













Dans le monde actuel axé sur les données, les entreprises doivent s’adapter aux changements rapides du mode de gestion, d’analyse et d’utilisation des données. Les systèmes centralisés traditionnels et les architectures monolithiques, qui étaient suffisants historiquement, ne répondent plus aux exigences croissantes des organisations qui ont besoin d’accès rapide et en direct aux données. Une architecture révolutionnaire dans ce domaine est l’architecture en nuage de données basée sur les événements, et quand elle est combinée aux services d’AWS, elle devient une solution robuste pour aborder les défis complexes de gestion des données.
Le dilemme des données
De nombreuses organisations font face à des défis importants lorsqu’elles comptent sur des architectures de données périmées. Ces défis incluent :
Un lac de données centralisé, monolithique et non spécifique au domaine
Un lac de données centraliséest un seul emplacement de stockage pour toutes vos données, ce qui facilite la gestion et l’accès mais peut entraîner des problèmes de performance si il n’est pas correctement échelonné. Un lac de données monolithique combine toutes les processus de traitement des données dans un seul système intégré, ce qui simplifie l’installation mais peut être difficile à écheloner et à maintenir. Un lac de données non spécifique au domaine est conçu pour stocker des données de n’importe quelle industrie ou source, offrant de la flexibilité et une large applicable mais peut être complexe à gérer et moins optimisé pour certaines utilisations.
Points de pression de l’échec de l’architecture traditionnelle
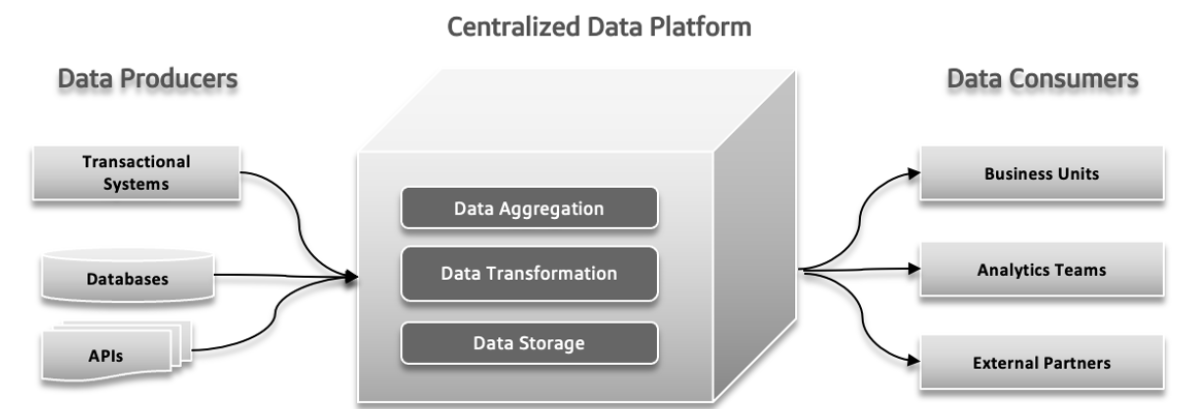
Dans les systèmes de données traditionnels, plusieurs problèmes peuvent survenir. Les producteurs de données peuvent envoyer de grandes quantités de données ou des données erronées, créant des problèmes en aval. Comme la complexité des données augmente et que plus de sources diverses contribuent au système, la plateforme de données centralisée peut éprouver des difficultés à gérer la charge croissante, ce qui peut entraîner des plantages et une performance lente. La demande croissante pour des expérimentations rapides peut dépasser le système, rendant difficile d’adapter rapidement et de tester de nouvelles idées. Les délais de réponse des données peuvent devenir un défi, entraînant des retards dans l’accès et l’utilisation des données, ce qui affecte la prise de décision et l’efficacité globale.
