













本篇文章摘錄自我的著作《TinyML Cookbook, Second Edition》。本文中使用的程式碼可於此處找到。
準備工作
本文將設計的應用旨在持續錄製一段1秒鐘的音訊片段並進行模型推斷,如以下圖片所示:
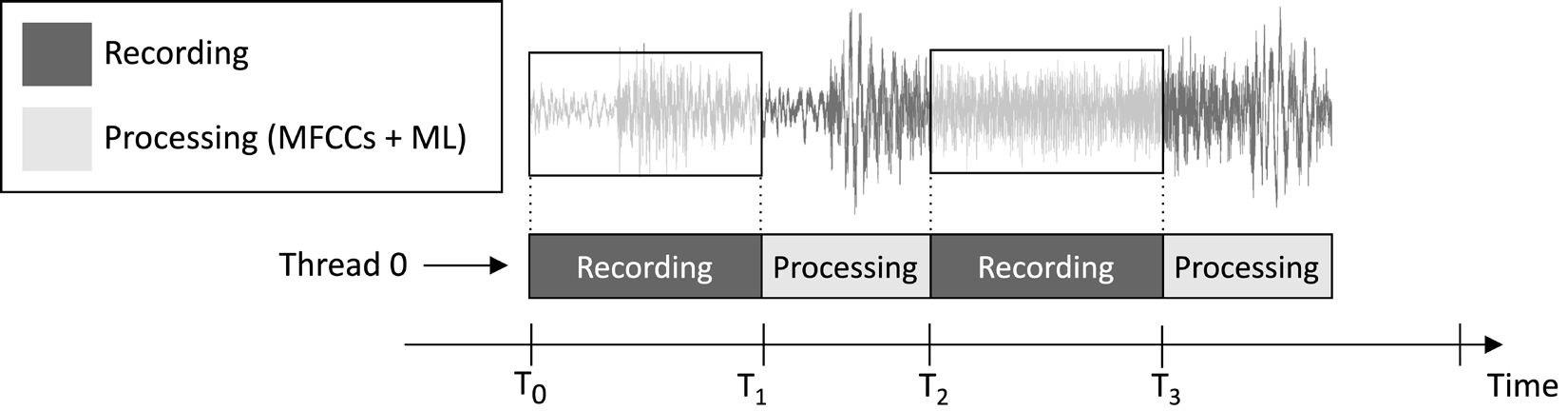
圖1:錄音與處理任務依序執行
從上述圖片所示的任務執行時間線中,您可以觀察到特徵提取和模型推斷總是在音訊錄製後進行,而非同時進行。因此,顯而易見地,我們並未處理即時音訊串流中的某些片段。
不同於即時關鍵詞偵測(KWS)應用,後者應捕捉並處理音訊串流中的所有片段,以確保不遺漏任何說出的詞語,在此,我們可以放寬這一要求,因為這並不影響應用的有效性。
如我們所知,MFCC特徵提取的輸入是1秒鐘的Q15格式原始音訊。然而,從麥克風獲取的樣本以16位元整數值表示。因此,我們如何將16位元整數值轉換為Q15?解決方案比您想像的更為直接:無需轉換音訊樣本。
要理解這一點,請考慮Q15定點格式。此格式能夠表示範圍在[-1, 1]內的浮點值。從浮點轉換到Q15涉及將浮點值乘以32,768(2^15)。然而,由於浮點表示起源於將16位整數樣本除以32,768(2^15),這意味著16位整數值本質上是以Q15格式存在的。
如何操作…
取帶有麥克風連接的Raspberry Pi Pico麵包板。從微控制器上斷開數據線,並從麵包板上移除按鈕及其連接的跳線,因為本教程不需要它們。圖2顯示了麵包板上應有的配置:
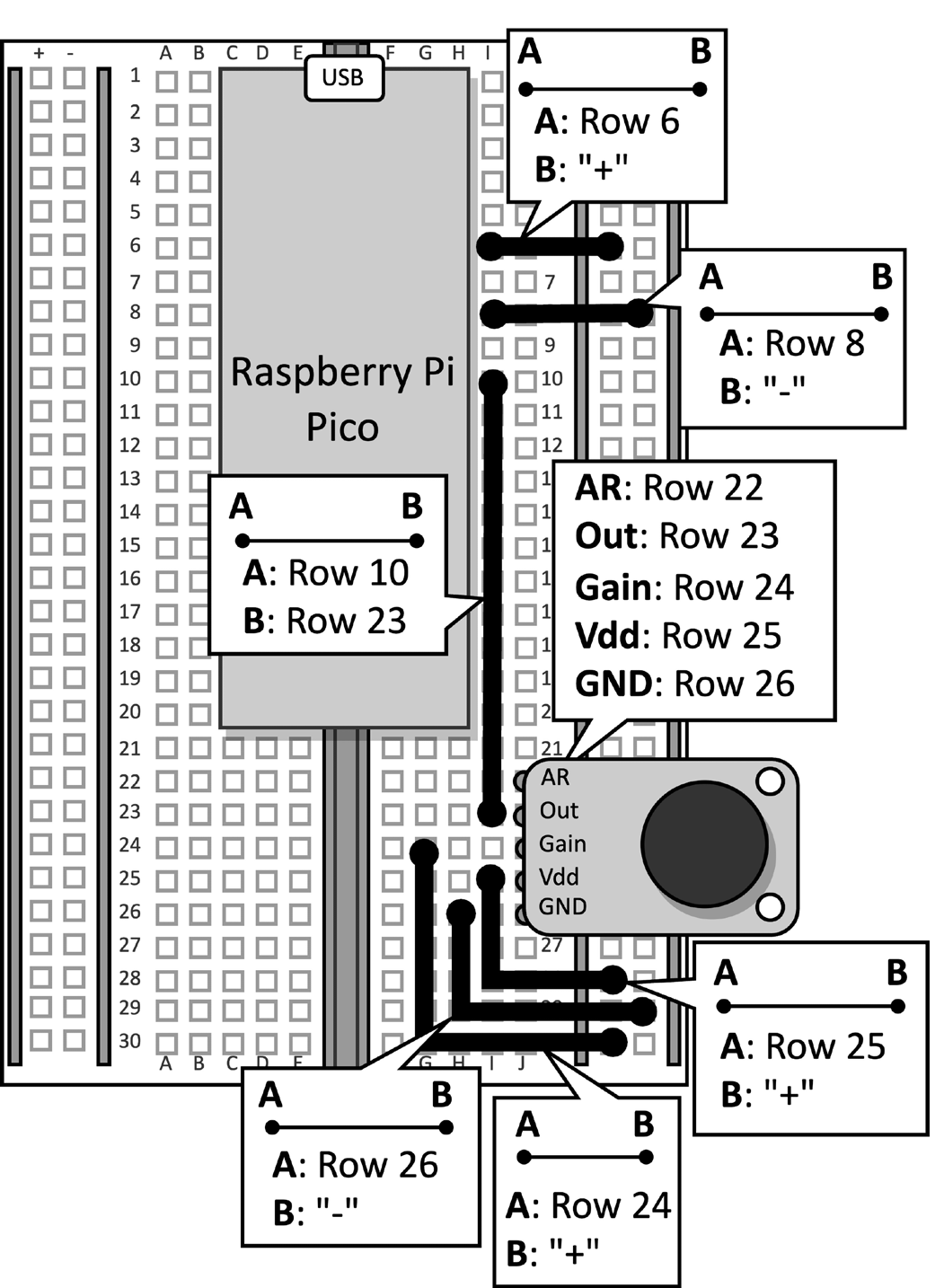
圖2:麵包板上搭建的電子電路
移除麵包板上的按鈕後,打開Arduino IDE並創建一個新草圖。
現在,按照以下步驟在Raspberry Pi Pico上開發音樂類型識別應用程序:
步驟1
從TinyML-Cookbook_2E GitHub 倉庫下載Arduino TensorFlow Lite庫。
下載ZIP檔案後,將其匯入Arduino IDE。
步驟2
在Arduino IDE中匯入所有生成用於MFCCs特徵提取演算法的C標頭檔案,不包括test_src.h和test_dst.h。
步驟3
複製第6章,在Raspberry Pi Pico上部署MFCCs特徵提取演算法中開發的草圖,用於實現MFCCs特徵提取,排除setup()和loop()函數。
移除test_src.h和test_dst.h標頭檔案的包含。接著,移除dst陣列的分配,因為MFCCs將直接存儲在模型的輸入中。
步驟4
複製第5章,使用TensorFlow和Raspberry Pi Pico識別音樂類型 – 第一部分中開發的草圖,用於使用麥克風錄製音頻樣本,排除setup()和loop()函數。
