













Nota del editor: A continuación se presenta un artículo escrito y publicado en el Informe de Tendencias 2024 de DZone, Ingeniería de Datos: Enriqueciendo Pipelines de Datos, Expandiendo IA y Acelerando Análisis.
Este artículo explora las estrategias esenciales para aprovechar el flujo de datos en tiempo real para obtener insights accionables, mientras se futura-proof los sistemas a través de la automatización de IA y bases de datos vectoriales. Aborda las arquitecturas y herramientas en evolución que permiten a las empresas mantenerse ágiles y competitivas en un mundo impulsado por los datos.
Flujo de Datos en Tiempo Real: Evolución y Consideraciones Clave
El flujo de datos en tiempo real ha evolucionado desde el procesamiento por lotes tradicional, donde los datos se procesaban en intervalos que introducían retrasos, hasta manejar continuamente los datos a medida que se generan, permitiendo respuestas instantáneas a eventos críticos. Al integrar IA, automatización y bases de datos vectoriales, las empresas pueden mejorar aún más sus capacidades, utilizando insights en tiempo real para predecir resultados, optimizar operaciones y gestionar de manera eficiente conjuntos de datos a gran escala y complejos.
Necesidad de Flujo en Tiempo Real
Es necesario actuar sobre los datos tan pronto como se generan, especialmente en escenarios como la detección de fraude, el análisis de registros o el seguimiento del comportamiento del cliente. El streaming en tiempo real permite a las organizaciones capturar, procesar y analizar datos instantáneamente, lo que les permite reaccionar rápidamente a eventos dinámicos, optimizar la toma de decisiones y mejorar la experiencia del cliente en tiempo real.
Fuentes de Datos en Tiempo Real
Los datos en tiempo real provienen de varios sistemas y dispositivos que generan datos continuamente, a menudo en grandes cantidades y en formatos que pueden ser difíciles de procesar. Las fuentes de datos en tiempo real suelen incluir:
- Dispositivos IoT y sensores
- Registros de servidores
- Actividad de aplicaciones
- Publicidad en línea
- Eventos de cambio en bases de datos
- Flujos de clics en sitios web
- Plataformas de redes sociales
- Bases de datos transaccionales
Gestionar y analizar eficazmente estos flujos de datos requiere una infraestructura robusta capaz de manejar datos no estructurados y semiestructurados; esto permite a las empresas extraer información valiosa y tomar decisiones en tiempo real.
Desafíos Críticos en las Tuberías de Datos Modernas
Las tuberías de datos modernas enfrentan varios desafíos, incluyendo mantener la calidad de los datos, asegurar transformaciones precisas y minimizar el tiempo de inactividad de la tubería:
- Una mala calidad de los datos puede llevar a conclusiones erróneas.
- Las transformaciones de datos son complejas y requieren una escritura precisa.
- El frecuentes tiempo de inactividad interrumpe las operaciones, haciendo que los sistemas tolerantes a fallos sean esenciales.
Además, governance de datos es crucial para asegurar consistencia de datos y confiabilidad a través de los procesos. Escalabilidad es otro tema clave, ya que los管道 deben manejar volúmenes variables de datos, y el correcto monitoreo y alertas son vitales para evitar fallos inesperados y asegurar un funcionamiento suave.
Arquitecturas y Escenarios de Aplicaciones de Transmisión de Datos en Tiempo Real Avanzada
Esta sección demuestra las capacidades de los sistemas de datos modernos para procesar y analizar datos en movimiento, proporcionando a las organizaciones las herramientas para responder a eventos dinámicos en milisegundos.
Pasos para Construir un Pipeline de Datos en Tiempo Real
Para crear un pipeline de datos en tiempo real efectivo, es esencial seguir una serie de pasos estructurados que aseguren un flujo suave de datos, procesamiento y escalabilidad. La Tabla 1, compartida a continuación, detalla los pasos clave involucrados en la construcción de un pipeline de datos en tiempo real robusto:
Tabla 1. Pasos para construir un pipeline de datos en tiempo real
| step | activities performed |
|---|---|
| 1. Ingesta de datos | Configurar un sistema para capturar flujos de datos de diversas fuentes en tiempo real |
| 2. Procesamiento de datos | Limpiar, validar y transformar los datos para asegurar que estén listos para el análisis |
| 3. Procesamiento de streams | Configurar consumidores para extraer, procesar y analizar datos de manera continua |
| 4. Almacenamiento | Almacenar los datos procesados en un formato adecuado para el uso downstream |
| 5. Monitoreo y escalabilidad | Implementar herramientas para monitorear el rendimiento del pipeline y asegurarse de que pueda escalar con el aumento de las demandas de datos |
Herramientas de Streamming de Código Abierto Líderes
Para construir pipelines de datos en tiempo real robustos, hay varias herramientas de código abierto disponibles para la ingestión, almacenamiento, procesamiento y análisis de datos, cada una cumpliendo un papel crucial en la gestión y procesamiento eficiente de flujos de datos a gran escala.
