













SettingWithCopyWarning는 Pandas가 DataFrame에 할당할 때 발생할 수 있는 경고입니다. 이는 연쇄 할당이나 슬라이스로 생성된 DataFrame을 사용할 때 발생할 수 있습니다. 이는 우리가 모두 직면한 Pandas 코드의 일반적인 버그 소스입니다. 이는 잘 작동해야 할 것으로 보이는 코드에서 나타날 수 있어서 디버깅하기 어려울 수 있습니다.
SettingWithCopyWarning를 이해하는 것은 데이터 조작과 관련된 잠재적인 문제를 신호하는 중요한 요소입니다. 이 경고는 코드가 의도한 대로 데이터를 수정하지 않을 수 있음을 시사하며, 의도하지 않은 결과와 추적하기 어려운 버그로 이어질 수 있습니다.
이 기사에서는 Pandas에서의 SettingWithCopyWarning를 탐색하고 이를 피하는 방법을 살펴볼 것입니다. 또한 Pandas의 미래와 copy_on_write 옵션이 데이터프레임과의 작업 방식을 어떻게 변경할지에 대해 논의할 것입니다.
데이터프레임 뷰와 복사본
데이터프레임의 슬라이스를 선택하고 변수에 할당할 때, 뷰나 새로운 데이터프레임 복사본을 얻을 수 있습니다.
뷰의 경우, 두 데이터프레임 간의 메모리가 공유됩니다. 이는 두 데이터프레임에 모두 존재하는 셀의 값을 수정하면 둘 다 수정된다는 것을 의미합니다.

복사본의 경우, 새로운 메모리가 할당되고 원본과 동일한 값을 가진 독립적인 데이터프레임이 생성됩니다. 이 경우, 두 데이터프레임은 구별된 엔티티이므로 한 데이터프레임의 값을 수정해도 다른 데이터프레임에 영향을 미치지 않습니다.
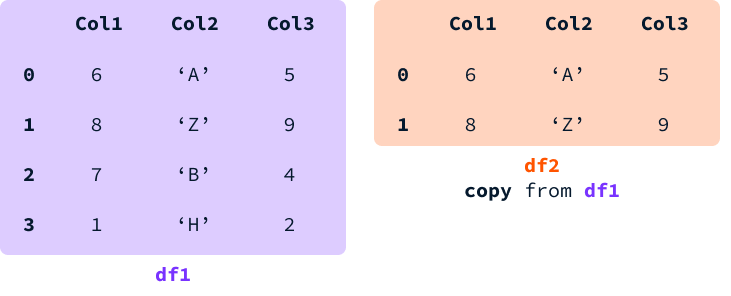
판다스는 성능을 최적화하기 위해 가능한 경우에는 복사본을 생성하지 않으려고 노력합니다. 그러나 미리 예측할 수 없기 때문에 뷰 또는 복사본을 얻을 수 있는지 알 수 없습니다. SettingWithCopyWarning은 DataFrame에 값을 할당할 때 해당 값이 다른 DataFrame의 뷰인지 복사본인지 명확하지 않은 경우에 발생합니다.
SettingWithCopyWarning을 실제 데이터로 이해하기
이번에는 이 Kaggle 데이터셋인 Real Estate Data London 2024을 사용하여 SettingWithCopyWarning가 발생하는 방법과 그 해결법을 배워보겠습니다.
이 데이터셋에는 런던의 최근 부동산 데이터가 포함되어 있습니다. 데이터셋에 있는 열의 개요는 다음과 같습니다:
addedOn: 목록이 추가된 날짜입니다.title: 목록의 제목입니다.descriptionHtml: 목록의 HTML 설명입니다.propertyType: 속성의 유형입니다. 유형이 지정되지 않은 경우 값은"Not Specified"입니다.sizeSqFeetMax: 평방 피트의 최대 크기입니다.bedrooms: 침실의 수입니다.listingUpdatedReason: 목록을 업데이트한 이유(예: 새 목록, 가격 인하)입니다.price: 파운드로 된 목록의 가격입니다.
