













Les architectures modernes natives du cloud nécessitent des solutions de traitement des journaux robustes, évolutives et sécurisées pour surveiller les applications distribuées. Cette étude présente une solution hybride pour la collecte, l’agrégation et l’analyse des journaux utilisant Azure Kubernetes Service (AKS) pour la génération de journaux, Fluent Bit pour la collecte des journaux, Azure EventHub pour l’agrégation intermédiaire, et Splunk déployé sur un cluster Apache CloudStack sur site pour un indexage et une visualisation complets des journaux.
Nous détaillons la conception, la mise en œuvre et l’évaluation du système, démontrant comment cette architecture prend en charge un traitement des journaux fiable et évolutif pour des charges de travail natives du cloud tout en conservant le contrôle des données sur site.
Introduction
Les solutions de journalisation centralisée sont devenues indispensables. Les applications modernes, en particulier celles construites sur des architectures de microservices, génèrent d’énormes quantités de journaux, souvent dans des formats divers et provenant de multiples sources. Ces journaux sont la clé pour surveiller la performance des applications, diagnostiquer des problèmes et assurer la fiabilité globale du système. Cependant, la gestion de tels volumes élevés de données de journaux pose des défis significatifs, en particulier dans des environnements cloud hybrides qui s’étendent à la fois sur des infrastructures sur site et basées sur le cloud.
Les solutions de journalisation traditionnelles, bien qu’efficaces pour les applications monolithiques, ont du mal à évoluer sous les exigences des architectures basées sur des microservices. La nature dynamique des microservices, caractérisée par des déploiements indépendants et des mises à jour fréquentes, produit un flux continu de journaux, chacun variant en format et en structure. Ces journaux doivent être ingérés, traités et analysés en temps réel pour fournir des informations exploitables. De plus, alors que les applications fonctionnent de plus en plus dans des environnements hybrides, garantir la sécurité et la protection des données personnelles (PII) devient primordial, compte tenu des exigences variées en matière de conformité et de réglementation.
Ce document présente une solution complète qui répond à ces défis en tirant parti des capacités combinées des ressources Azure et Apache CloudStack. En intégrant la scalabilité et les capacités d’analyse d’Azure avec la flexibilité et le coût-efficacité de l’infrastructure sur site de CloudStack, cette solution offre une approche robuste et unifiée pour la journalisation centralisée.
Revue de la littérature
La collecte centralisée des journaux dans les microservices fait face à des défis tels que la latence réseau, les formats de données divers et la sécurité à travers plusieurs couches. Bien que des agents légers comme Fluent Bit et FluentD soient largement utilisés, le transport efficace des journaux reste un défi.
Des solutions telles que la pile ELK et Azure Monitor offrent un traitement centralisé des journaux, mais impliquent généralement des mises en œuvre uniquement cloud ou uniquement sur site, ce qui limite la flexibilité dans les déploiements hybrides. Les solutions de cloud hybride permettent aux organisations de tirer parti de la scalabilité du cloud tout en conservant le contrôle sur les données sensibles dans les environnements sur site. Les pipelines hybrides de traitement des journaux, en particulier ceux utilisant des technologies de diffusion d’événements, répondent au besoin de transport et d’agrégation de journaux évolutifs.
Architecture du système
L’architecture, illustrée ci-dessous, intègre Azure EventHub et AKS avec Apache CloudStack et Splunk sur site. Chaque composant est optimisé pour un traitement efficace des journaux et un transfert sécurisé des données entre les environnements.
