













I came across one of the test cases in my previous projects where I had to click on a button to navigate to the next page. I searched for the element locator of the button on the page and ran the tests hoping it would click the button and navigate to the next page.
然而,令我意外的是,测试失败了,因为它无法定位到元素,控制台日志中出现了NoSuchElementException。看到这个错误让我很不高兴,因为我尝试点击的只是一个简单的按钮,并没有任何复杂性。
进一步分析问题,展开DOM结构并检查根元素后,我发现按钮定位器位于#shadow-root(open)节点下,这让我意识到需要以不同的方式处理,因为它是一个Shadow DOM元素。
在本篇Selenium WebDriver教程中,我们将探讨Shadow DOM元素以及如何在Selenium WebDriver中自动化处理Shadow DOM。在深入了解如何在Selenium中自动化Shadow DOM之前,我们先来理解什么是Shadow DOM以及它的用途。
什么是Shadow DOM?
Shadow DOM是一种功能,允许浏览器在不将其放入主文档DOM树的情况下渲染DOM元素。这创建了开发者与浏览器之间可访问性的屏障;开发者不能像访问嵌套元素那样访问Shadow DOM,而浏览器可以像处理嵌套元素一样渲染和修改这些代码。
Shadow DOM是实现HTML文档中封装的一种方式。通过实施它,你可以保持文档某一部分的样式和行为隐藏并与其他代码分离,从而避免干扰。
Shadow DOM允许将隐藏的DOM树附加到常规DOM树中的元素上——Shadow DOM树以Shadow根开始,在其下可以像正常DOM一样附加任何元素。
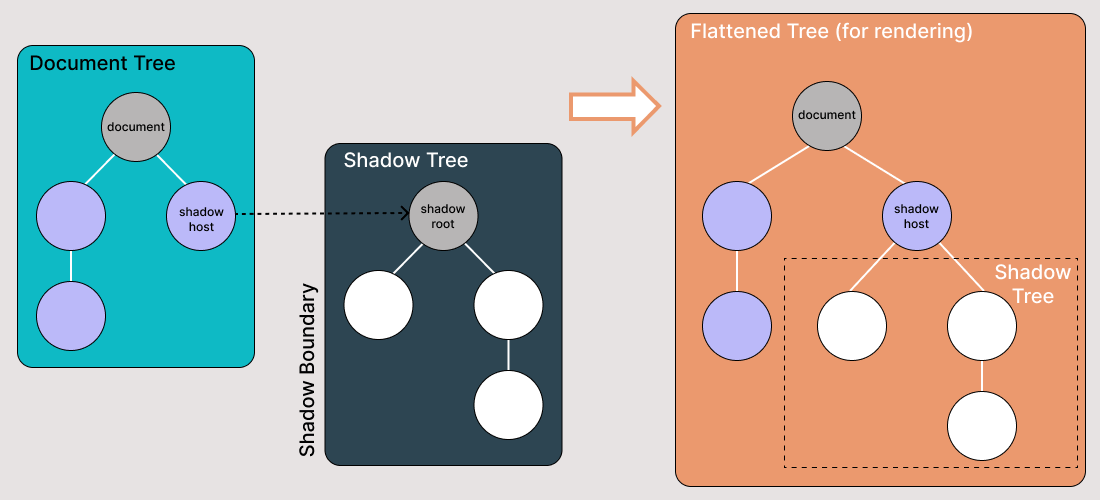
需要了解一些Shadow DOM术语:
- 影子宿主:Shadow DOM所附加的常规DOM节点
- 影子树:Shadow DOM内部的DOM树
- 影子边界是Shadow DOM结束与常规DOM开始之处
- 影子根:影子树的根节点
Shadow DOM的用途是什么?
Shadow DOM用于封装。它允许组件拥有自己的“影子”DOM树,无法从主文档意外访问,可以拥有局部样式规则等。
以下是Shadow DOM的一些基本特性:
- 拥有自己的id空间
- 对主文档的JavaScript选择器(如querySelector)不可见
- 仅使用来自影子树的样式,不使用主文档的样式
使用Selenium WebDriver查找Shadow DOM元素
