













SettingWithCopyWarning 是 Pandas 在對 DataFrame 進行賦值時可能引發的警告。當我們使用鏈式賦值或使用從切片創建的 DataFrame 時,就可能出現這種情況。這是 Pandas 代碼中常見的錯誤來源,我們都曾遇到過。這很難進行調試,因為警告可能出現在看起來應該正常工作的代碼中。
理解 SettingWithCopyWarning 的重要性是因為它提示了數據操作存在潛在問題。這個警告表明您的代碼可能未按照預期修改數據,這可能導致意外後果並使難以追踪的錯誤變得模糊不清。
在本文中,我們將探討 Pandas 中的 SettingWithCopyWarning 以及如何避免它。我們還將討論 Pandas 的未來以及 copy_on_write 選項將如何改變我們使用 DataFrames 的方式。
DataFrame 的視圖和副本
當我們選擇 DataFrame 的一個切片並將其賦值給一個變量時,我們可能會得到一個視圖或一個全新的 DataFrame 副本。
使用視圖時,兩個 DataFrame 之間的內存是共享的。這意味著修改存在於兩個 DataFrame 中的單元格的值將同時修改它們兩個。

使用副本時,將分配新的內存,並創建一個具有與原始 DataFrame 相同值的獨立 DataFrame。在這種情況下,兩個 DataFrame 是獨立的實體,因此在其中一個中修改值不會影響另一個。
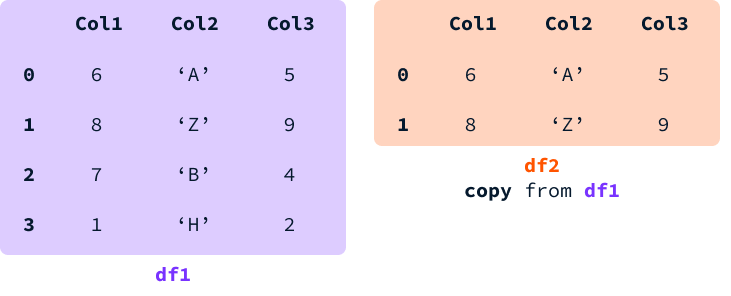
Pandas儘可能避免創建副本以優化性能。但是,無法事先預測我們將獲得視圖還是複本。每當我們為DataFrame分配值時,如果不清楚它是來自另一個DataFrame的視圖還是複本,就會引發SettingWithCopyWarning。
通過真實數據理解SettingWithCopyWarning
我們將使用這個倫敦2024年房地產數據 Kaggle數據集來學習SettingWithCopyWarning發生的情況以及如何修復它。
該數據集包含來自倫敦的最新房地產數據。以下是數據集中出現的列的概述:
addedOn:列出日期。title:列出標題。descriptionHtml:列出的HTML描述。propertyType:物業類型。如果未指定類型,則值將為"Not Specified"。sizeSqFeetMax:平方英尺的最大尺寸。bedrooms:臥室數量。listingUpdatedReason:更新列出的原因(例如,新列表,價格降低)。price:列出價格(以英鎊為單位)。
具有明確臨時變量的示例
假設我們被告知未指定屬性類型的屬性是房屋。因此,我們希望將所有propertyType等於"Not Specified"的行更新為"House"。一種方法是將具有非指定屬性類型的行篩選到臨時DataFrame變數中,並像這樣更新propertyType列值:
import pandas as pd dataset_name = "realestate_data_london_2024_nov.csv" df = pd.read_csv(dataset_name) # 獲取所有未指定屬性類型的行 no_property_type = df[df["propertyType"] == "Not Specified"] # 將這些行的屬性類型更新為“House” no_property_type["propertyType"] = "House"
