













في عالم اليوم الذي يعتمد على البيانات، يجب على الشركات التكيف مع التغيرات السريعة في كيفية إدارة البيانات وتحليلها واستخدامها. الأنظمة المركزية التقليدية والهياكل الأحادية، على الرغم من كونها كافية تاريخياً، لم تعد تفي بمتطلبات المنظمات المتزايدة التي تحتاج إلى وصول أسرع وفي الوقت الفعلي إلى رؤى البيانات. إطار عمل ثوري في هذا المجال هو بنية شبكة البيانات المدفوعة بالأحداث، وعند دمجها مع خدمات AWS، تصبح حلاً قوياً لمعالجة تحديات إدارة البيانات المعقدة.
معضلة البيانات
تواجه العديد من المنظمات تحديات كبيرة عند الاعتماد على هياكل البيانات القديمة. تشمل هذه التحديات:
بحيرة بيانات مركزية، أحادية، وغير متخصصة في المجال
بحيرة البيانات المركزية هي موقع تخزين واحد لجميع بياناتك، مما يسهل إدارتها والوصول إليها ولكن قد يتسبب في مشاكل أداء إذا لم يتم توسيعها بشكل صحيح. بحيرة البيانات الأحادية تجمع جميع عمليات التعامل مع البيانات في نظام متكامل واحد، مما يبسط الإعداد ولكنه قد يكون صعب التوسيع والصيانة. بحيرة البيانات غير المتخصصة في المجال مصممة لتخزين البيانات من أي صناعة أو مصدر، مما يوفر مرونة وتطبيقات واسعة ولكن قد تكون معقدة في الإدارة وأقل تحسينًا للاستخدامات المحددة.
نقاط فشل الهندسة التقليدية
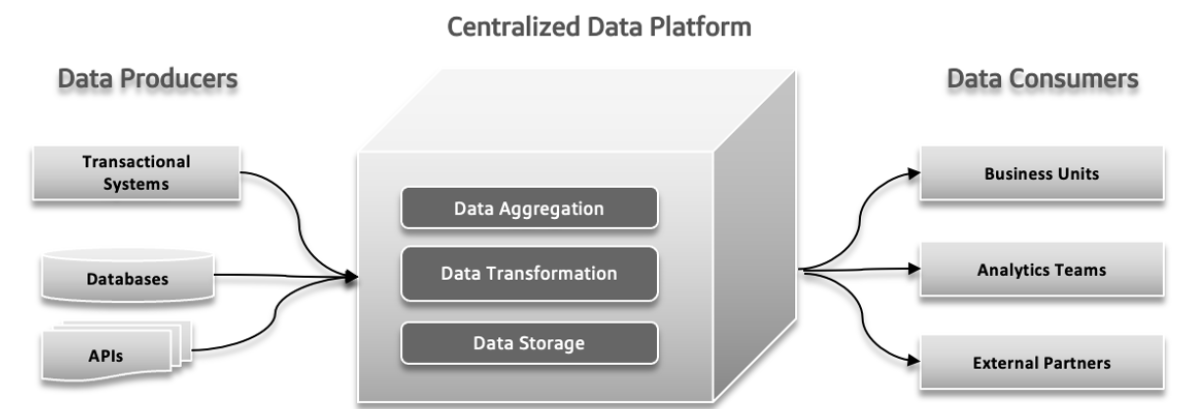
هناك العديد من المشاكل التي يمكن أن تحدث في أنظمة البيانات التقليدية. قد يرسل منتجو البيانات كميات كبيرة من البيانات أو بيانات بأخطاء، مما يخلق مشاكل في المراحل اللاحقة. مع زيادة تعقيد البيانات وإسهام مصادر أكثر تنوعًا في النظام، قد يصارع المنصة المركزية للبيانات في التعامل مع الحمل المتزايد، مما يؤدي إلى انهيارات وأداء بطيء. قد يؤدي الطلب المتزايد على التجريب السريع إلى إرهاق النظام، مما يجعل من الصعب التكيف بسرعة واختبار أفكار جديدة. قد تصبح أوقات استجابة البيانات تحديًا، مما يؤدي إلى تأخيرات في الوصول إلى البيانات واستخدامها، مما يؤثر على عملية صنع القرار والكفاءة الشاملة.