当我们尝试使用Selenium定位器查找Shadow DOM元素时,会得到NoSuchElementException,因为它对DOM不可直接访问。
我们将采用以下策略来访问Shadow DOM定位器:
- 使用JavaScriptExecutor。
- 使用Selenium WebDriver的
getShadowDom()方法。
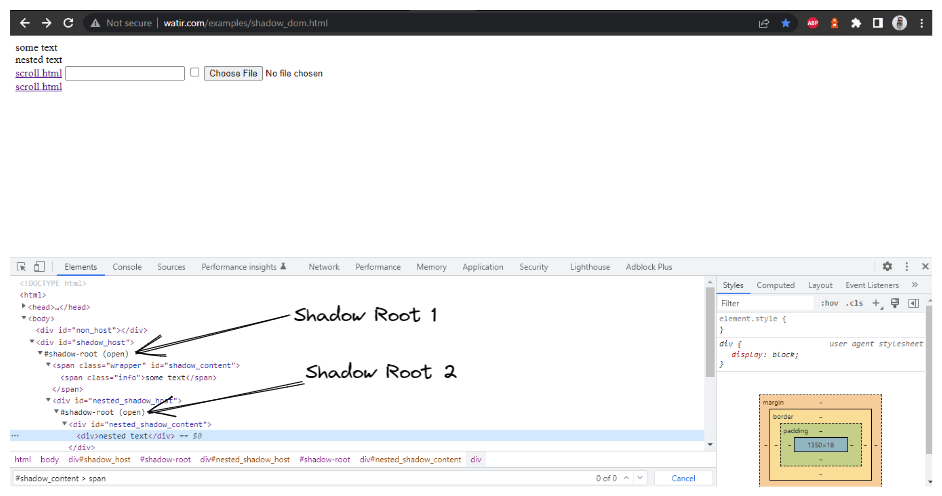
在本博客部分,我们将探讨如何在Selenium中自动化Shadow DOM,以Watir.com的首页为例,尝试使用Selenium WebDriver断言shadow dom及其嵌套的shadow dom文本。需要注意的是,在到达文本-> 某些文本之前,有一个shadow root元素,而在到达文本-> 嵌套文本之前,则有两个shadow root元素。
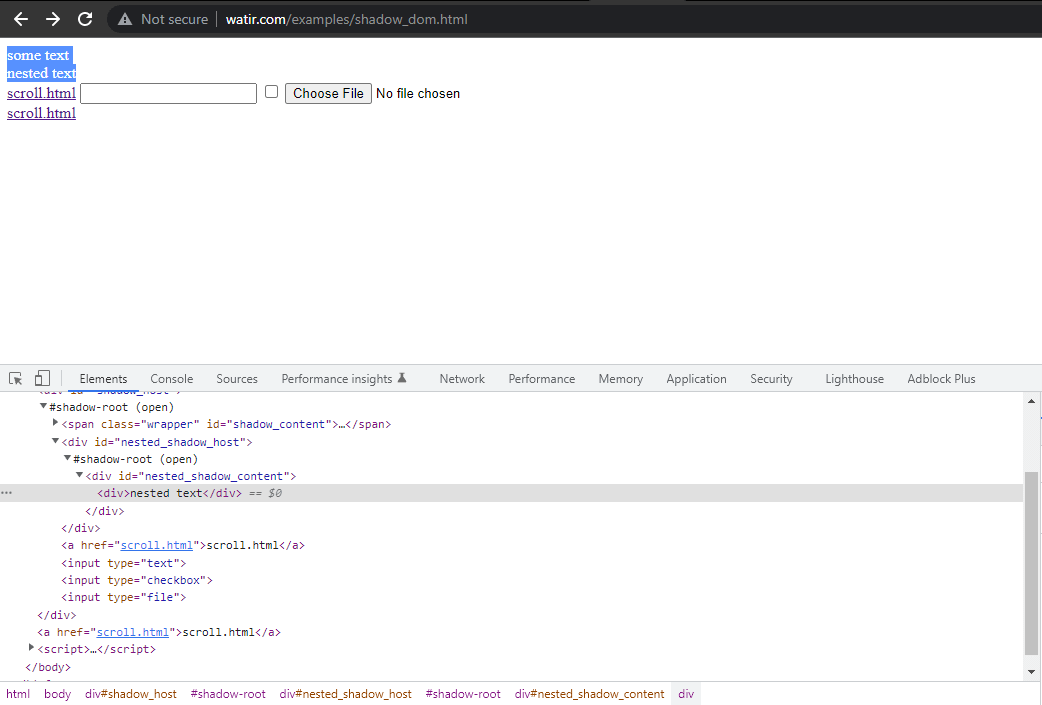
现在,如果我们尝试使用cssSelector("#shadow_content > span")定位元素,它
无法被定位,Selenium WebDriver将抛出NoSuchElementException。
以下是Homepage类的截图,其中尝试使用
cssSelector(“#shadow_content > span”)获取文本。

以下是测试截图,我们尝试断言文本(“某些文本”)。
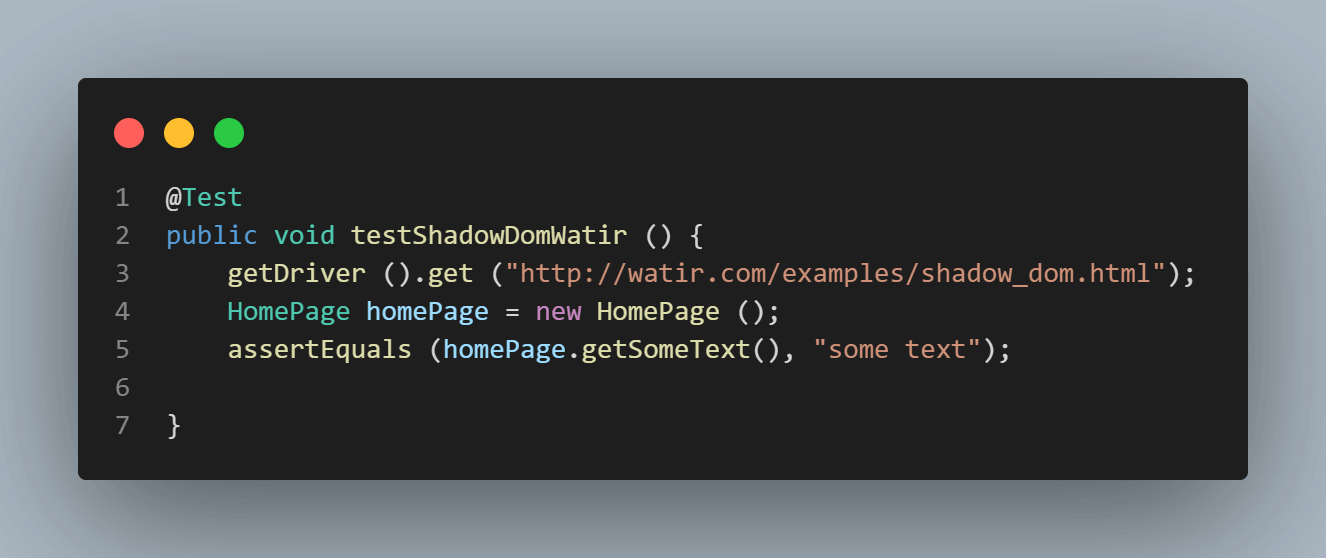
运行测试时显示NoSuchElementException错误
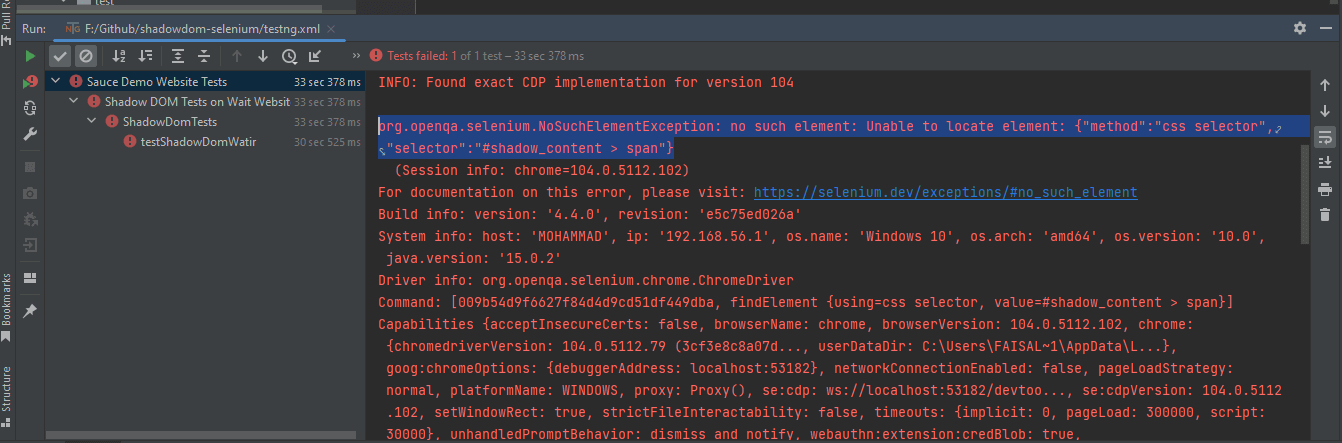
为了正确地定位文本元素,我们需要通过Shadow root元素。只有这样,我们才能在页面上定位到“某些文本”和”嵌套文本”。
如何使用‘getShadowDom’方法在Selenium WebDriver中查找Shadow DOM
随着Selenium WebDriver 4.0.0及以上版本的发布,引入了getShadowRoot()方法,帮助定位Shadow root元素。
以下是getShadowRoot()方法的语法和详细信息:
default SearchContext getShadowRoot()
Returns:
The ShadowRoot class represents the shadow root of a web component. With a shadow root, you can access the shadow DOM of a web component.
Throws:
NoSuchShadowRootException - If shadow root is not found.根据文档,getShadowRoot()方法返回元素的Shadow根表示,用于访问Web组件的Shadow DOM。
