













בעולם המוניטין המודרני, על העסקים להסתגל לשינויים המהירים באופן בו מנוהלים המידע, ניתנים ומשמשים אותו. מערכות מרכזיות המסורתיות וארכיטקטורות מונוליסטיות, עם היסטוריה מספקת, אינן יותר מספקות למטרות הגדלה של אירגונים הצריכים נגישות מהירות גבוהה יותר ולמחשבות מקרה אמת על מידע. קרקע מהפכנית בתחום הזו היא ארכיטקטורת משוב אירגונים, ובשילוב עם שירותי AWS, היא מופנה כפתרון חזק לטיפול באתגרים המידע המורכבים.
הדילמה של המידע
הרבה אירגונים מעמדים במאמץ גדול כשמסתמכים על ארכיטקטורות מידע מאוד מיושנות. אחד האתגרים הם:
מידע מרכזי, מונוליסטי ולא מוביל לתחום
מידע מרכזי מרכזימאגר מידעהוא מיקום אחד לכל המידע שלך, שמקל לניהול וגישה אך יכול לגרום לבעיות ביצועים אם לא מוסיף בדיוק. מאגר מידע מונוליסטי שמשתלב את כל תהליכי הניהול המידעי במערכת אחת משולבת, שפשוט את ההגדרה אך קשה להרחב ולשמר. מאגר מידע לא מוביל לתחום מעוצב לאחסן מידע מכל תעשייה או מקור, מציע פלנטריות ויישום רחב אך יכול להיות מורכב למנוע ופחות מותאם לשימושים ספציפיים.
נקודות הדחיפות בהתבסס על אר
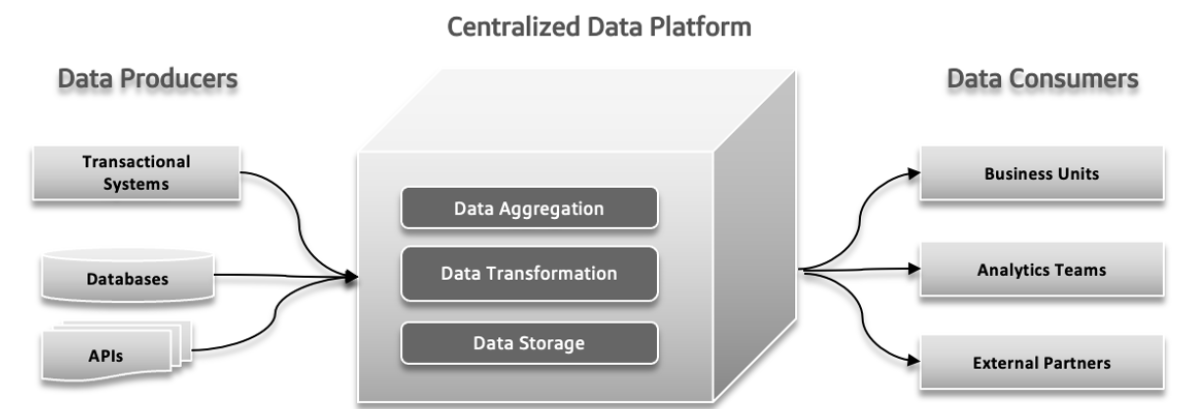
במערכות נתונים מסורתיות, יכולים להתרחש מספר בעיות. יצרני הנתונים עשויים לשלוח כמויות גדולות של נתונים או נתונים עם שגיאות, מה שיוצר בעיות במורד הזרם. ככל שהמורכבות של הנתונים גדלה ומקורות מגוונים יותר תורמים למערכת, הפלטפורמה הנתונית המרכזית עלולה להתקשות להתמודד עם העומס הגדל, מה שמוביל לקריסות וביצועים איטיים. הדרישה הגוברת לניסויים מהירים יכולה להעמיס על המערכת, ולהקשות על התאמה ובדיקות מהירות של רעיונות חדשים. זמני תגובה של נתונים יכולים להפוך לאתגר, לגרום לעיכובים בגישה ושימוש בנתונים, מה שמשפיע על קבלת החלטות ועל היעילות הכוללת.