執行此代碼將導致pandas生成SettingWithCopyWarning:
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy no_property_type["propertyType"] = "House"
這是因為pandas無法知道no_property_type DataFrame是df的視圖還是副本。
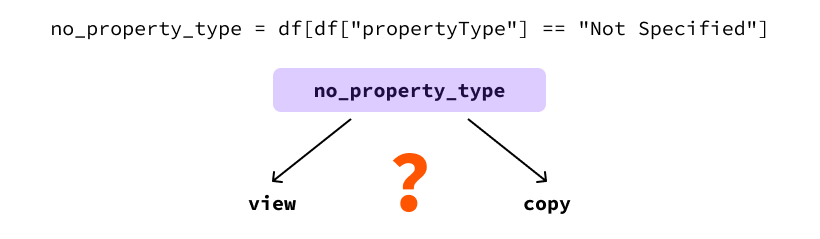
這是一個問題,因為以下代碼的行為可能會根據其是視圖還是副本而有所不同。
在這個例子中,我們的目標是修改原始DataFrame。只有當no_property_type是視圖時才會發生這種情況。如果我們的其餘代碼假設df已被修改,這可能是錯誤的,因為無法保證這是正確的。由於這種不確定的行為,Pandas會發出警告來讓我們了解這個事實。
即使我們的代碼因為得到了一個視圖而正常運行,但在後續運行中我們可能得到一個副本,代碼將無法按預期工作。因此,重要的是不要忽略此警告,並確保我們的代碼始終按我們的意願執行。
帶有隱藏臨時變量的示例
在前面的例子中,很明顯正在使用一個臨時變量,因為我們明確地將DataFrame的一部分分配給一個名為no_property_type的變量。
然而,在某些情況下,這並不那麼明確。發生SettingWithCopyWarning的最常見例子是鏈式索引。假設我們用一行代替最後兩行:
df[df["propertyType"] == "Not Specified"]["propertyType"] = "House"
乍一看,它似乎沒有創建臨時變量。然而,執行後也會導致SettingWithCopyWarning。
代碼的執行方式是:
- 計算並將
df[df["propertyType"] == "Not Specified"]臨時存儲到內存中。 - 訪問該臨時內存位置的索引
["propertyType"]。

索引訪問逐個評估,因此,鏈式索引導致相同的警告,因為我們不知道中間結果是視圖還是拷貝。上述代碼本質上與執行以下操作相同:
tmp = df[df["propertyType"] == "Not Specified"] tmp["propertyType"] = "House"
這個例子通常被稱為鏈式索引,因為我們使用[]來鏈接索引訪問。首先,我們訪問[df["propertyType"] == "Not Specified"],然後是["propertyType"]。

如何解決SettingWithCopyWarning
讓我們學習如何編寫程式碼,以確保沒有模稜兩可的地方,也不會觸發 SettingWithCopyWarning。我們了解到,這個警告是由於對於 DataFrame 是檢視還是另一個 DataFrame 的副本存在模稜兩可而引起的。
解決的方法是確保我們創建的每個 DataFrame 是一個副本(如果我們希望它是副本)或是一個檢視(如果我們希望它是檢視)。
安全地使用 loc 來修改原始的 DataFrame
讓我們修復上面示例中的代碼,其中我們想要修改原始的 DataFrame。為了避免使用臨時變數,使用loc 索引器屬性。
df.loc[df["propertyType"] == "Not Specified", "propertyType"] = "House"
使用這段程式碼,我們通過 loc 索引器屬性直接對原始的 df DataFrame 進行操作,因此不需要中間變數。這是我們想要直接修改原始 DataFrame 時需要做的事情。