명시적임시 변수를 사용한 예제
우리에게 특정하지 않은 속성 유형의 속성이 주택이라고 알려져 있다고 가정해 봅시다. 따라서 propertyType가 "Not Specified"인 모든 행을 "House"로 업데이트하고 싶습니다. 이 작업을 수행하는 한 가지 방법은 속성 유형이 지정되지 않은 행을 임시 DataFrame 변수로 필터링하고 다음과 같이 propertyType 열 값을 업데이트하는 것입니다:
import pandas as pd dataset_name = "realestate_data_london_2024_nov.csv" df = pd.read_csv(dataset_name) # 속성 유형이 지정되지 않은 행 모두 가져오기 no_property_type = df[df["propertyType"] == "Not Specified"] # 해당 행들의 속성 유형을 “House”로 업데이트 no_property_type["propertyType"] = "House"
이 코드를 실행하면 pandas가 SettingWithCopyWarning을 생성합니다:
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy no_property_type["propertyType"] = "House"
이는 pandas가 no_property_type DataFrame이 df의 뷰인지 아니면 복사본인지를 알 수 없기 때문입니다.
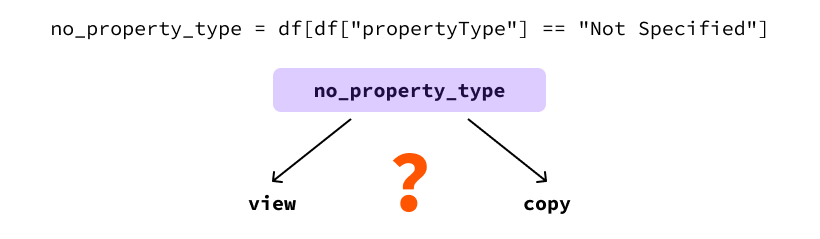
이는 df가 수정되었는지 여부에 따라 다음 코드의 동작이 매우 다를 수 있다는 문제입니다.
이 예에서 우리의 목표는 원본 DataFrame을 수정하는 것입니다. 이것은 no_property_type이 뷰인 경우에만 발생합니다. 코드의 나머지 부분이 df가 수정되었다고 가정한다면 이것이 사실인지 보장할 방법이 없기 때문에 잘못될 수 있습니다. 이러한 불확실한 동작 때문에 Pandas는 이 사실을 알려주기 위해 경고를 표시합니다.
코드가 뷰를 얻은 경우에도 정상적으로 실행되더라도 이후 실행에서 복사본을 얻을 수 있고 코드가 의도한 대로 작동하지 않을 수 있습니다. 따라서 이 경고를 무시하지 않고 항상 우리의 코드가 의도한 대로 작동하도록 보장해야 합니다.
임시 변수를 사용한 예시
이전 예시에서 임시 변수가 사용되고 있는 것이 명확합니다. 왜냐하면 DataFrame의 일부를 명시적으로 no_property_type이라는 변수에 할당하고 있기 때문입니다.
그러나 경우에 따라 이것이 그렇게 명확하지 않을 수도 있습니다. SettingWithCopyWarning이 발생하는 가장 흔한 예는 연쇄적 인덱싱일 때입니다. 마지막 두 줄을 한 줄로 대체한다고 가정해보겠습니다:
df[df["propertyType"] == "Not Specified"]["propertyType"] = "House"
첫눈에는 임시 변수가 생성되는 것 같지 않습니다. 그러나 실행하면 마찬가지로 SettingWithCopyWarning이 발생합니다.
이 코드가 실행되는 방식은 다음과 같습니다:
df[df["propertyType"] == "Not Specified"]가 평가되어 임시로 메모리에 저장됩니다.- 그 임시 메모리 위치의
["propertyType"]가 액세스됩니다.

