













设置 AWS CLI 和 AWS S3
在深入了解 aws s3 cp 命令之前,您需要在系统上安装并正确配置 AWS CLI。如果您以前没有使用过 AWS – 不用担心,安装过程很简单,不到10分钟就可以完成。
我将这个过程分解为三个简单阶段:安装 AWS CLI 工具,配置您的凭据,以及为存储创建您的第一个 S3 存储桶。
安装 AWS CLI
安装过程根据您使用的操作系统略有不同。
对于 Windows 系统:
- 导航至官方 AWS CLI 文档页面
- 下载 64 位 Windows 安装程序
- 启动下载的文件并按照安装向导进行安装
对于 Linux 系统:
通过终端运行以下三个命令:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
对于 macOS 系统:
假设您已经安装了 Homebrew,请在终端中运行以下一行命令:
brew install awscli
如果您没有安装 Homebrew,请使用以下两条命令代替:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
要确认安装成功,请在终端中运行 aws --version。您应该会看到类似这样的内容:
图片 1 – AWS CLI 版本
配置 AWS CLI
安装 CLI 后,现在是时候为身份验证设置 AWS 凭据了。
首先,访问您的 AWS 帐户并导航至 IAM 服务仪表板。创建一个具有程序化访问权限的新用户,并附加适当的 S3 权限策略:
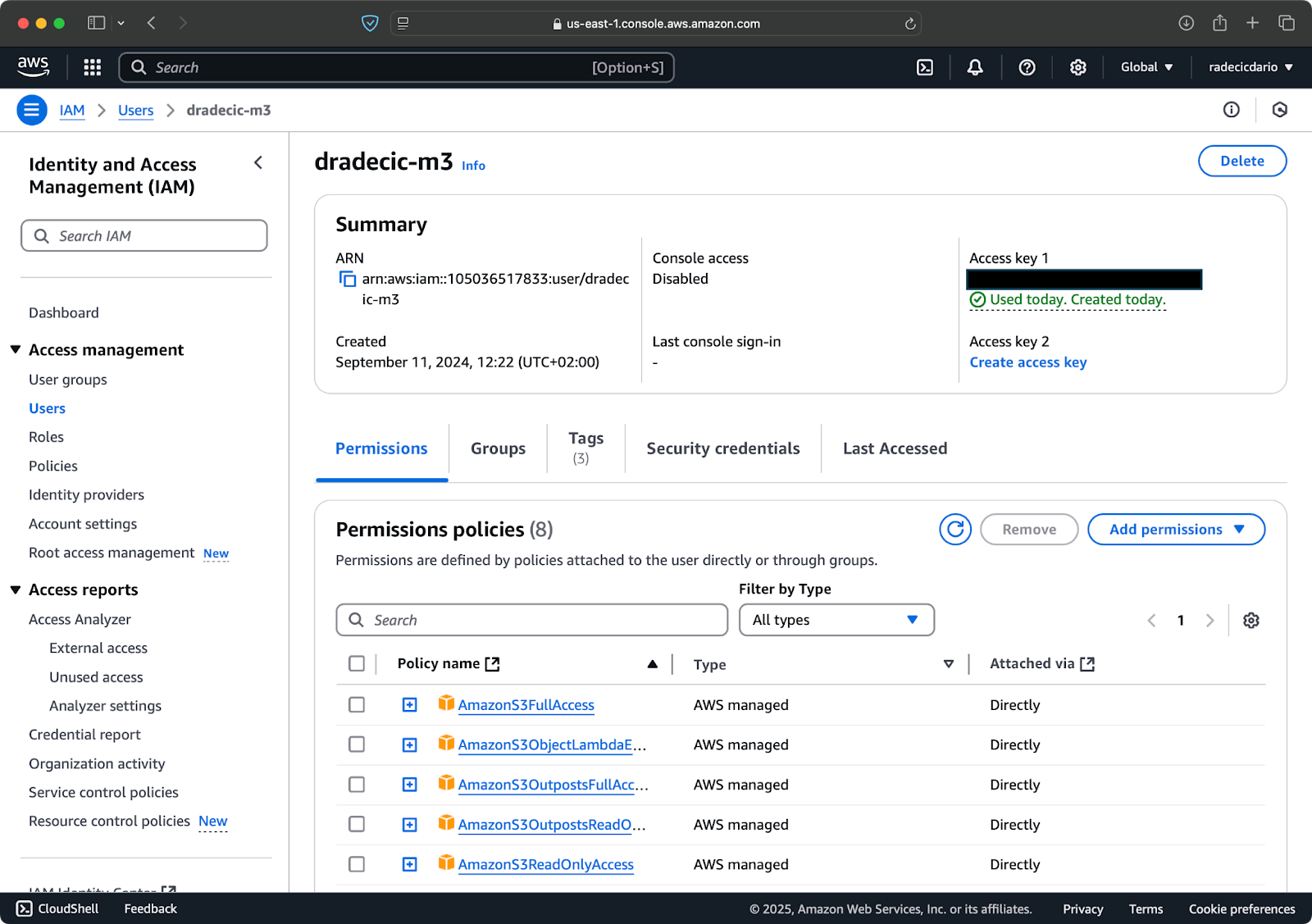
