













Scikit Learn
 Scikit-learn é uma biblioteca de aprendizado de máquina para Python. Possui vários algoritmos de regressão, classificação e agrupamento, incluindo SVMs, aumento de gradiente, k-means, florestas aleatórias e DBSCAN. Foi projetado para funcionar com Python Numpy e SciPy. O projeto scikit-learn começou como um projeto do Google Summer of Code (também conhecido como GSoC) por David Cournapeau como scikits.learn. Ele recebeu seu nome de “Scikit”, uma extensão de terceiros separada para o SciPy.
Scikit-learn é uma biblioteca de aprendizado de máquina para Python. Possui vários algoritmos de regressão, classificação e agrupamento, incluindo SVMs, aumento de gradiente, k-means, florestas aleatórias e DBSCAN. Foi projetado para funcionar com Python Numpy e SciPy. O projeto scikit-learn começou como um projeto do Google Summer of Code (também conhecido como GSoC) por David Cournapeau como scikits.learn. Ele recebeu seu nome de “Scikit”, uma extensão de terceiros separada para o SciPy.
Python Scikit-learn
Scikit é escrito em Python (na maior parte) e alguns de seus algoritmos principais são escritos em Cython para um desempenho ainda melhor. Scikit-learn é usado para construir modelos e não é recomendado para leitura, manipulação e resumo de dados, já que existem estruturas melhores disponíveis para esse fim. É de código aberto e lançado sob a licença BSD.
Instalar o Scikit Learn
O Scikit assume que você tem uma plataforma Python 2.7 ou superior em execução com os pacotes NumPY (1.8.2 ou superior) e SciPY (0.13.3 ou superior) em seu dispositivo. Uma vez que tenhamos esses pacotes instalados, podemos prosseguir com a instalação. Para instalação via pip, execute o seguinte comando no terminal:
pip install scikit-learn
Se você prefere o conda, também pode usar o conda para a instalação do pacote, execute o seguinte comando:
conda install scikit-learn
Usando o Scikit-Learn
Assim que terminar a instalação, você pode usar o scikit-learn facilmente em seu código Python importando-o como:
import sklearn
Carregando Conjunto de Dados do Scikit Learn
Vamos começar carregando um conjunto de dados para brincar. Vamos carregar um conjunto de dados simples chamado Iris. É um conjunto de dados de uma flor, contendo 150 observações sobre diferentes medidas da flor. Vamos ver como carregar o conjunto de dados usando o scikit-learn.
# Importar scikit learn
from sklearn import datasets
# Carregar dados
iris= datasets.load_iris()
# Imprimir forma dos dados para confirmar que os dados foram carregados
print(iris.data.shape)
Estamos imprimindo a forma dos dados para facilitar, você também pode imprimir todos os dados se desejar, executar os códigos gera uma saída como esta: 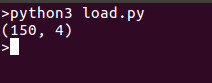
Scikit Learn SVM – Aprendizado e Previsão
Agora que carregamos os dados, vamos tentar aprender com eles e prever novos dados. Para isso, precisamos criar um estimador e depois chamar seu método de ajuste.
from sklearn import svm
from sklearn import datasets
# Carregar conjunto de dados
iris = datasets.load_iris()
clf = svm.LinearSVC()
# Aprender a partir dos dados
clf.fit(iris.data, iris.target)
# Prever para dados não vistos
clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
# Os parâmetros do modelo podem ser alterados usando os atributos que terminam com um sublinhado
print(clf.coef_ )
Aqui está o que obtemos quando executamos este script: 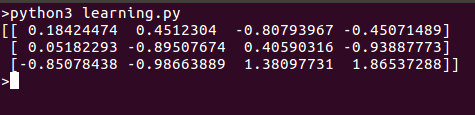
Regressão Linear do Scikit Learn
É bastante simples criar vários modelos usando o scikit-learn. Vamos começar com um exemplo simples de regressão.
#importar o modelo
from sklearn import linear_model
reg = linear_model.LinearRegression()
# usá-lo para ajustar um conjunto de dados
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# Vamos analisar os dados ajustados
print(reg.coef_)
A execução do modelo deve retornar um ponto que pode ser plotado na mesma linha: 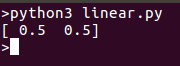
k-Nearest neighbour classifier
Vamos tentar um algoritmo de classificação simples. Este classificador utiliza um algoritmo baseado em árvores de esferas para representar as amostras de treinamento.
from sklearn import datasets
# Carregar conjunto de dados
iris = datasets.load_iris()
# Criar e ajustar um classificador de vizinho mais próximo
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target)
# Prever e imprimir o resultado
result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(result)
Vamos executar o classificador e verificar os resultados; o classificador deve retornar 0. Vamos tentar o exemplo: 
K-means clustering
Este é o algoritmo de agrupamento mais simples. O conjunto é dividido em ‘k’ clusters e cada observação é atribuída a um cluster. Isso é feito iterativamente até que os clusters converjam. Vamos criar um modelo de agrupamento assim no programa a seguir:
from sklearn import cluster, datasets
# carregar dados
iris = datasets.load_iris()
# criar clusters para k=3
k=3
k_means = cluster.KMeans(k)
# ajustar dados
k_means.fit(iris.data)
# imprimir resultados
print( k_means.labels_[::10])
print( iris.target[::10])
Ao executar o programa, veremos clusters separados na lista. Aqui está a saída para o trecho de código acima: 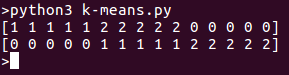
Conclusão
Neste tutorial, vimos que o Scikit-Learn facilita o trabalho com vários algoritmos de aprendizado de máquina. Vimos exemplos de Regressão, Classificação e Agrupamento. O Scikit-Learn ainda está em fase de desenvolvimento e sendo desenvolvido e mantido por voluntários, mas é muito popular na comunidade. Vá e tente seus próprios exemplos.
Source:
https://www.digitalocean.com/community/tutorials/python-scikit-learn-tutorial