













הערת העורך: מאמר הבא נכתב ופורסם בדוח המגמות לשנת 2024 של DZone,הנדסת נתונים: העשרת תשתיות נתונים, הרחבת בינה מלאכותית והאצת אנליטיקה.
מאמר זה בוחן אסטרטגיות חיוניות לניצול זרימת נתונים בזמן אמת להשגת תובנות פעולתיות והכנת מערכות לעתיד דרך אוטומציה של בינה מלאכותית ומאגרי נתונים וקטוריים. הוא חוקר ארכיטקטורות וכלים מתפתחים שמעצימים את יכולת העסקים להישאר גמישים ומתחרים בעולם מונע בנתונים.
זרימת נתונים בזמן אמת: האבולוציה והשיקולים המרכזיים
זרימת נתונים בזמן אמת התפתחה מתהליך עיבוד חלקי מסורתי, שבו הנתונים עובדו באינטרוולים שהכניסו השהיות, לטיפול מתמשיך בנתונים בעת יצירתם, ולאפשר מענות מיידיות לאירועים קריטיים. על ידי הינתקות של בינה מלאכותית, אוטומציה ומאגרי נתונים וקטוריים, עסקים יכולים להעצים את יכולותיהם, בשימוש בתובנות בזמן אמת לחיזוי תוצאות, אופטימיזציה של תהליכים וניהול יעיל של קבוצות נתונים גדולות ומורכבות.
הצורך בזרימת נתונים בזמן אמת
יש צורך לפעול על מידע ברגע שהוא נוצר, במיוחד במצבים כמו גילוי התרמית, אנליטיקה של לוגים או עקיבת התנהגות הלקוחות. שידור בזמן אמת מאפשר לארגונים ללכוד, לעבד ולנתח מידע באופן מיידי, ולהגיב במהירות לאירועים דינמיים, לאופטימיזץ' קבלת החלטות ולשפר חוויית הלקוח בזמן אמת.
מקורות מידע בזמן אמת
מידע בזמן אמת מקור לרוב ממערכות ומכשירים שמייצרים מידע באופן מתמשך, לעיתים קרובות בכמויות גדולות ובפורמטים שקשים לעיבוד. מקורות מידע בזמן אמת לרוב כוללים:
- מכשירי IoT וחיישנים
- לוגים של שרתים
- פעילות אפליקציות
- פרסום מקוון
- אירועים של שינויים בבסיס נתונים
- זרמי קליקים באתרים
- פלטפורמות מדיה חברתית
- בסיסי נתונים טרנזקציוניים
ניהול יעיל וניתוח של זרמי המידע האלה דורשת מערכת עזור חזקה שיכולה להתמודד עם נתונים לא מאורגנים ונתונים חצי-מאורגנים; זה מאפשר לעסקים להוציא מידע ערכי ולקבל החלטות בזמן אמת.
אתגרים קריטיים בקווי מידע מודרניים
קווי מידע מודרניים ניצבים לפני מספר אתגרים, כולל שמירה על איכות המידע, ביצוע המרות מדויקות ומינימיזציה של זמן השיבת קו המידע:
- איכות מידע ירודה יכולה להוביל למסקנות מוטעות.
- המרות של מידע הן מורכבות ודורשות קידוד מדויק.
- תקלות תכופות מפריעות לתפעול, ולכן מערכות עמידות בפני שגיאות הן חיוניות.
בנוסף, ניהול מידע חשוב מאוד כדי להבטיח אחידות מידע ואמינות ברחבי התהליכים. יכולת גידול היא בעיה נוספת, שכן קווי העיבוד חייבים להתאים לשינויים בנפחי המידע, וניטורנכון והתראות הם חיוניים להימנעות מכשלים בלתי צפויים ולהבטחת תפעול חלק.
ארכיטקטורות ותרחישי יישום של זרימת מידע בזמן אמת מתקדם
החלק הזה מדגים את היכולות של מערכות מידע מודרניות לעיבוד וניתוח מידע בתנועה, ונותן לארגונים את הכלים להגיב לאירועים דינמיים במילישנים.