图片 2 – AWS IAM 用户
接下来,访问 “安全凭证” 选项卡并生成一个新的访问密钥对。确保将访问密钥 ID 和秘密访问密钥都保存在安全的地方 – 在此屏幕之后,亚马逊将不会再显示您的秘密密钥:
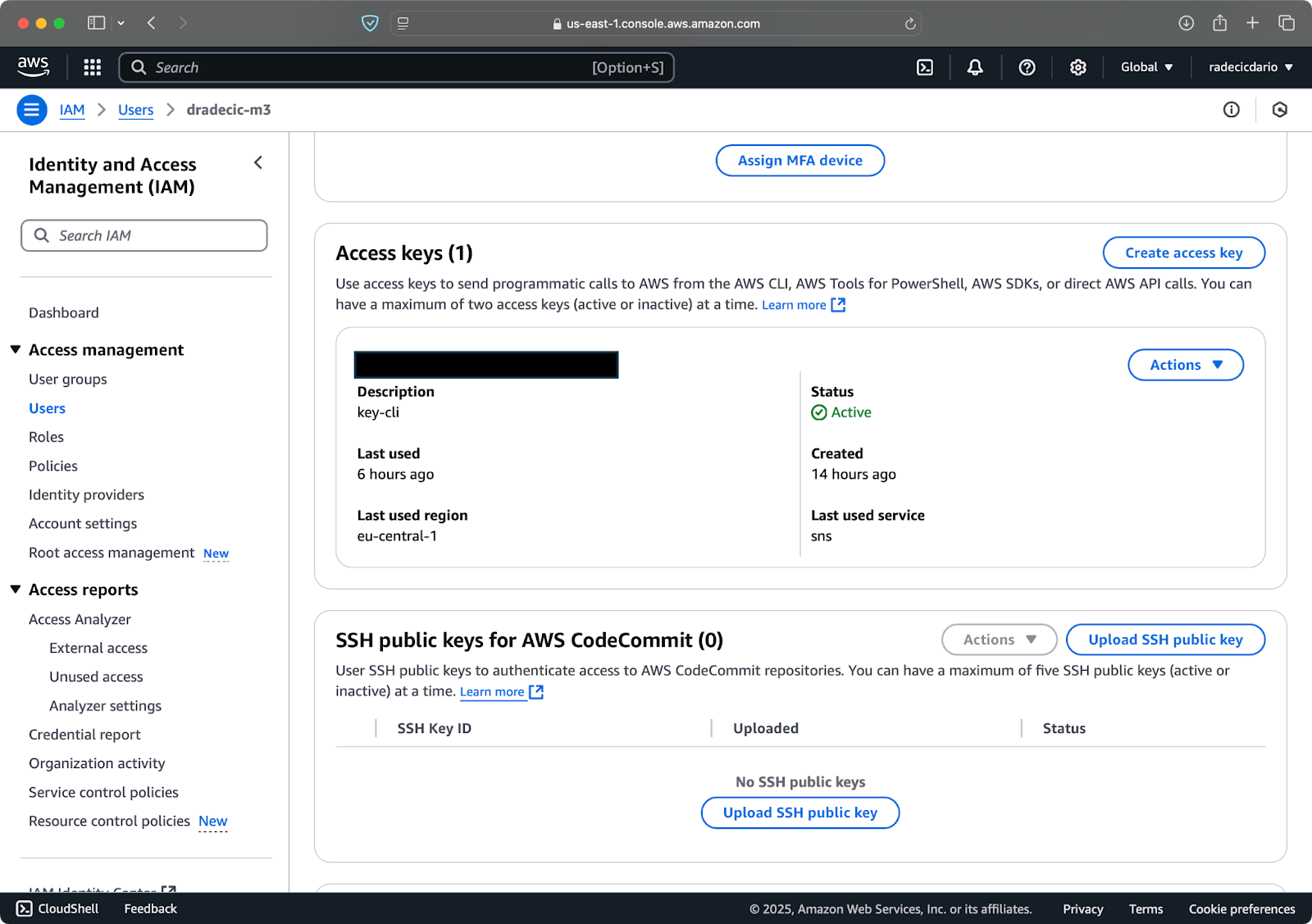
图片 3 – AWS IAM 用户凭据
现在打开您的终端并执行aws configure命令。您将被要求输入四个信息:您的访问密钥ID,秘密访问密钥,默认区域(我在使用eu-central-1),和首选输出格式(通常为json):
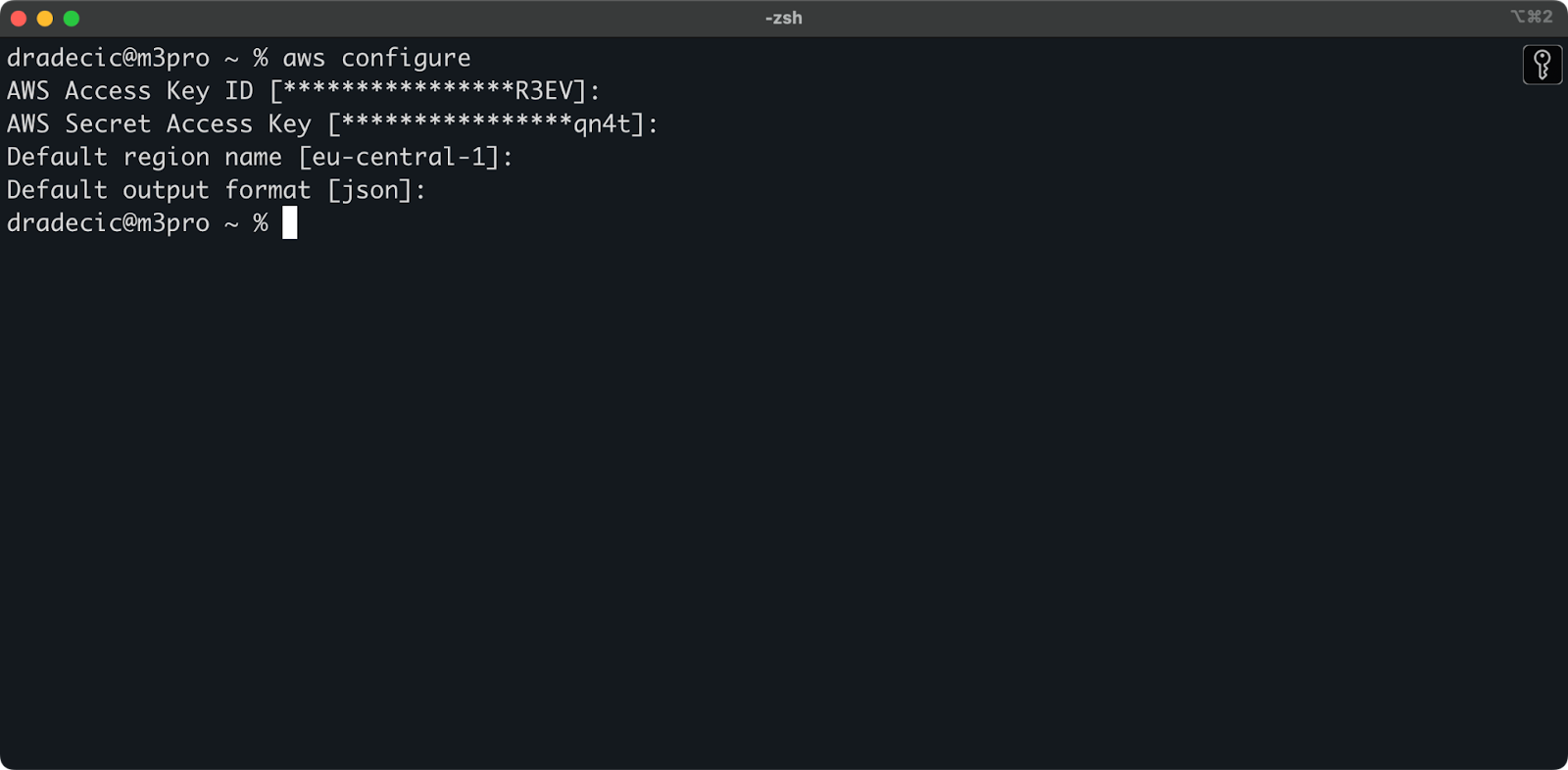
图片4 – AWS CLI配置
为了确保一切连接正确,使用以下命令验证您的身份:
aws sts get-caller-identity
如果配置正确,您将看到您的账户详情:
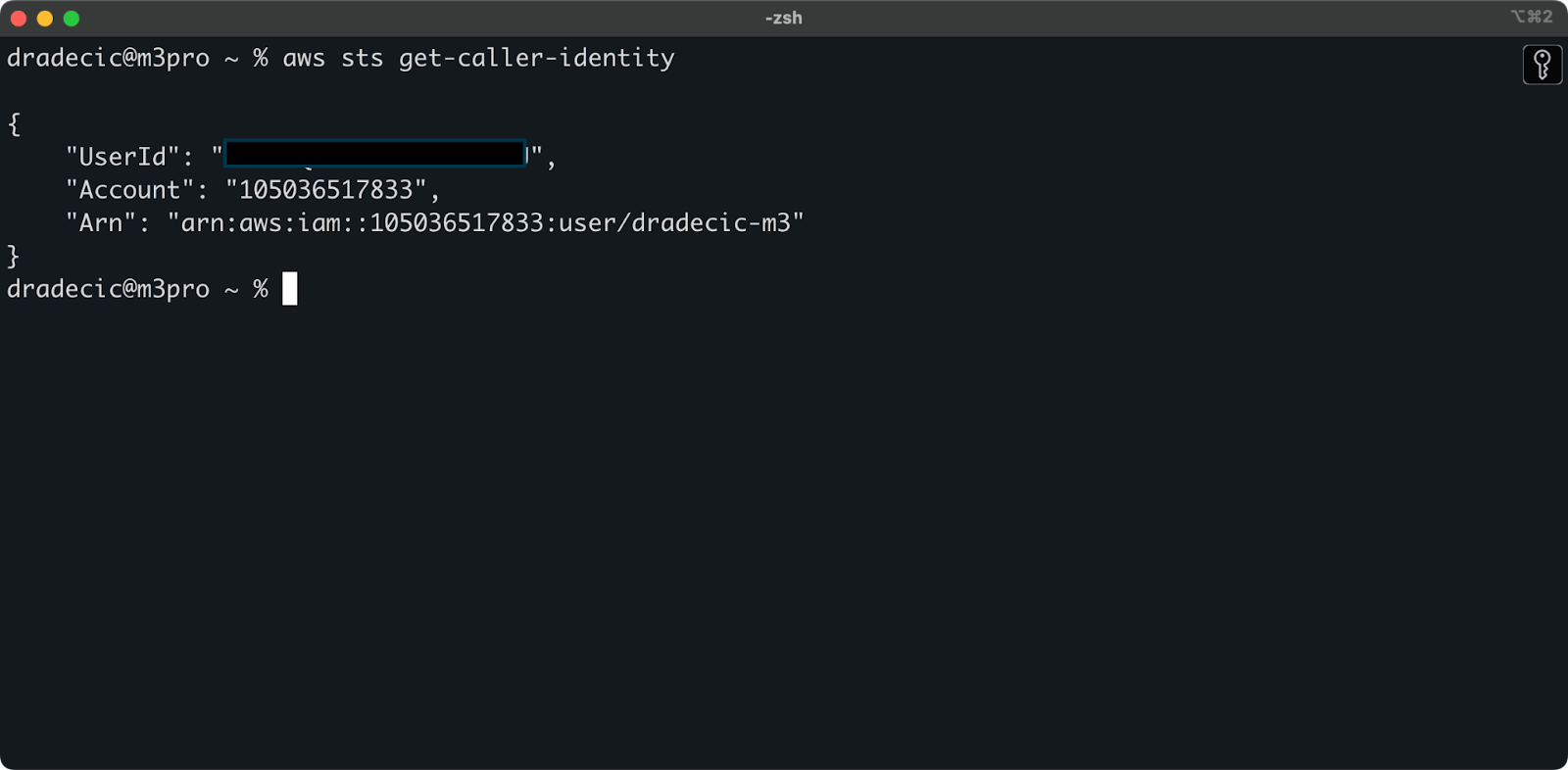
图片5 – AWS CLI测试连接命令
创建一个S3存储桶
最后,您需要创建一个S3存储桶来存储您将要复制的文件。
前往AWS控制台中的S3服务部分,然后点击“创建存储桶”。请记住,存储桶名称必须在AWS范围内是全局唯一的。选择一个独特的名称,现在保留默认设置,然后点击“创建”:
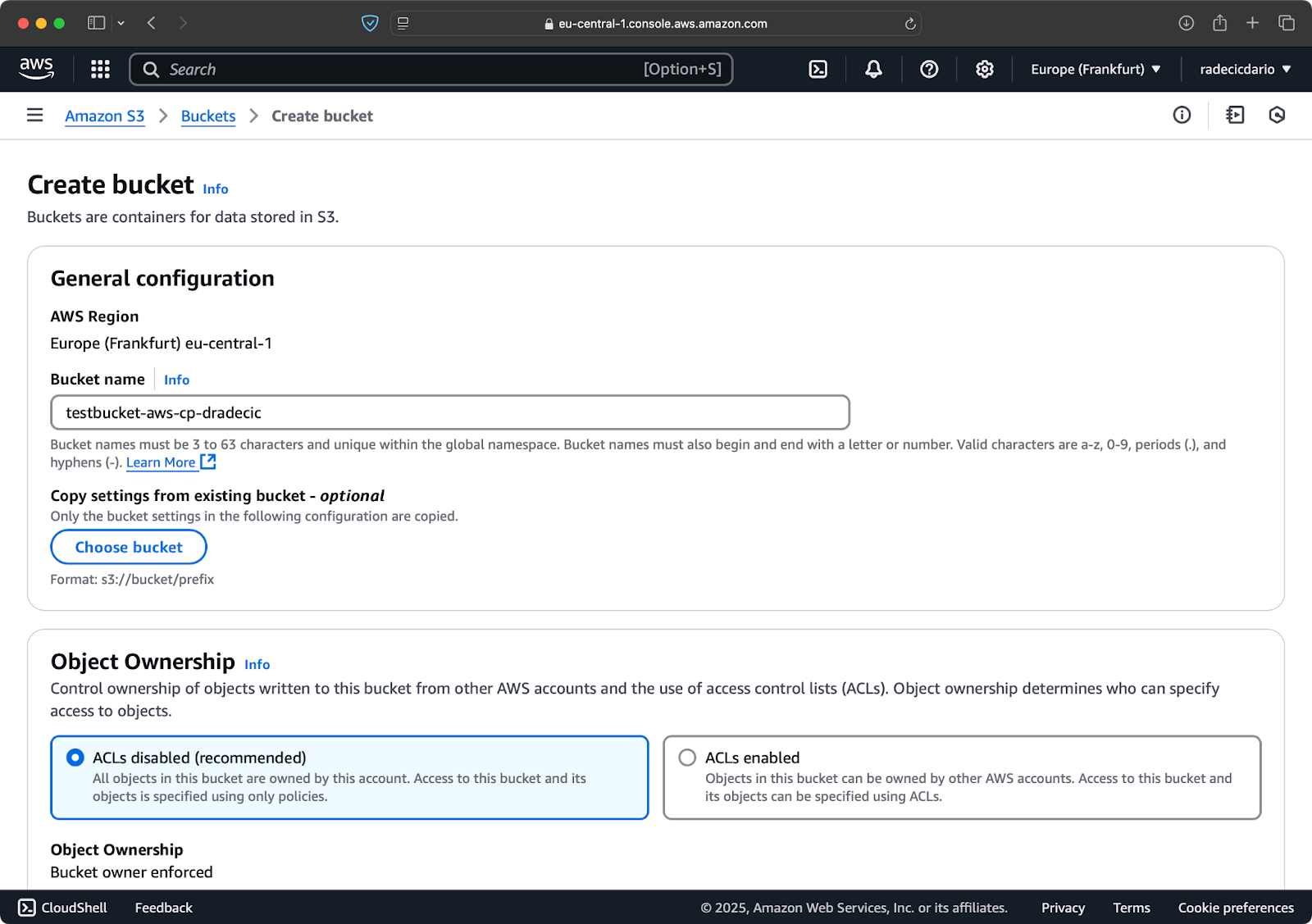
图片6 – AWS存储桶创建
创建完成后,您的新存储桶将出现在控制台中。您也可以通过命令行确认其存在:
aws s3 ls