匯入程式碼後,移除任何關於LED和按鈕的引用,因為它們不再需要。然後,將AUDIO_LENGTH_SEC的定義更改為錄製持續1秒的音頻:
#define AUDIO_LENGTH_SEC 1步驟5
將包含TensorFlow Lite模型的標頭檔案(model.h)匯入Arduino專案。
匯入檔案後,在草圖中包含model.h標頭檔案:
#include "model.h"
包含tflite-micro所需的标头文件:
#include
#include
#include
#include
#include
#include 步骤6
声明tflite-micro模型和解释器的全局变量:
const tflite::Model* tflu_model = nullptr;
tflite::MicroInterpreter* tflu_interpreter = nullptr;
接着,声明TensorFlow Lite张量对象(TfLiteTensor)以访问模型的输入和输出张量:
TfLiteTensor* tflu_i_tensor = nullptr;
TfLiteTensor* tflu_o_tensor = nullptr;
步骤7
声明一个缓冲区(张量竞技场)以存储模型执行期间使用的中介张量:
constexpr int tensor_arena_size = 16384;
uint8_t tensor_arena[tensor_arena_size] __attribute__((aligned(16)));
张量竞技场的大小已通过实证测试确定,因为中介张量所需的内存根据底层LSTM操作符的实现方式而变化。我们在Raspberry Pi Pico上的实验发现,该模型仅需要16 KB的RAM进行推理。
步骤8
在setup()函数中,以115200波特率初始化串行外设:
Serial.begin(115200);
while (!Serial);
串行外设将用于通过串行通信传输识别的音乐流派。
步骤9
在setup()函数中,加载存储在model.h头文件中的TensorFlow Lite模型:
tflu_model = tflite::GetModel(model_tflite);接著,註冊所有tflite-micro支援的DNN操作,並初始化tflite-micro解釋器:
tflite::AllOpsResolver tflu_ops_resolver;
static tflite::MicroInterpreter static_interpreter(
tflu_model,
tflu_ops_resolver,
tensor_arena,
tensor_arena_size);
tflu_interpreter = &static_interpreter;步驟10