Divergence entre les paysages de données opérationnelles et analytiques
Dans l’architecture des logiciels, des problèmes tels que la propriété isolée, l’utilisation des données imprécise, des chaînes de données fortement couplées data pipelines et des limitations inhérentes peuvent provoquer des problèmes importants. La propriété isolée se produit quand des équipes différentes travaillent en isolement, entraînant des problèmes de coordination et des inefficiencies. Le manque d’une compréhension claire de la façon dont les données devraient être utilisées ou partagées peut entraîner des efforts dupliqués et des résultats incohérents. Des chaînes de données couplées, où les composants sont trop dépendants les uns des autres, font qu’il est difficile d’adapter ou d’échelle le système, entraînant des retards. Enfin, les limitations inhérentes au système peuvent ralentir la livraison de nouvelles fonctionnalités et mises à jour, entrave le progrès global. Rester à jour sur ces points de pression est crucial pour un développement plus efficient et réactif.
Défis liés aux Big Data
Les systèmes de Traitement Analytique en Ligne (OLAP) organisent les données de manière à faciliter l’exploration des différents aspects des données par les analystes. Pour répondre aux requêtes, ces systèmes doivent transformer les données opérationnelles en un format adapté à l’analyse et gérer de grandes quantités de données. Les warehouses de données traditionnels utilisent des processus ETL (Extraire, Transformer, Charger) pour gérer cela. Les technologies de big data, telles que Apache Hadoop, ont amélioré les warehouses de données en résolvant les problèmes de scalabilité et en étant open source, ce qui permettait à toute entreprise de les utiliser à condition de gérer l’infrastructure. Hadoop a introduit une nouvelle approche en permettant des données non structurées ou semi-structurées plutôt que deimposer un schéma strict d’emblée. Cette flexibilité, où les données pouvaient être écrites sans schéma prédéfini et structurées plus tard lors des requêtes, a simplifié le travail des ingénieurs des données et l’intégration des données. Adopter Hadoop signifiait souvent la formation d’une équipe de données distincte : les ingénieurs des données traitent l’extraction des données, les scientifiques des données gèrent la nettoyage et la restructuration, et les analystes des données effectuent l’analyse. Cette configuration pouvait parfois entraîner des problèmes en raison de la communication limitée entre l’équipe des données et les développeurs des applications, souvent pour éviter d’impacter les systèmes de production.
Problème 1 : Questions relatives aux frontières du modèle de données
Les données utilisées pour l’analyse sont étroitement liées à leur structure originale, ce qui peut poser des problèmes avec des modèles complexes et fréquemment mis à jour. Les modifications apportées à la structure des données affectent tous les utilisateurs, les rendant vulnérables à ces modifications, en particulier lorsque le modèle implique de nombreuses tables.
Problème 2 : Mauvaises Données, Les Coûts de l’Ignorance du Problème
Les mauvaises données passent souvent inaperçues jusqu’à ce qu’elles provoquent des problèmes dans un schéma, entraînant des problèmes tels que des types de données incorrects. Comme la validation est souvent retardée jusqu’à la fin du processus, les mauvaises données peuvent se propager dans les pipeline, entraînant des corrections coûteuses et des solutions incohérentes. Les mauvaises données peuvent entraîner des pertes significatives pour les entreprises, telles que des erreurs de facturation coûtant des millions. Des recherches indiquent que les mauvaises données coûtent aux entreprises des milliards chaque année, gaspillant une grande quantité de temps pour les travailleurs du savoir et les scientifiques des données.
Problème 3 : Manque d’Propriété Unique
Les développeurs d’applications, qui sont des experts dans le modèle de données source, ne communiquent généralement pas cette information aux autres équipes. Leurs responsabilités se terminent généralement à leurs frontières applications et bases de données. Les ingénieurs de données, qui gèrent l’extraction et le déplacement des données, travaillent souvent de manière réactive et contrôlent de manière limitée les sources de données. Les analystes de données, éloignés des développeurs, font face à des défis avec les données qu’ils reçoivent, entraînant des problèmes de coordination et le besoin de solutions distinctes.
Problème 4 : Connexions Personnalisées de Données
Dans les grandes organisations, plusieurs équipes peuvent utiliser les mêmes données mais créer leurs propres processus pour les gérer. Cela donne lieu à plusieurs copies des données, chacune gérée indépendamment, créant un chaos. Il devient difficile de suivre les jobs ETL et de s’assurer de la qualité des données, ce qui peut entraîner des inexactitudes dues à des facteurs tels que les problèmes de synchronisation et des sources de données moins sûres. Cette approche dispersée gaspille temps, argent et opportunités.