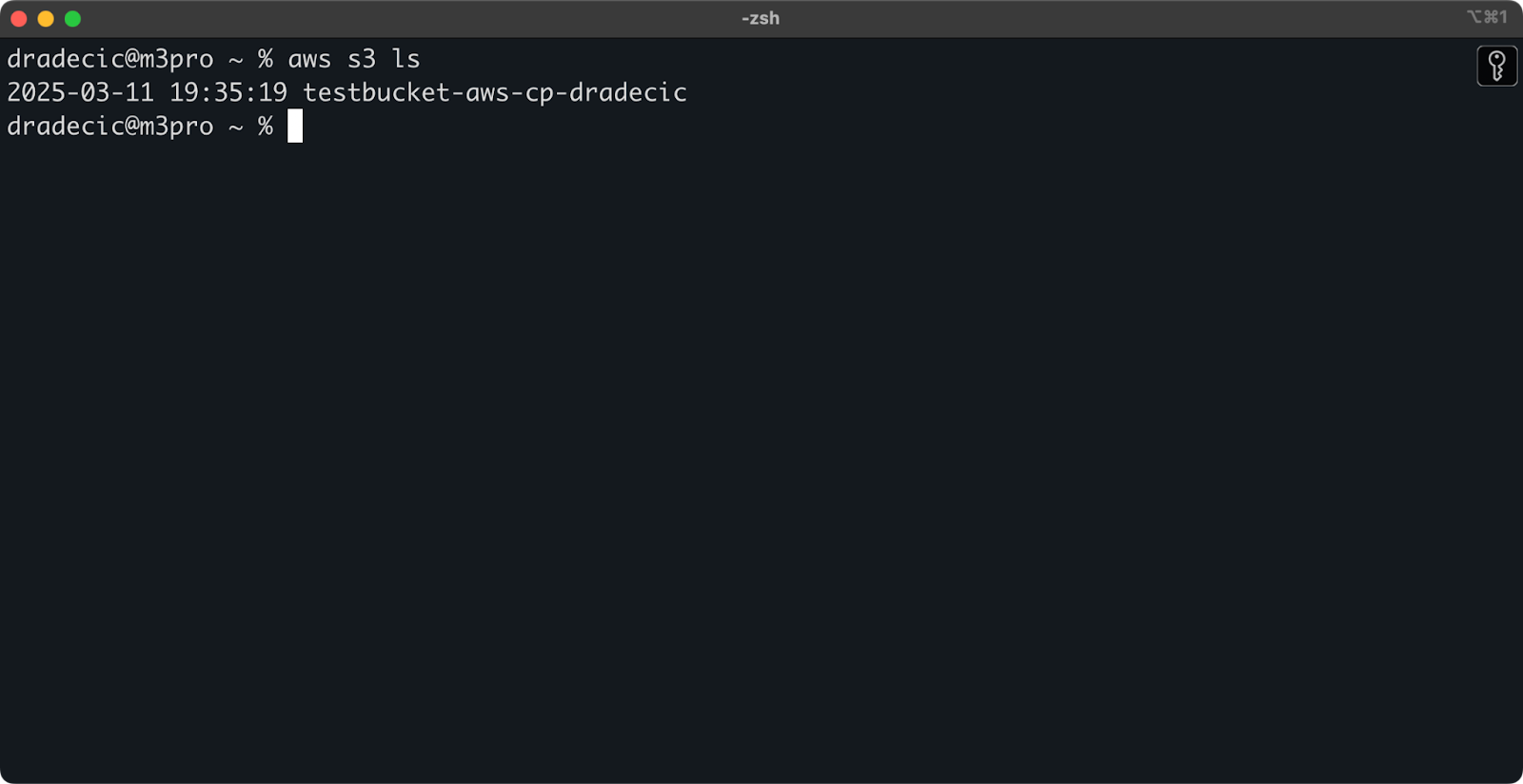
图片7 – 所有可用的S3存储桶
所有S3存储桶默认为私有,所以请记住这一点。如果您打算将这个存储桶用于可以公开访问的文件,您需要相应地修改存储桶策略。
现在您已经完全准备好开始使用aws s3 cp命令来传输文件。让我们接下来从基础开始。
基本的AWS S3 cp命令语法
现在您已经配置好了所有内容,让我们深入了解aws s3 cp命令的基本用法。与AWS一贯的风格一样,其美妙之处在于简单,即使该命令可以处理不同的文件传输场景。
在其最基本的形式中,aws s3 cp命令遵循以下语法:
aws s3 cp <source> <destination> [options]
其中<source>和<destination>可以是本地文件路径或S3 URI(以s3://开头)。让我们探索一下最常见的三种用法。
从本地复制文件到S3
要将文件从本地系统复制到S3存储桶,源将是本地路径,目标将是S3 URI:
aws s3 cp /Users/dradecic/Desktop/test_file.txt s3://testbucket-aws-cp-dradecic/test_file.txt
此命令将上传文件test_file.txt从提供的目录到指定的S3存储桶。如果操作成功,您将看到如下控制台输出:
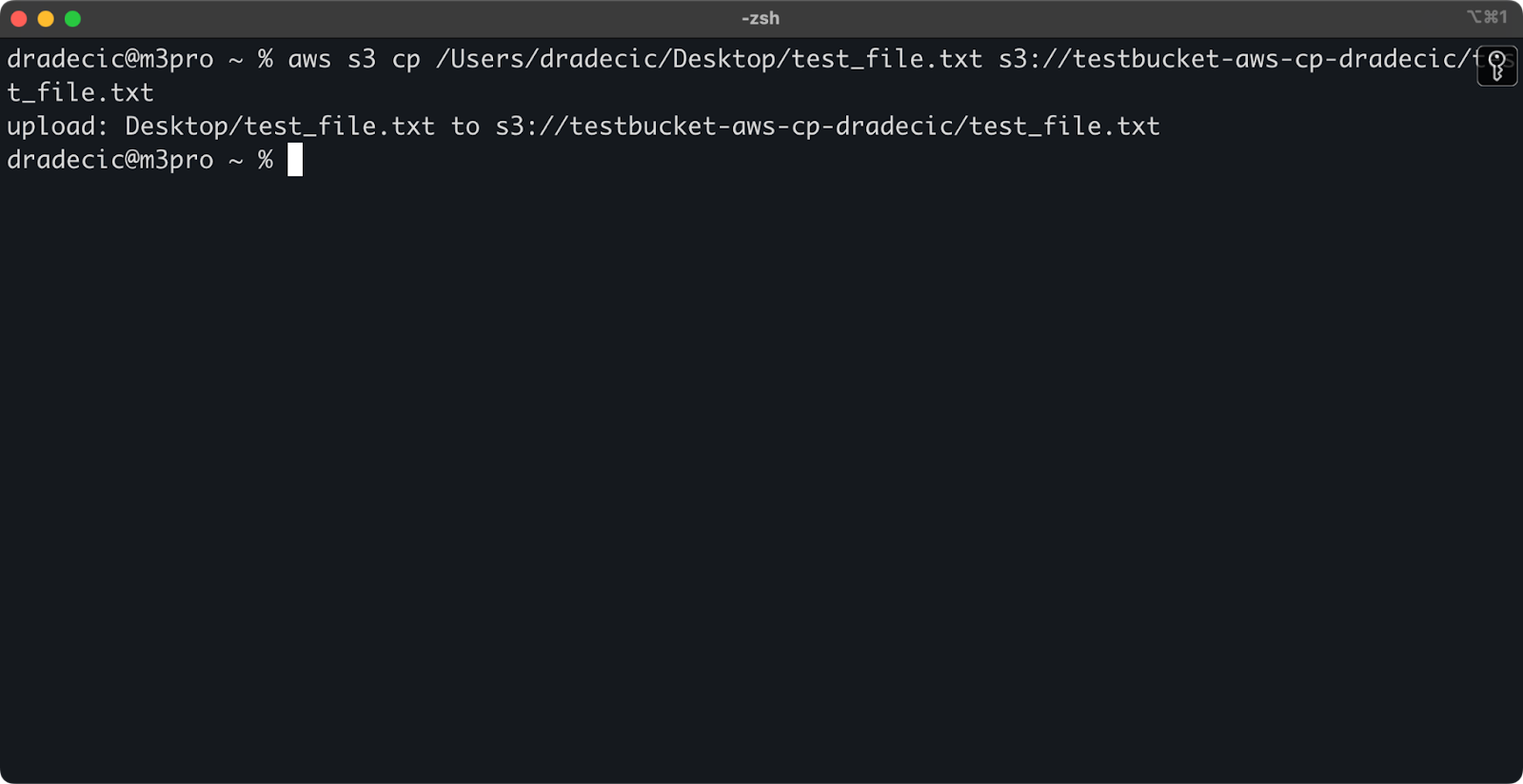
图8 – 复制本地文件后的控制台输出
在AWS管理控制台上,您将看到您上传的文件:
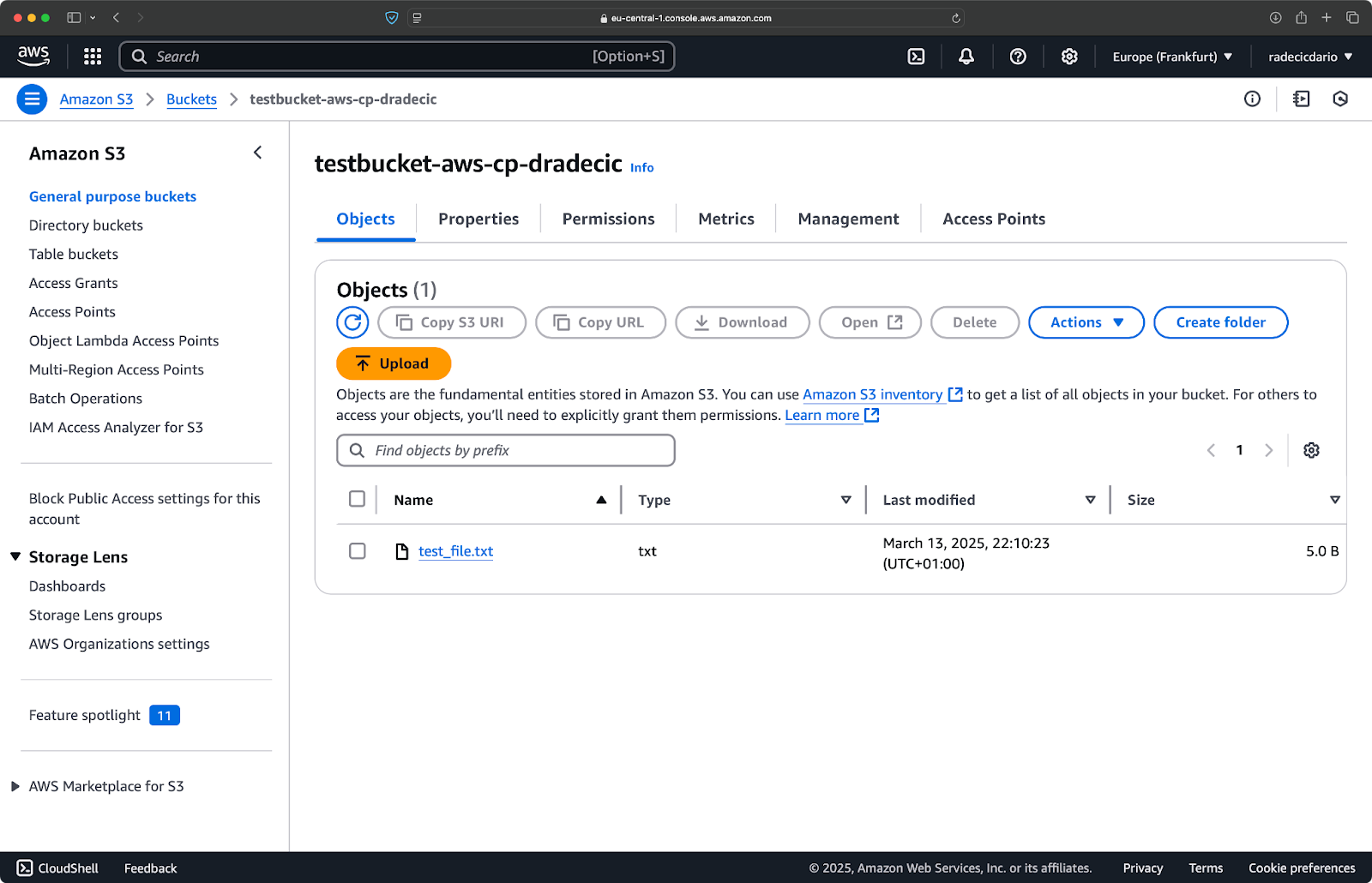