שלבים לבניית קו עיבוד מידע בזמן אמת
ליצירת קו עיבוד מידע בזמן אמת אפקטיבי, חשוב לבצע סדרה של שלבים מובנים שיבטיחו זרימת מידע, עיבוד ויכולת גידול חלקה. טבלה 1, שמוצגת להלן, מתארת את השלבים העיקריים המעורבים בבניית קו עיבוד מידע בזמן אמת מוצק:
טבלה 1. שלבים לבניית קו עיבוד מידע בזמן אמת
| step | activities performed |
|---|---|
| 1. קליטת מידע | הקמת מערכת ללכידת זרמי מידע ממקורות שונים בזמן אמת |
| 2. עיבוד מידע | ניקוי, אימות ושינוי פורמט של המידע כדי להבטיח שהוא מוכן לניתוח |
| 3. עיבוד זרימה | הגדרת צרכנים ללקיחת, עיבוד וניתוח מידע באופן מתמשך |
| 4. איחסון | איחסון המידע המעובד בפורמט מתאים לשימוש במשק הירידה |
| 5. ניטור וקירוב | התקינו כלים לניטור ביצועי הפיפליין ולהבטיח שהוא יכול להתאים לדרישות נתונים גוברות |
כלים מובילים לזרימת נתונים בקוד פתוח
לבניית פיפליין של נתונים בזמן אמת עמיד ויציב, קיימים מספר כלים מובילים בקוד פתוח לאיסוף, איחסון, עיבוד וניתוח נתונים, כל אחד מהם ממלא תפקיד קרדינלי בניהול ועיבוד זרמי נתונים בקנה מידה גדול.
כלים בקוד פתוח לאיסוף נתונים:
- Apache NiFi, עם גרסתו החדשה 2.0.0-M3, מציע יכולות של קירוב מוגבר ועיבוד בזמן אמת.
- Apache Airflow משמש לניהול תהליכים מורכבים.
- Apache StreamSets מספק ניטור ועיבוד זרימת נתונים רציפים.
- Airbyte מפשיט את איסוף וטעינת הנתונים, והוא בחירה חזקה לניהול דרישות איסוף נתונים מגוונות.
כלים בקוד פתוח לאיחסון נתונים:
- אפאצ'ה קאפקא משמש ברחבי העולם לבניית קווי תעבורה בזמן אמת ויישומי זרימה בזכות יכולת ההתאמה, העמידות והמהירות הגבוהה שלו.
- אפאצ'ה פולסר, מערכת הודעות מבוזרת, מציעה יכולת התאמה ועמידות חזקות, ומתאימה לניהול מסרים בקנה מידה גדול.
- NATS.io היא מערכת הודעות ביצועית גבוהה, שמשמשת בדרך כלל ביישומי IoT ויישומים ניהיליים בענן, ותוכננה לארכיטקטורות מיקרוסרוויסים ומציעה תקשורת קלה ומהירה לצרכים של נתונים בזמן אמת.
- אפאצ'ה הבייס, מאגר נתונים מבוזר שבנוי מעל HDFS, מספק עמידות חזקה ויכולת קלט/פלט גבוהה, ומתאים לאיחסון כמויות גדולות של נתונים בזמן אמת בסביבה NoSQL.
כלים פתוחים לעיבוד נתונים:
- אפאצ'ה ספארק בולט בשל מחשוב הקלט בזכרון, ומספק עיבוד מהיר עבור כל יישומי חבילה וזרימה.
- אפאצ'ה פלינק מתוכנן לעיבוד זרימה מבוזר בביצועים גבוהים ותומך במשימות חבילה.
- Apache Storm ידוע ביכולתו לעבד יותר ממיליון רשומות בשניה, מה שהופך אותו למהיר ביותר וגמיש.
- Apache Apex מציע עיבוד משולב של זרמים וקבוצות.
- Apache Beam מספק מודל גמיש שעובד עם מספר מנועי ביצועים כמו Spark ואף Flink.
