













SettingWithCopyWarning – это предупреждение, которое может возникнуть в Pandas при выполнении присвоения к DataFrame. Это может произойти, когда мы используем цепные присвоения или при использовании DataFrame, созданного из среза. Это распространенное источник ошибок в коде Pandas, с которым мы все сталкивались раньше. Это может быть сложно отлаживать, потому что предупреждение может появиться в коде, который, казалось бы, должен работать нормально.
Понимание SettingWithCopyWarning важно, потому что это сигнализирует о потенциальных проблемах с манипулированием данными. Это предупреждение указывает на то, что ваш код может не изменять данные так, как задумано, что может привести к неожиданным последствиям и затруднить отслеживание ошибок.
В этой статье мы рассмотрим SettingWithCopyWarning в pandas и как избежать его. Мы также обсудим будущее Pandas и то, как опция copy_on_write изменит наше взаимодействие с DataFrames.
Представления и копии DataFrame
Когда мы выбираем срез DataFrame и присваиваем его переменной, мы можем получить либо представление, либо новую копию DataFrame.
С представлением память между обоими DataFrame общая. Это означает, что изменение значения ячейки, присутствующей в обоих DataFrame, изменит оба из них.

С копией выделяется новая память, и создается независимый DataFrame с теми же значениями, что и у оригинала. В этом случае оба DataFrame являются отдельными сущностями, поэтому изменение значения в одном из них не влияет на другой.
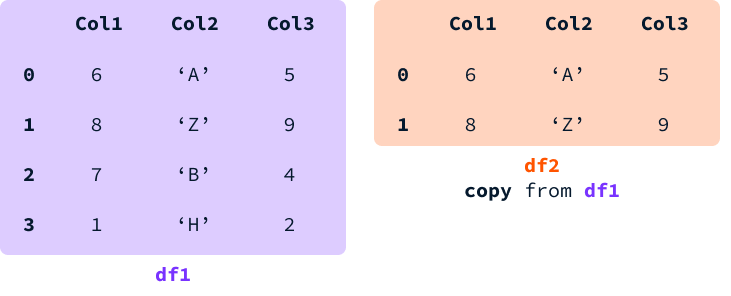
Пандас пытается избегать создания копии, когда это возможно, чтобы оптимизировать производительность. Однако заранее невозможно предсказать, получим ли мы представление или копию. Предупреждение SettingWithCopyWarning возникает всякий раз, когда мы присваиваем значение DataFrame, для которого неясно, является ли оно копией или представлением из другого DataFrame.
Понимание предупреждения SettingWithCopyWarning на реальных данных
Мы будем использовать набор данных Kaggle Real Estate Data London 2024, чтобы узнать, как возникает предупреждение SettingWithCopyWarning и как его исправить.
Этот набор данных содержит недавние данные о недвижимости из Лондона. Вот обзор столбцов, присутствующих в наборе данных:
addedOn: Дата добавления объявления.title: Название объявления.descriptionHtml: HTML-описание объявления.propertyType: Тип недвижимости. Значение будет"Not Specified", если тип не был указан.sizeSqFeetMax: Максимальный размер в квадратных футах.bedrooms: Количество спален.listingUpdatedReason: Причина обновления объявления (например, новое объявление, снижение цены).price: Цена объявления в фунтах.
Пример с явной временной переменной
Скажем, нам сказали, что объекты с неуказанным типом недвижимости являются домами. Поэтому мы хотим обновить все строки с propertyType, равным "Not Specified", на "House". Один из способов сделать это – отфильтровать строки с неуказанным типом недвижимости во временную переменную DataFrame и обновить значения столбца propertyType так:
import pandas as pd dataset_name = "realestate_data_london_2024_nov.csv" df = pd.read_csv(dataset_name) # Получить все строки с неуказанным типом недвижимости no_property_type = df[df["propertyType"] == "Not Specified"] # Обновить тип недвижимости на “House” в этих строках no_property_type["propertyType"] = "House"
Выполнение этого кода приведет к появлению предупреждения SettingWithCopyWarning:
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy no_property_type["propertyType"] = "House"
Причина в том, что pandas не может определить, является ли DataFrame no_property_type представлением или копией df.