Herramientas de código abierto para la ingestión de datos:
- Apache NiFi, con su última versión 2.0.0-M3, ofrece una escalabilidad mejorada y capacidades de procesamiento en tiempo real.
- Apache Airflow se utiliza para orquestar flujos de trabajo complejos.
- Apache StreamSets proporciona monitoreo y procesamiento continuo del flujo de datos.
- Airbyte simplifica la extracción y carga de datos, convirtiéndose en una excelente opción para gestionar diversas necesidades de ingestión de datos.
Herramientas de código abierto para el almacenamiento de datos:
- Apache Kafka se utiliza ampliamente para construir pipelines en tiempo real y aplicaciones de streaming debido a su alta escalabilidad, tolerancia a fallos y velocidad.
- Apache Pulsar, un sistema de mensajería distribuida, ofrece una fuerte escalabilidad y durabilidad, lo que lo hace ideal para manejar mensajería a gran escala.
- NATS.io es un sistema de mensajería de alto rendimiento, comúnmente utilizado en aplicaciones IoT y nativas de la nube, diseñado para arquitecturas de microservicios y ofrece comunicación ligera y rápida para necesidades de datos en tiempo real.
- Apache HBase, una base de datos distribuida construida sobre HDFS, proporciona una fuerte consistencia y un alto rendimiento, lo que lo hace ideal para almacenar grandes cantidades de datos en tiempo real en un entorno NoSQL.
Herramientas de código abierto para procesamiento de datos:
- Apache Spark destaca por su computación en memoria de clúster, proporcionando un procesamiento rápido tanto para aplicaciones batch como de streaming.
- Apache Flink está diseñado para el procesamiento distribuido de streams de alto rendimiento y admite trabajos batch.
- Apache Storm es conocido por su capacidad para procesar más de un millón de registros por segundo, lo que lo hace extremadamente rápido y escalable.
- Apache Apex ofrece un procesamiento unificado de flujos y lotes.
- Apache Beam proporciona un modelo flexible que funciona con varios motores de ejecución como Spark y Flink.
- Apache Samza, desarrollado por LinkedIn, se integra bien con Kafka y maneja el procesamiento de flujos con un enfoque en escalabilidad y tolerancia a fallos.
- Heron, desarrollado por Twitter, es una plataforma de análisis en tiempo real que es altamente compatible con Storm pero ofrece un mejor rendimiento y aislamiento de recursos, lo que lo hace adecuado para el procesamiento de flujos de alta velocidad a gran escala.
Herramientas de código abierto para análisis de datos:
- Apache Kafka permite un procesamiento de alto rendimiento y baja latencia de flujos de datos en tiempo real.
- Apache Flink ofrece un procesamiento de flujos potente, ideal para aplicaciones que requieren cálculos distribuidos y con estado.
- Apache Spark Streaming integrado con el ecosistema más amplio de Spark maneja datos en tiempo real y en lote dentro de la misma plataforma.
- Apache Druid y Pinot sirven como bases de datos analíticas en tiempo real, ofreciendo capacidades OLAP que permiten consultar grandes conjuntos de datos en tiempo real, lo que los hace particularmente útiles para paneles y aplicaciones de inteligencia de negocios.
Casos de Implementación
Las implementaciones del mundo real de pipelines de datos en tiempo real muestran las diversas formas en que estas arquitecturas impulsan aplicaciones críticas en diversas industrias, mejorando el rendimiento, la toma de decisiones y la eficiencia operativa.
Transmisión de Datos de Mercado Financiero para Sistemas de Trading de Alta Frecuencia
En sistemas de trading de alta frecuencia, donde los milisegundos pueden marcar la diferencia entre ganancias y pérdidas, se utilizan Apache Kafka o Apache Pulsar para la ingestión de datos de alta capacidad. Apache Flink o Apache Storm manejan el procesamiento de baja latencia para garantizar que las decisiones de trading se tomen de inmediato. Estos pipelines deben soportar una escalabilidad extrema y tolerancia a fallos, ya que cualquier tiempo de inactividad del sistema o retraso en el procesamiento puede llevar a perder oportunidades de trading o a pérdidas financieras.