인덱스 액세스는 하나씩 평가되며, 따라서 연쇄적 인덱싱은 중간 결과물이 뷰(view)인지 복사본(copy)인지 알 수 없기 때문에 동일한 경고가 발생합니다. 위의 코드는 사실상 다음을 수행하는 것과 동일합니다:
tmp = df[df["propertyType"] == "Not Specified"] tmp["propertyType"] = "House"
이 예시는 자주 연쇄적 인덱싱이라고 불리며, []를 사용하여 인덱스 액세스를 연결합니다. 먼저 [df["propertyType"] == "Not Specified"]에 접근한 다음 ["propertyType"]에 접근합니다.

SettingWithCopyWarning를 해결하는 방법
코드를 작성하는 방법을 배워봅시다. 모호함이 없고 SettingWithCopyWarning이 발생하지 않도록 합시다. 경고가 발생하는 이유는 DataFrame이 다른 DataFrame의 뷰(View)인지 복사본(Copy)인지에 대한 모호함에서 비롯된다는 것을 배웠습니다.
문제를 해결하는 방법은 원하는 경우 DataFrame이 복사본이 되도록 하거나 뷰가 되도록 하는 것을 보장하는 것입니다.
loc 를 사용하여 원본 DataFrame을 안전하게 수정하기
위의 예시에서 원본 DataFrame을 수정하려는 코드를 수정해 봅시다. 임시 변수를 사용하지 않고, loc 인덱서 속성을 사용하세요.
df.loc[df["propertyType"] == "Not Specified", "propertyType"] = "House"
이 코드를 사용하면, 우리는 loc 인덱서 속성을 통해 원본 df DataFrame에 직접 작용하므로 중간 변수가 필요하지 않습니다. 이것은 우리가 원본 DataFrame을 직접 수정하고 싶을 때 해야 할 일입니다.
첫눈에는 연쇄적인 인덱싱처럼 보일 수 있지만, 그렇지 않습니다. 각 인덱싱을 정의하는 것은 대괄호 []입니다.

loc을 사용할 때 값에 직접 할당하는 경우에만 안전합니다. 대신 임시 변수를 사용하는 경우에는 다시 같은 문제에 빠집니다. 문제를 해결하지 못하는 두 가지 코드 예시를 여기에 안내합니다:
- 임시 변수와 함께
loc사용하기:
# loc 및 임시 변수를 함께 사용해도 문제가 해결되지 않음 no_property_type = df.loc[df["propertyType"] == "Not Specified"] no_property_type["propertyType"] = "House"
loc을 인덱스와 함께 사용하기 (체인 인덱싱과 동일):
# loc 및 인덱싱을 함께 사용하는 것은 체인 인덱싱과 동일함 df.loc[df["propertyType"] == "Not Specified"]["propertyType"] = "House"
이러한 예제들은 사람들을 혼란스럽게 만들기 쉽습니다. loc이 있으면 원본 데이터가 수정된다고 하는 일반적인 오해가 있기 때문입니다. 이는 잘못된 생각입니다. 값을 원본 DataFrame에 할당하는 유일한 방법은 별도의 인덱싱 없이 단일 loc을 사용하여 직접 할당하는 것입니다.
copy()를 사용하여 원본 DataFrame의 사본과 안전하게 작업하기
데이터프레임의 사본에서 작동하는지 확인하려면 .copy() 메서드를 사용해야 합니다.
예를 들어, 속성의 단위당 가격을 분석해야 한다고 가정해 봅시다. 원본 데이터를 수정하고 싶지 않습니다. 다른 팀에게 보낼 분석 결과가 담긴 새로운 데이터프레임을 만드는 것이 목표입니다.
