנים אלו חייבים להיות נקלטים, מעובדים ומנותחים בזמן אמת כדי לספק תובנות ברות פעולה. יתרה מכך, ככל שהיישומים פועלים יותר ויותר בסביבות היברידיות, הבטחת האבטחה ונתוני PII הופכת להיות קריטית, לאור הדרישות השונות לעמידה בתקנות ורגולציות.
מאמר זה מציג פתרון כולל שעונה על אתגרים אלו על ידי ניצול היכולות המשולבות של Azure ו-Apache CloudStack. על ידי שילוב היכולת להתרחב וניתוח של Azure עם הגמישות והעלויות הנמוכות של תשתית CloudStack המקומית, הפתרון הזה מציע גישה מקיפה ומאוחדת לרישום מרכזי.
סקירת ספרות
איסוף יומנים מרכזי במיקרו-שירותים מתמודד עם אתגרים כמו השהיית רשת, פורמטים שונים של נתונים ואבטחה על פני שכבות מרובות. בעוד שסוכנים קלים כמו Fluent Bit ו-FluentD בשימוש נרחב, הובלת יומנים בצורה יעילה נותרת אתגר.
פתרונות כמו ערימת ELK ו-Azure Monitor מציעים עיבוד מרכזי של יומנים אך לרוב כוללים יישומים רק בענן או רק באתר, מה שמגביל את הגמישות בפריסות היברידיות. פתרונות ענן היברידיים מאפשרים לארגונים לנצל את יכולת ההרחבה של הענן תוך שמירה על שליטה על נתונים רגישים בסביבות מקומיות. צינורות עיבוד יומנים היברידיים, במיוחד אלו המשתמשים בטכנולוגיות סטרימינג של אירועים, עונים על הצורך בהעברת יומנים והצטברות בקנה מידה.
ארכיטקטורת מערכת
הארכיטקטורה, המוצגת למטה, משלבת את Azure EventHub ו-AKS עם Apache CloudStack ו-Splunk מקומיים. כל רכיב מותאם לעיבוד יומנים יעיל ולהעברת נתונים מאובטחת בין הסביבות.
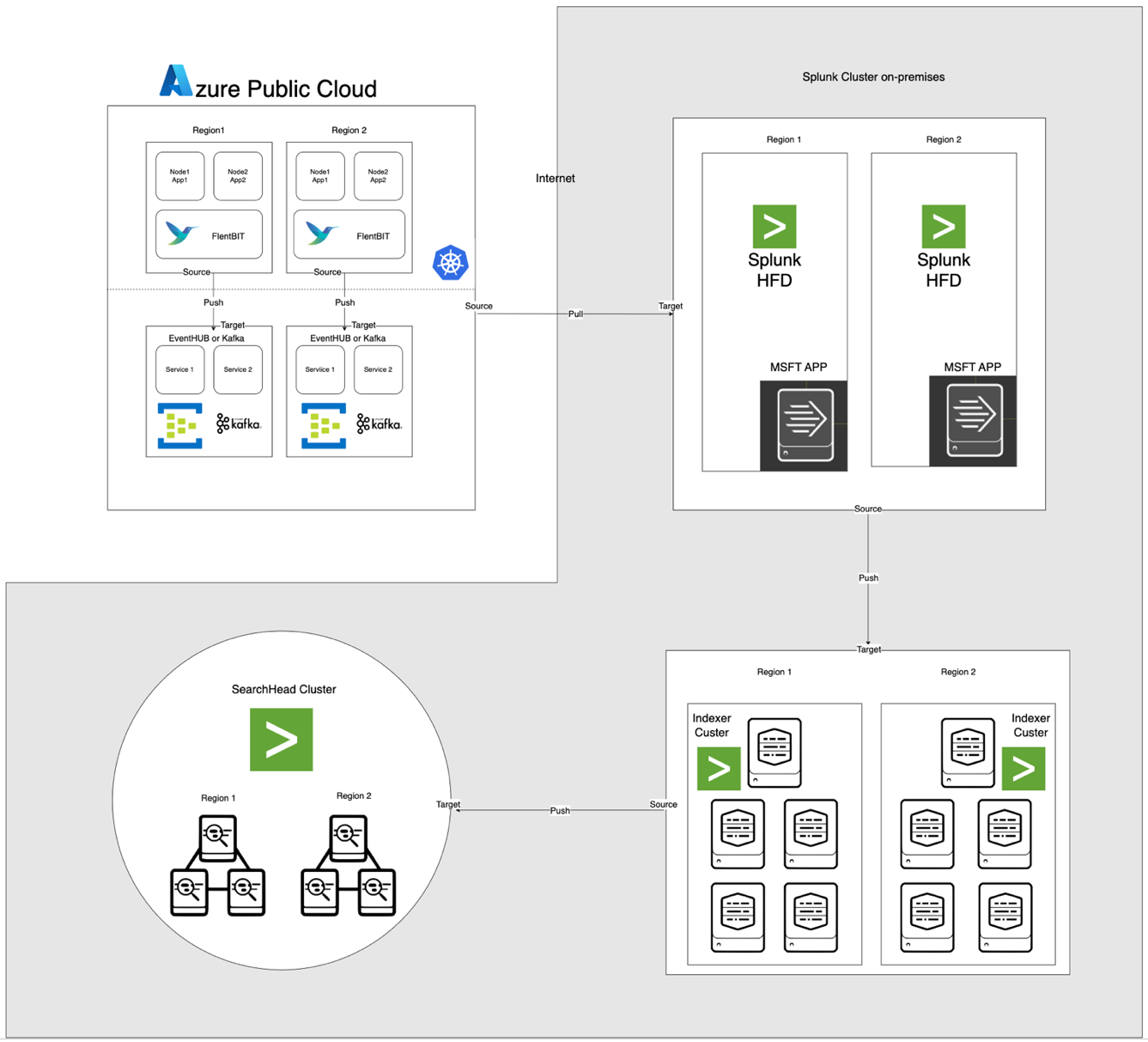
תיאורי רכיבים
- AKS: מארח יישומים ממוקדים ומייצר יומנים הנגישים דרך שכבת הצטברות היומנים של Kubernetes.
- Fluent Bit: מופעל כ-DaemonSet, אוסף יומנים מקודקודי AKS. כל מופע של Fluent Bit לוכד יומנים מ-/var/log/containers, מסנן אותם ומעביר אותם בפורמט JSON ל-EventHub.