הבדלים בין נופי נתונים תפעוליים ואנליטיים
בארכיטקטורת תוכנה, בעיות כמו בעלות מבודדת, שימוש בלתי ברור בנתונים, צינורות נתונים צמודים, ומגבלות מובנות עלולות לגרום לבעיות משמעותיות. בעלות מבודדת מתרחשת כאשר צוותים שונים עובדים בבידוד, מה שמוביל לבעיות בתיאום ולחוסר יעילות. חוסר בהבנה ברורה של איך יש להשתמש או לשתף נתונים יכול לגרום למאמצים כפולים ולתוצאות בלתי עקביות. צינורות נתונים צמודים, שבהם הרכיבים תלויים זה בזה יותר מדי, מקשים על התאמה או גידול של המערכת, מה שמוביל לעיכובים. לבסוף, מגבלות מובנות במערכת יכולות להאט את מסירת התכונות והעדכונים החדשים, מה שמפריע להתקדמות הכוללת. התמודדות עם נקודות לחץ אלו היא חיונית לתהליך פיתוח יעיל ומגיב יותר.
אתגרים עם נתונים גדולים
מערכות עיבוד אנליטי מקוון (OLAP) מארגנות מידע בדרך שמקלה על האנליסטים להתפתח באספקטים שונים של המידע. כדי להגיד תשובה על שאילתות, המערכות חייבות לשנות את המידע ה operative לפורמט מתאים לניתוח ולטפל בעלי היכולת הגדולה של מידע. מחסני מידע מסורתיים משתמשים בתהליכי ETL (הוצאה, שינוי, לודאי) לניהול זאת. טכנולוגיות המידע הענק, כמו Apache Hadoop, שיפרו מחסני המידע על ידי טיפול בבעיות הגידול והיותם פתוחים מקוריים, שאיפשרה לכל חברה להשתמש בהם כל עוד הם יכולים לנהל את התשתית. האדום הזה הציג גישה חדשה על ידי אישור למידע לא מבנים או בעל מבנה חלקי במקום לוקח מבנה פתוח מראש. הגמישות הזו, בה המידע יכול להיות כתוב בלי סכם מקודם ולהיות מבנה לאחר מכן בזמן השאילתות, הפך את העבודת המהנדסים במידע קלה יותר לטפל במידע ולהיות משולב. אימוץ Hadoop היה לרוב אומר יצירת צוות מידע נפרד: מהנדסי המידע טיפלו בניצול המידע, מדעני המידע ניהלו את הניקוי והשינוי המבנה, ואנליסטי המידע ביצעו אנליציות. ההגדרה הזו לפעמים הובילה לבעיות בגלל התקשורת מוגבלת בין הצוות המידע לבין מפתחי היישומים, בעיקר במטרה למנוע השפעה על מערכות הפייצוח.
בעיה 1: בעיות עם
הנתונים המשמשים לניתוח קשורים בקשר הדוק למבנה המקורי שלהם, מה שיכול להיות בעייתי במודלים מורכבים שמתעדכנים בתדירות גבוהה. שינויים במודל הנתונים משפיעים על כל המשתמשים, מה שהופך אותם לפגיעים לשינויים אלה, במיוחד כאשר המודל כולל טבלאות רבות.
בעיה 2: נתונים רעים, עלויות התעלמות מהבעיה
נתונים רעים לרוב לא מתגלים עד שהם גורמים לבעיות בסכימה, מה שמוביל לבעיות כמו סוגי נתונים שגויים. מכיוון שהאימות מתעכב לעיתים קרובות עד סוף התהליך, נתונים רעים יכולים להתפשט בצינורות, מה שמוביל לתיקונים יקרים ולפתרונות לא עקביים. נתונים רעים יכולים להוביל להפסדים עסקיים משמעותיים, כמו שגיאות בחשבוניות שיכולות לעלות מיליונים. מחקרים מצביעים על כך שנתונים רעים עולים לעסקים טריליונים בשנה, ומבזבזים זמן ניכר לעובדי ידע ולמדעני נתונים.