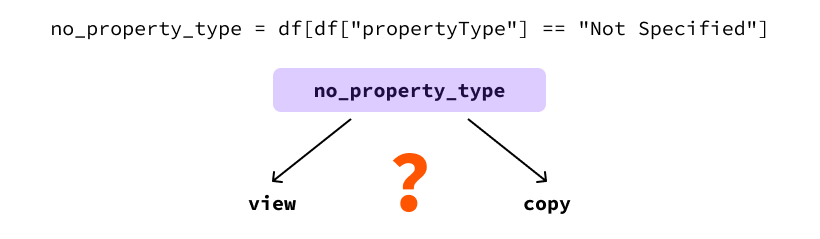
Проблема заключается в том, что поведение следующего кода может быть очень разным в зависимости от того, является ли это представлением или копией.
В данном примере наша цель – изменить исходный DataFrame. Это произойдет только в случае, если no_property_type является представлением. Если оставшаяся часть нашего кода предполагает, что df был изменен, это может быть неверно, потому что нет гарантии, что это так. Из-за этого неопределенного поведения Pandas выдает предупреждение, чтобы мы знали об этом факте.
Даже если наш код выполняется правильно из-за представления, мы можем получить копию при последующих запусках, и код не будет работать, как задумано. Поэтому важно не игнорировать это предупреждение и убедиться, что наш код всегда будет делать то, что мы от него хотим.
Пример с скрытой временной переменной
В предыдущем примере ясно, что используется временная переменная, потому что мы явно присваиваем часть DataFrame переменной с именем no_property_type.
Однако в некоторых случаях это не так явно. Самый распространенный пример возникновения предупреждения SettingWithCopyWarning – это цепная индексация. Предположим, что мы заменим последние две строки одной:
df[df["propertyType"] == "Not Specified"]["propertyType"] = "House"
На первый взгляд, не кажется, что создается временная переменная. Однако ее выполнение также приводит к предупреждению SettingWithCopyWarning.
Код выполняется следующим образом:
- Вычисляется и временно сохраняется
df[df["propertyType"] == "Not Specified"]. - Обращается к индексу
["propertyType"]в этом временном месте памяти.

Обращения к индексу вычисляются по одному, и поэтому цепная индексация приводит к тому же предупреждению, потому что мы не знаем, являются ли промежуточные результаты представлениями или копиями. Вышеуказанный код фактически эквивалентен следующему:
tmp = df[df["propertyType"] == "Not Specified"] tmp["propertyType"] = "House"
Этот пример часто называется цепной индексацией, потому что мы объединяем индексированные обращения, используя []. Сначала мы обращаемся к [df["propertyType"] == "Not Specified"], а затем к ["propertyType"].

Как решить предупреждение SettingWithCopyWarning
Давайте научимся писать наш код так, чтобы не было никакой неоднозначности и предупреждение SettingWithCopyWarning не срабатывало. Мы узнали, что предупреждение возникает из-за неоднозначности в отношении того, является ли DataFrame представлением или копией другого DataFrame.
Способ исправить это заключается в том, чтобы убедиться, что каждый DataFrame, который мы создаём, является копией, если мы хотим, чтобы это была копия, или представлением, если мы хотим, чтобы это было представление.
Безопасное изменение оригинального DataFrame с помощью свойства индексатора loc
Давайте исправим код из приведенного выше примера, где мы хотим изменить оригинальный DataFrame. Чтобы избежать использования временной переменной, используйте свойство индексатора loc.
df.loc[df["propertyType"] == "Not Specified", "propertyType"] = "House"
С помощью этого кода мы действуем непосредственно на исходном DataFrame df через свойство индексатора loc, поэтому нет необходимости в промежуточных переменных. Это то, что нам нужно делать, когда мы хотим изменить исходный DataFrame напрямую.
На первый взгляд это может показаться как цепное индексирование, потому что здесь все еще есть параметры, но это не так. Каждое индексирование определяется квадратными скобками [].