التباين بين بيئات البيانات التشغيلية والتحليلية
في معمارية البرمجيات، قد تسبب مشاكل مثل الملكية المنعزلة، وعدم وضوح استخدام البيانات، والأنابيب المرتبطة ارتباطًا وثيقًاأنابيب البيانات، والقيود الذاتية مشاكل كبيرة. تحدث الملكية المنعزلة عندما تعمل فرق مختلفة بشكل منعزل، مما يؤدي إلى مشاكل في التنسيق وعدم الكفاءة. قد ينتج عدم فهم واضح لكيفية استخدام أو مشاركة البيانات تكرار الجهود ونتائج متناقضة. تجعل الأنابيب المرتبطة ارتباطًا وثيقًا، حيث تعتمد المكونات على بعضها البعض بشكل كبير، من الصعب التكيف أو تطوير النظام، مما يؤدي إلى تأخيرات. أخيرًا، يمكن أن تبطئ القيود الذاتية في النظام تسليم الميزات والتحديثات الجديدة، مما يعيق التقدم الشامل. إن معالجة هذه نقاط الضغط أمر حاسم لعملية تطوير أكثر كفاءة واستجابة.
تحديات البيانات الضخمة
تنظيم المعالجة التحليلية على الإنترنت (OLAP) ينظم البيانات بطريقة تجعل التحليليون يتمكنون أسهل من استكشاف جوانب مختلفة من البيانات. وللإجابة عن الأسئلة، يتوجب على هذه الأنظمة تحويل البيانات التامية الإجراءية إلى تنظيم مناسب للتحليل ومعالجة كميات كبيرة من البيانات. يستخدم عمليات (ETL) (استخراج، تحويل، تحميل) في المخازن البيانية التقليدية للإدارة بهذا. وتقنيات البيانات الكبيرة، مثل (Apache Hadoop)، قدمت تحسينات للمخازن البيانية من خلال التنبؤ بالقضايا المتسعة وبوجودها مفتوحة المصدر، وهذا سمح لأي شركة باستخدامها بما long أنها تستطيع إدارة البنية التحتية. أدى Hadoop مقاربة جديدة بتسمية البيانات الغير منظمة أو البيانات النصف منظمة، بدلاً من تطبيق شكل قاطع مباشرة. تلك المرونة، حيث يمكن الكتابة للبيانات بدون شكل معين مسبقاً وتنظمها لاحقاً أثناء الاستكشاف، جعلت المهندسين البيانات يتمكنوا أسهل من التعامل والدمج البيانات. تبني Hadoop يتم غالبًا بمجموعة فريق من البيانات منفصلة: يقوم المهندسون البيانات بالاستخراج، يلفت العلماء البيانات الى التنظيف والتجديد، ويقومون بالتحليلات البيانات المحليين. قد توجد هذا الإطار مشاكل بسبب تواصل محدود بين فريق البيانات ومطوري التطبيقات، وغالبًا لتوفر تأثير على الأنظمة الإنتاجية.
المشكلة 1: قضايا مع الحدود النمو
البيانات المستخدمة في التحليل مرتبطة ارتباطًا وثيقًا ببنيتها الأصلية، مما يمكن أن يكون مشكلة مع النماذج المعقدة والمحدثة بشكل متكرر. تؤثر التغييرات في نموذج البيانات على جميع المستخدمين، مما يجعلهم عرضة لهذه التغييرات، خاصة عندما يتضمن النموذج العديد من الجداول.