בעיה 3: חוסר בעלות יחידה
מפתחי יישומים, שהם מומחים במודל נתוני המקור, לרוב אינם מתקשרים מידע זה לצוותים אחרים. אחריותם לרוב מסתיימת בגבולות היישום ומאגרי הנתונים שלהם. מהנדסי נתונים, שמנהלים את חילוץ והעברת הנתונים, עובדים לעיתים קרובות באופן תגובתי ויש להם שליטה מוגבלת על מקורות הנתונים. אנליסטי נתונים, שמרוחקים מאוד מהמפתחים, נתקלים באתגרים עם הנתונים שהם מקבלים, מה שמוביל לבעיות תיאום ולצורך בפתרונות נפרדים.
בעיה 4: חיבורים מותאמים אישית של נתונים
בארגונים גדולים, צוותים שונים עשויים להשתמש באותם נתונים אך ליצור תהליכים משלהם לניהולם. זה מוביל לעותקים מרובים של נתונים, כל אחד מנוהל באופן עצמאי, ויוצר בלאגן מסובך. קשה לעקוב אחרי עבודות ETL ולוודא איכות נתונים, מה שמוביל לאי דיוקים בגלל גורמים כמו בעיות סנכרון ומקורות נתונים פחות בטוחים. גישה זו מבזבזת זמן, כסף והזדמנויות.
Data mesh פותר בעיות אלו על ידי טיפול בנתונים כמוצר עם סכמות ברורות, תיעוד וגישה מתוקננת, מה שמקטין סיכוני נתונים רעים ומשפר דיוק ויעילות נתונים.
Data Mesh: גישה מודרנית
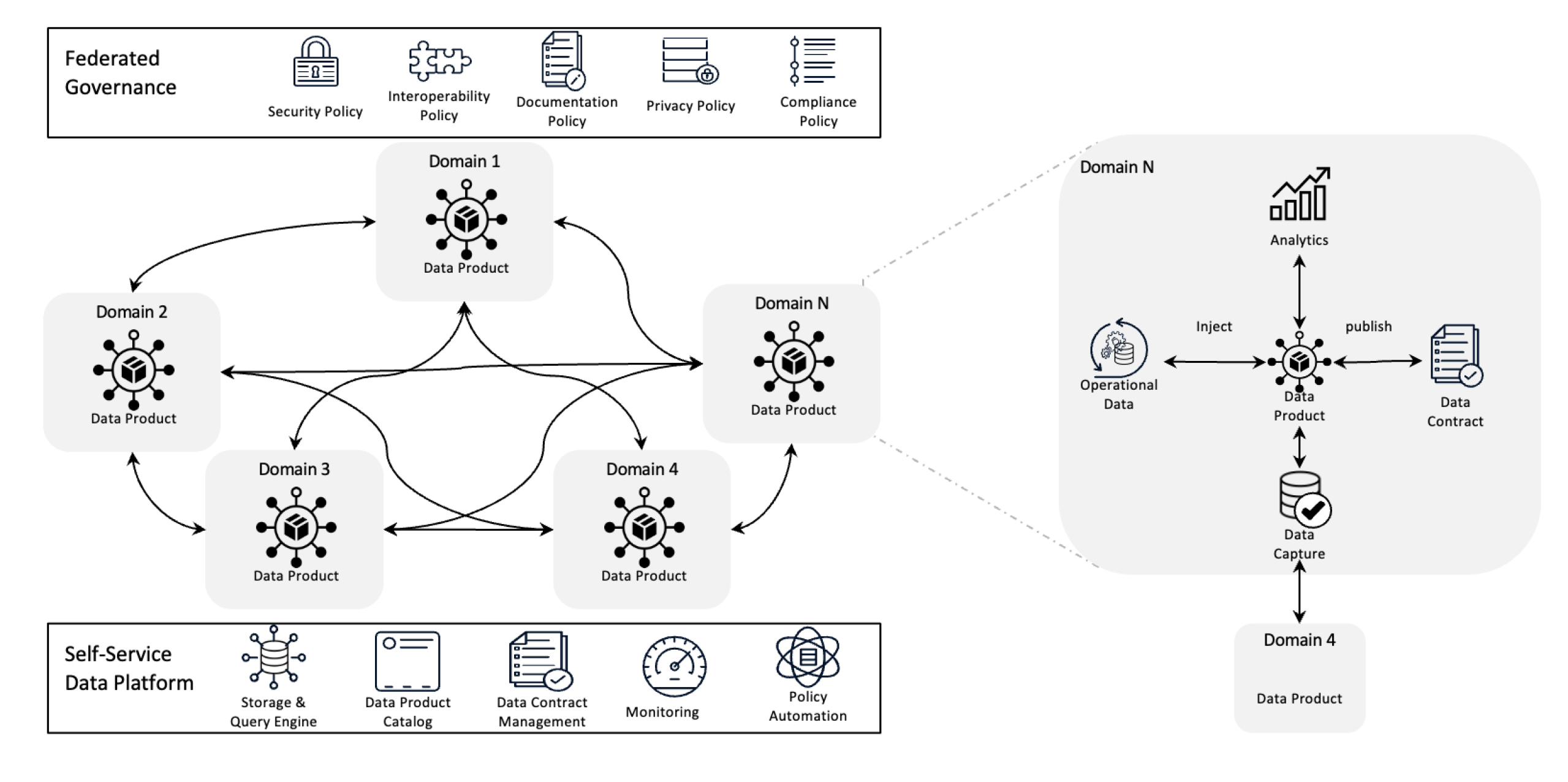
ארכיטקטורת Data Mesh
Data mesh מגדיר מחדש ניהול נתונים על ידי העברת הבעלות לצוותים וטיפול בנתונים כמוצר, עם תשתית לשירות עצמי. שינוי זה מעצים צוותים לקחת שליטה מלאה על הנתונים שלהם בעוד שממשל פדרלי מבטיח איכות, התאמה וסקלביליות בכל הארגון.