Procesamiento de Datos de Sensores IoT y en Tiempo Real
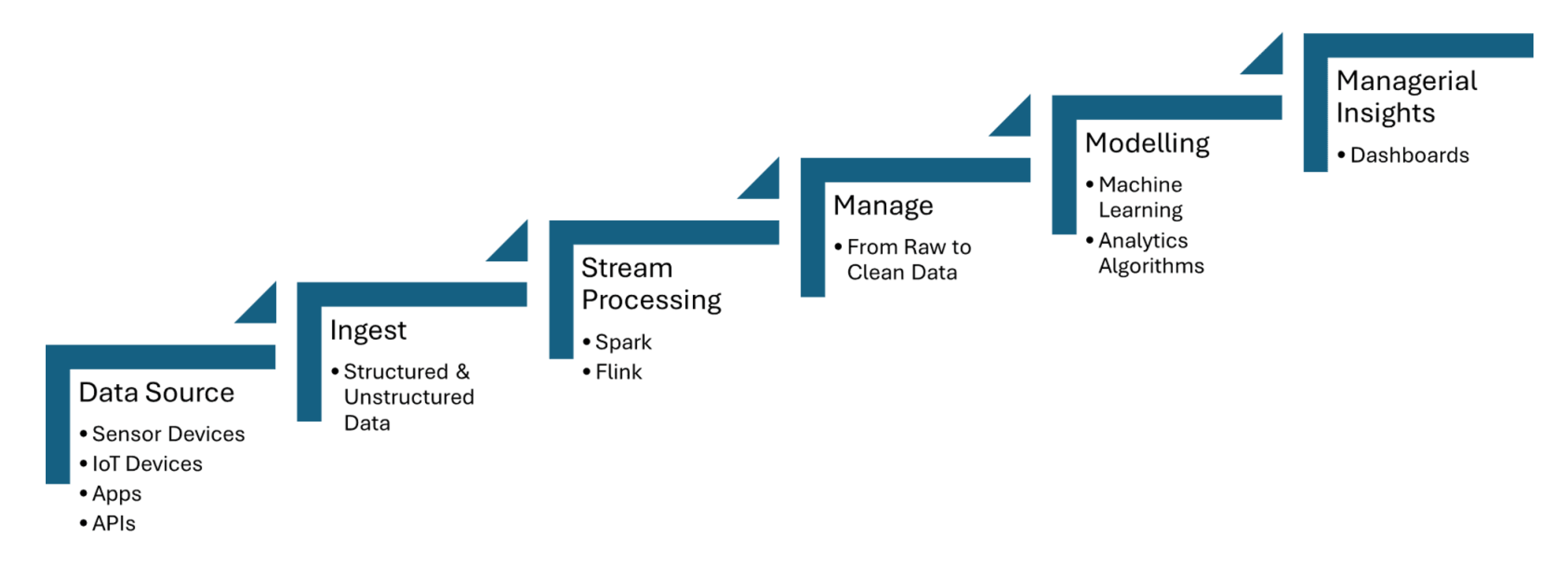
Las tuberías de datos en tiempo real ingieren datos de sensores IoT, que capturan información como temperatura, presión o movimiento, y luego procesan los datos con una latencia mínima. Apache Kafka se utiliza para manejar la ingesta de datos de sensores, mientras que Apache Flink o Apache Spark Streaming permiten el análisis en tiempo real y la detección de eventos. La Figura 1 compartida a continuación muestra los pasos del procesamiento de flujo para IoT desde las fuentes de datos hasta la representación en dashboards:
Figura 1. Procesamiento de flujo para IoT
Detección de Fraude desde el Flujo de Datos de Transacciones
Los datos de transacciones se ingieren en tiempo real utilizando herramientas como Apache Kafka, que maneja grandes volúmenes de datos en flujo desde múltiples fuentes, como transacciones bancarias o pasarelas de pago. Los marcos de trabajo de procesamiento de flujo como Apache Flink o Apache Spark Streaming se utilizan para aplicar modelos de aprendizaje automático o sistemas basados en reglas que detectan anomalías en los patrones de transacciones, como comportamientos de gasto inusuales o discrepancias geográficas.
Cómo la Automatización de IA Está Impulsando Tuberías Inteligentes y Bases de Datos Vectoriales
Los flujos inteligentes aprovechan el procesamiento de datos en tiempo real y las bases de datos vectoriales para mejorar la toma de decisiones, optimizar operaciones y mejorar la eficiencia de los entornos de datos a gran escala.