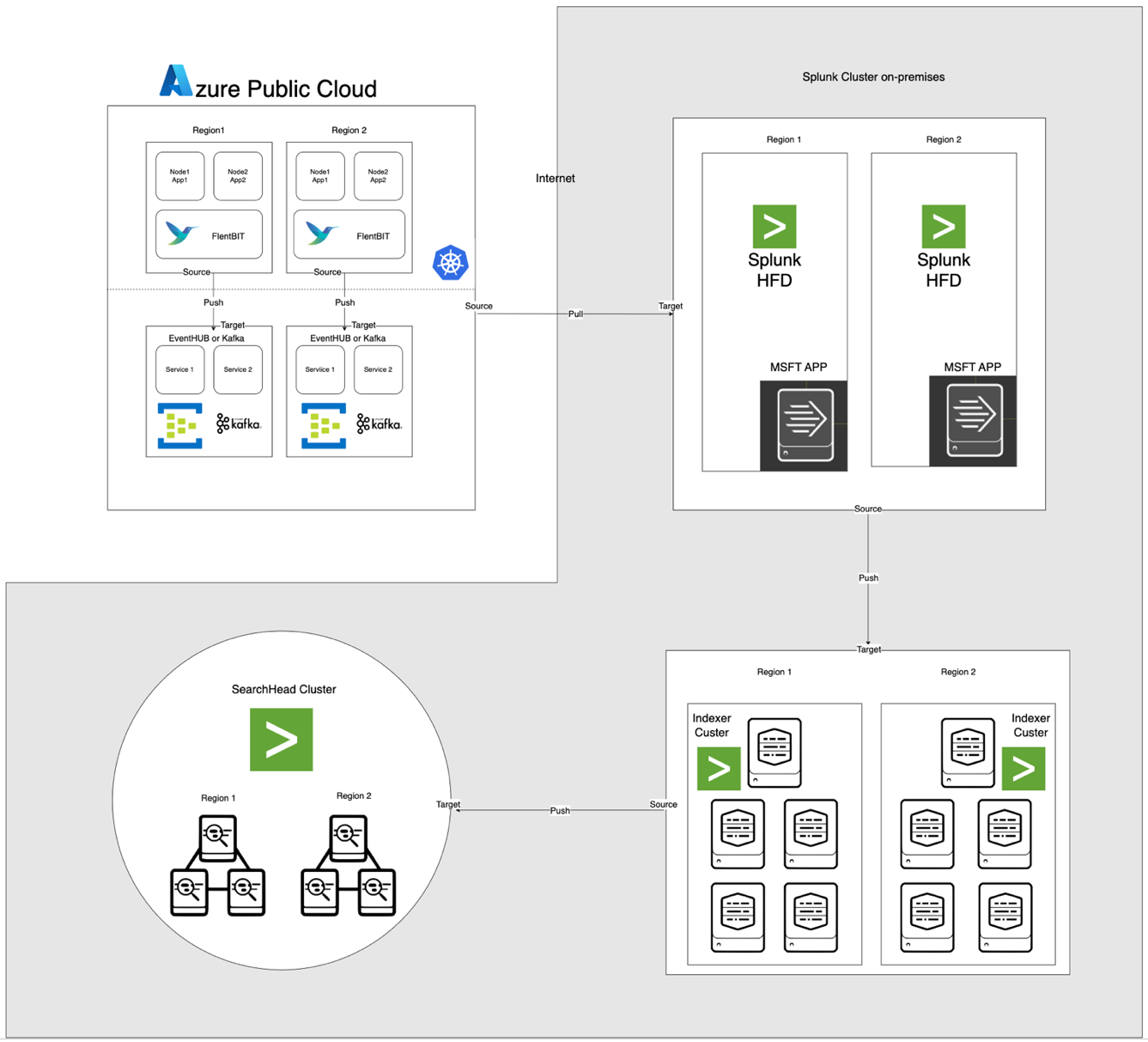
Description des composants
- AKS : Héberge des applications conteneurisées et génère des journaux accessibles via la couche d’agrégation de journaux de Kubernetes.
- Fluent Bit : Déployé en tant que DaemonSet, collecte les journaux des nœuds AKS. Chaque instance de Fluent Bit capture les journaux de /var/log/containers, les filtre et les transfère au format JSON vers EventHub.
- Azure EventHub : Sert de courtier de messages à haut débit, agrégeant les journaux de Fluent Bit et les stockant temporairement jusqu’à ce qu’ils soient récupérés par le Splunk Heavy Forwarder.
- Apache Kafka: Agit comme un pont fiable entre Fluent Bit et Splunk. Fluent Bit transfère les journaux vers Kafka en utilisant son plugin de sortie Kafka, où les journaux sont stockés et traités temporairement. Splunk consomme ensuite les journaux de Kafka en utilisant des connecteurs comme le connecteur Splunk Sink pour Kafka Connect ou des scripts personnalisés, garantissant une architecture évolutive et découplée.
- Splunk Heavy Forwarder (HF): Installé dans Apache CloudStack, le Heavy Forwarder récupère les journaux d’Azure EventHub en utilisant le Add-on Splunk pour les services cloud Microsoft. Cet add-on fournit une intégration transparente, permettant au Heavy Forwarder de se connecter de manière sécurisée à EventHub, de récupérer les journaux en quasi temps réel et de les transformer si nécessaire avant de les transmettre à l’indexeur de Splunk pour le stockage et le traitement
- Splunk sur Apache CloudStack: Fournit l’indexation des journaux, la recherche, la visualisation et la création d’alertes.