乍一看,這可能看起來像是鏈式索引,因為仍然有參數,但實際上不是。每個索引的界定是方括號 []。

請注意,只有當我們直接賦值時,使用 loc 才是安全的,就像我們上面所做的那樣。如果我們改為使用臨時變數,我們又會陷入同樣的問題。以下是兩個未解決問題的代碼示例:
- 使用具有临时变量的
loc:
# 使用带有临时变量的 loc 不能解决问题 no_property_type = df.loc[df["propertyType"] == "Not Specified"] no_property_type["propertyType"] = "House"
- 使用
loc与索引一起(与链式索引相同):
# 使用 loc 加索引与链式索引相同 df.loc[df["propertyType"] == "Not Specified"]["propertyType"] = "House"
这两个示例往往会让人困惑,因为人们普遍错误地认为只要有loc,就在修改原始数据。这是不正确的。确保数值被分配给原始 DataFrame 的唯一方法是直接使用单个loc进行赋值,而不进行任何单独的索引。
使用copy()安全地处理原始 DataFrame 的副本
當我們想要確保我們在 DataFrame 的副本上操作時,應該使用 .copy() 方法。
假設我們被要求分析房產每平方英尺的價格。我們不希望修改原始數據。目標是創建一個包含分析結果的新 DataFrame,以便發送給另一個團隊。
第一步是過濾掉一些行並清理數據。具體來說,我們需要:
- 刪除未定義
sizeSqFeetMax的行。 - 刪除
price為"POA"(價格待定)的行。 - 將價格轉換為數值(原始數據集中,價格是以以下格式的字符串表示:
"£25,000,000")
我們可以使用以下代碼執行以上步驟:
# 1. 過濾掉所有沒有大小或價格的屬性 properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")] # 2. 從價格列中刪除£和,字符 properties_with_size_and_price["price"] = properties_with_size_and_price["price"].str.replace("£", "", regex=False).str.replace(",", "", regex=False) # 3. 將價格列轉換為數值 properties_with_size_and_price["price"] = pd.to_numeric(properties_with_size_and_price["price"])
要計算每平方英尺的價格,我們創建一個新的列,其值是將price列除以sizeSqFeetMax列的結果:
properties_with_size_and_price["pricePerSqFt"] = properties_with_size_and_price["price"] / properties_with_size_and_price["sizeSqFeetMax"]
如果執行此代碼,我們再次會收到SettingWithCopyWarning。這並不奇怪,因為我們明確創建並修改了一個臨時的DataFrame變量properties_with_size_and_price。
由於我們想要處理數據的副本而不是原始的 DataFrame,我們可以通過確保 properties_with_size_and_price 是一個全新的 DataFrame 副本而不是視圖來解決這個問題,方法是使用 .copy() 方法 在第一行:
properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")].copy()
安全地添加新列
創建新列的行為與賦值相同。每當我們處於不確定是在操作副本還是視圖的情況下,pandas 會引發 SettingWithCopyWarning。
如果我們想使用數據的副本,應該明確地使用 .copy() 方法進行複製。然後,我們可以隨意地為新的列進行賦值。我們在之前的例子中創建 pricePerSqFt 列時就是這樣做的。
另一方面,如果我們想修改原始的 DataFrame,則需要考慮兩種情況。
- 如果新列涵蓋每一行,我們可以直接修改原始的 DataFrame。這不會引起警告,因為我們不會選擇行的子集。例如,我們可以為每一行添加一個
note列,當房屋類型缺失時:
df["notes"] = df["propertyType"].apply(lambda house_type: "Missing house type" if house_type == "Not Specified" else "")
- 如果新列僅為某些行定義值,那麼我們可以使用
loc索引器屬性。例如:
df.loc[df["propertyType"] == "Not Specified", "notes"] = "Missing house type"
請注意,在這種情況下,未選擇的列的值將是未定義的,因此首選第一種方法,因為它允許我們為每一行指定一個值。
SettingWithCopyWarning 錯誤在 Pandas 3.0 中
目前,SettingWithCopyWarning 只是警告,不是錯誤。我們的代碼仍然會執行,而 Pandas 只是告訴我們要小心。
根據 官方的 Pandas 文檔,從版本 3.0 開始,SettingWithCopyWarning 將不再使用,並將默認替換為實際的 錯誤,以強化代碼標準。
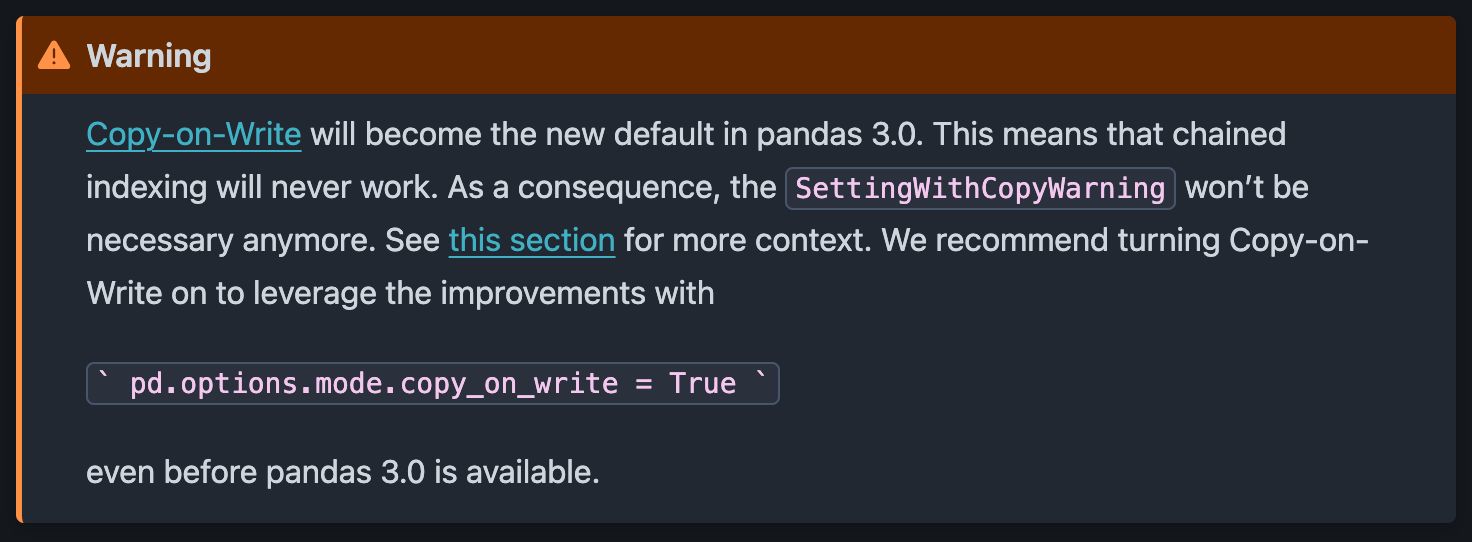
為了確保我們的代碼與未來的 pandas 版本保持兼容,建議已經更新代碼以引發錯誤而不是警告。
這是通過在導入 pandas 後設置以下選項來完成的:
import pandas as pd pd.options.mode.copy_on_write = True
將這段代碼添加到現有代碼中,將確保我們在代碼中處理每個模糊的賦值,並確保在我們更新到 pandas 3.0 時代碼仍然有效。
結論
SettingWithCopyWarning 會在我們的代碼使得修改的值是視圖還是副本變得模糊時發生。我們可以通過始終明確我們想要的來修正它:
- 如果我們想要處理副本,我們應該使用
copy()方法明確地進行複製。 - 如果我們想要修改原始的 DataFrame,我們應該使用
loc索引器屬性,並在訪問數據時直接賦值,而不使用中介變量。
儘管這不是一個錯誤,但我們不應該忽略這個警告,因為它可能導致意外結果。此外,從 Pandas 3.0 開始,默認將其設為錯誤,因此我們應該通過在當前代碼中使用 pd.options.mode.copy_on_write = True 來打開 Copy-on-Write,以確保代碼在未來版本的 Pandas 中保持功能正常。
Source:
https://www.datacamp.com/tutorial/settingwithcopywarning-pandas