Le Data Mesh résout ces problèmes en traitant les données comme un produit avec des schémas clairs, de la documentation et un accès standardisé, réduisant les risques de mauvaises données et améliorant l’exactitude et l’efficacité des données.
Data Mesh : une approche moderne
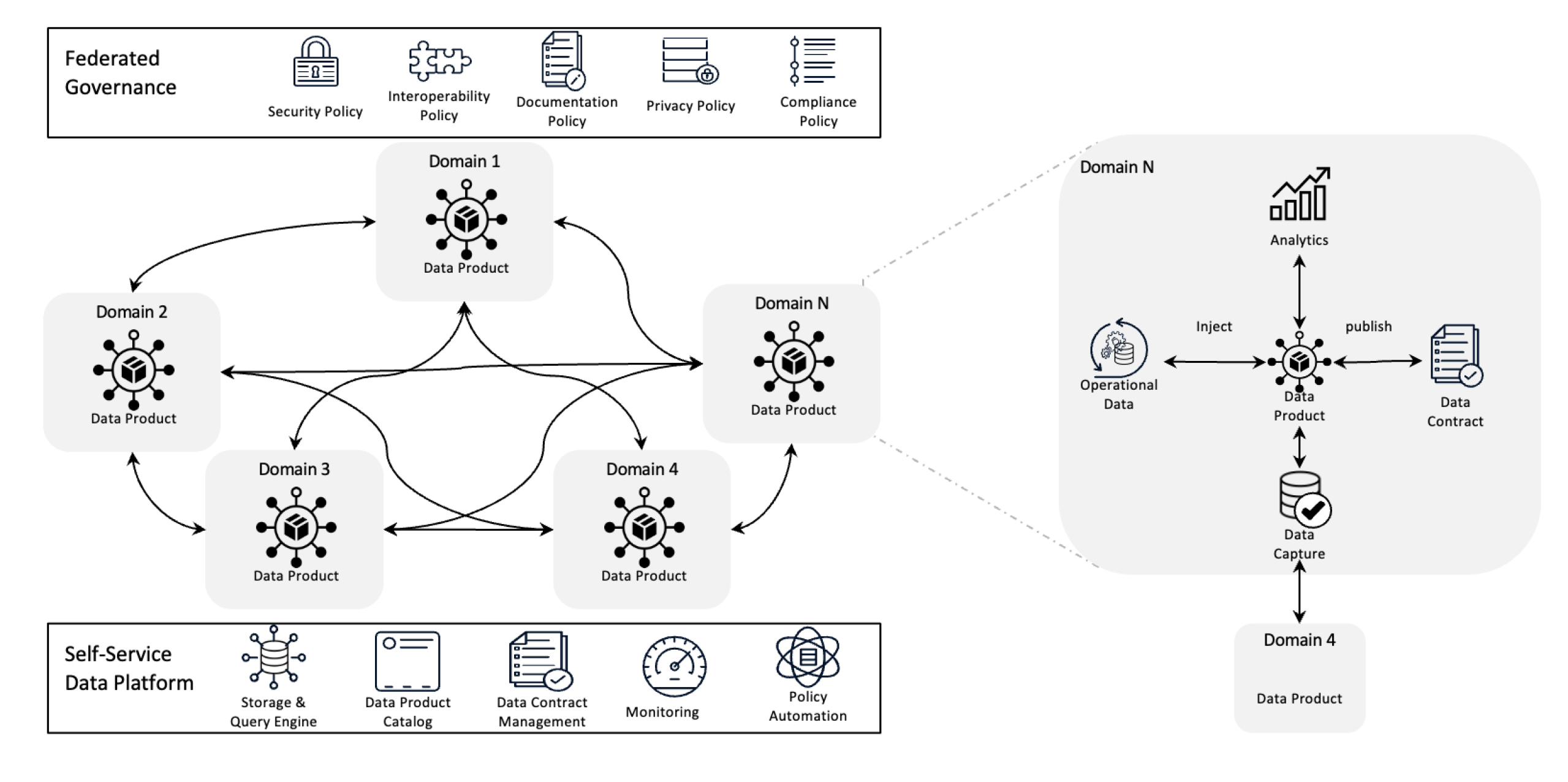
Architecture Data Mesh
Le Data Mesh redéfinit la gestion des données en décentralisant la propriété et en traitant les données comme un produit, soutenu par une infrastructure de self-service. Ce changement permet aux équipes de prendre pleinement le contrôle de leurs données tandis que la gouvernance fédérée assure la qualité, la conformité et la scalabilité à travers l’organisation.