Обратите внимание, что использование loc безопасно только если мы непосредственно присваиваем значение, как мы сделали выше. Если же мы используем временную переменную, мы снова попадаем в ту же проблему. Вот два примера кода, которые не решают проблему:
- Использование
locс временной переменной:
# Использование loc вместе с временной переменной не решает проблему no_property_type = df.loc[df["propertyType"] == "Not Specified"] no_property_type["propertyType"] = "House"
- Использование
locвместе с индексом (так же, как цепной индекс):
# Использование loc вместе с индексированием эквивалентно цепному индексированию df.loc[df["propertyType"] == "Not Specified"]["propertyType"] = "House"
Оба эти примера часто вводят людей в заблуждение, потому что общепринято ошибочно считать, что если есть loc, мы изменяем исходные данные. Это неверно. Единственный способ гарантировать, что значение назначается исходному DataFrame, – это назначить его напрямую, используя один loc без дополнительного индексирования.
Безопасная работа с копией исходного DataFrame с помощью copy()
Когда мы хотим убедиться, что мы работаем с копией DataFrame, мы должны использовать метод .copy().
Предположим, что нас просят проанализировать цену за квадратный фут недвижимости. Мы не хотим изменять оригинальные данные. Цель – создать новый DataFrame с результатами анализа для отправки другой команде.
Первый шаг – отфильтровать некоторые строки и очистить данные. Конкретно, нам нужно:
- Удалите строки, где
sizeSqFeetMaxне определено. - Удалите строки, где
priceравна"POA"(цена по запросу). - Преобразуйте цены в числовые значения (в исходном наборе данных цены представлены строками в следующем формате:
"£25,000,000")
Мы можем выполнить вышеуказанные шаги, используя следующий код:
# 1. Отфильтруйте все объекты без размера или цены properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")] # 2. Удалите символы £ и , из столбцов цен properties_with_size_and_price["price"] = properties_with_size_and_price["price"].str.replace("£", "", regex=False).str.replace(",", "", regex=False) # 3. Преобразуйте столбец цен в числовые значения properties_with_size_and_price["price"] = pd.to_numeric(properties_with_size_and_price["price"])
Для расчета цены за квадратный фут мы создаем новый столбец, значения которого являются результатом деления столбца price на столбец sizeSqFeetMax:
properties_with_size_and_price["pricePerSqFt"] = properties_with_size_and_price["price"] / properties_with_size_and_price["sizeSqFeetMax"]
Если выполнить этот код, мы снова получим SettingWithCopyWarning. Это не должно вызывать удивление, потому что мы явно создали и изменили временную переменную DataFrame properties_with_size_and_price.
Поскольку мы хотим работать с копией данных, а не с исходным DataFrame, мы можем исправить проблему, убедившись, что properties_with_size_and_price является свежей копией DataFrame, а не представлением, используя метод .copy() в первой строке:
properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")].copy()
Безопасное добавление новых столбцов
Создание новых столбцов ведет себя так же, как присвоение значений. В случаях, когда неясно, работаем ли мы с копией или представлением, pandas выдает предупреждение SettingWithCopyWarning.
Если мы хотим работать с копией данных, нам следует явно скопировать их, используя метод .copy(). Затем мы можем свободно присвоить новый столбец так, как нам угодно. Мы сделали это, когда создали столбец pricePerSqFt в предыдущем примере.
С другой стороны, если мы хотим изменить исходный DataFrame, есть два случая для рассмотрения.
- Если новый столбец охватывает каждую строку, мы можем непосредственно изменить исходный DataFrame. Это не вызовет предупреждение, потому что мы не будем выбирать подмножество строк. Например, мы могли бы добавить столбец
noteдля каждой строки, где отсутствует тип дома:
df["notes"] = df["propertyType"].apply(lambda house_type: "Missing house type" if house_type == "Not Specified" else "")
- Если новый столбец определяет значения только для подмножества строк, тогда мы можем использовать свойство индексатора
loc. Например:
df.loc[df["propertyType"] == "Not Specified", "notes"] = "Missing house type"
Обратите внимание, что в этом случае значение в столбцах, которые не были выбраны, будет неопределенным, поэтому предпочтительнее первый подход, поскольку он позволяет нам указать значение для каждой строки.
Ошибка SettingWithCopyWarning в Pandas 3.0
На данный момент SettingWithCopyWarning является только предупреждением, а не ошибкой. Наш код по-прежнему выполняется, и Pandas просто информирует нас быть осторожными.
Согласно официальной документации Pandas, SettingWithCopyWarning больше не будет использоваться начиная с версии 3.0 и будет заменен на ошибку по умолчанию, что обеспечит более строгие стандарты кодирования.