如果未找到Shadow根,则会抛出NoSuchShadowRootException。
在开始编写测试和讨论代码之前,让我告诉您我们将用于编写和运行测试的工具:
以下编程语言和工具已用于编写和运行测试:
- 编程语言:Java 11
- Web自动化工具:Selenium WebDriver
- 测试运行器:TestNG
- 构建工具:Maven
- 云平台:LambdaTest
开始使用Selenium WebDriver查找Shadow DOM
如前所述,此项目关于Selenium中的Shadow DOM是使用Maven创建的。TestNG用作测试运行器。要了解更多关于Maven的信息,您可以阅读这篇关于开始使用Maven进行Selenium测试的博客。
项目创建后,我们需要在pom.xml文件中添加Selenium WebDriver和TestNG的依赖项。
依赖项的版本在单独的属性块中设置。这样做是为了便于维护,如果我们需要更新版本,可以轻松完成,无需在整个pom.xml文件中搜索依赖项。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>io.github.mfaisalkhatri</groupId>
<artifactId>shadowdom-selenium</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<selenium.java.version>4.4.0</selenium.java.version>
<testng.version>7.6.1</testng.version>
<webdrivermanager.version>5.2.1</webdrivermanager.version>
<maven.compiler.version>3.10.1</maven.compiler.version>
<surefire-version>3.0.0-M7</surefire-version>
<java.release.version>11</java.release.version>
<maven.source.encoding>UTF-8</maven.source.encoding>
<suite-xml>testng.xml</suite-xml>
<argLine>-Dfile.encoding=UTF-8 -Xdebug -Xnoagent</argLine>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>${selenium.java.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.testng/testng -->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>${testng.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>${webdrivermanager.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<release>${java.release.version}</release>