图9 – S3存储桶内容
类似地,如果您想要将本地文件夹复制到您的S3存储桶,并将其放在另一个嵌套文件夹中,可以运行类似于以下命令:
aws s3 cp /Users/dradecic/Desktop/test_folder s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder/ --recursive
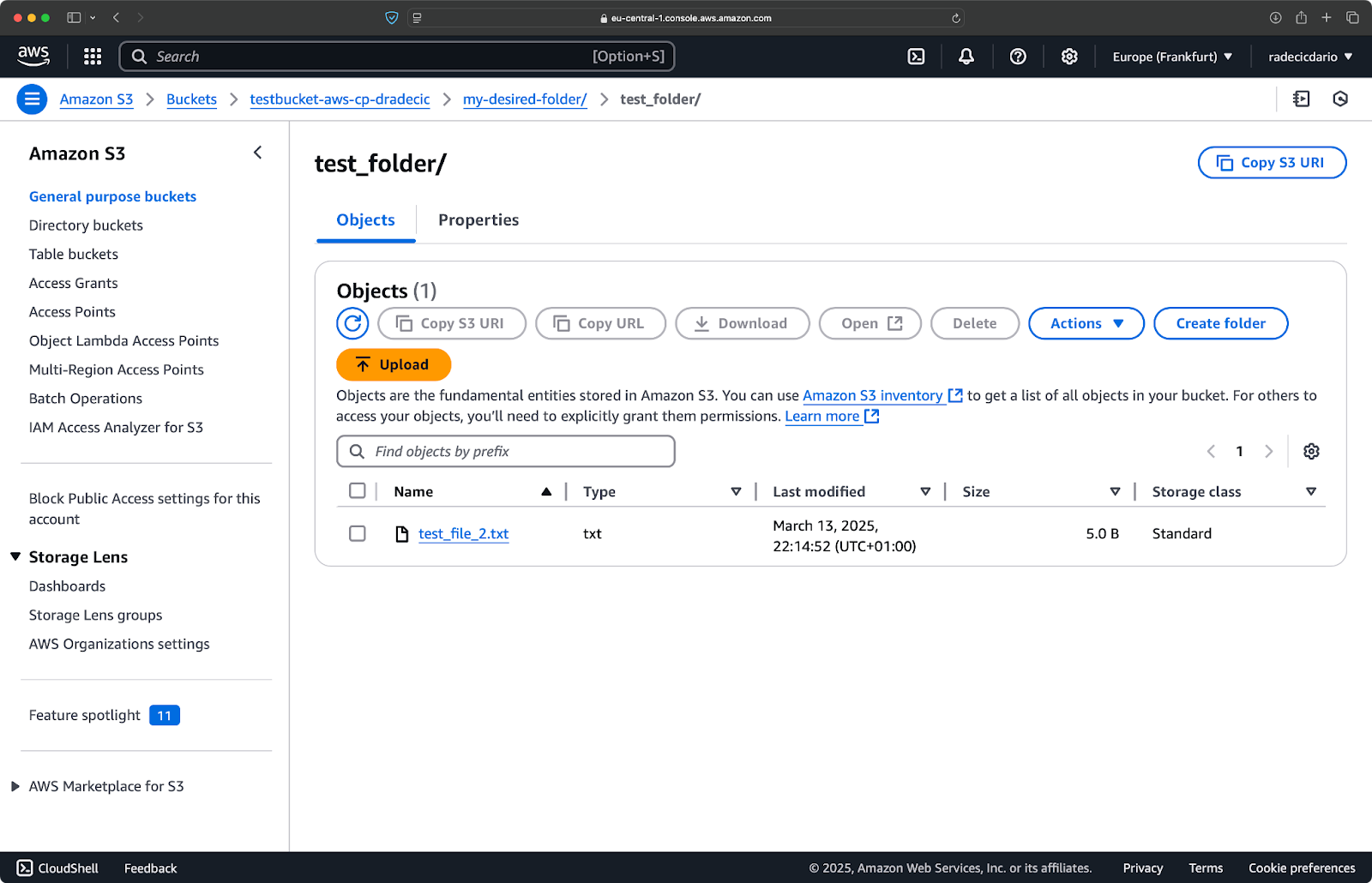
图10 – 上传文件夹后的S3存储桶内容
--recursive标志将确保复制文件夹内的所有文件和子文件夹。
请记住 – S3实际上并没有文件夹 – 路径结构只是对象键的一部分,但它在概念上像文件夹一样运作。
从S3复制文件到本地
将文件从S3复制到本地系统,只需颠倒顺序 – 源变成S3 URI,目标为本地路径:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt /Users/dradecic/Documents/s3-data/downloaded_test_file.txt
此命令将从您的S3存储桶下载test_file.txt并将其保存为提供的目录中的downloaded_test_file.txt。您会立即在本地系统中看到它:
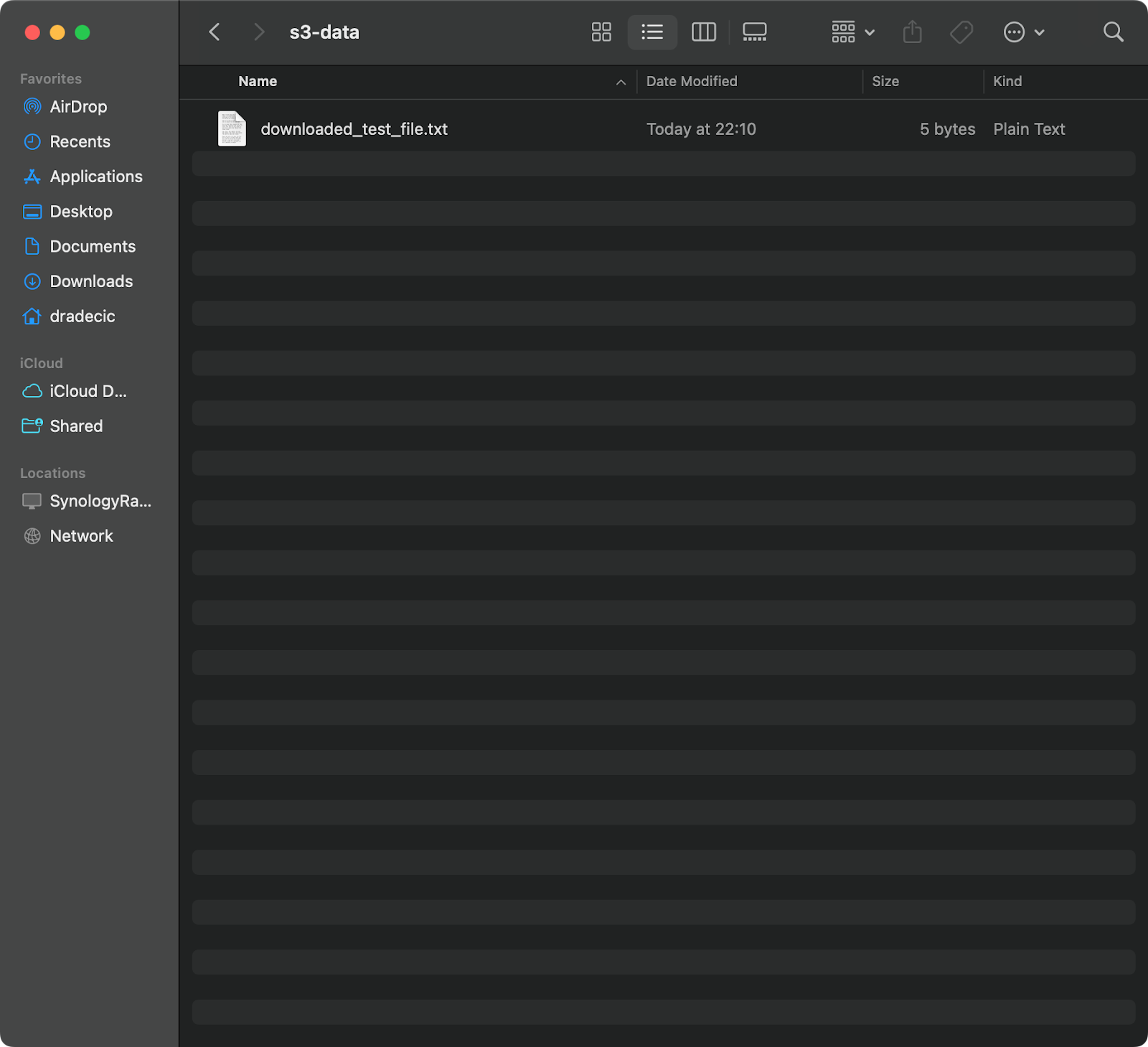
图像11 – 从S3下载单个文件
如果省略目标文件名,命令将使用原始文件名:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt .
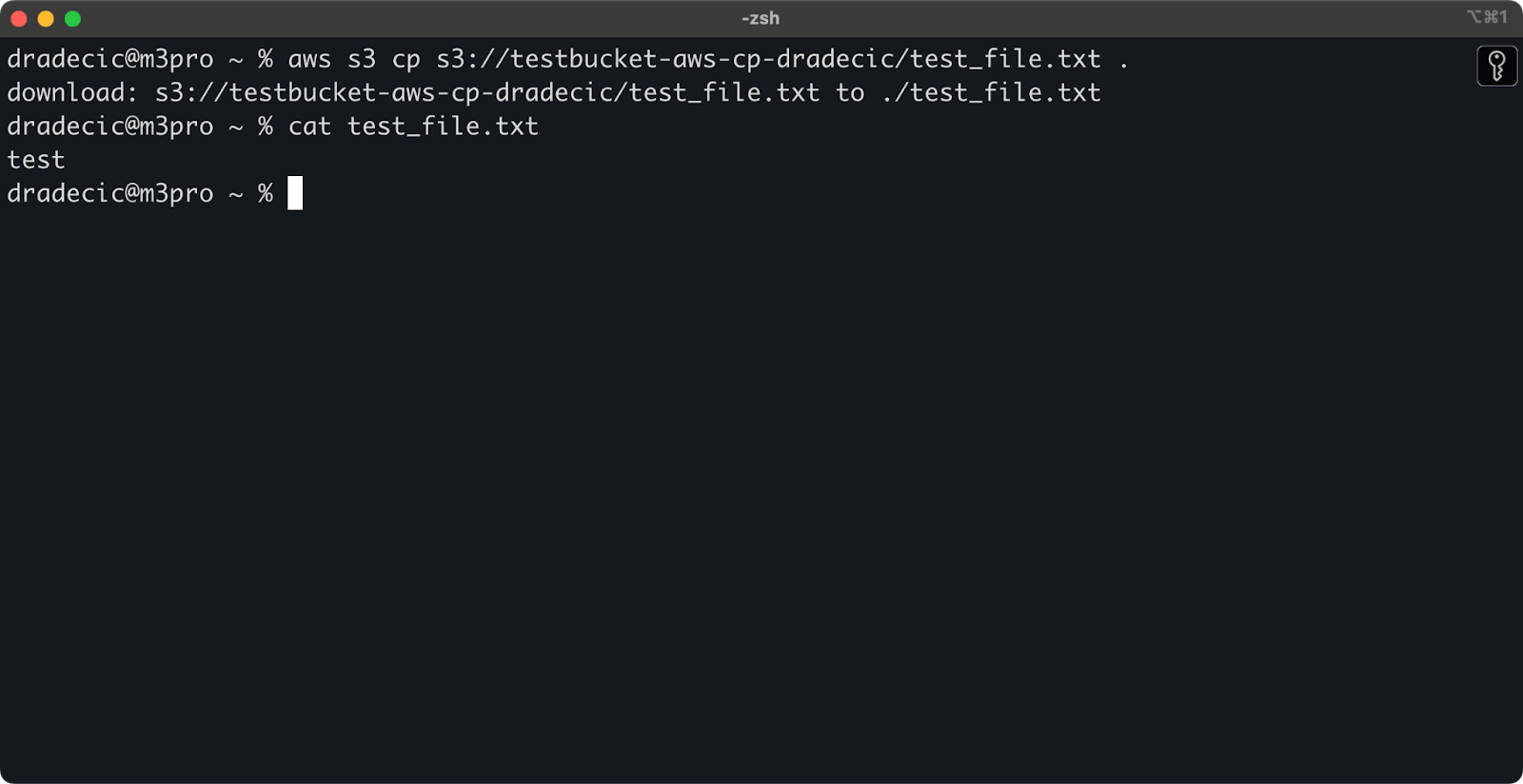
图像12 – 下载文件的内容
句点(.)代表您当前的目录,因此这将把test_file.txt下载到当前位置。
最后,要下载整个目录,可以使用类似于以下命令:
aws s3 cp s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder /Users/dradecic/Documents/test_folder --recursive
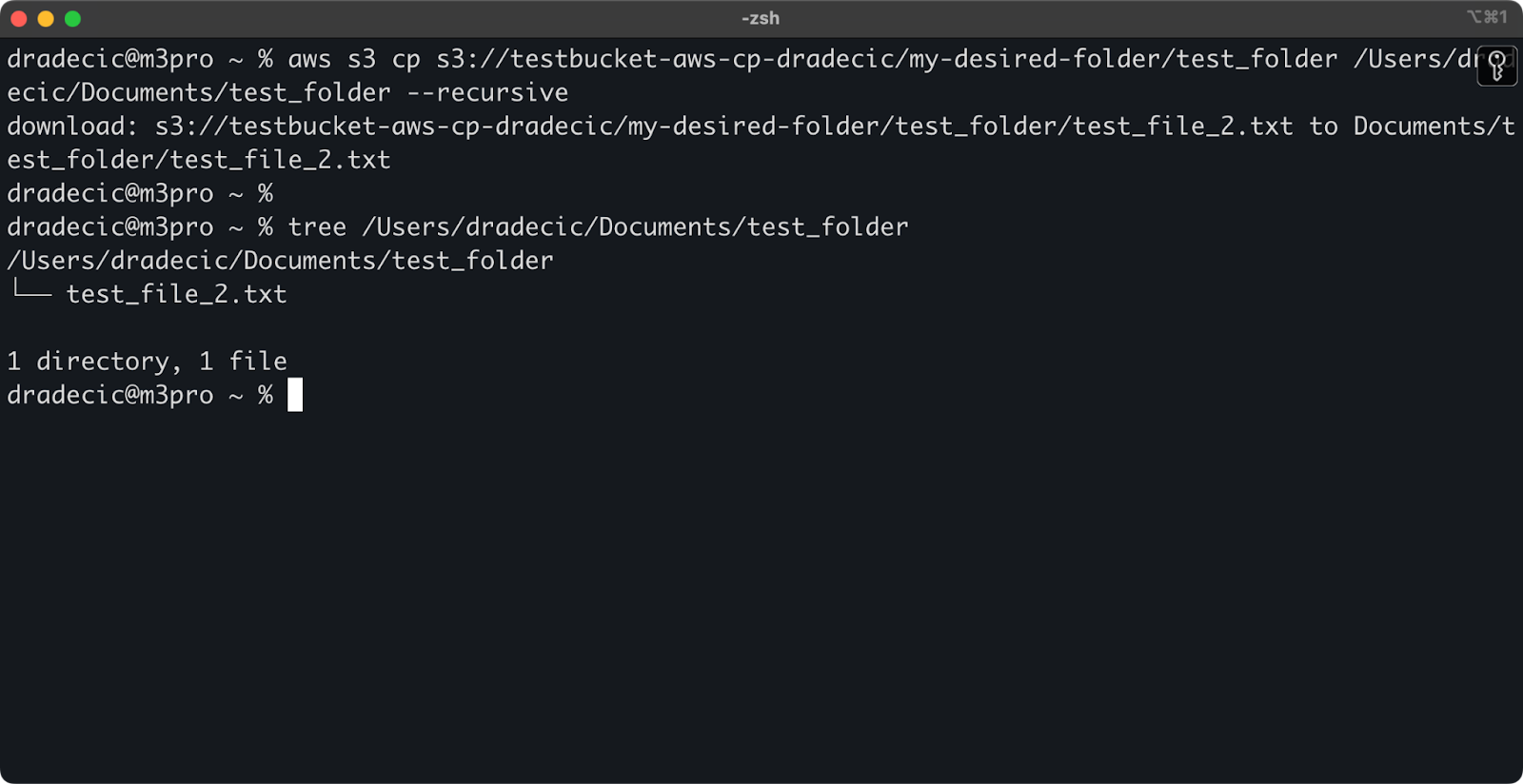
图像13 – 下载文件夹的内容
请注意,在处理多个文件时,--recursive标志是必不可少的 – 如果源是目录,则没有该标志,命令将失败。
使用这些基本命令,您已经可以完成大部分所需的文件传输任务。但在下一部分,您将学习更多高级选项,以便更好地控制复制过程。
高级AWS S3 cp选项和功能
AWS提供了一些高级选项,让您最大限度地利用文件复制操作。在本节中,我将向您展示一些最有用的标志和参数,这些将帮助您完成日常任务。
使用–exclude和–include标志
有时候,您可能只想复制与特定模式匹配的某些文件。--exclude 和 --include 标志允许您根据模式过滤文件,并精确控制要复制的内容。
为了让您了解背景情况,这是我正在处理的目录结构:
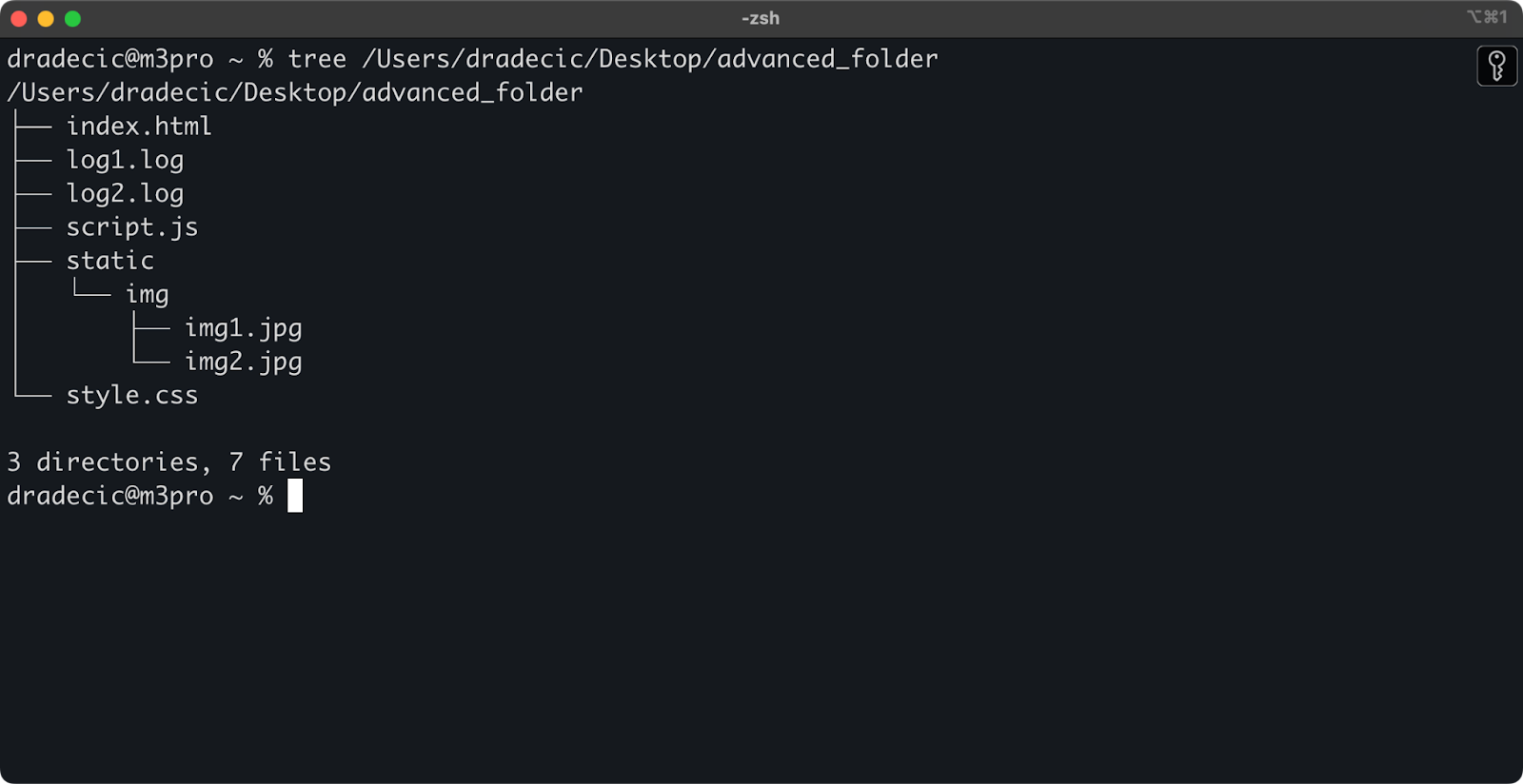
图像14 – 目录结构
现在,假设您想要从目录中复制所有文件,但排除 .log 文件:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*.log"
此命令将从 advanced_folder 目录复制所有文件到 S3,排除任何具有 .log 扩展名的文件:
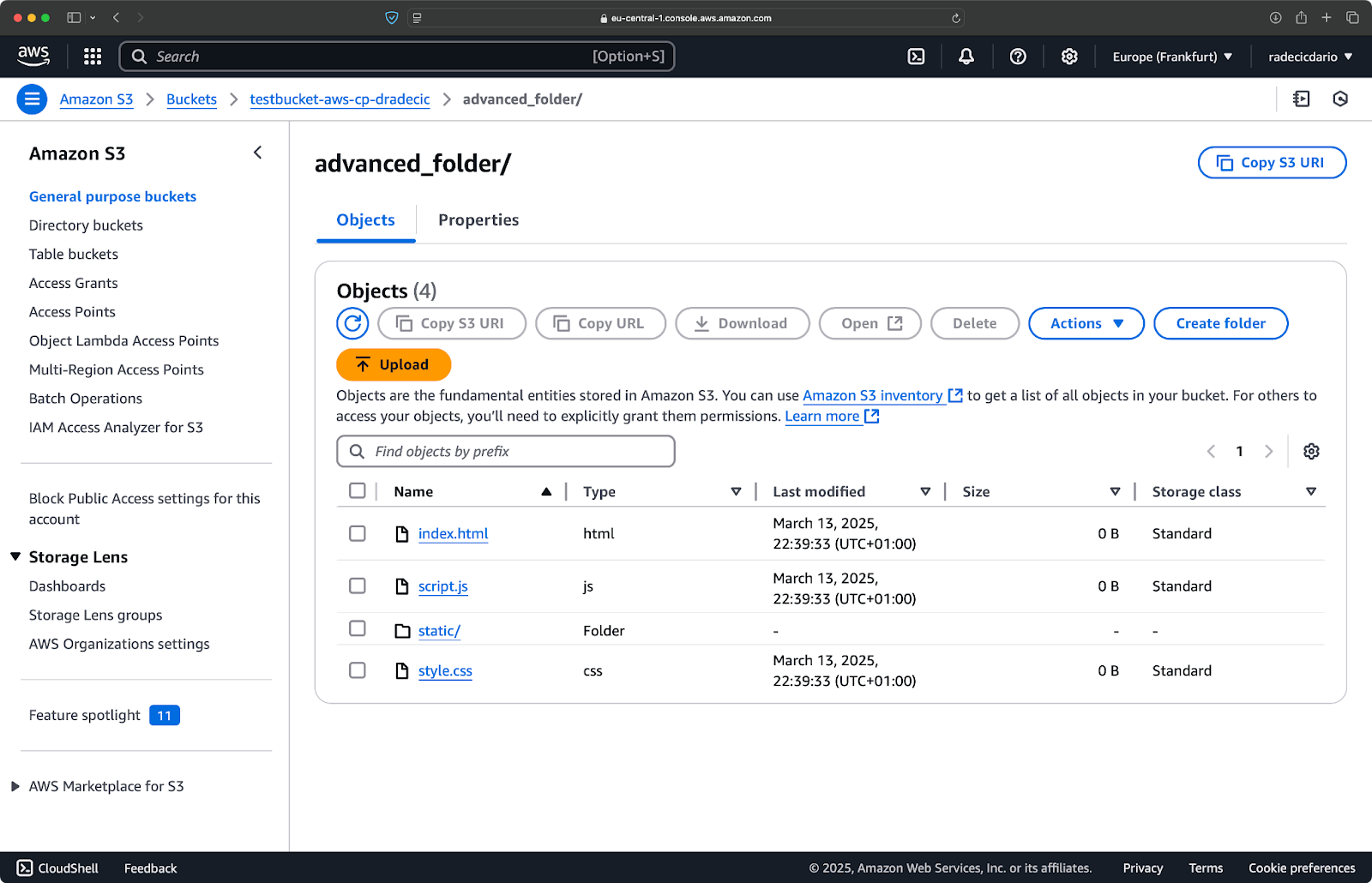
图像15 – 文件夹复制结果
您也可以组合多个模式。假设您只想从项目文件夹中复制 HTML 和 CSS 文件:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*" --include "*.html" --include "*.css"
此命令首先排除所有内容(--exclude "*"),然后仅包括扩展名为 .html 和 .css 的文件。结果如下:
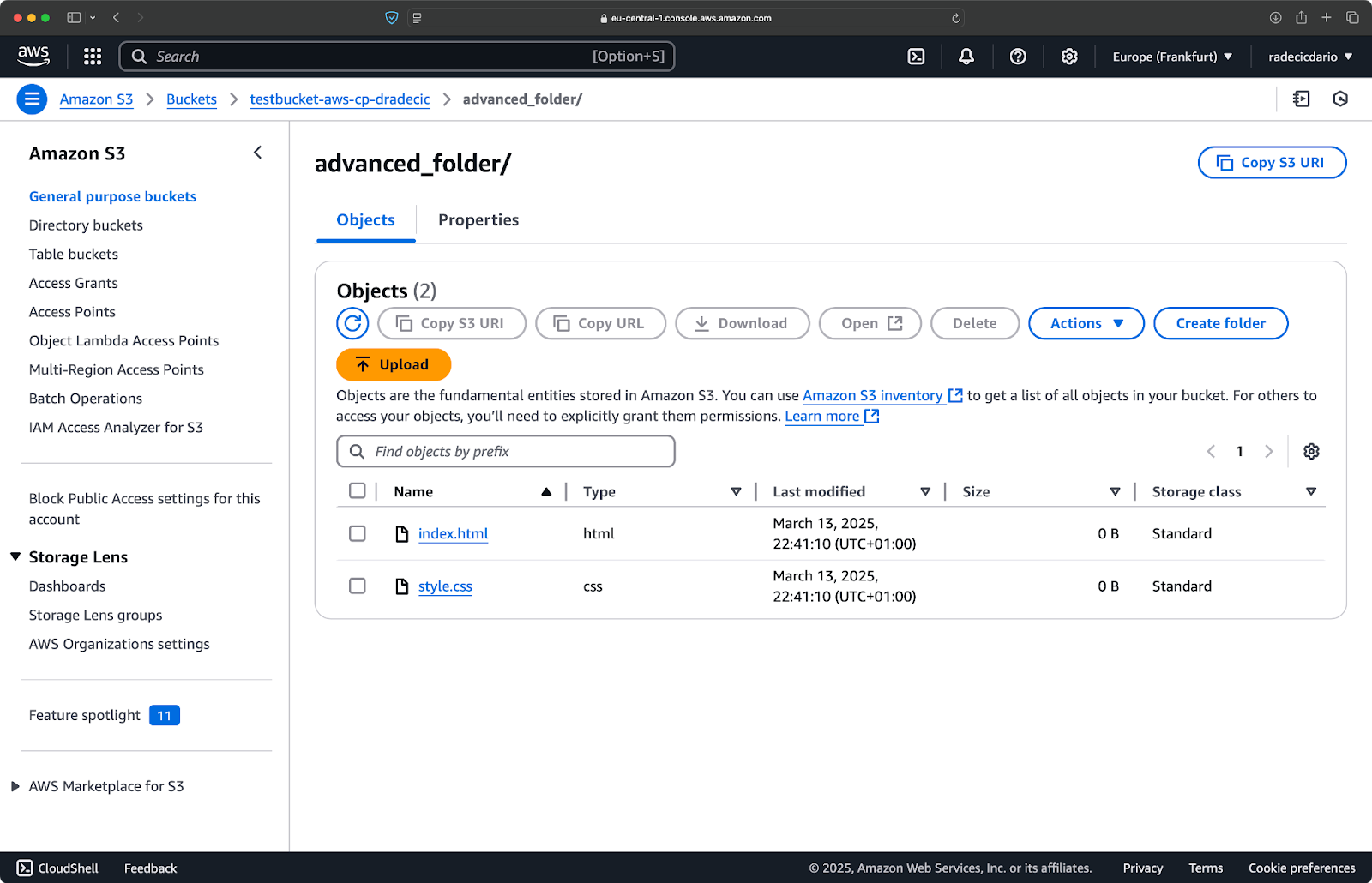
图像16 – 文件夹复制结果(2)
请记住标志的顺序很重要 – AWS CLI 会按顺序处理这些标志,因此如果您将 --include 放在 --exclude 之前,您将获得不同的结果:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --include "*.html" --include "*.css" --exclude "*"
这次,未将任何内容复制到存储桶:
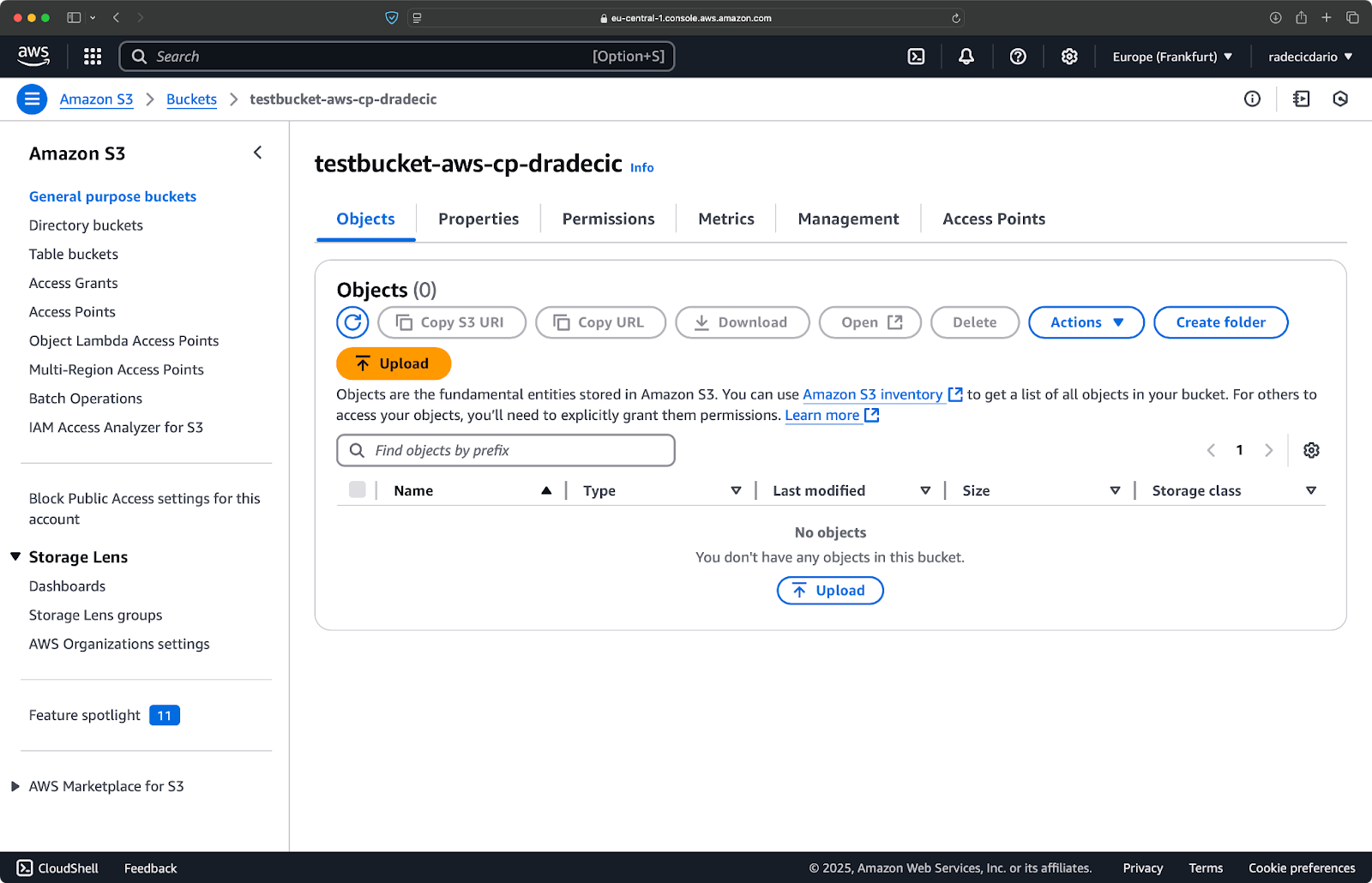
图像17 – 文件夹复制结果(3)
指定 S3 存储类
Amazon S3提供不同的存储类别,每种类别都有不同的成本和检索特性。默认情况下,aws s3 cp会将文件上传到标准存储类别,但您可以使用--storage-class标志指定不同的类别:
aws s3 cp /Users/dradecic/Desktop/large-archive.zip s3://testbucket-aws-cp-dradecic/archives/ --storage-class GLACIER
此命令将large-archive.zip上传到冰川存储类别,这个类别的成本更低,但检索成本更高,检索时间更长:
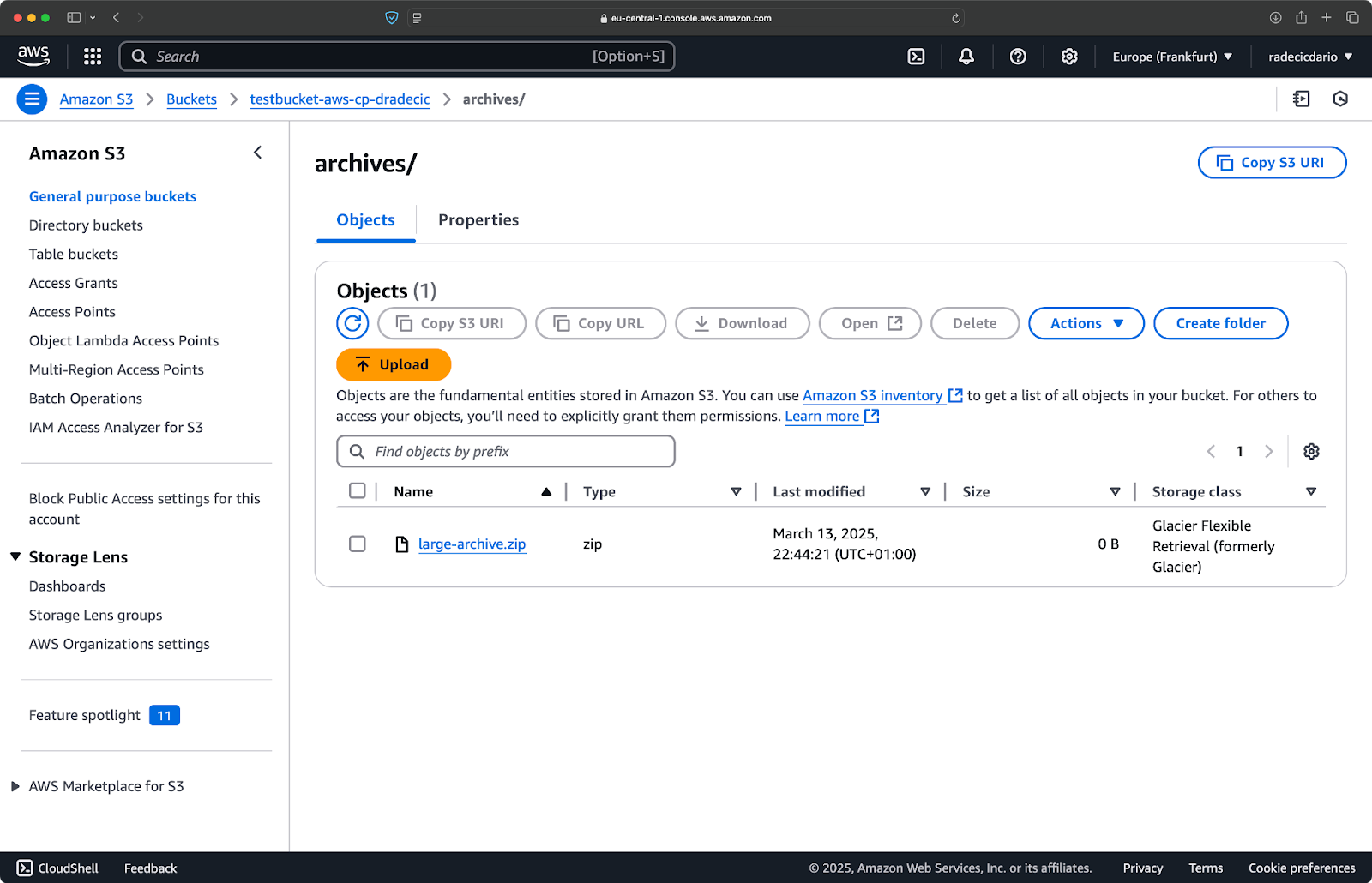
图像18 – 使用不同存储类别将文件复制到S3
可用的存储类别包括:
STANDARD(默认):具有高耐用性和可用性的通用存储。REDUCED_REDUNDANCY(不建议使用):较低的耐用性,节省成本的选项,现已弃用。STANDARD_IA(低频访问):针对访问频率较低的数据的低成本存储。ONEZONE_IA(单可用区低频访问):单个AWS可用区中的低成本、低频访问存储。INTELLIGENT_TIERING:根据访问模式在存储层之间自动移动数据。GLACIER:用于长期保留的低成本存档存储,检索时间为几分钟到几小时。DEEP_ARCHIVE:最便宜的存档存储,检索时间为几小时,非常适合长期备份。