Automatización de la Pipeline de Datos
La automatización de la管道 de datos permite la gestión eficiente de tareas de ingesta, transformación y análisis a gran escala sin intervención manual. Apache Airflow asegura que las tareas se activan de manera automática en el momento adecuado y en la secuencia correcta. Apache NiFi facilita la gestión automática del flujo de datos, permitiendo la ingesta, transformación y enrutamiento de datos en tiempo real. Apache Kafka asegura que los datos se procesen de manera continua y eficiente.
Marco de Orquestación de Pipeline
Los marcos de orquestación de pipeline son esenciales para automatizar y gestionar flujos de trabajo de datos de manera estructurada y eficiente. Apache Airflow ofrece características como la gestión de dependencias y monitoreo. Luigi se centra en construir pipelines complejos de trabajos por lotes. Dagster y Prefect proporcionan gestión dinámica de pipelines y manejo mejorado de errores.
Pipelines Adaptativos
Los pipelines adaptativos están diseñados para ajustarse dinámicamente a los cambios en los entornos de datos, como las fluctuaciones en el volumen, estructura o fuentes de datos. Apache Airflow o Prefect permiten una respuesta en tiempo real automatizando las dependencias de las tareas y la programación basada en las condiciones actuales del pipeline. Estos pipelines pueden aprovechar marcos como Apache Kafka para la transmisión de datos escalable y Apache Spark para el procesamiento de datos adaptativo, asegurando un uso eficiente de los recursos.
Pipelines de Transmisión
Una pipeline de flujo en tiempo real para poblar una base de datos vectorial para la generación aumentada de recuperación en tiempo real (RAG) se puede construir completamente utilizando herramientas como Apache Kafka y Apache Flink. Los datos de flujo procesados se convierten luego en embeddings y se almacenan en una base de datos vectorial, lo que permite una búsqueda semántica eficiente. Esta arquitectura en tiempo real asegura que los modelos de lenguaje grandes (LLMs) tengan acceso a información actualizada y contextualmente relevante, mejorando la precisión y confiabilidad de las aplicaciones basadas en RAG, como chatbots o motores de recomendación.
Data Streaming como Data Fabric para IA Generativa
El flujo de datos en tiempo real permite la ingesta, procesamiento y recuperación en tiempo real de grandes cantidades de datos que los LLMs requieren para generar respuestas precisas y actualizadas. Mientras Kafka ayuda en el flujo, Flink procesa estos flujos en tiempo real, asegurando que los datos estén enriquecidos y contextualmente relevantes antes de ser alimentados en las bases de datos vectoriales.
El Camino a Seguir: blindar las Pipeelines de Datos para el Futuro
La integración de flujos de datos en tiempo real, la automatización con IA y las bases de datos vectoriales ofrece un potencial transformador para las empresas. Para la automatización con IA, integrar flujos de datos en tiempo real con marcos como TensorFlow o PyTorch permite la toma de decisiones en tiempo real y actualizaciones continuas de modelos. Para la recuperación de datos contextuales en tiempo real, utilizar bases de datos como Faiss o Milvus ayuda en búsquedas semánticas rápidas, que son cruciales para aplicaciones como RAG.
Conclusión
Las principales conclusiones incluyen el papel crítico de herramientas como Apache Kafka y Apache Flink para un flujo de datos escalable y de baja latencia, junto con TensorFlow o PyTorch para la automatización en tiempo real con IA, y FAISS o Milvus para búsquedas semánticas rápidas en aplicaciones como RAG. Asegurar la calidad de los datos, automatizar flujos de trabajo con herramientas como Apache Airflow, e implementar mecanismos robustos de monitoreo y tolerancia a fallos ayudará a las empresas a mantenerse ágiles en un mundo impulsado por datos y a optimizar sus capacidades de toma de decisiones.
Recursos adicionales:
- AI Automation Essentials de Tuhin Chattopadhyay, DZone Refcard
- Esenciales de Apache Kafka por Sudip Sengupta, DZone Refcard
- Introducción a los Modelos de Lenguaje de Gran Tamaño por Tuhin Chattopadhyay, DZone Refcard
- Introducción a las Bases de Datos Vectoriales por Miguel Garcia, DZone Refcard
Este es un extracto del Informe de Tendencias de DZone 2024,
Ingeniería de Datos: Enriqueciendo Pipelines de Datos, Expandiendo IA y Acelerando Análisis.
Source:
https://dzone.com/articles/the-data-pipeline-movement