المشكلة 2: البيانات السيئة، تكاليف تجاهل المشكلة
غالبًا ما تمر البيانات السيئة دون أن يلاحظها أحد حتى تتسبب في مشكلات في المخطط، مما يؤدي إلى مشاكل مثل أنواع البيانات غير الصحيحة. نظرًا لأن التحقق من صحة البيانات غالبًا ما يتم تأجيله حتى نهاية العملية، يمكن أن تنتشر البيانات السيئة عبر الأنابيب، مما يؤدي إلى إصلاحات مكلفة وحلول غير متسقة. يمكن أن تؤدي البيانات السيئة إلى خسائر تجارية كبيرة، مثل أخطاء الفوترة التي تكلف الملايين. تشير الأبحاث إلى أن البيانات السيئة تكلف الشركات تريليونات سنويًا، مما يهدر وقتًا كبيرًا على العاملين في المعرفة وعلماء البيانات.
المشكلة 3: عدم وجود ملكية فردية
مطورو التطبيقات، الذين هم خبراء في نموذج البيانات المصدر، لا يقومون عادةً بإيصال هذه المعلومات إلى الفرق الأخرى. تنتهي مسؤولياتهم غالبًا عند حدود تطبيقاتهم وقواعد بياناتهم. مهندسو البيانات، الذين يديرون استخراج البيانات وحركتها، يعملون غالبًا بشكل تفاعلي ولديهم سيطرة محدودة على مصادر البيانات. يواجه محللو البيانات، الذين هم بعيدون عن المطورين، تحديات مع البيانات التي يتلقونها، مما يؤدي إلى مشكلات في التنسيق والحاجة إلى حلول منفصلة.
المشكلة 4: اتصالات البيانات المخصصة
في المنظمات الكبيرة، قد تستخدم فرق متعددة نفس البيانات ولكن تنشئ عملياتها الخاصة لإدارتها. ينتج عن ذلك نسخ متعددة من البيانات، كل منها مُدار بشكل مستقل، مما يخلق فوضى متشابكة. يصبح من الصعب تتبع وظائف ETL وضمان جودة البيانات، مما يؤدي إلى أخطاء بسبب عوامل مثل مشاكل المزامنة ومصادر البيانات الأقل أمانًا. هذا النهج المبعثر يهدر الوقت والمال والفرص.
شبكة البيانات تعالج هذه القضايا من خلال التعامل مع البيانات كمنتج ذو مخططات واضحة ووثائق ووصول موحد، مما يقلل من مخاطر البيانات السيئة ويحسن دقة وكفاءة البيانات.