첫 번째 단계는 일부 행을 필터링하고 데이터를 정리하는 것입니다. 구체적으로 다음을 수행해야 합니다:
- sizeSqFeetMax가 정의되지 않은 행을 제거합니다.
price가"POA"(요청 시 가격)인 행을 제거합니다.- 가격을 숫자 값으로 변환합니다 (원본 데이터 세트에서 가격은 다음 형식의 문자열입니다:
"£25,000,000")
다음 코드를 사용하여 위의 단계를 수행할 수 있습니다:
# 1. 크기나 가격이 없는 모든 속성을 필터링합니다 properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")] # 2. 가격 열에서 £와 , 문자를 제거합니다 properties_with_size_and_price["price"] = properties_with_size_and_price["price"].str.replace("£", "", regex=False).str.replace(",", "", regex=False) # 3. 가격 열을 숫자 값으로 변환합니다 properties_with_size_and_price["price"] = pd.to_numeric(properties_with_size_and_price["price"])
제곱피트 당 가격을 계산하려면, price 열을 sizeSqFeetMax 열로 나눈 결과를 값으로 갖는 새 열을 생성합니다:
properties_with_size_and_price["pricePerSqFt"] = properties_with_size_and_price["price"] / properties_with_size_and_price["sizeSqFeetMax"]
이 코드를 실행하면 다시 SettingWithCopyWarning이 발생합니다. 이는 우리가 명시적으로 properties_with_size_and_price라는 임시 DataFrame 변수를 생성하고 수정했기 때문에 놀라운 일이 아닙니다.
우리는 원본 DataFrame이 아니라 데이터의 복사본에서 작업하기를 원하므로, properties_with_size_and_price가 뷰가 아닌 새로운 DataFrame 복사본이 되도록 .copy() 메서드를 사용하여 문제를 해결할 수 있습니다.첫 번째 줄에서:
properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")].copy()
안전하게 새로운 열 추가하기
새로운 열을 만드는 것은 값 할당과 동일하게 작동합니다. 복사본과 뷰 중 어떤 것을 작업하고 있는지 불명확할 때마다 pandas는 SettingWithCopyWarning을 발생시킵니다.
데이터의 사본을 사용하려면 .copy() 메서드를 사용하여 명시적으로 복사해야 합니다. 그런 다음, 원하는 방식으로 새 열을 할당할 수 있습니다. 이전 예제에서 pricePerSqFt 열을 생성할 때 이렇게 했습니다.
반면에, 원래 DataFrame을 수정하려면 고려해야 할 두 가지 경우가 있습니다.
- 새 열이 모든 행에 걸쳐 있는 경우, 원래 DataFrame을 직접 수정할 수 있습니다. 이는 행의 하위 집합을 선택하지 않기 때문에 경고가 발생하지 않습니다. 예를 들어, 주택 유형이 누락된 모든 행에
note열을 추가할 수 있습니다:
df["notes"] = df["propertyType"].apply(lambda house_type: "Missing house type" if house_type == "Not Specified" else "")
- 새 열이 일부 행에 대한 값만 정의하는 경우,
loc인덱서 속성을 사용할 수 있습니다. 예를 들면:
df.loc[df["propertyType"] == "Not Specified", "notes"] = "Missing house type"
이 경우에는 선택되지 않은 열의 값이 정의되지 않으므로 각 행마다 값을 지정할 수 있는 첫 번째 방법이 선호됩니다.
SettingWithCopyWarning 판다스 3.0에서 발생하는 오류
현재 SettingWithCopyWarning은 경고일 뿐이며 오류가 아닙니다. 우리의 코드는 여전히 실행되고, 판다스는 우리에게 주의를 줍니다.
공식 판다 문서에 따르면공식 판다 문서에 따르면, SettingWithCopyWarning는 3.0 버전부터 더 이상 사용되지 않고실제 오류로 대체되어 기본적으로 더 엄격한 코드 표준이 적용될 것입니다.