En termes plus simples, il s’agit d’une structure architecturale conçue pour résoudre les défis complexes des données en utilisant une propriété décentralisée et des méthodes distribuées. Elle est utilisée pour intégrer les données de divers domaines commerciaux pour des analyses de données complètes. Elle est également construite à sur une forte politique de partage et de gouvernance des données.
Objectifs du Data Mesh
Le data mesh aide diverses organisations à obtenir des aperçus précieux de leurs données à une échelle large ; en bref, à gérer un paysage de données en constante évolution, un nombre croissant de sources de données et d’utilisateurs, la variété des transformations de données nécessaires et la nécessité de s’adapter rapidement aux changements.
Le data mesh résout tous les problèmes mentionnés ci-dessus en décentralisant le contrôle, ce qui permet aux équipes de gérer leurs propres données sans qu’elles soient isolées dans des départements distincts. Cette approche améliore la scalabilité en distribuant la traitement et le stockage des données, ce qui permet d’éviter des ralentissements dans un seul système central. Elle accélère les aperçus en permettant aux équipes de travailler directement avec leurs propres données, réduisant les délais causés par l’attente d’une équipe centrale. Chaque équipe est responsable de ses propres données, ce qui améliore la qualité et la cohérence. En utilisant des produits de données faciles à comprendre et des outils de self-service, le data mesh garantit que toutes les équipes peuvent rapidement accéder et gérer leurs données, ce qui conduit à des opérations plus rapides, plus efficientes et une meilleure alignmentement avec les besoins commerciaux.
Principes clés du Data Mesh
- Propriété décentralisée des données : Les équipes possèdent et gèrent leurs propres produits de données, ce qui les rend responsables de leur qualité et de leur disponibilité.
- Données comme produit : Les données sont traitées comme un produit avec un accès standardisé, une gestion de version et des définitions de schémas, garantissant une cohérence et une facilité d’utilisation across departments.
- Gouvernance fédérée : Des politiques sont mises en œuvre pour maintenir l’intégrité des données, la sécurité et le respect des obligations réglementaires, tout en permettant la propriété décentralisée.
- Infrastructure de self-service : Les équipes ont accès à une infrastructure scalable qui permet de traiter, de stocker et de rechercher des données sans les verrous ou sans dépendre d’une équipe de données centralisée.
Comment les Événements Aident-ils le Mesh des Données ?
Les événements aident le mesh des données en permettant à différentes parties du système de partager et de mettre à jour les données en temps réel. Lorsqu’une modification est effectuée dans une région donnée, un événement en informe les autres parties, ce qui permet à tout le monde de rester à jour sans besoin de connexions directes. Cela rend le système plus flexible et plus scalable parce qu’il peut gérer de grandes quantités de données et s’adapter facilement aux changements. Les événements rendent également plus facile de suivre l’utilisation et la gestion des données, et permettent à chaque équipe de gérer ses propres données sans dépendre des autres.
Enfin, examinons l’architecture du mesh des données basée sur les événements.
