













Scikit Learn
 Scikit-learn 是 Python 的機器學習庫。它包括幾個回歸、分類和聚類算法,包括支持向量機、梯度提升、k-means、隨機森林和DBSCAN。它設計為與 Python Numpy 和 SciPy 配合使用。Scikit-learn 項目始於由 David Cournapeau 在 Google 夏季程式碼營(也稱為 GSoC)中作為 scikits.learn 的項目。它的名稱來自於「Scikit」,這是 SciPy 的一個獨立的第三方擴展。
Scikit-learn 是 Python 的機器學習庫。它包括幾個回歸、分類和聚類算法,包括支持向量機、梯度提升、k-means、隨機森林和DBSCAN。它設計為與 Python Numpy 和 SciPy 配合使用。Scikit-learn 項目始於由 David Cournapeau 在 Google 夏季程式碼營(也稱為 GSoC)中作為 scikits.learn 的項目。它的名稱來自於「Scikit」,這是 SciPy 的一個獨立的第三方擴展。
Python Scikit-learn
Scikit 大部分用 Python 編寫,其中一些核心算法使用 Cython 編寫,以獲得更好的性能。Scikit-learn 用於構建模型,不建議用於讀取、操作和總結數據,因為有更好的框架可用於此目的。它是開源的,並釋出為 BSD 許可證。
安裝Scikit Learn
Scikit假設您的設備上運行著Python 2.7或以上版本,並且安裝了NumPY(1.8.2及以上版本)和SciPY(0.13.3及以上版本)軟件包。一旦安裝了這些軟件包,我們就可以繼續進行安裝。對於pip安裝,請在終端中運行以下命令:
pip install scikit-learn
如果您喜歡conda,您也可以使用conda進行包安裝,運行以下命令:
conda install scikit-learn
使用Scikit-Learn
安裝完成後,您可以在Python代碼中輕鬆使用scikit-learn,只需導入它:
import sklearn
Scikit Learn 加載數據集
讓我們從加載一個數據集開始。我們將加載一個簡單的數據集,名為Iris。這是一個關於花的數據集,包含了150個不同花的測量觀察。讓我們看看如何使用scikit-learn加載數據集。
# 導入 scikit learn
from sklearn import datasets
# 載入數據
iris= datasets.load_iris()
# 打印數據形狀以確認數據已載入
print(iris.data.shape)
我們打印數據形狀以便查看,如果您願意,也可以打印整個數據,運行代碼後會得到如下輸出: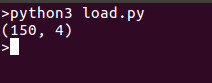
Scikit Learn SVM – 學習和預測
現在我們已經載入了數據,讓我們試著從中學習並對新數據進行預測。為此,我們必須創建一個估計器,然後調用其 fit 方法。
from sklearn import svm
from sklearn import datasets
# 載入數據集
iris = datasets.load_iris()
clf = svm.LinearSVC()
# 從數據中學習
clf.fit(iris.data, iris.target)
# 對未見過的數據進行預測
clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
# 通過使用帶下劃線結尾的屬性來更改模型的參數
print(clf.coef_ )
當我們運行此腳本時,我們得到以下結果: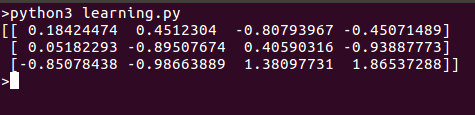
Scikit Learn 線性回歸
使用 scikit-learn 創建各種模型相當簡單。讓我們從一個簡單的回歸示例開始。
#匯入模型
from sklearn import linear_model
reg = linear_model.LinearRegression()
# 使用它來擬合數據
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# 讓我們查看擬合後的數據
print(reg.coef_)
運行模型應該返回一個可以繪製在同一條線上的點: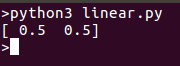
k-Nearest neighbour classifier
讓我們試一個簡單的分類算法。這個分類器使用基於球樹的算法來表示訓練樣本。
from sklearn import datasets
# 加載數據集
iris = datasets.load_iris()
# 創建並擬合最近鄰分類器
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target)
# 預測並打印結果
result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(result)
讓我們運行分類器並檢查結果,分類器應該返回0。讓我們試試這個例子:
K-means clustering
這是最簡單的聚類算法。集合被劃分為’k’個簇,每個觀察值被分配到一個簇中。這樣做是迭代的,直到簇收斂。我們將在下面的程序中創建一個這樣的聚類模型:
from sklearn import cluster, datasets
# 加載數據
iris = datasets.load_iris()
# 為k=3創建簇
k=3
k_means = cluster.KMeans(k)
# 擬合數據
k_means.fit(iris.data)
# 打印結果
print( k_means.labels_[::10])
print( iris.target[::10])
運行程序後,我們將在列表中看到不同的簇。以下是上述代碼片段的輸出: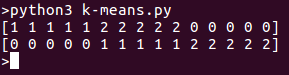
結論
在這個教程中,我們已經看到 Scikit-Learn 讓我們能夠輕鬆地使用多個機器學習算法。我們已經看到了回歸、分類和聚類的示例。Scikit-Learn 仍在開發階段,由志願者開發和維護,但在社區中非常受歡迎。去嘗試一下你自己的示例吧。
Source:
https://www.digitalocean.com/community/tutorials/python-scikit-learn-tutorial