- Apache Samza, שפותח על ידי LinkedIn, מתאים היטב ל-Kafka ומטפל בעיבוד זרמים עם דגש על גמישות ועמידות.
- Heron, שפותח על ידי Twitter, היא פלטפורמת אנליטיקה בזמן אמת שמתאימה בצורה טובה ל-Storm אך מציעה ביצועים טובים יותר והפרדת משאבים, מה שהופך אותה מתאימה לעיבוד זרמים מהירים בקנה מידה גדול.
כלים חופשיים לאנליטיקה של נתונים:
- Apache Kafka מאפשר עיבוד בעל קצב גבוה ועיכוב נמוך של זרמי נתונים בזמן אמת.
- Apache Flink מציע עיבוד זרם חזק, מתאים ליישומים שדורשים חישובים מבוזרים ובעלי מצב.
- Apache Spark Streaming משולב עם מערכת Spark הרחבה יותר ומתמודד עם נתונים בזמן אמת ובטיפול בנתונים בכמות גדולה באותה הפלטפורמה.
- Apache Druid ו-Pinot משמשים כמסדי נתונים אנליטיים בזמן אמת, המציעים יכולות OLAP המאפשרות שאילתות של מערכות נתונים גדולות בזמן אמת, מה שהופך אותם לשימושיים במיוחד ללוחות בקרה ויישומי בינה עסקית.
מקרי שימוש ביישום
יישומים בעולם האמיתי של תשתיות נתונים בזמן אמת מדגימים את הדרכים המגוונות בהן ארכיטקטורות אלו מספקות אפקטיביות קריטיות ביישומים שונים בתעשיות מגוונות, המשפרות ביצועים, קבלת החלטות ויעילות אופרציונית.
זרימת נתונים של שוק ההון למערכות סחר בקצב גבוה
במערכות סחר בקצב גבוה, שבהן מילישנים יכולים להיות ההבדל בין רווח להפסד, משתמשים ב- Apache Kafka או Apache Pulsar לצריכת נתונים בקצב גבוה. Apache Flink או Apache Storm מתאימים לעיבוד בעיכוב נמוך כדי לוודא שהחלטות סחר נעשות באופן מיידי. תשתיות אלו חייבות לתמוך ביכולת גדולה להתאמה ועמידות לשגיאות, כי כל השהייה במערכת או עיכוב בעיבוד יכולים להוביל להחמצת הזדמנויות סחר או לאובדן כספי.
עיבוד נתונים מה-IoT וחיישנים בזמן אמת
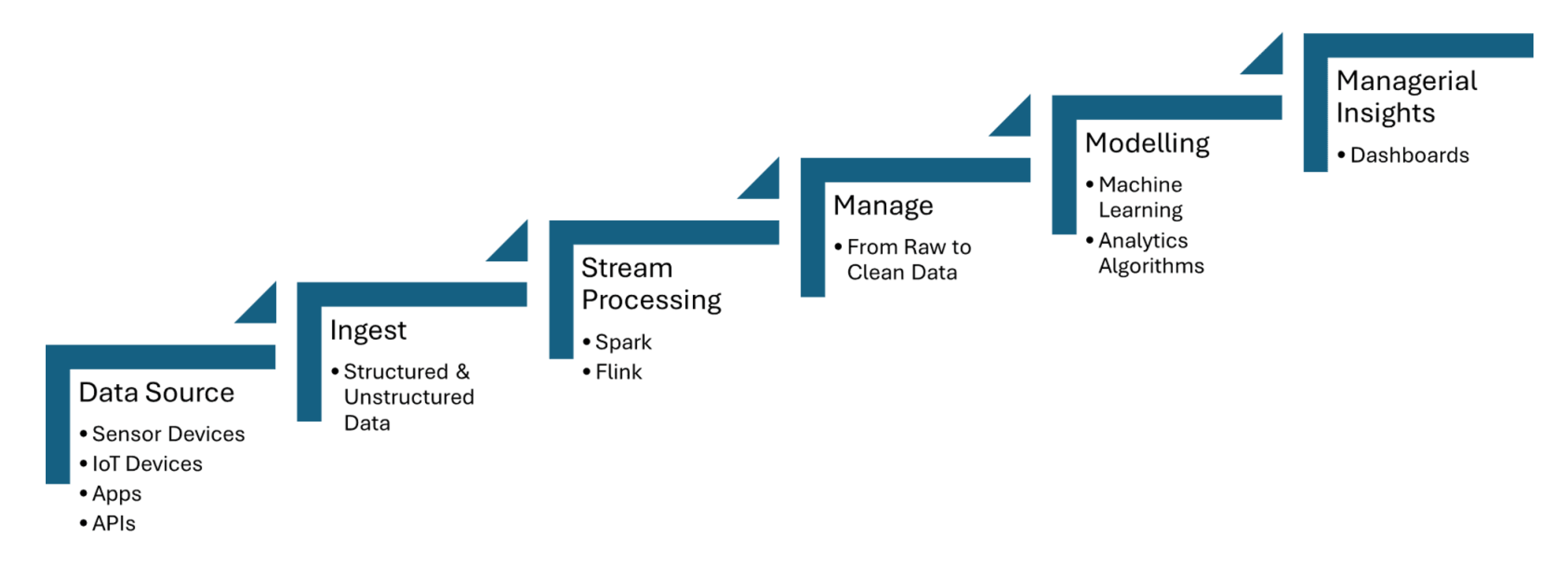