<encoding>${maven.source.encoding}</encoding>
<forceJavacCompilerUse>true</forceJavacCompilerUse>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire-version}</version>
<executions>
<execution>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
<properties>
<property>
<name>usedefaultlisteners</name>
<value>false</value>
</property>
</properties>
<suiteXmlFiles>
<suiteXmlFile>${suite-xml}</suiteXmlFile>
</suiteXmlFiles>
<argLine>${argLine}</argLine>
</configuration>
</plugin>
</plugins>
</build>
</project>接下来我们转向代码;本项目采用了Page Object Model(POM),这种模式有助于减少代码重复并提升测试用例的维护性。
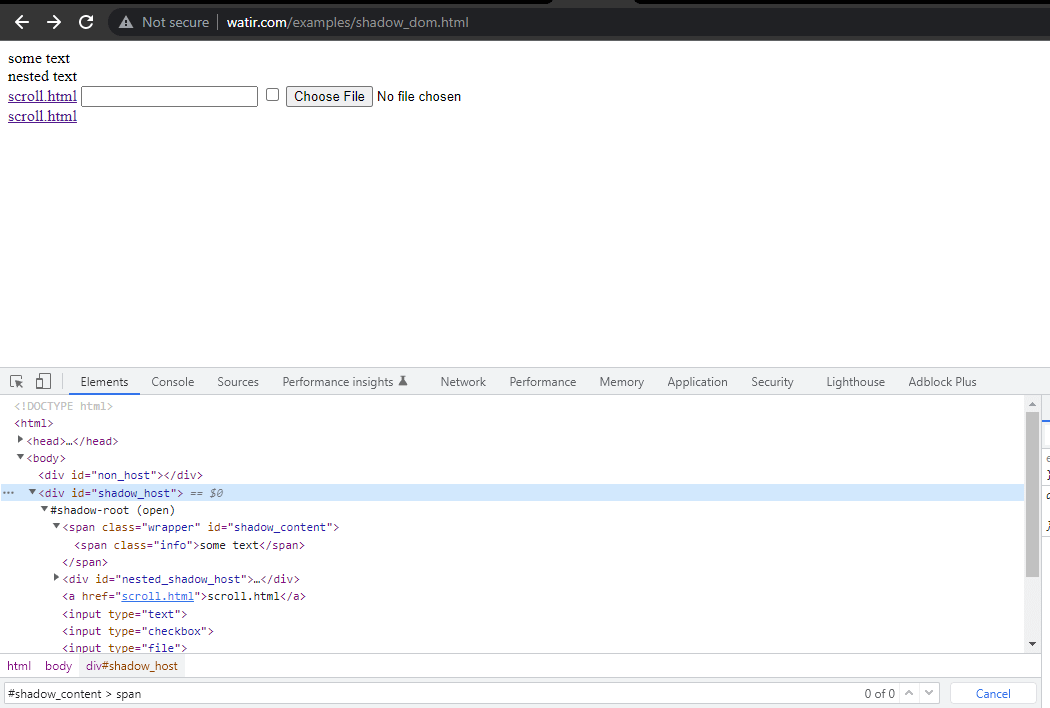
首先,我们将在HomePage上查找“some text”和“nested text”的定位器。
public class HomePage {
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
public String getSomeText () {
return getDriver ().findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
}
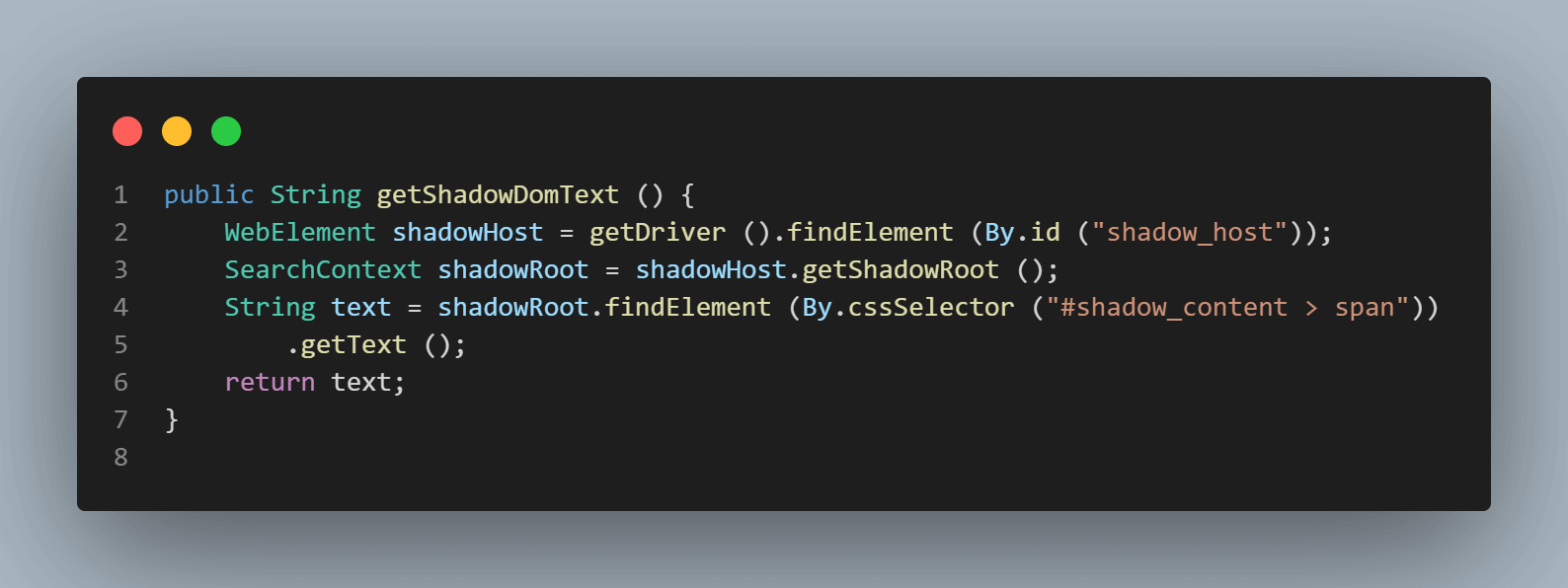
public String getShadowDomText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
return text;
}
public String getNestedShadowText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")).getText ();
return nestedText;