במילים פשוטות, זהו מסגרת ארכיטקטונית שתוכננה לפתור אתגרי נתונים מורכבים באמצעות בעלות מבוזרת ושיטות מבוזרות. הוא משמש לשילוב נתונים מתחומי עסקים שונים לצורך אנליטיקה מקיפה של נתונים. הוא גם מבוסס על מדיניות חזקה של שיתוף נתונים וניהול.
מטרות ה-Data Mesh
דאטה מש עוזר לארגונים שונים לקבל תובנות ערך בקנה מידה גדול; בקיצור, טיפול בנוף נתונים המשתנה ללא הרף, מספר הולך וגדל של מקורות נתונים ומשתמשים, מגוון התמרות הנתונים הנדרשות, והצורך להסתגל במהירות לשינויים.
דאטה מש פותר את כל הבעיות הנ"ל על ידי הלאמת שליטה, כך שצוותים יכולים לנהל את הנתונים שלהם מבלי שהם ייבודדו במחלקות נפרדות. גישה זו משפרת את הסקלביליות על ידי חלוקת עיבוד הנתונים והאחסון, מה שעוזר למנוע האטות במערכת מרכזית יחידה. היא מאיצה תובנות על ידי אפשרות לצוותים לעבוד ישירות עם הנתונים שלהם, מה שמפחית עיכובים שנגרמים על ידי המתנה לצוות מרכזי. כל צוות לוקח אחריות על הנתונים שלו, מה שמעלה את האיכות והעקביות. על ידי שימוש במוצרי נתונים קלים להבנה ובכלים לשירות עצמי, דאטה מש מבטיח שכל הצוותים יוכלו לגשת ולנהל את הנתונים שלהם במהירות, מה שמוביל לפעולות מהירות ויעילות יותר והתאמה טובה יותר לצרכים העסקיים.
