













Scikit Learn
 Scikit-learn – это библиотека машинного обучения для Python. Она включает в себя несколько алгоритмов регрессии, классификации и кластеризации, включая метод опорных векторов (SVM), градиентный бустинг, k-средних, случайные леса и DBSCAN. Она разработана для совместной работы с библиотеками Python, такими как Numpy и SciPy. Проект scikit-learn стартовал как проект Google Summer of Code (также известный как GSoC) под руководством Дэвида Курнапо как scikits.learn. Его название произошло от “Scikit”, отдельного стороннего расширения для SciPy.
Scikit-learn – это библиотека машинного обучения для Python. Она включает в себя несколько алгоритмов регрессии, классификации и кластеризации, включая метод опорных векторов (SVM), градиентный бустинг, k-средних, случайные леса и DBSCAN. Она разработана для совместной работы с библиотеками Python, такими как Numpy и SciPy. Проект scikit-learn стартовал как проект Google Summer of Code (также известный как GSoC) под руководством Дэвида Курнапо как scikits.learn. Его название произошло от “Scikit”, отдельного стороннего расширения для SciPy.
Python Scikit-learn
Scikit написана на Python (в основном), и некоторые из ее основных алгоритмов написаны на Cython для еще более высокой производительности. Scikit-learn используется для создания моделей, и не рекомендуется использовать ее для чтения, манипулирования и обобщения данных, так как существуют более подходящие фреймворки для этих целей. Он является проектом с открытым исходным кодом и распространяется под лицензией BSD.
Установка Scikit Learn
Scikit предполагает, что у вас есть запущенная платформа Python 2.7 или выше с пакетами NumPY (1.8.2 и выше) и SciPY (0.13.3 и выше) на вашем устройстве. После установки этих пакетов мы можем приступить к установке. Для установки с помощью pip выполните следующую команду в терминале:
pip install scikit-learn
Если вы предпочитаете conda, вы также можете использовать conda для установки пакета, выполните следующую команду:
conda install scikit-learn
Использование Scikit-Learn
После завершения установки вы можете легко использовать scikit-learn в своем коде Python, импортировав его как:
import sklearn
Загрузка набора данных Scikit Learn
Давайте начнем с загрузки набора данных для работы. Давайте загрузим простой набор данных с именем Iris. Это набор данных о цветке, он содержит 150 наблюдений о различных измерениях цветка. Посмотрим, как загрузить набор данных с помощью scikit-learn.
# Импорт scikit learn
from sklearn import datasets
# Загрузка данных
iris= datasets.load_iris()
# Печать формы данных для подтверждения загрузки данных
print(iris.data.shape)
Мы выводим форму данных для удобства, вы также можете вывести все данные, если хотите, запуск кода дает вывод вот так: 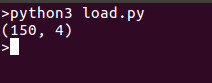
Scikit Learn SVM – Обучение и Прогнозирование
Теперь у нас загружены данные, давайте попробуем извлечь из них знания и предсказать на новых данных. Для этого нам нужно создать оценщика и затем вызвать его метод fit.
from sklearn import svm
from sklearn import datasets
# Загрузка набора данных
iris = datasets.load_iris()
clf = svm.LinearSVC()
# извлечение знаний из данных
clf.fit(iris.data, iris.target)
# предсказание для невидимых данных
clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
# Параметры модели можно изменить, используя атрибуты, заканчивающиеся подчеркиванием
print(clf.coef_ )
Вот что мы получаем, когда запускаем этот скрипт: 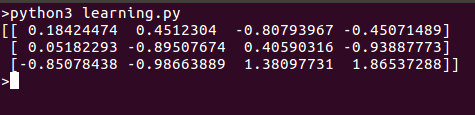
Scikit Learn Линейная Регрессия
Создание различных моделей довольно просто с использованием scikit-learn. Давайте начнем с простого примера регрессии.
#import модели
from sklearn import linear_model
reg = linear_model.LinearRegression()
# используйте ее для подгонки данных
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# Давайте посмотрим на подготовленные данные
print(reg.coef_)
Запуск модели должен вернуть точку, которую можно построить на той же линии: 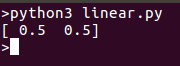
k-Nearest neighbour classifier
Давайте попробуем простой алгоритм классификации. Этот классификатор использует алгоритм, основанный на деревьях шаров, для представления обучающих выборок.
from sklearn import datasets
# Загрузка набора данных
iris = datasets.load_iris()
# Создание и подгонка классификатора ближайших соседей
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target)
# Предсказание и печать результата
result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(result)
Давайте запустим классификатор и проверим результаты, классификатор должен вернуть 0. Давайте попробуем пример: 
K-means clustering
Это самый простой алгоритм кластеризации. Набор делится на ‘k’ кластеров, и каждое наблюдение присваивается к кластеру. Это делается итеративно до сходимости кластеров. Мы создадим одну такую модель кластеризации в следующей программе:
from sklearn import cluster, datasets
# загрузка данных
iris = datasets.load_iris()
# создание кластеров для k=3
k=3
k_means = cluster.KMeans(k)
# подгонка данных
k_means.fit(iris.data)
# печать результатов
print( k_means.labels_[::10])
print( iris.target[::10])
При запуске программы мы увидим отдельные кластеры в списке. Вот вывод для приведенного выше фрагмента кода: 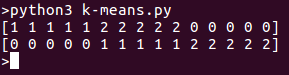
Заключение
В этом учебнике мы видели, что Scikit-Learn облегчает работу с несколькими алгоритмами машинного обучения. Мы видели примеры регрессии, классификации и кластеризации. Scikit-Learn все еще находится в фазе разработки и разрабатывается и поддерживается добровольцами, но очень популярен в сообществе. Попробуйте сами написать свои примеры.
Source:
https://www.digitalocean.com/community/tutorials/python-scikit-learn-tutorial