شبكة البيانات: نهج حديث
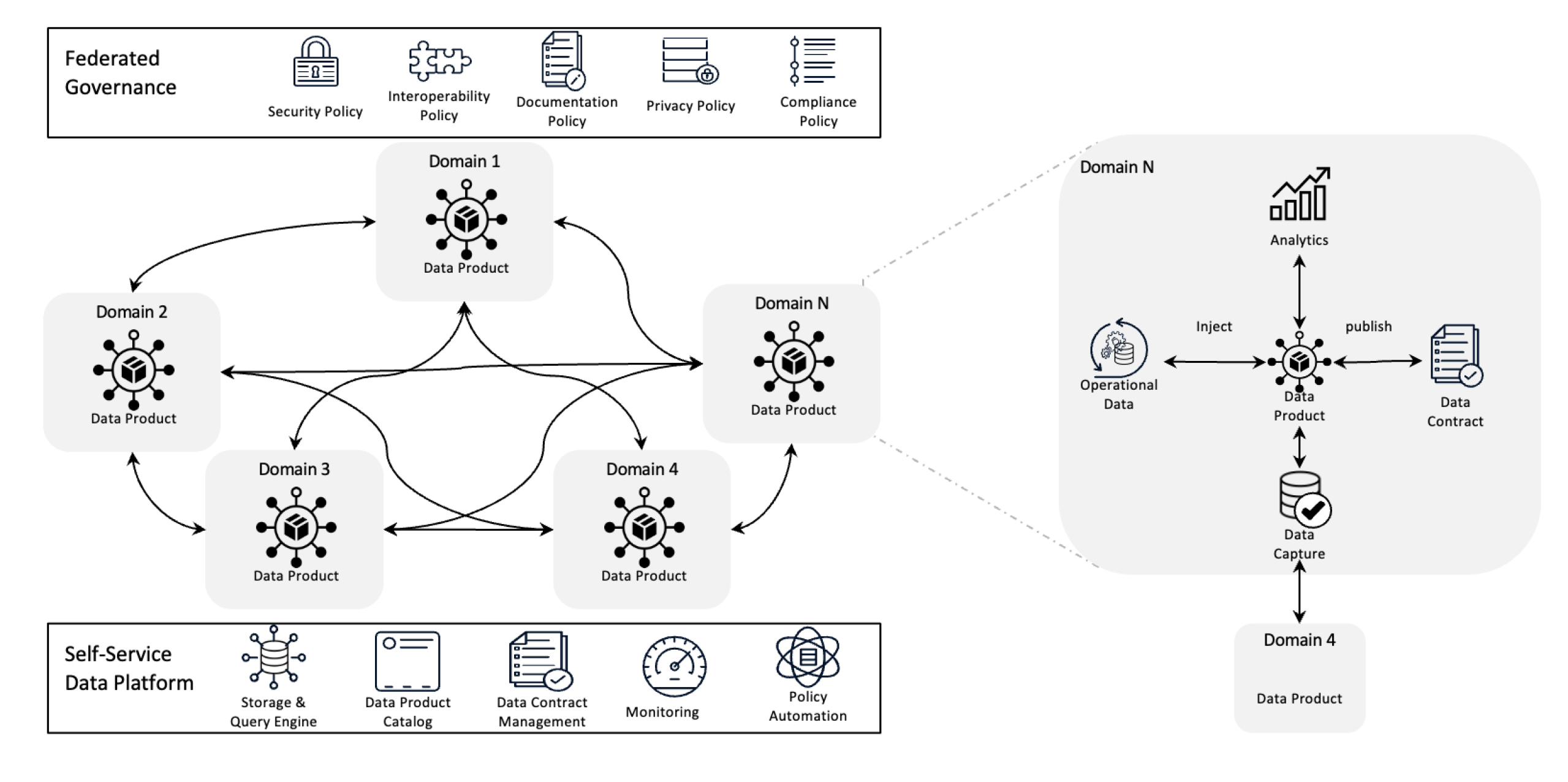
هندسة شبكة البيانات
تعيد شبكة البيانات تعريف إدارة البيانات من خلال لامركزية الملكية والتعامل مع البيانات كمنتج، مدعومة ببنية تحتية ذاتية الخدمة. هذا التحول يمكّن الفرق من السيطرة الكاملة على بياناتهم بينما تضمن الحوكمة الفيدرالية الجودة والامتثال والقابلية للتوسع عبر المنظمة.
بعبارات أبسط، هي إطار عمل معماري مصمم لحل تحديات البيانات المعقدة باستخدام ملكية لامركزية وطرق موزعة. يُستخدم لدمج البيانات من مختلف المجالات التجارية لتحليلات بيانات شاملة. كما أنها مبنية على سياسات قوية لمشاركة البيانات والحوكمة.
أهداف شبكة البيانات
يشاعد مبدأ الشبكة البيانية (Data Mesh) المنظمات المختلفة على الحصول على رؤى قيمة من البيانات على نطاق واسع؛ باختصار، التعامل مع بيئة البيانات المتغيرة باستمرار، والعدد المتزايد من مصادر البيانات والمستخدمين، وتنوع التحولات البيانية المطلوبة، والحاجة إلى التكيف السريع مع التغييرات.
تحل شبكة البيانات جميع المشاكل المذكورة أعلاه من خلال اللامركزية في التحكم، بحيث يمكن للفرق إدارة بياناتها الخاصة دون أن تكون معزولة في أقسام منفصلة. هذا النهج يحسن من قابلية التوسع من خلال توزيع معالجة البيانات والتخزين، مما يساعد على تجنب التباطؤات في نظام مركزي واحد. كما يُسرع من الحصول على الرؤى من خلال السماح للفرق بالعمل مباشرة مع بياناتها الخاصة، مما يقلل من التأخيرات الناتجة عن انتظار فريق مركزي. كل فريق يتحمل مسؤولية بياناته الخاصة، مما يعزز الجودة والتناسق. من خلال استخدام منتجات البيانات سهلة الفهم وأدوات الخدمة الذاتية، تضمن شبكة البيانات أن جميع الفرق يمكنها الوصول إلى بياناتها وإدارتها بسرعة، مما يؤدي إلى عمليات أسرع وأكثر كفاءة وتوافق أفضل مع احتياجات العمل.