如果您正在备份不需要立即访问的文件,使用GLACIER或DEEP_ARCHIVE可以节省大量存储成本。
使用–exact-timestamps标志同步文件
当您在S3中更新已经存在的文件时,您可能只想复制已更改的文件。--exact-timestamps标志通过比较源和目的地之间的时间戳来帮助实现这一点。
这里有一个示例:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exact-timestamps
使用此标志,命令只会复制时间戳与S3中已有文件不同的文件。当您定期更新大量文件时,这可以减少传输时间和带宽使用。
那么,这有什么用呢?想象一下部署场景,您希望更新应用文件而无需传输未更改的资产。
虽然--exact-timestamps用于执行某种同步是有用的,但如果您需要更复杂的解决方案,请考虑使用aws s3 sync而不是aws s3 cp。sync命令专门设计用于保持目录同步,并具有额外的功能以实现此目的。我在AWS S3 Sync教程中详细介绍了sync命令。
有了这些高级选项,您现在可以更精细地控制S3文件操作。您可以针对特定文件,优化存储成本,并有效地更新文件。在下一节中,您将学会使用脚本和定时任务自动化这些操作。
使用AWS S3 cp自动化文件传输
到目前为止,您已经学会了如何使用命令行手动复制文件到S3并从S3复制文件。使用aws s3 cp的最大优势之一是您可以轻松自动化这些传输,这将为您节省大量时间。
让我们探讨如何将aws s3 cp命令集成到脚本和定时作业中,实现无需干预的文件传输。
在脚本中使用AWS S3 cp
这是一个简单的bash脚本示例,用于将目录备份到S3,为备份添加时间戳,并实现错误处理和日志记录到文件中:
#!/bin/bash # 设置变量 SOURCE_DIR="/Users/dradecic/Desktop/advanced_folder" BUCKET="s3://testbucket-aws-cp-dradecic/backups" DATE=$(date +%Y-%m-%d-%H-%M) BACKUP_NAME="backup-$DATE" LOG_FILE="/Users/dradecic/logs/s3-backup-$DATE.log" # 确保日志目录存在 mkdir -p "$(dirname "$LOG_FILE")" # 创建备份并记录输出 echo "Starting backup of $SOURCE_DIR to $BUCKET/$BACKUP_NAME" | tee -a $LOG_FILE aws s3 cp $SOURCE_DIR $BUCKET/$BACKUP_NAME --recursive 2>&1 | tee -a $LOG_FILE # 检查备份是否成功 if [ $? -eq 0 ]; then echo "Backup completed successfully on $DATE" | tee -a $LOG_FILE else echo "Backup failed on $DATE" | tee -a $LOG_FILE fi
将此内容保存为backup.sh,使用chmod +x backup.sh使其可执行,然后您就有了一个可重复使用的备份脚本!
然后您可以使用以下命令运行它:
./backup.sh
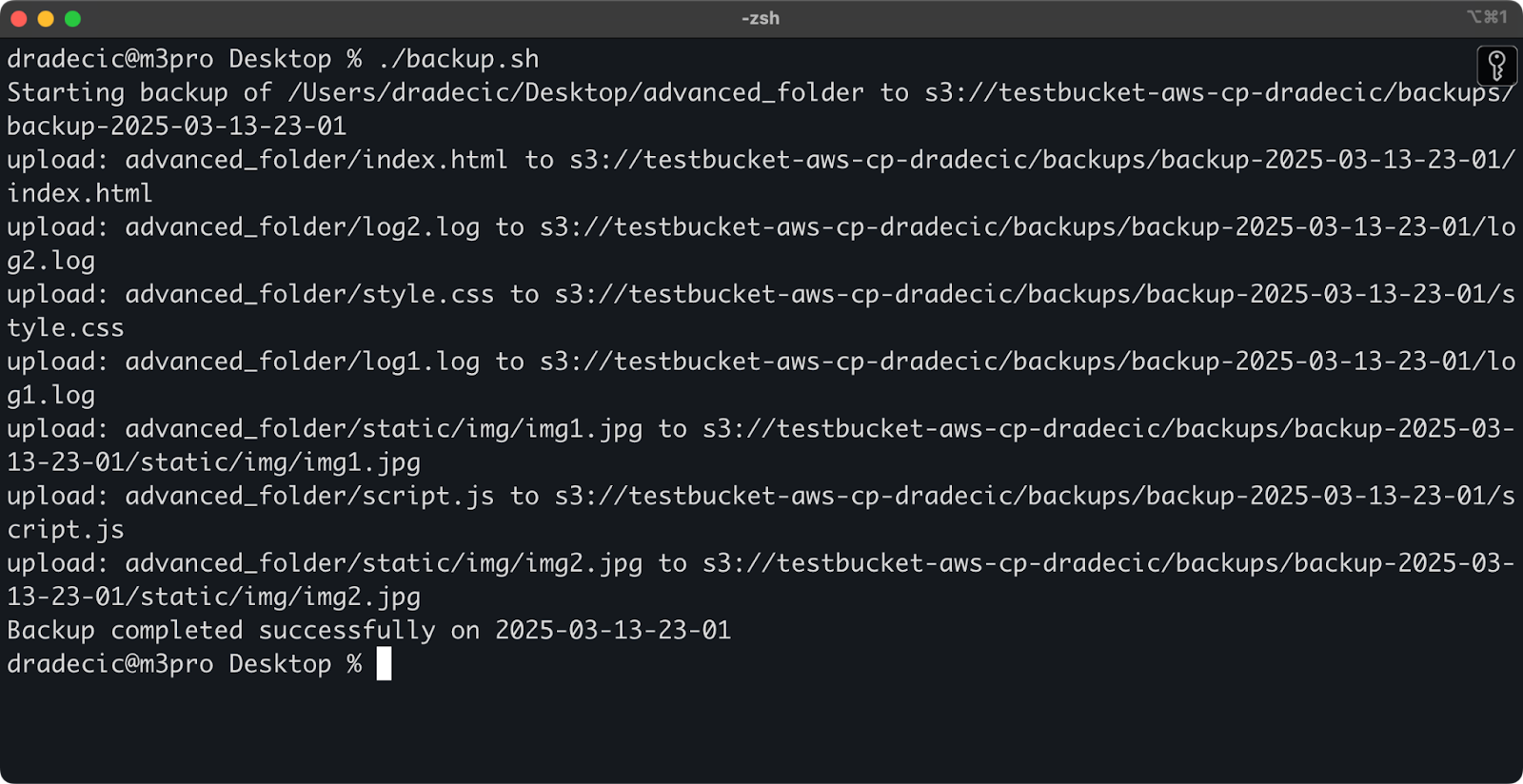
图像19 – 脚本在终端中运行
之后,存储桶中的backups文件夹将被填充:
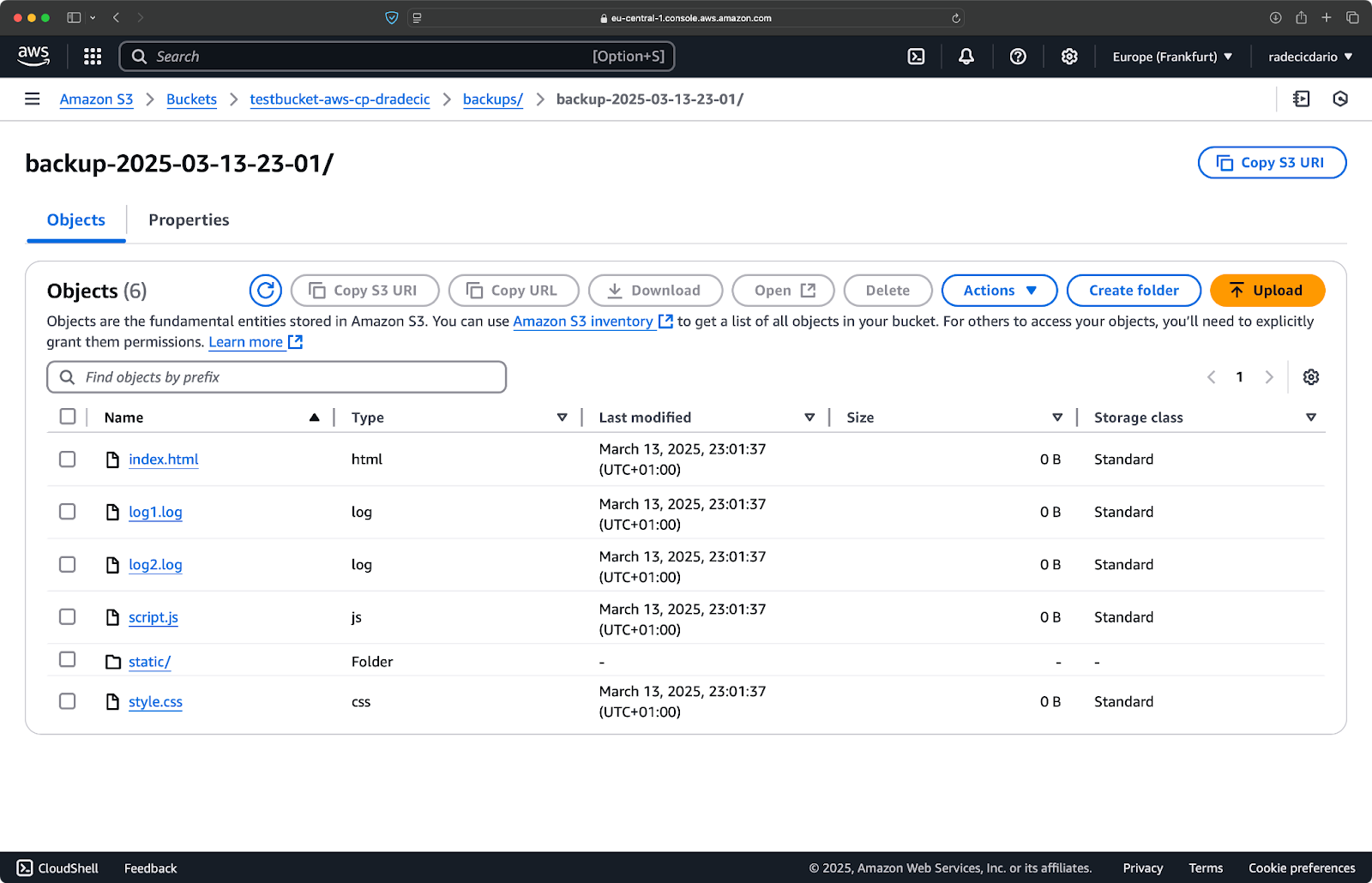
图像20 – 存储在S3存储桶中的备份
让我们将这个提升到下一个级别,通过在计划中运行脚本来自动执行。
使用cron作业调度文件传输
现在您已经有了一个脚本,下一步是将其安排在特定时间自动运行。
如果你使用Linux或macOS,你可以使用cron来安排备份任务。以下是如何设置cron作业,使备份脚本每天午夜运行一次:
1. 打开你的crontab进行编辑:
crontab -e
2. 添加以下行以使你的脚本每天午夜运行:
0 0 * * * /path/to/your/backup.sh
图像21 – 每日运行脚本的Cron作业
cron作业的格式是分钟 小时 月份中的日期 月份 星期几 命令。以下是一些示例:
- 每小时运行:
0 * * * * /path/to/your/backup.sh - 每周一上午9点运行:
0 9 * * 1 /path/to/your/backup.sh - 每月1日运行:
0 0 1 * * /path/to/your/backup.sh