- Azure EventHub: משמש כמתווך הודעות בעל קיבולת גבוהה, מצטבר יומנים מ-Fluent Bit ושומר אותם באופן זמני עד שימשכו על ידי ה-Splunk Heavy Forwarder.
- אפאצ'י קאפקה: פועל כגשר אמין בין Fluent Bit ו-Splunk. Fluent Bit מעביר יומנים ל-Kafka באמצעות תוסף הפלט שלו ל-Kafka, שם הלוגים מאוחסנים ומעובדים באופן זמני. לאחר מכן, Splunk צורף את הלוגים מ-Kafka באמצעות מחברים כמו Kafka Connect Splunk Sink או סקריפטים מותאמים, מבטיח ארכיטקטורה המתקיימת ומיוחדת.
- העביר החמור של Splunk (HF): מותקן ב-Apache CloudStack, העביר החמור משיג לוגים מ-Azure EventHub באמצעות תוסף Splunk לשירותי ענן של מיקרוסופט. תוסף זה מספק שילוב חלק, מאפשר לעביר החמור להתחבר בצורה מאובטחת ל-EventHub, לשלוף לוגים בזמן קרוב לזמן אמיתי, ולהמיר אותם כפי הצורך לפני העברתם לאינדקסר של Splunk לאחסון ועיבוד
- Splunk על Apache CloudStack: מספק אינדקסציה של לוגים, חיפוש, ויזואליזציה, והתראות.
זרימת נתונים
- איסוף לוגים ב-AKS: Fluent Bit מקבל את הקבצי לוגים בתיקיית /var/log/containers, מסנן לוגים לא נחוצים ומסמן כל לוג עם מטא-נתונים (למשל, שם המיכל, שם המרחב).
- העברה ל-EventHub: הלוגים נשלחים ל-EventHub דרך HTTPS באמצעות תוסף הפלט של Fluent Bit ל-azure_eventhub, מבטיח העברת נתונים מאובטחת.
- אפאצ'י Kafka: יומנים מ-AKS מאגרים על ידי Fluent Bit, הפועל כ-DaemonSet, שמנתח ומעביר אותם אל Apache Kafka דרך תוסף הפלט שלו ל-Kafka. Kafka פועל כמאגר בתקיפות גבוהה, אוחסן ומפרט יומנים לצורך התרחבות. Splunk מקליט את היומנים הללו מ-Kafka באמצעות מחברים או סקריפטים, מאפשר אינדוקסציה, ניתוח ומעקב בזמן אמת.