المبادئ الرئيسية لشبكة البيانات
- الملكية اللامركزية للبيانات: تملك الفرق منتجات بياناتها وتديرها، مما يجعلها مسؤولة عن جودتها وتوافرها.
- البيانات كمنتج: تُعامل البيانات كمنتج مع إمكانية الوصول الموحدة، والتعريفات المتسلسلة، وتعريفات المخططات، مما يضمن التناسق وسهولة الاستخدام عبر الأقسام.
- الحوكمة الفيدرالية: يتم وضع السياسات للحفاظ على سلامة البيانات، وأمنها، والامتثال، مع السماح بالملكية اللامركزية.
- البنية التحتية ذاتية الخدمة: يمكن للفرق الوصول إلى بنية تحتية قابلة للتوسع تدعم استيعاب البيانات ومعالجتها واستجوابها بدون اختناقات أو الاعتماد على فريق بيانات مركزي.
كيف تساعد الأحداث في شبكة البيانات؟
تساعد الأحداث في شبكة البيانات من خلال السماح لأجزاء مختلفة من النظام بمشاركة وتحديث البيانات في الوقت الفعلي. عندما يحدث تغيير في منطقة ما، يقوم الحدث بإخطار المناطق الأخرى بذلك، بحيث يبقى الجميع على اطلاع دائم دون الحاجة إلى اتصالات مباشرة. هذا يجعل النظام أكثر مرونة وقابلية للتوسع لأنه يمكنه التعامل مع الكثير من البيانات والتكيف مع التغييرات بسهولة. كما تجعل الأحداث من السهل تتبع كيفية استخدام البيانات وإدارتها، وتتيح لكل فريق التعامل مع بياناته الخاصة دون الاعتماد على الآخرين.
أخيرًا، دعونا نلقي نظرة على بنية شبكة البيانات المدفوعة بالأحداث.
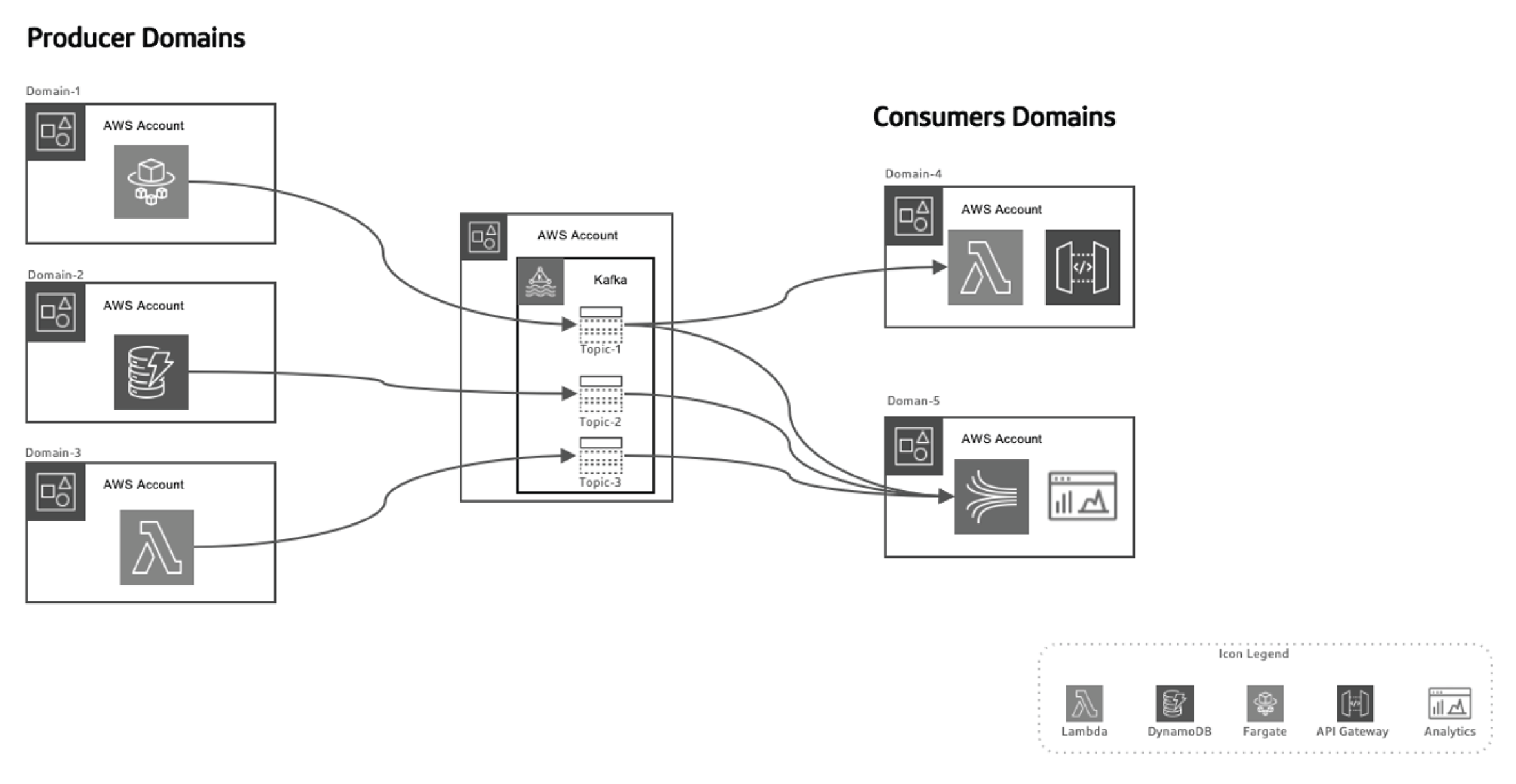