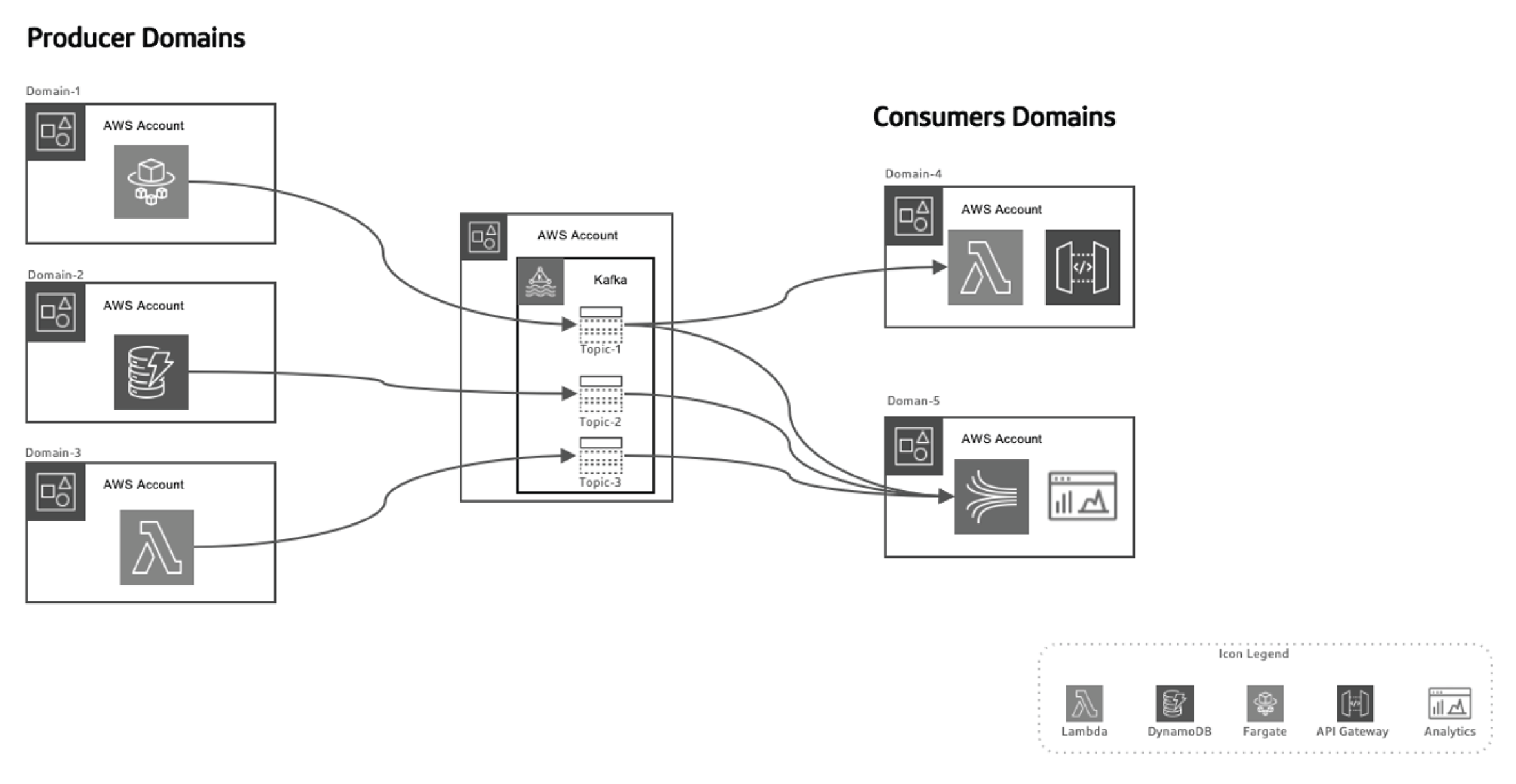
Cette approche basée sur les événements permet de séparer les producteurs de données des consommateurs, rendant le système plus scalable au fil du temps lorsque les domaines évoluent sans nécessiter de modifications majeures à l’architecture. Les producteurs sont responsables de la génération d’événements, qui sont ensuite envoyés vers un système de données en cours de transit. La plateforme de streaming garantit la réliabilité de l’acheminement de ces événements. Lorsqu’un microservice ou un magasin de données de production publie un nouvel événement, il est stocké dans un sujet spécifique. Cela déclenche alors des écoutes du côté des consommateurs, comme des fonctions Lambda ou Kinesis, pour traiter l’événement et l’utiliser à des fins spécifiques.
Exploiter AWS pour une Architecture de Mesh des Données Basée sur les Événements
AWS propose une suite de services qui complètent parfaitement le modèle de toile de données pilotée par les événements, permettant aux organisations de scaler leur infrastructure de données, d’assurer la livraison de données en temps réel et de maintenir des niveaux élevés de gouvernance et de sécurité.