- משיכת יומנים עם Splunk Heavy Forwarder: ה-Heavy Forwarder ב-Apache CloudStack מתחבר ל-EventHub באמצעות SDK של EventHubs ומשכפל יומנים, מעביר אותם לאינדקסר המקומי של Splunk לאחסון ועיבוד.
- אחסון וניתוח ב-Splunk: היומנים מאוחסנים ב-Splunk, מאפשר חיפושים בזמן אמת, ויזואליזציות של דפים ממופעים והתראות על סמכויות יומן.
מתודולוגיה
הפעלת Fluent Bit כ-DaemonSet ב-AKS
הגדרה של Fluent Bit מאוחסנת ב-ConfigMap ומופעלת כ-DaemonSet. להלן ההגדרה המורחבת ל-DaemonSet של Fluent Bit:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations:
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- אימות הרשומה הנכנסת
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- הפקת מפתח ייחודי לאיחוד על פי זרם ותגית
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- טיפול בקטעי יומן (תגית יומן == 'P')
if record.logtag == 'P' then
-- אחסון הקטע במצב האיחוד
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- טיפול בסוף של יומן משובש
if reassemble_state[reassemble_key] then
-- שלב הקטעים שמאוחסנים עם היומן הנוכחי
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- ניקוי מצב האיחוד עבור מפתח זה
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- אם לא נדרש איחוד, להעביר את היומן כפי שהוא
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(? - [קלט] המקטע מפרט את איסוף הלוגים מתיקיית /var/log/containers.
- [מסנן] המקטע מעשיר את הלוגים במטא-נתוני Kubernetes.
- [פלט] המקטע מגדיר את Fluent Bit להעביר את הלוגים ל-EventHub בפורמט JSON.
הגדרות EventHub של Azure
EventHub מחייב ניימספייס, מופע מסוים של EventHub ושליטת גישה דרך מדיניות גישה משותפת.
- הגדרת ניימספייס ו-EventHub: צור ניימספייס ומופע של EventHub ב-Azure, הגדר מדיניית שליחה וקבל את מחרוזת החיבור.
- הגדרה עבור כמות נתונים גבוהה: EventHub מוגדר עם כמות גבוהה של מחיצות כדי לתמוך בקידמה, במאפס, ובזרימות נתונים סותמות מ-Fluent Bit.
הגדרת Splunk Heavy Forwarder ב-Apache CloudStack
Splunk Heavy Forwarder מפעיל לוגים מ-EventHub ומעביר אותם לאינדקסר של Splunk.
- תוסף עבור שירותי הענן של מיקרוסופט: התקן את התוסף כדי לאפשר קישוריות אל EventHub. הגדר את הקלט ב־
inputs.conf:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- עיבוד בצמיחה: הגדר batch_size ל־500 וinterval ל־30 שניות כדי לייעל את קליטת הנתונים ולהפחית את תדירות שיחות הרשת.
אינדוקסציה ותצוגה ב-Splunk
- העשרת נתונים: הלוגים מועשרים במטא-נתונים נוספים ב-Splunk באמצעות חילוצי שדות.
- חיפושים ולוחות מחוונים: שאילתות SPL מאפשרות חיפושים בזמן אמת, ולוחות מחוונים מותאמים אישית מספקים ויזואליזציה של דפוסי יומן.
- התראות: התראות מוגדרות להפעלה על דפוסי יומן ספציפיים, כמו שיעורי שגיאות גבוהים או אזהרות חוזרות ממיכלים ספציפיים.
ביצועים וקניין
ניסויים מראים כי המערכת יכולה לעמוד בעיבוד יומנים בקצב גבוה, ויכולות האגזוז של EventHub מונעות אובדן נתונים במהלך הפסקות רשת. שימוש במשאבים של Fluent Bit על צמתי AKS נשאר מינימלי, ואינדקסר של Splunk עובד על נפח היומנים ביעילות עם הגדרות מתאימות של אינדקסציה וסינון.