Flux de données
- Collecte de journaux dans AKS: Fluent Bit surveille les fichiers journaux dans /var/log/containers, filtre les journaux inutiles et ajoute des métadonnées à chaque journal (par ex. nom du conteneur, espace de noms).
- Transfert vers EventHub: Les journaux sont envoyés à EventHub via HTTPS en utilisant le plugin de sortie azure_eventhub de Fluent Bit, garantissant une transmission sécurisée des données.
- Apache Kafka: Les journaux d’AKS sont collectés par Fluent Bit, s’exécutant en tant que DaemonSet, qui les analyse et les transmet à Apache Kafka via son plugin de sortie Kafka. Kafka agit comme un tampon à haut débit, stockant et partitionnant les journaux pour la scalabilité. Splunk ingère ces journaux depuis Kafka en utilisant des connecteurs ou des scripts, permettant l’indexation, l’analyse et la surveillance en temps réel.
- Extraction des journaux avec Splunk Heavy Forwarder: Le Heavy Forwarder dans Apache CloudStack se connecte à EventHub en utilisant le SDK EventHubs et extrait les journaux, les transmettant à l’indexeur Splunk local pour le stockage et le traitement.
- Stockage et analyse dans Splunk: Les journaux sont indexés dans Splunk, permettant des recherches en temps réel, des visualisations de tableau de bord et des alertes basées sur les motifs de journal.
Méthodologie
Déploiement du DaemonSet Fluent Bit dans AKS
La configuration de Fluent Bit est stockée dans un ConfigMap et déployée en tant que DaemonSet. Voici la configuration étendue pour le DaemonSet Fluent Bit:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations:
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- Valider l'enregistrement entrant
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- Générer une clé unique pour la réassemblage basée sur le flux et le tag
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- Gérer les fragments de journal (logtag == 'P')
if record.logtag == 'P' then
-- Stocker le fragment dans l'état de réassemblage
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- Gérer la fin d'un journal fragmenté
if reassemble_state[reassemble_key] then
-- Combiner les fragments stockés avec le journal actuel
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- Effacer l'état stocké pour cette clé
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- Si aucune réassemblage n'est nécessaire, transmettre le journal tel quel
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(? - [INPUT] section spécifie la collecte des journaux à partir du répertoire /var/log/containers.
- [FILTER] section enrichit les journaux avec des métadonnées Kubernetes.
- [OUTPUT] section configure Fluent Bit pour transférer les journaux vers EventHub au format JSON.
Configuration d’Azure EventHub
EventHub nécessite un espace de noms, une instance spécifique d’EventHub, et un contrôle d’accès via des politiques d’accès partagé.
- Configuration de l’espace de noms et d’EventHub: Créez un espace de noms et une instance d’EventHub dans Azure, définissez une politique d’envoi, et récupérez la chaîne de connexion.
- Configuration pour un débit élevé: EventHub est configuré avec un nombre élevé de partitions pour supporter la scalabilité, le buffering, et des flux de données concurrents depuis Fluent Bit.
Configuration de Splunk Heavy Forwarder dans Apache CloudStack
Splunk Heavy Forwarder récupère les journaux depuis EventHub et les transfère vers l’indexeur de Splunk.
- Add-on pour les services cloud Microsoft: Installez l’add-on pour activer la connectivité à EventHub. Configurez l’entrée dans
inputs.conf:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- Traitement par lots: Définissez batch_size à 500 et interval à 30 secondes pour optimiser l’ingestion de données et réduire la fréquence des appels réseau.
Indexation et visualisation dans Splunk
- Enrichissement des données: Les journaux sont enrichis avec des métadonnées supplémentaires dans Splunk en utilisant des extractions de champs.
- Recherches et tableaux de bord: Les requêtes SPL permettent des recherches en temps réel, et les tableaux de bord personnalisés fournissent une visualisation des motifs de journaux.
- Alertes: Les alertes sont configurées pour se déclencher sur des motifs de journaux spécifiques, tels que des taux d’erreur élevés ou des avertissements répétés provenant de conteneurs spécifiques.