}
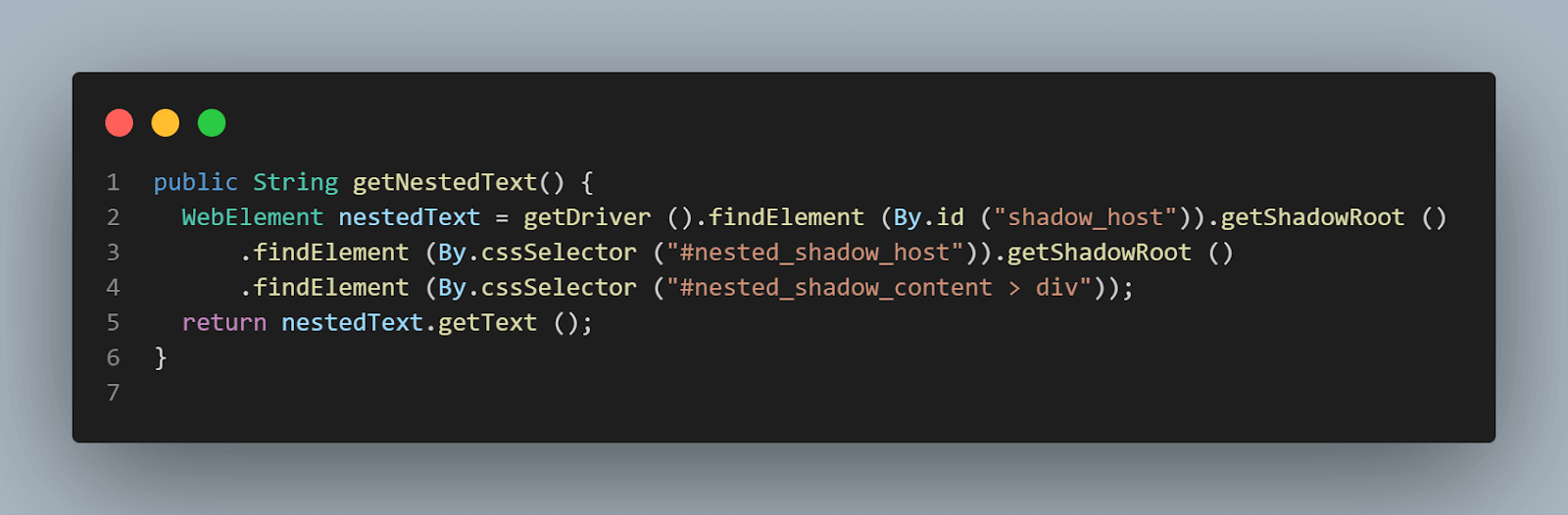
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}
public String getNestedTextUsingJSExecutor () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);
return shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();
}
}代码解析
我们首先定位到< div id = "shadow_host" >中的第一个元素,使用的是定位策略——id。
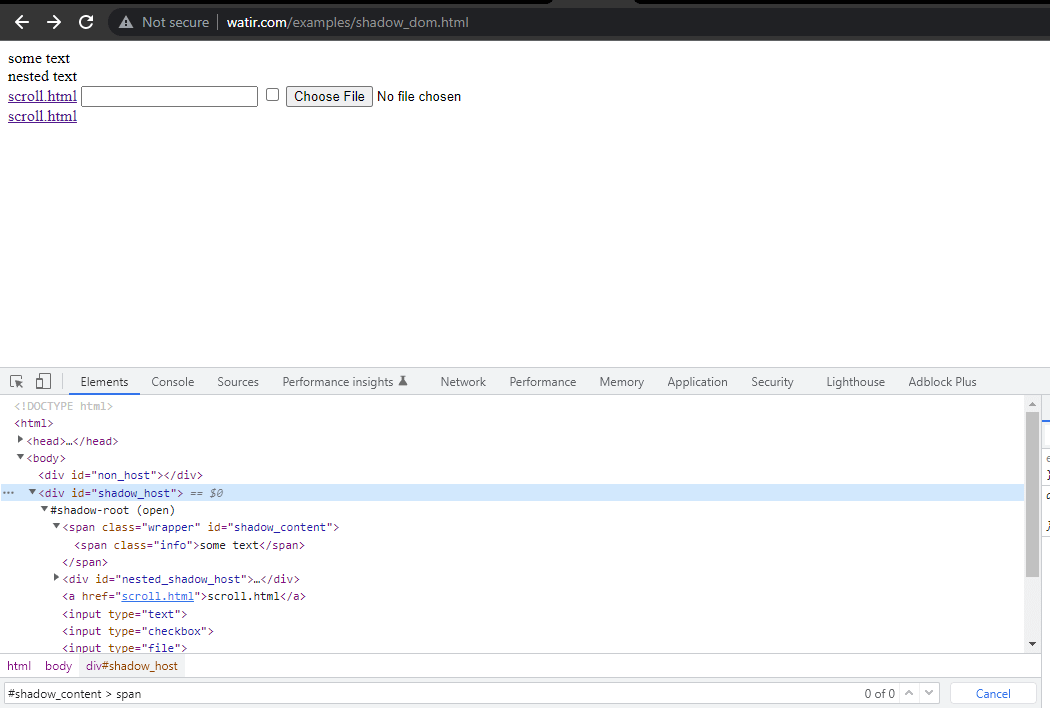
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));接着,我们在DOM中查找紧邻其后的第一个Shadow Root。为此,我们使用了SearchContext接口。通过getShadowRoot()方法返回Shadow Root。如上图所示,#shadow-root (open)紧邻< div id = "shadow_host" >。
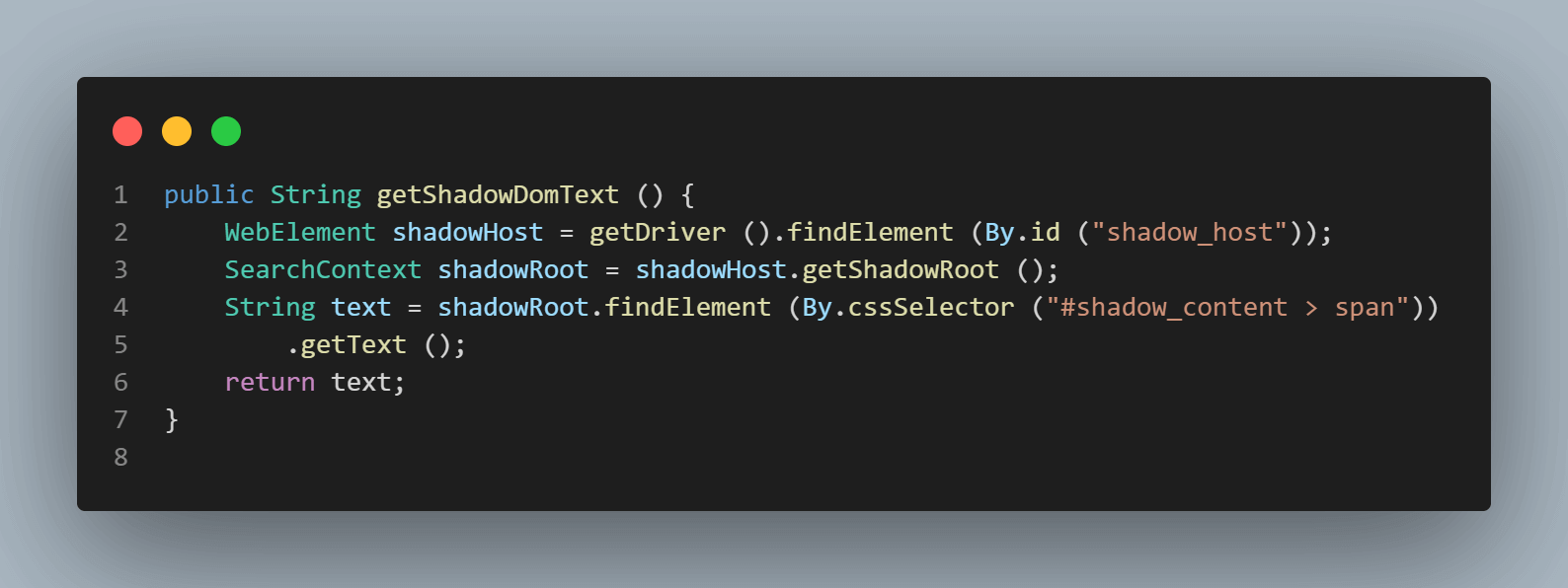
为了定位文本“some text,”,我们只需获取一个Shadow DOM元素。
以下代码行帮助我们获取Shadow根元素。
SearchContext shadowRoot = downloadsManager.getShadowRoot();一旦找到Shadow Root,我们就可以搜索元素以定位文本“some text”。以下代码行帮助我们获取该文本:
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();接下来,我们将定位包含嵌套文本“nested text,”的元素,该元素包含一个嵌套的Shadow root元素,并探讨如何定位其元素。
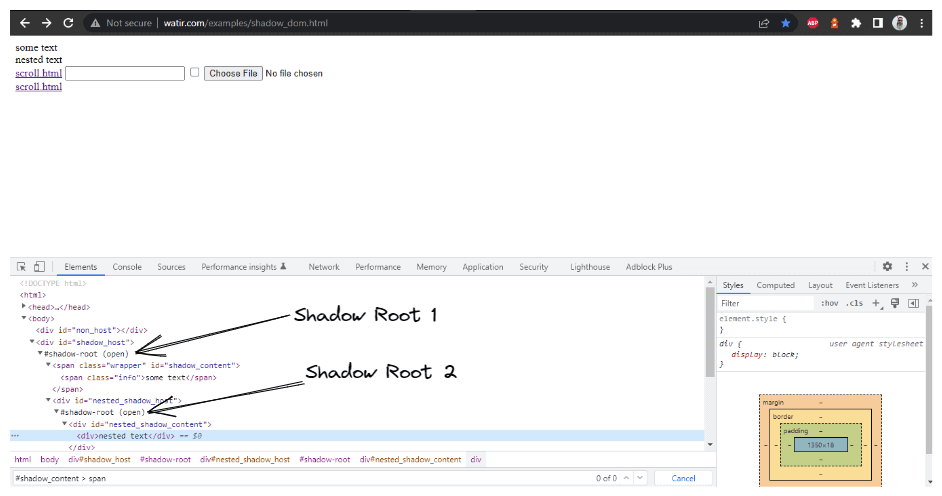
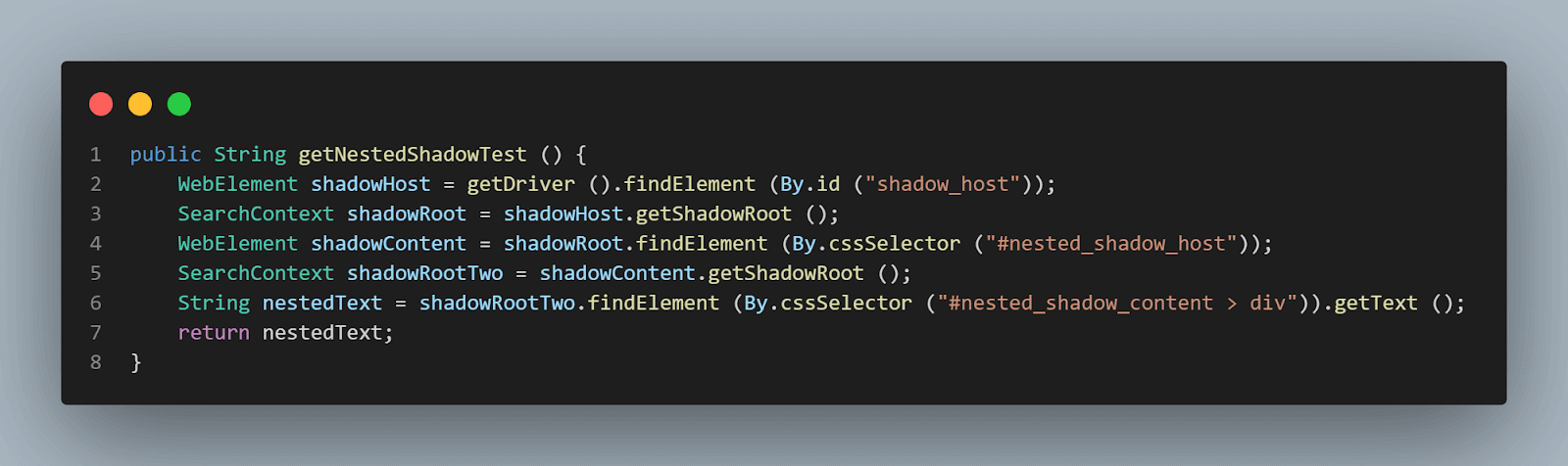
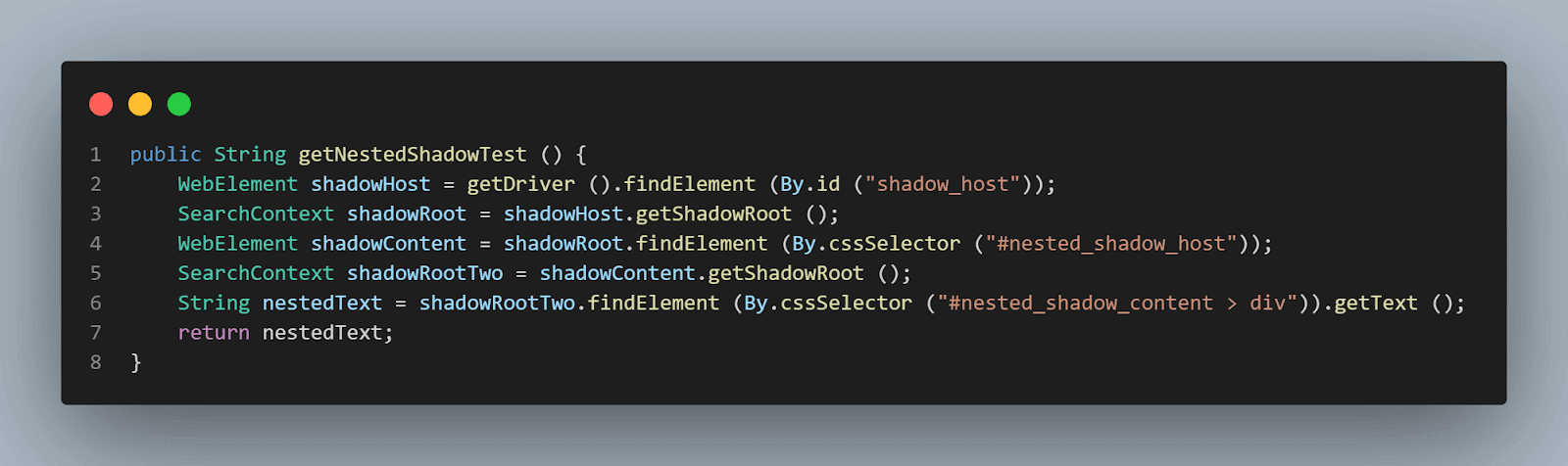
getNestedShadowText()方法:
首先,如上节所述,我们需要通过定位策略——id来找到< div id = "shadow_host" >。
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));随后,我们需要使用getShadowRoot()方法来找到Shadow Root元素;一旦获取到Shadow root元素,我们将需要进一步通过cssSelector来定位第二个Shadow Root:
<div id ="nested_shadow_host">
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));接着,我们需要使用getShadowRoot()方法来找到第二个Shadow Root元素。最后,我们将定位实际元素以获取文本——“nested text”。
以下代码行将帮助我们定位文本:
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"以流畅的方式编写代码
在上文中关于Selenium中Shadow DOM的讨论中,我们看到了从定位实际工作元素开始的漫长过程,并且需要多次初始化WebElement和SearchContext接口,以及编写多行代码来定位单个工作元素。
我们还有一种更流畅的编写整个代码的方式,以下是如何操作:
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}Fluent Interface的设计大量依赖于方法链。这种模式有助于编写易于阅读的代码,无需深入技术理解即可理解。该术语由Eric Evans和Martin Fowler于2005年首次提出。
我们将执行的方法链来定位元素。
这段代码实现了与上述步骤相同的功能。
- 首先,我们将通过其id定位shadow_host元素,然后使用
getShadowRoot()方法获取Shadow Root元素。 - 接下来,我们将使用CSS选择器搜索nested_shadow_host元素,并使用
getShadowRoot()方法获取Shadow Root元素。 - 最后,我们将通过cssSelector – nested_shadow_content > div获取“嵌套文本”。
如何在Selenium中使用JavaScriptExecutor查找Shadow DOM
在上述代码示例中,我们使用了getShadowRoot()方法定位元素。现在,让我们看看如何使用JavaScriptExecutor在Selenium WebDriver中定位Shadow root元素。
在HomePage类中创建了getNestedTextUsingJSExecutor()方法,
该方法用于根据传入的WebElement扩展Shadow Root元素。在DOM中(如上图所示截图),我们发现需要先扩展两个Shadow Root元素,才能到达获取文本的实际定位器——嵌套文本。因此,创建了expandRootElement()方法,避免了每次复制粘贴相同的JavaScript执行器代码。
我们将实现SearchContext接口,这将帮助我们使用JavaScriptExecutor,并根据传入的WebElement返回Shadow根元素。
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