Voici comment différents services AWS se prêtent à cette architecture :
AWS Kinesis pour le streaming d’événements en temps réel
Dans une toile de données pilotée par les événements, le streaming en temps réel est un élément crucial. AWS Kinesis offre la possibilité de collecter, traiter et analyser des données de streaming en temps réel à une échelle importante.
Kinesis propose plusieurs composants :
- Flux de données Kinesis : Intégrer des événements en temps réel et traiter-les concurremment avec plusieurs consommateurs.
- Flux de données Kinesis Firehose : Permet de livrer des flux d’événements directement vers S3, Redshift ou Elasticsearch pour un traitement et une analyse ultérieurs.
- Analytics des données Kinesis : Traite les données en temps réel pour tirer des inscriptions en direct, permettant des boucles de rétroaction immédiates dans les pipelines de traitement des données.
AWS Lambda pour le traitement d’événements
AWS Lambda est la structure de base du traitement d’événements sans serveur dans l’architecture de toile de données. Avec sa capacité à scaler automatiquement et à traiter des flux de données entrantes sans nécessiter la gestion de serveurs,
Lambda est un choix idéal pour :
- Traiter des flux Kinesis en temps réel
- Déclencher des requêtes de API Gateway en réponse à des événements spécifiques
- Interagir avec DynamoDB, S3 ou d’autres services AWS pour stocker, traiter ou analyser des données
AWS SNS et SQS pour la distribution d’événements.
AWS Simple Notification Service (SNS) agit en tant que système primaire de diffusion d’événements, en envoyant des notifications en temps réel sur des systèmes distribués. AWS Simple Queue Service (SQS) garantit la distribution fiable de messages entre des services déconnectés, même en cas de défaillance partielle du système. Ces services permettent à des microservices déconnectés d’interagir sans dépendances directes, garantissant ainsi que le système reste scalable et tolérant aux pannes.
AWS DynamoDB pour la gestion de données en temps réel
Dans les architectures décentralisées, DynamoDB fournit une base de données NoSQL scalable et à faible latence qui peut stocker des données d’événements en temps réel, ce qui en fait l’idéal pour stocker les résultats des chaînes de traitement de données. Elle supporte le pattern Outbox, où les événements générés par l’application sont stockés
dans DynamoDB et consommés par le service de streaming (par exemple, Kinesis ou Kafka).
AWS Glue pour le catalogue de données fédéré et l’extraction, transformation et chargement (ETL)
AWS Glue offre un service de catalogue de données et de ETL géré à 100 %, essentiel pour la gouvernance de données fédérées dans le data mesh. Glue aide à cataloguer, préparer et transformer les données dans les domaines distribués, garantissant la découverte, la gouvernance et l’intégration à travers l’organisation.
AWS Lake Formation et S3 pour les lacs de données.
Tandis que l’architecture du data mesh se détache de la centralisation des lacs de données, S3 et AWS Lake Formation jouent un rôle crucial dans le stockage, la sécurisation et le catalogage des données qui circulent entre divers domaines, assurant ainsi le stockage à long terme, la gouvernance et le respect des conformités.
Data Mesh Basé sur les Événements en Action avec AWS et Python
Producteur d’Événements : AWS Kinesis + Python
Dans cet exemple, nous utilisons AWS Kinesis pour faire le stream d’événements lors de la création d’un nouveau client :
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')
Traitement des Événements : AWS Lambda + Python
Cette fonction Lambda consomme les événements de Kinesis et les traite en temps réel.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")
Conclusion
En exploitant les services AWS tels que Kinesis, Lambda, DynamoDB et Glue, les organisations peuvent pleinement réaliser le potentiel de l’architecture de data mesh basé sur les événements. Cette architecture offre agilité, scalabilité et vues en temps réel, assurant ainsi aux organisations de rester concurrentielles dans le paysage des données en évolution rapide. Adopter une architecture de data mesh basée sur les événements n’est pas seulement une amélioration technique mais une imposition stratégique pour les entreprises qui souhaitent prospérer dans l’ère des grands volumes de données et des systèmes distribués.
Source:
https://dzone.com/articles/event-driven-data-mesh-architecture-with-aws