Performance et Scalabilité
Les tests montrent que le système peut gérer une ingestion de journaux à haut débit, avec les capacités de mise en mémoire tampon d’EventHub évitant la perte de données lors d’interruptions réseau. L’utilisation des ressources de Fluent Bit sur les nœuds AKS reste minimale, et l’indexeur de Splunk gère le volume de journaux efficacement avec des configurations d’indexation et de filtrage appropriées.
Sécurité
HTTPS est utilisé pour sécuriser la communication entre AKS et EventHub, tandis que Splunk HF utilise des clés sécurisées pour s’authentifier auprès d’EventHub. Chaque composant dans le pipeline met en œuvre des mécanismes de réessai pour maintenir l’intégrité des données.
Utilisation des ressources
- Fluent Bit a en moyenne 100-150 MiB de mémoire et 0,2-0,3 CPU sur les nœuds AKS.
- L’utilisation des ressources d’EventHub est ajustée dynamiquement en fonction des configurations de partition et de débit.
- La charge de Splunk HF est équilibrée grâce au traitement par lots, optimisant le transfert de données sans surcharger les ressources d’Apache CloudStack.
Fiabilité et Tolérance aux pannes
La solution utilise la mise en mémoire tampon d’EventHub pour assurer la rétention des journaux en cas de défaillance en aval. EventHub prend également en charge des politiques de réessai, améliorant ainsi davantage l’intégrité et la fiabilité des données.
Discussion
Avantages de l’architecture Cloud Hybride
Cette architecture offre une flexibilité, une évolutivité et une sécurité en combinant les services Azure avec un contrôle sur site. Elle exploite également les capacités de diffusion et de mise en mémoire tampon basées sur le cloud sans compromettre la souveraineté des données.
Limitations
Alors qu’EventHub offre une agrégation fiable des données, les coûts augmentent avec les unités de débit, ce qui rend essentiel d’optimiser les configurations de transfert de journaux. De plus, le transfert de données entre le cloud et les environnements sur site introduit une latence potentielle.
Applications Futures
Cette architecture pourrait être étendue en intégrant l’apprentissage automatique pour la détection d’anomalies dans les journaux ou en ajoutant la prise en charge de plusieurs fournisseurs de cloud pour étendre davantage le traitement des journaux et la résilience multi-cloud.
Conclusion
Cette étude démontre l’efficacité d’un pipeline de traitement des journaux hybride exploitant les ressources cloud et sur site. En intégrant Azure Kubernetes Service (AKS), Azure EventHub et Splunk sur Apache CloudStack, nous créons une solution évolutive et résiliente pour la gestion et l’analyse centralisées des journaux. L’architecture aborde les principaux défis du journalisation distribuée, notamment le débit élevé des données, la sécurité et la tolérance aux pannes.
L’utilisation de Fluent Bit en tant que collecteur de journaux léger dans AKS garantit une collecte de données efficace avec un minimum de surcharge des ressources. Les capacités de mise en tampon d’Azure EventHub permettent une agrégation fiable des journaux et un stockage temporaire, ce qui le rend bien adapté pour gérer un trafic de journaux variable et maintenir l’intégrité des données en cas de problèmes de connectivité. Le Splunk Heavy Forwarder et le déploiement Splunk dans Apache CloudStack permettent aux organisations de conserver le contrôle sur le stockage et l’analyse des journaux tout en bénéficiant de l’évolutivité et de la flexibilité des ressources cloud.
Cette approche offre des avantages significatifs pour les organisations nécessitant une configuration cloud hybride, tels qu’un contrôle accru sur les données, la conformité aux exigences de résidence des données et la flexibilité de s’adapter à la demande. Les travaux futurs peuvent explorer l’intégration de l’apprentissage automatique pour améliorer l’analyse des journaux, la détection automatisée des anomalies et l’expansion vers une configuration multi-cloud pour accroître la résilience et la polyvalence. Cette recherche fournit une architecture fondamentale adaptable aux besoins évolutifs des systèmes modernes et distribués dans des environnements d’entreprise.
Références
Azure Event Hubs et Kafka
Surveillance et journalisation hybrides
- Modèles de surveillance hybrides et multi-cloud
- Stratégies de surveillance de cloud hybride
Intégration Splunk
- Exploration Splunk des hubs d’événements Azure
- Données Azure dans la plateforme Splunk
Déploiement AKS
Source:
https://dzone.com/articles/bridging-cloud-and-on-premises-log-processing