עקרונות מפתח של דאטה מש
- בעלות נתונים הלאמתית: צוותים מחזיקים ומנהלים את מוצרי הנתונים שלהם, מה שהופך אותם לאחראים על איכותם וזמינותם.
- נתונים כמוצר: נתונים מטופלים כמו מוצר עם גישה מתוקנת, גרסאות והגדרות סכמה, מה שמבטיח עקביות וקלות שימוש בין מחלקות.
- ממשל פדרלי: מדיניות מקובלת כדי לשמור על שלמות הנתונים, אבטחה ועמידה בתקנים, תוך אפשרות לבעלות הלאמתית.
- תשתית עצמית-שירות: לצוותים יש גישה לתשתית בקנה מידה שתומכת בקליטה, בעיבוד ובשאילתת נתונים ללא צווארי בקבוק או תלות בצוות נתונים מרכזי.
כיצד עוזרים אירועים למערך הנתונים?
אירועים עוזרים למערך הנתונים על ידי אפשור שיתוף ועדכון נתונים בזמן אמת בין חלקים שונים של המערכת. כאשר משהו משתנה באזור אחד, אירוע מודיע לאזורים אחרים על כך, כך שכולם נשארים מעודכנים בלי צורך בחיבורים ישירים. זה הופך את המערכת גמישה ובקנה מידה גדול יותר מכיוון שהיא יכולה לטפל בהרבה נתונים ולהסתגל לשינויים בקלות. אירועים גם הופכים את מעקב השימוש והניהול של הנתונים לקל יותר, ומאפשרים לכל צוות לטפל בנתונים שלו ללא תלות באחרים.
לבסוף, בואו נסתכל על האדריכלות של מערך הנתונים המונע על ידי אירועים.
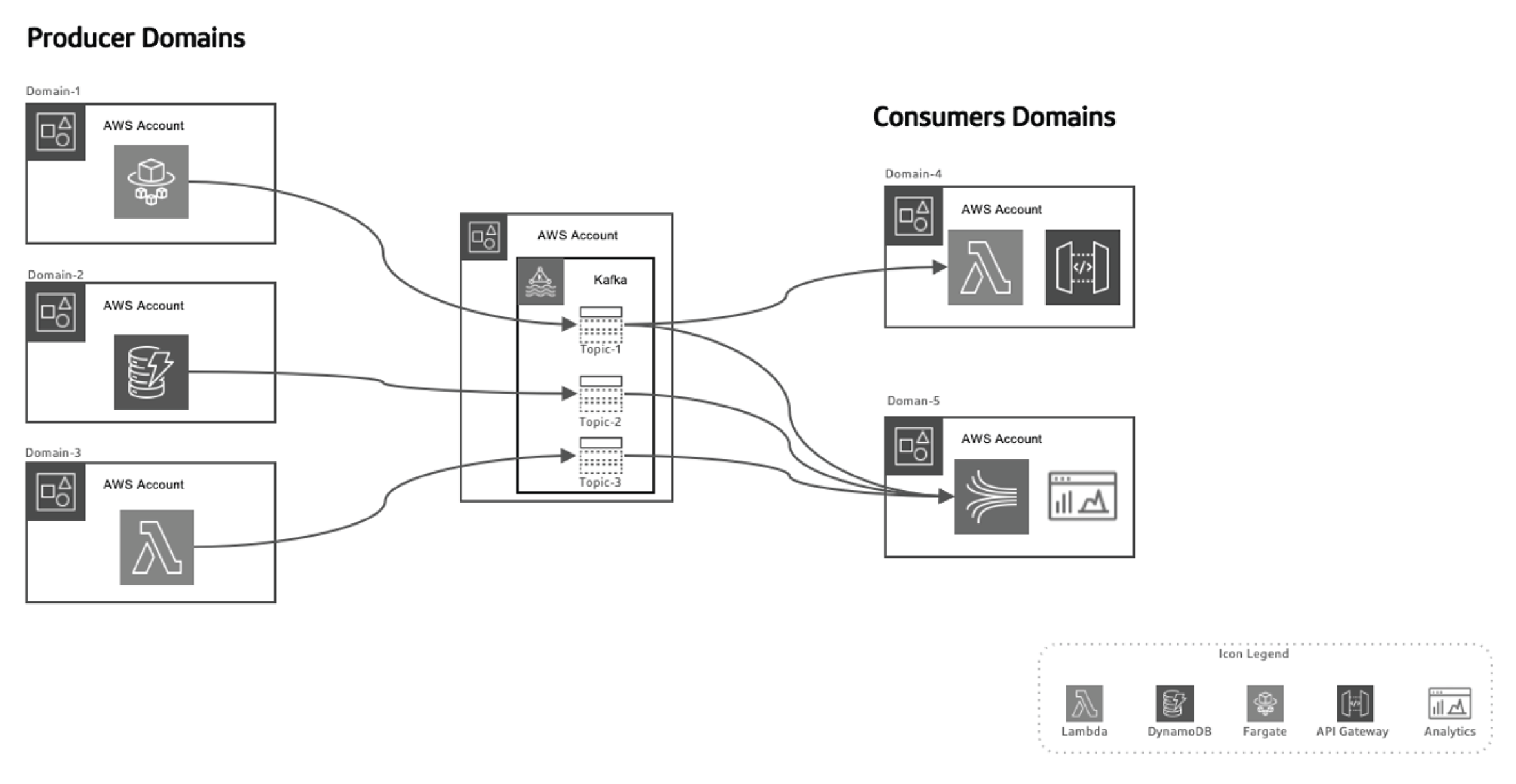