就是这样!现在backup.sh脚本将按照预定的间隔运行。
自动化S3文件传输是一个不错的选择。特别适用于以下情况:
- 重要数据的每日备份
- 将产品图片同步到网站
- 将日志文件移至长期存储
- 部署更新的网站文件
像这样的自动化技术将帮助您建立一个可靠的系统,处理文件传输而无需手动干预。您只需编写一次,然后就可以忘记它。
在接下来的部分中,我将介绍一些最佳实践,以使您的aws s3 cp操作更安全高效。
使用AWS S3 cp的最佳实践
虽然aws s3 cp命令易于使用,但事情可能会出错。
如果遵循最佳实践,您将避免常见陷阱,优化性能,并保护您的数据安全。让我们探讨这些实践,使您的文件传输操作更高效。
高效的文件管理
在使用S3时,合理组织文件将为您节省时间并避免日后的麻烦。
首先,建立一致的存储桶和前缀命名约定。例如,您可以按环境、应用程序或日期来区分您的数据:
s3://company-backups/production/database/2023-03-13/ s3://company-backups/staging/uploads/2023-03/
这种组织方式使以下操作变得更加容易:
- 在需要时找到特定文件。
- 在正确的级别应用存储桶策略和权限。
- 设置生命周期规则以归档或删除旧数据。
另一个提示:在传输大量文件时,考虑先将小文件分组在一起(使用zip或tar)再上传。这样可以减少对S3的API调用次数,降低成本并加快传输速度。
# 不要复制成千上万个小日志文件 # 先将它们打包,然后上传 tar -czf example-logs-2025-03.tar.gz /var/log/application/ aws s3 cp example-logs-2025-03.tar.gz s3://testbucket-aws-cp-dradecic/logs/2025/03/
处理大数据传输
当您复制大文件或大量文件时,有一些技巧可以使过程更可靠和高效。
您可以使用--quiet标志在脚本中运行时减少输出:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/backups/ --recursive --quiet
这将抑制每个文件的进度信息,使日志更易管理。它还略微提高了性能。
对于非常大的文件,请考虑使用分段上传,并使用--multipart-threshold标志:
aws s3 cp huge-file.iso s3://testbucket-aws-cp-dradecic/backups/ --multipart-threshold 100MB
上述设置告诉 AWS CLI将大于100MB的文件拆分为多个部分进行上传。这样做有一些好处:
- 如果连接中断,只需重试受影响的部分。
- 零件可以并行上传,可能会增加吞吐量。
- 您可以暂停和恢复大文件上传。
在不同区域之间传输数据时,考虑使用S3传输加速以加快上传速度:
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/backups/ --endpoint-url https://s3-accelerate.amazonaws.com
上述方法会通过亚马逊的边缘网络传输您的数据,可以显著加快跨区域传输速度。
确保安全
在使用云端数据时,安全性应始终是最重要的。
首先,确保您的IAM权限遵循最小特权原则。只授予每个任务所需的具体权限。
以下是您可以分配给用户的示例策略:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::testbucket-aws-cp-dradecic/backups/*" } ] }
此策略仅允许复制文件到和从“my-bucket”中的“backups”前缀。
增加安全性的另一种方法是启用加密来保护敏感数据。您可以在上传时指定服务器端加密:
aws s3 cp confidential.docx s3://testbucket-aws-cp-dradecic/ --sse AES256
或者,为了更高的安全性,可以使用AWS密钥管理服务(KMS):
aws s3 cp secret-data.json s3://testbucket-aws-cp-dradecic/ --sse aws:kms --sse-kms-key-id myKMSKeyId
然而,对于非常敏感的操作,请考虑使用S3的VPC端点。这样可以使您的流量保持在AWS网络内,完全避免了公共互联网。
在接下来的部分,您将学习如何解决在使用此命令时可能遇到的常见问题。
故障排除 AWS S3 cp 错误