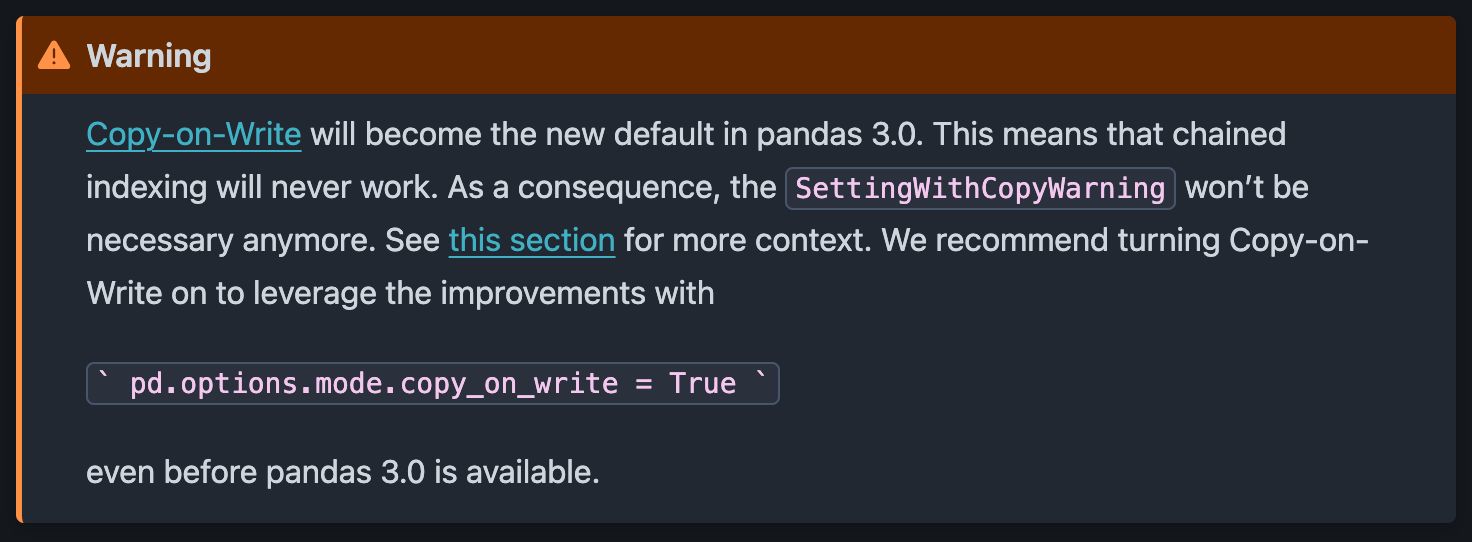
Чтобы убедиться, что наш код остается совместимым с будущими версиями pandas, рекомендуется уже сейчас обновить его, чтобы вызывать ошибку вместо предупреждения.
Это можно сделать, установив следующую опцию после импорта pandas:
import pandas as pd pd.options.mode.copy_on_write = True
Добавление этого в существующий код обеспечит обработку каждого неоднозначного присвоения в нашем коде и гарантирует, что код по-прежнему будет работать при обновлении до pandas 3.0.
Заключение
Предупреждение SettingWithCopyWarning возникает, когда в нашем коде неоднозначно, модифицируемое значение является представлением или копией. Мы можем исправить это, всегда явно указывая, что мы хотим:
- Если мы хотим работать с копией, мы должны явно скопировать ее, используя метод
copy(). - Если мы хотим изменить исходный DataFrame, мы должны использовать свойство индексатора
locи назначить значение непосредственно при доступе к данным без использования промежуточных переменных.
Несмотря на то, что это не ошибка, мы не должны игнорировать это предупреждение, потому что это может привести к неожиданным результатам. Более того, начиная с Pandas 3.0, по умолчанию это станет ошибкой, поэтому мы должны обеспечить защиту нашего кода в будущем, включив Copy-on-Write в нашем текущем коде, используя pd.options.mode.copy_on_write = True. Это гарантирует, что код будет функциональным для будущих версий Pandas.
Source:
https://www.datacamp.com/tutorial/settingwithcopywarning-pandas