הגישה המונעת על ידי אירועים הזו מאפשרת לנו להפריד בין יוצרי הנתונים לבין צרכני הנתונים, מה שהופך את המערכת גמישה יותר ובקנה מידה גדול יותר שכן תחומים מתפתחים לאורך זמן ללא צורך בשינויים משמעותיים באדריכלות. יוצרי האירועים אחראים על יצירת אירועים, שנשלחים לאחר מכן למערכת נתונים בנתיב. פלטפורמת הזרמה מבטיחה שאירועים אלה מסופקים באופן מהימן. כאשר שירות מיקרו או מאגר נתונים מפרסם אירוע חדש, הוא נשמר בנושא ספציפי. זה מפעיל את המאזינים בצד הצרכן, כמו פונקציות Lambda או Kinesis, לעבד את האירוע ולהשתמש בו לפי הצורך.
ניצול AWS לאדריכלות מערך נתונים מונעת אירועים
AWS מציעה חבילת שירותים שמשלימים בצורה מושלמת את המודל של רשת נתונים מבוססת אירועים, ומאפשרת לארגונים להגדיל את תשתית הנתונים שלהם, להבטיח אספקת נתונים בזמן אמת, ולשמור על רמות גבוהות של ממשל וביטחון.
כאן ניתן לראות כיצד שירותי AWS שונים מתאימים לארכיטקטורה הזו:
AWS Kinesis ל-Real-Time Event Streaming
ברשת נתונים מבוססת אירועים, זרימת נתונים בזמן אמת היא אלמנט חיוני. AWS Kinesis מספקת את היכולת לאסוף, לעבד ולנתח נתונים בזמן אמת בקנה מידה גדול.
Kinesis מציעה מספר רכיבים:
- Kinesis Data Streams: אסוף אירועים בזמן אמת ועיבודם במקביל עם מספר צרכנים.
- Kinesis Data Firehose: מספקת זרימת אירועים ישירות ל-S3, Redshift, או Elastic search לעיבוד וניתוח נוספים.
- Kinesis Data Analytics: מעבדת נתונים בזמן אמת כדי לגזור מסקנות בזמן, מה שמאפשר לולאות משוב מיידיות בצינורות עיבוד נתונים.