تسمح لنا هذه الطريقة المدفوعة بالأحداث بفصل المنتجين للبيانات عن المستهلكين، مما يجعل النظام أكثر قابلية للتوسع حيث تتطور النطاقات بمرور الوقت دون الحاجة إلى تغييرات كبيرة في البنية التحتية. يتحمل المنتجون مسؤولية توليد الأحداث، التي تُرسل بعد ذلك إلى نظام نقل البيانات. تضمن منصة التدفق تسليم هذه الأحداث بشكل موثوق. عندما ينشر منتج خدمة مصغرة أو قاعدة بيانات حدثًا جديدًا، يتم تخزينه في موضوع محدد. هذا يُشغل المستمعين على الجانب المستهلك، مثل وظائف Lambda أو Kinesis، لمعالجة الحدث واستخدامه حسب الحاجة.
الاستفادة من AWS لبنية شبكة البيانات المدفوعة بالأحداث
تقدم AWS مجموعة من الخدمات التي تكمل بشكل مثالي نموذج شبكة البيانات المدفوعة بالأحداث، مما يسمح للمؤسسات بتوسيع بنية بياناتها التحتية، وضمان تسليم البيانات في الوقت الفعلي، والحفاظ على مستويات عالية من الحوكمة والأمان.
إليك كيف تتناسب خدمات AWS المختلفة مع هذه البنية المعمارية:
AWS Kinesis للبث المباشر للأحداث
في شبكة البيانات المدفوعة بالأحداث، يعد البث المباشر عنصرًا حاسمًا. يوفر AWS Kinesis القدرة على جمع ومعالجة وتحليل بيانات البث المباشر على نطاق واسع.
تقدم Kinesis عدة مكونات:
- Kinesis Data Streams: ادخل الأحداث في الوقت الفعلي وقم بمعالجتها بالتوازي مع العديد من المستهلكين.
- Kinesis Data Firehose: ينقل تدفقات الأحداث مباشرة إلى S3 أو Redshift أو Elastic search لمزيد من المعالجة والتحليل.
- Kinesis Data Analytics: يعالج البيانات في الوقت الفعلي لاستخلاص الأفكار على الفور، مما يسمح بحلقات ردود فعل فورية في خطوط معالجة البيانات.