קווי נתונים בזמן אמת צורכים נתונים מחיישני IoT, שמקלטים מידע כמו טמפרטורה, לחץ או תנועה, ואז מעבדים את הנתונים עם מינימום זמן תיזמון. Apache Kafka משמש להתמודד עם קליטת נתוני החיישן, בעוד שApache Flink או Apache Spark Streaming מאפשרים אנליטיקה בזמן אמת וזיהוי אירועים. תמונה 1 שמותחת למטה מראה את שלבי עיבוד הזרם לIoT ממקורות הנתונים לדשבורדינג:
תמונה 1. עיבוד זרם לIoT
גילוי רמאות מנתוני עיסקאות זרם
נתוני עיסקאות נקלטים בזמן אמת באמצעות כלים כמו Apache Kafka, שמתמודד עם כמויות גבוהות של נתונים זורמים ממקורות מרובים, כגון עיסקאות בנק או שערי תשלום. מסגרות עיבוד זרם כמו Apache Flink או Apache Spark Streaming משמשות ליישום מודלים של למידת מכונה או מערכות מבוססות כללים שמזהים אנומליות בתבניות עיסקאות, כגון התנהגות הוצאה חריגה או חילוקי מיקום גאוגרפיים.
איך אוטומציה של AI דוחפת קווי נתונים חכמים ומסדי נתונים וקטוריים
תהליכים חכמים מנצלים עיבוד נתונים בזמן אמת ומסדי נתונים וקטוריים לשיפור קבלת החלטות, אופטימיזציה של תפעולים ושיפור היעילות של סביבות נתונים בקנה מידה גדול.
אוטומציה של קווי נתונים
ניהול אוטומטי של תעלות נתונים מאפשר טיפול יעיל במעבר נתונים בקנה מידה גדול, כולל קליטה, המרה וניתוח נתונים ללא התערבות ידנית. Apache Airflow מבטיח שמשימות יוצתו באופן אוטומטי בזמן הנכון וברצף נכון. Apache NiFi מקל על ניהול זרימת נתונים אוטומטי, ומאפשר קליטה, המרה וניתוב נתונים בזמן אמת. Apache Kafka מבטיח כי נתונים יעובדו באופן מתמשך ויעיל.
מסגרות ניהול תעלות
מסגרות ניהול תעלות הן חיוניות לאוטומציה וניהול של תהליכי נתונים בדרך מבנית ויעילה. Apache Airflow מציע תכונות כמו ניהול תלות וניטור. Luigi מתמקד בבניית תעלות מורכבות של משימות בכביש. Dagster ו-Prefect מספקים ניהול תעלות דינמי וניהול שגיאות משופר.