AWS Lambda לעיבוד אירועים
AWS Lambda הוא עמוד השדרה של עיבוד אירועים ללא שרת בארכיטקטורת רשת הנתונים. עם יכולתו להתכווץ באופן אוטומטי ולעבד זרמי נתונים נכנסים ללא צורך בניהול שרת,
Lambda הוא בחירה אידיאלית ל:
- עיבוד זרימות Kinesis בזמן אמת
- קריאה לבקשות API Gateway בתגובה לאירועים מסוימים
- אינטראקציה עם DynamoDB, S3, או שירותי AWS אחרים לאחסון, עיבוד או ניתוח נתונים
AWS SNS ו-SQS להפצת אירועים
שירות ההתרעות הפשוט של AWS (SNS) פועל כמערכת השדרה העיקרית לאירועים, שולחת התרעות בזמן אמת דרך מערכות מפורטות.שירות המסרים הפשוט של AWS (SQS) מאפשר שהמסרים בין שירותים נפרדים מועברים באמון, אפילו במקרה של כשל חלקים במערכת. השירותים האלה מאפשרים למיקרוסרבים נפרדים להתאבק אחד עם השני בלי תלות ישירה, וזה מוביל למערכת המשך להיות מסוגלת להתארח ולהיות עמידה לכשלונות.
DynamoDB של AWS לניהול מידע בזמן אמת
בארכיטקטורות מאופיות, DynamoDB מספק בסיס נתונים נוסף ובעל latency נמוך, שיכול לאחסן מידע על אירועים בזמן אמת, וזה מועיל לשימור את התוצאות של ערוצי עיבוד מידע. הוא מספק את הדפוס המילוטים החוצה, בו האירועים הנולדים מהיישומון אחסנים בDynamoDB ונצרכים על ידי שירות הזרם (למשל, Kinesis או Kafka).
AWS Glue לספרד מאגר נתונים ושירות עיבוד תערובת
AWS Glue מציע ספרד מאגר נתונים ושירות עיבוד תערובת שמנוהל באופן מלאה עבור ממשל נתונים מובנה במערכת הנתונים. Glue עוזר לספרד, להכין ולשנות נתונים במגוון האזורים המפורטים, ומובטח את הגיוון, הממשל וההיתוך ברחבי הארגון.
AWS Lake Formation ו-S3 עבור אגני מידע
בעוד ארכיטקטורת מערך המידע מתרחקת מאגרי מידע מרכזיים, S3 ועיצוב האגרת הירח של AWS משחקים תפקיד קריטי באחסון, בטיחת וקטגוריזציית המידע שזורם בין תחומים שונים, ומוודאים אחסון לטווח הארוך, ממשל והגידול בהגידול.
מערך המידע מונע על ידי אירועים בעצם עם AWS וPython
מייצר אירועים: AWS Kinesis + Python
בדוגמה זו, אנחנו משתמשים ב-AWS Kinesis כדי לזרם אירועים בזמן התייחסות למשתמש חדש:
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')
עיבוד אירועים: AWS Lambda + Python
הפונקצייה הזו מצטלבת אירועים של Kinesis ומעבדת אותם בזמן אמת.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")
מסקנה
באמצעות שימוש בשירותים AWS כמו Kinesis, Lambda, DynamoDB וGlue, ארגונים יכולים להגיע לפוטנציאל המלא של מערך המידע מונע על ידי אירועים. הארכיטקטורה הזו מעניקה גילויים בזמן אמת, סקלטות ואגיליה, ומוודאה שארגונים נשארים מתחרים בשדה המידע המתפתח בקצב גבוה היום. אימוץ מערך המידע המונע על ידי אירועים הוא לא רק שיפור טכני אלא אמצעי אסטרטגי עבור העסקים שרוצים לשגשג בעידן המידע הגדול.
Source:
https://dzone.com/articles/event-driven-data-mesh-architecture-with-aws