有一点是肯定的-在使用 aws s3 cp 时,偶尔会遇到问题。但是,通过了解常见错误及其解决方案,当事情不顺利时,您将节省一些时间和挫折感。
在本部分中,我将向您展示最常见的问题以及如何解决它们。
常见错误和解决方法
错误:”拒绝访问”
这可能是您遇到的最常见错误:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
通常意味着以下三种情况之一:
- 您的 IAM 用户没有足够的权限执行该操作。
- 存储桶策略限制了访问。
- 您的 AWS 凭证已过期。
故障排除:
- 检查您的 IAM 权限,确保具有必要的
s3:PutObject(用于上传)或s3:GetObject(用于下载)权限。 - 验证存储桶策略是否限制了您的操作。
- 运行
aws configure以更新凭据(credentials)如果它们已过期。
错误:”没有该文件或目录”
当您尝试复制的本地文件或目录不存在时会出现此错误:
upload failed: ./missing-file.txt to s3://testbucket-aws-cp-dradecic/missing-file.txt An error occurred (404) when calling the PutObject operation: Not Found
解决方案很简单 – 仔细检查您的文件路径。路径是区分大小写的,所以请牢记这一点。另外,在使用相对路径时,请确保您位于正确的目录中。
错误:”指定的存储桶不存在”
如果您看到这个错误:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not exist
检查:
- 您的存储桶名称中是否有错别字。
- 您是否使用了正确的AWS区域。
- 存储桶是否实际存在(可能已被删除)。
您可以使用aws s3 ls列出所有存储桶以确认正确的名称。
错误:”连接超时”
网络问题可能导致连接超时:
upload failed: ./largefile.zip to s3://testbucket-aws-cp-dradecic/largefile.zip An error occurred (RequestTimeout) when calling the PutObject operation: Request timeout
解决方法:
- 检查您的互联网连接。
- 尝试使用较小的文件或启用大文件的分段上传。
- 考虑使用AWS传输加速以获得更好的性能。
处理上传失败
在传输大文件时更容易出现错误。在这种情况下,尽量优雅地处理失败。
例如,您可以使用--only-show-errors标志使脚本中的错误诊断更容易:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/ --recursive --only-show-errors
这将抑制成功的传输消息,仅显示错误,从而使大型传输的故障排除更加容易。
处理中断传输时,--recursive 命令会自动跳过目标位置已存在且大小相同的文件。然而,为了更加彻底,您可以使用AWS CLI内置的重试机制来处理网络问题,只需设置以下环境变量:
export AWS_RETRY_MODE=standard export AWS_MAX_ATTEMPTS=5 aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/
这将告诉AWS CLI自动重试最多5次失败的操作。
但对于非常大的数据集,请考虑使用aws s3 sync而不是cp,因为它更适合处理中断:
aws s3 sync large-directory/ s3://testbucket-aws-cp-dradecic/large-directory/
sync命令只会传输与目标位置已有文件不同的文件,非常适合恢复中断的大文件传输。
如果您了解这些常见错误并在脚本中实施适当的错误处理,将使您的S3复制操作更加强大和可靠。
总结AWS S3 cp
总而言之,aws s3 cp命令是将本地文件复制到S3以及反之的一站式解决方案。
您在本文中学到了所有这些。您从基础知识和环境配置开始,最终编写了用于复制文件的定时和自动化脚本。您还学会了如何处理移动文件时遇到的一些常见错误和挑战,特别是大文件。
如果您是开发人员、数据专业人员或系统管理员,我认为您会发现这个命令很有用。熟练掌握它的最佳方法是经常使用。确保您理解基础知识,然后花些时间自动化工作中繁琐的部分。
要了解更多关于AWS的知识,请跟随DataCamp提供的这些课程:
您甚至可以使用DataCamp来准备AWS认证考试-AWS云从业者(CLF-C02)。