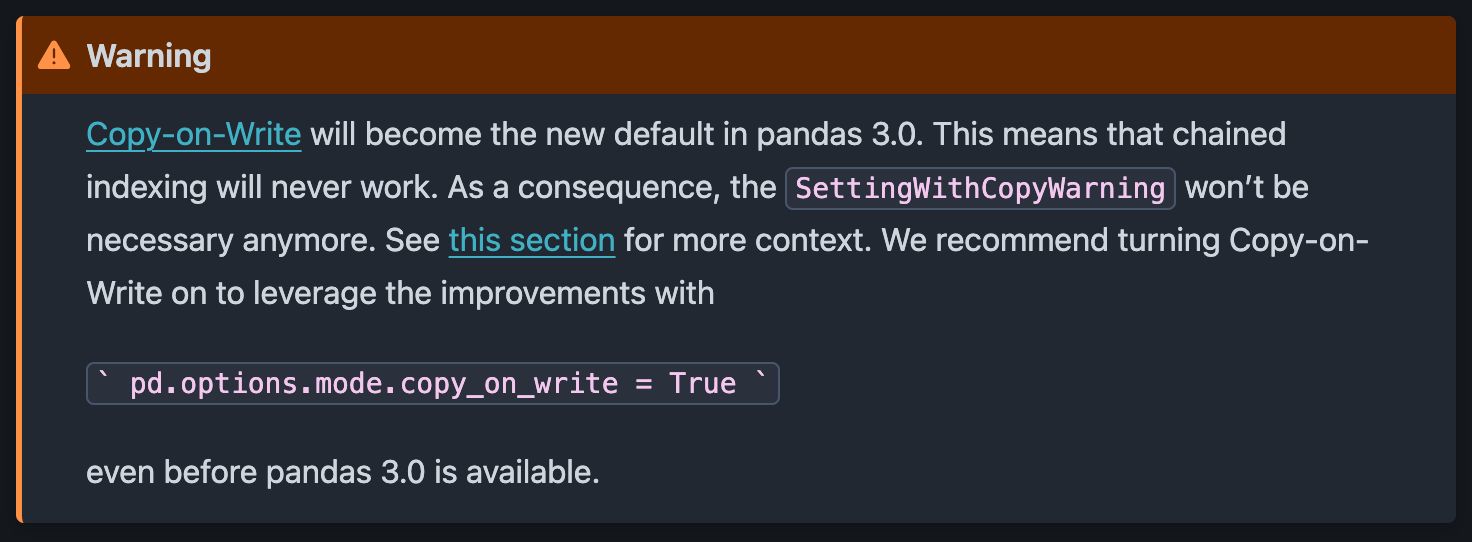
향후 판다 버전과 호환되도록 우리의 코드를 유지하려면 경고 대신 오류를 발생시키도록 이미 업데이트하는 것이 권장됩니다.
이는 pandas를 가져온 후 다음 옵션을 설정하여 수행됩니다:
import pandas as pd pd.options.mode.copy_on_write = True
기존 코드에 이를 추가하면 코드에서 각 애매한 할당을 처리하고 pandas 3.0으로 업데이트할 때 코드가 여전히 작동하는지 확인할 수 있습니다.
결론
SettingWithCopyWarning는 코드가 우리가 수정하고 있는 값이 뷰인지 복사본인지 애매할 때마다 발생합니다. 우리는 항상 우리가 원하는 것을 명확하게 함으로써 이를 수정할 수 있습니다:
- 복사본으로 작업하고 싶다면,
copy()메서드를 사용하여 명시적으로 복사해야 합니다. - 원본 DataFrame을 수정하고 싶다면,
loc인덱서 속성을 사용하고 중간 변수를 사용하지 않고 데이터에 접근할 때 값을 직접 할당해야 합니다.
오류가 아닌 것에도 불구하고, 이 경고를 무시해서는 안 됩니다. 이는 예상치 못한 결과를 초래할 수 있기 때문입니다. 게다가 Pandas 3.0부터는 기본적으로 오류로 간주될 것이므로, 현재 코드에서 pd.options.mode.copy_on_write = True를 사용하여 Copy-on-Write를 활성화함으로써 우리의 코드를 미래에 대비해야 합니다. 이렇게 하면 Pandas의 미래 버전에서도 코드가 정상적으로 작동할 수 있습니다.
Source:
https://www.datacamp.com/tutorial/settingwithcopywarning-pandas