תעלות אדפטיביות
תעלות אדפטיביות מעוצבות כדי להתאים באופן דינמי לשינויים בסביבות נתונים, כמו שינויים בנפח, מבנה או מקורות נתונים. Apache Airflow או Prefect מאפשרים תגובה בזמן אמת על ידי אוטומציה של תלויות משימות ותזמון על פי תנאי תעלה נוכחיים. תעלות אלה יכולות לנצל מסגרות כמו Apache Kafka לזרימת נתונים סקילבילית ו-Apache Spark לעיבוד נתונים אדפטיבי, כדי להבטיח שימוש יעיל במשאבים.
תעלות זרימה
מערכת זרימת סטרימינג לאיכול וסידור מסד וקטורים לשם שליפה בזמן אמת להגדלת יכולת ייצור (RAG) ניתן לבנות באמצעות כלים כמו Apache Kafka ו-Apache Flink. הנתונים המעובדים של הסטרימינג הופכים לאמבדינגים ונאחסים במסד וקטורים, דבר שמאפשר חיפוש סמנטי יעיל. הארכיטקטורה בזמן אמת זו מבטיחה ש-מודלים שפה גדולים (LLMs) יכולים לגשת למידע עדכני ורלוונטי מבחינה הקשורה להקשר, דבר שמשפר את הדיוק והאמינות של יישומים מבוססי RAG כמו צ'טבוטים או מנועי המלצות.
זרימת נתונים כבד לתפירה לשם ייצור מוצאים
זרימת נתונים בזמן אמת מאפשרת איכול, עיבוד ושליפה בזמן אמת של כמויות גדולות של נתונים שה-LLMs דורשים ליצירת תגובות מדויקות ועדכניות. בעוד Kafka עוזר בזרימה, Flink מעבד את הזרמים בזמן אמת, דבר שמבטיח שהנתונים מועשרים ורלוונטיים לפני שהם מוכנים למסדי הווקטורים.
הדרך לעתיד: הכנת תשתיות נתונים לעתיד
האינטגרציה של זרימת נתונים בזמן אמת, אוטומציה באמצעות AI ומסדי נתונים וקטוריים מציעים פוטנציאל מרחיק לכת לעסקים. עבור אוטומציה באמצעות AI, האינטגרציה של זרימת נתונים בזמן אמת עם מסגרות כמו TensorFlow או PyTorch מאפשרת החלטות בזמן אמת ועדכונים מתמשיכים של מודלים. עבור שליפת נתונים קונטקסטואליים בזמן אמת, ניצול מסדי נתונים כמו Faiss או Milvus עוזרים בחיפושים סמנטיים מהירים, שהם קריטיים ליישומים כמו RAG.
מסקנה
המסקנות העיקריות כוללות את התפקיד הקריטי של כלים כמו Apache Kafka ו-Apache Flink לזרימת נתונים קלה להתאמה, בעלת זמן מהירות נמוך, יחד עם TensorFlow או PyTorch לאוטומציה באמצעות AI בזמן אמת, ו-FAISS או Milvus לחיפוש סמנטי מהיר ביישומים כמו RAG. ביטחון איכות הנתונים, אוטומציה של תהליכים עם כלים כמו Apache Airflow, ויישום מנגנונים חזקים של ניטור ועמידות יעזרו לעסקים להישאר גמישים בעולם מונע בנתונים ולאופטימז את יכולת ההחלטות שלהם.
משאבים נוספים:
- מועילי אוטומציה ב-AI על ידי Tuhin Chattopadhyay, DZone Refcard
- יסודות Apache Kafka מאת סודיפ סנגופטה, כרטיס הרפרוש של DZone
- תחילת עבודה עם מודלי שפה גדולים מאת טוהין צ'טופאדיה, כרטיס הרפרוש של DZone
- תחילת עבודה עם מאגרי וקטורים מאת מיגל גרסיה, כרטיס הרפרוש של DZone
זהו קטע מדוח המגמות של DZone לשנת 2024,
הנדסת נתונים: העשרת קווי נתונים, הרחבת בינה מלאכותית והאצת אנליטיקה.
Source:
https://dzone.com/articles/the-data-pipeline-movement