AWS Lambda لمعالجة الأحداث
AWS Lambda هو العمود الفقري لمعالجة الأحداث بدون خادم في بنية شبكة البيانات. بقدرته على التوسع التلقائي ومعالجة تدفقات البيانات الواردة دون الحاجة إلى إدارة الخوادم،
يعد Lambda خيارًا مثاليًا لـ:
- معالجة تدفقات Kinesis في الوقت الفعلي
- استدعاء طلبات API Gateway استجابة لأحداث محددة
- التفاعل مع DynamoDB أو S3 أو خدمات AWS الأخرى لتخزين أو معالجة أو تحليل البيانات
AWS SNS و SQS لتوزيع الأحداث
خدمة AWS Simple Notification Service (SNS)تعمل كنظام بث أحداث الأساسي، يمكنها إرسال تنبيهات حالية إلى أنظمة موزعة.خدمة AWS Simple Queue Service (SQS)تتأكد من توصيل الرسائل بين الخدمات المفصلة بشكل موثوق، حتى في حالة فشل جزءين من النظام. تسمح هذه الخدمات للميكروسرويات المفصلة بالتفاعل دون إعتمادات مباشرة، متأكدةً من أن النظام يبقى قابلاً للتوسعة ومتحملاً الخطأ.
DynamoDB لإدارة البيانات الحالية بواسطة AWS
في الأركييندات اللامركزية، يوفر DynamoDB قاعدة بيانات NoSQL قابلة للتوسعة وخاصة قليلة، التي يمكنها تخزين البيانات التي تنتج في الوقت الحالي، ما يجعلها مناسبة لتخزين نتائج أنابيب التحليل البياناتي. وهي تدعم النموذج الخارجي (Outbox pattern),حيث تتم تخزين
الأحداث التي تنتج من التطبيق في DynamoDB وتتم استخدامها خدمة التسجيل (على سبيل المثال، Kinesis أو Kafka).
خدمة AWS Glue للموارد الخام والتحليل البياناتي
تقدم خدمة AWS Glue خدمة قاعدة بيانات وخدمة التحليل البياناتي مضبوطة بالكامل، هي أساسية لإدارة البيانات التامية في الشبكة الخام. تساعد Glue على تسجيل، تحضير وتحويل البيانات في المجالات الموزعة، ضمن تأمين الاكتشاف، الحكم والدمج عبر المنظومة.
AWS Lake Formation و S3 لبيانات البحيرات
بينما يتحرك هيكلة شبكة البيانات الى ابعاد مستودعات البيانات المركزية، تلعب س3 وتشكيل بحيرة الأوروقة دور حاسم في تخزين، تأمين وتسجيل البيانات التي تسرب بين مجالات مختلفة، ضمن تأمين التخزين الطويل الأمد، والحكم والموافقة.
الشبكة البياناتية المتحركة وفقاً للحالات مع AWS وPython
منتج الأحداث: AWS Kinesis + Python
في هذا المثال ، نستخدم AWS Kinesis لتسريب الأحداث حين إنشاء مستخدم جديد:
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')
تحليل الأحداث: AWS Lambda + Python
يستهلك هذه الما لاما تلك الأحداث من Kinesis وتعالجها في الوقت الحالي.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")
خلاصة
من خلال تسخير خدمات AWS مثل Kinesis و Lambda و DynamoDB و Glue، يمكن للمنظمات تحقيق الحصول بالكامل على قدرات الشبكة البياناتية المتحركة المبنية على الأحداث. هذه الهيكلة توفر المرونة والتنمية المستمرة والنظرات الحالية، مضمناً أن المنظمات تبقى متمركزة في مناظر البيانات التي تتغير بسرعة في العصر الحديث. تبني هيكلة الشبكة البياناتية المتحركة وفقاً للحالات ليس مجرد تحسين تقني بل تعتبر ضرورياً استراتيجياً للأعمال التي ترغب في النجاح في عصر البيانات الكبيرة والأنظمة الموزعة.
Source:
https://dzone.com/articles/event-driven-data-mesh-architecture-with-aws