אבטחה
HTTPS משמש לאבטחת תקשורת בין AKS ו-EventHub, בעוד ש-Splunk HF משתמש במפתחות מאובטחים לאימות עם EventHub. כל רכיב בצינור מיישם מנגנוני ניסיון מחדש כדי לשמור על שלמות הנתונים.
שימוש במשאבים
- Fluent Bit מצמצם בממוצע 100-150 MiB של זיכרון ו-0.2-0.3 CPU על צמתי AKS.
- שימוש במשאבים של EventHub מתארגן באופן דינמי בהתאם להגדרות מחלקות וקפיציות.
- העומס על Splunk HF מאוזן דרך עיבוד באצווה, מקסם העברת נתונים בלי להעמיס על משאבי Apache CloudStack.
אמינות וגמישות בפני תקלות
הפתרון משתמש באגזוז של EventHub כדי לוודא שהיומנים נשמרים במקרה של כשלים בלועזי. EventHub גם תומך במדיניות ניסיון מחדש, שמשפרת עוד יותר את שלמות הנתונים והאמינות.
דיון
יתרונות של ארכיטקטורת ענן היברידי
ארכיטקטורה זו מספקת גמישות, יכולת הרחבה ואבטחה על ידי שילוב שירותי Azure עם שליטה מקומית. היא גם מנצלת יכולות של סטרימינג ומידוד מבוסס ענן מבלי לפגוע בריבונות הנתונים.
מגבלות
בעוד ש-EventHub מציע אגירה אמינה של נתונים, העלויות גדלות עם יחידות המעבר, מה שהופך אופטימיזציה של תצורות Forwarding לעניין חיוני. בנוסף, העברת נתונים בין ענן לסביבות מקומיות מציגה פוטנציאל לעיכוב.
יישומים עתידיים
ארכיטקטורה זו יכולה להיות מורחבת על ידי שילוב למידת מכונה לגילוי אנומליות ביומנים או הוספת תמיכה לספקי ענן מרובים כדי להרחיב עוד יותר את עיבוד היומנים ואת החוסן של רב-ענן.
סיכום
מחקר זה מדגים את היעילות של צינור עיבוד יומנים היברידי המנצל משאבי ענן ומקומיים. על ידי שילוב שירות Kubernetes של Azure (AKS), Azure EventHub ו-Splunk על Apache CloudStack, אנו יוצרים פתרון הניתן להרחבה וחסין לניהול וניתוח יומנים מרכזי. הארכיטקטורה מתמודדת עם אתגרים מרכזיים בלוגינג מבוזר, כולל קצב נתונים גבוה, אבטחה וסובלנות לתקלות.
שימוש ב־Fluent Bit כאוסף יומנים קל מאוד ב־AKS מבטיח איסוף נתונים יעיל עם שימוש מינימלי במשאבים. יכולות הBuffering של Azure EventHub מאפשרות אגירת יומנים אמינה ואחסון זמני, מה שהופך אותו למתאים מאוד לטיפול בתעבורת יומנים משתנה ולשמירה על תקינות הנתונים במקרה של בעיות קישור. ה־Splunk Heavy Forwarder וההצגה של Splunk ב־Apache CloudStack מאפשרים לארגונים לשמור בקרה על אחסון יומנים וניתוחים תוך נצילות מהגמישות והגידול של משאבי הענן.
הגישה הזו מציעה יתרונות ניכרים לארגונים הזקוקים להגדרת ענן היברידי, כגון שליטה משופרת על הנתונים, עמיתות עם דרישות מגורי הנתונים, והגמישות לגדול עם הביקוש. עבודה עתידית יכולה לחקור את השילוב של למידת מכונה כדי לשפר את ניתוח היומנים, גילוי חריגות אוטומטי, והרחבה להגדרת עננים מרובים כדי להגביר עמיתות וגמישות. מחקר זה מספק ארכיטקטורת בסיס הניתנת להתאמה לצרכי המתפתחים של מערכות מודרניות ומבוזרות בסביבות תעשייתיות.
מקורות
Azure Event Hubs ו־Kafka
מעקב ולוגים היברידיים
- תבניות מעקב Hybrid ו- Multi-Cloud
- אסטרטגיות מעקב ל-Hybrid Cloud
שילוב Splunk
- הפעלת Azure Event Hubs ב-Splunk
- נתוני Azure אל פלטפורמת Splunk
הפצת AKS
Source:
https://dzone.com/articles/bridging-cloud-and-on-premises-log-processing