在setup()函數中,分配模型所需的記憶體,並取得輸入和輸出張量的記憶體指標:
tflu_interpreter->AllocateTensors();
tflu_i_tensor = tflu_interpreter->input(0);
tflu_o_tensor = tflu_interpreter->output(0);
步驟11
在setup()函數中,使用Raspberry Pi Pico SDK初始化ADC周邊:
adc_init();
adc_gpio_init(26);
adc_select_input(0);
步驟12
在loop()函數中,準備模型的輸入。為此,錄製1秒的音訊片段:
// 重置音訊緩衝區
buffer.cur_idx = 0;
buffer.is_ready = false;
constexpr uint32_t sr_us = 1000000 / SAMPLE_RATE;
timer.attach_us(&timer_ISR, sr_us);
while(!buffer.is_ready);
timer.detach();錄音後,提取MFCCs:
mfccs.run((const q15_t*)&buffer.data[0],
(float *)&tflu_i_tensor->data.f[0]);
如前述程式碼片段所示,MFCCs將直接存儲在模型的輸入中。
步驟13
運行模型推斷並透過序列通訊返回分類結果:
tflu_interpreter->Invoke();
size_t ix_max = 0;
float pb_max = 0;
for (size_t ix = 0; ix < 3; ix++) {
if(tflu_o_tensor->data.f[ix] > pb_max) {
ix_max = ix;
pb_max = tflu_o_tensor->data.f[ix];
}
}
const char *label[] = {"disco", "jazz", "metal"};
Serial.println(label[ix_max]);現在,將微型USB數據線插入Raspberry Pi Pico。連接後,編譯並上傳草圖到微控制器。
之後,在Arduino IDE中打開序列監視器,將您的智能手機靠近麥克風播放迪斯可、爵士或金屬歌曲。應用程式現在應該能識別歌曲的音樂類型並在序列監視器中顯示分類結果!
結論
在本文中,您已學會如何將訓練好的音樂類型分類模型部署到 Raspberry Pi Pico 上,使用的是 tflite-micro 技術。
Source:
https://dzone.com/articles/recognizing-music-genres-with-the-raspberry-pi-pic