getNestedTextUsingJSExecutor()方法
首先,我们将通过定位策略——id定位到<div id="shadow_host">元素。
接下来,我们将基于搜索到的shadow_host WebElement扩展Root元素。
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);扩展第一个Shadow Root后,我们可以使用cssSelector定位另一个WebElement:
<div id ="nested_shadow_host">
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);最后,现在是定位获取文本的实际元素——“嵌套文本”的时候了。
以下代码行将帮助我们定位文本:
shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();演示
在本篇文章关于Selenium中Shadow DOM的部分,我们快速编写一个测试,验证前几步找到的定位器是否能提供所需的文本。我们可以对编写的代码进行断言,以确认代码的预期功能是否正常工作。
@Test
public void testShadowDomWatir () {
getDriver ().get ("http://watir.com/examples/shadow_dom.html");
HomePage homePage = new HomePage ();
// assertEquals(homePage.getSomeText(), "some text");
assertEquals (homePage.getShadowDomText (), "some text");
assertEquals (homePage.getNestedShadowText (),"nested text");
assertEquals (homePage.getNestedText (), "nested text");
assertEquals (homePage.getNestedTextUsingJSExecutor (), "nested text");
}这是一个简单的测试,用于断言文本显示是否符合预期。我们将使用TestNG中的assertEquals()断言进行检查。
实际值中,我们提供刚编写的从页面获取文本的方法,预期值则根据断言的不同,传递“some text”或”nested text”。
测试中提供了四个assertEquals语句。
- 使用
getShadowRoot()方法检查Shadow DOM元素:
- 使用
getShadowRoot()方法检查嵌套的Shadow DOM元素:
- 使用
getShadowRoot()方法流畅地检查嵌套的Shadow DOM元素:
执行
有两种方式运行Selenium中自动化Shadow DOM的测试:
- 通过IDE使用TestNG
- 通过CLI使用Maven
使用TestNG在Selenium WebDriver中自动化Shadow DOM
TestNG被用作测试运行器。因此,创建了testng.xml文件,通过右键点击该文件并选择运行‘…\testng.xml’选项来执行测试。但在运行测试之前,我们需要在运行配置中添加LambdaTest用户名和访问密钥,因为我们是从系统属性中读取这些信息的。
LambdaTest提供了一个在线浏览器农场,涵盖超过3000种真实浏览器和操作系统,支持您在本地或在云端运行Java测试。您可以通过在多种浏览器和操作系统配置上并行运行测试,加速Java的Selenium测试,大幅减少测试执行时间。
- 请按照以下说明在运行配置中添加值:
- Dusername =
< LambdaTest 用户名 > - DaccessKey =
< LambdaTest 访问密钥 >
- Dusername =
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Sauce Demo Website Tests">
<test name="Shadow DOM Tests on Watir Website">
<parameter name="browser" value="remote-chrome"/>
<classes>
<class name="ShadowDomTests">
<methods>
<include name="testShadowDomWatir"/>
</methods>
</class>
</classes>
</test> <!-- Test -->
</suite>以下是使用Intellij IDE在Selenium中本地运行Shadow DOM的测试截图。
使用Maven自动化Selenium WebDriver中的Shadow DOM
要使用Maven运行测试,请执行以下步骤以自动化Selenium中的Shadow DOM:
- 打开命令提示符/终端。
- 导航至项目根目录。
- 输入命令:
mvn clean install -Dusername=< LambdaTest 用户名 > -DaccessKey=< LambdaTest 访问密钥 >。
以下是来自IntelliJ的截图,展示了使用Maven执行测试的状态:
测试成功运行后,我们可以查看LambdaTest仪表板,浏览所有视频录制、截图、设备日志以及测试运行的详细步骤。请查看下方截图,它们将为您提供自动化应用测试仪表板的清晰概念。
 LambdaTest仪表板
LambdaTest仪表板
以下截图展示了用于自动化Selenium中Shadow DOM的构建和测试细节。再次,每个测试的名称、浏览器名称、浏览器版本、操作系统名称、相应的操作系统版本以及屏幕分辨率均清晰可见。
还包括了测试运行的视频,更直观地展示了测试在设备上的执行情况。
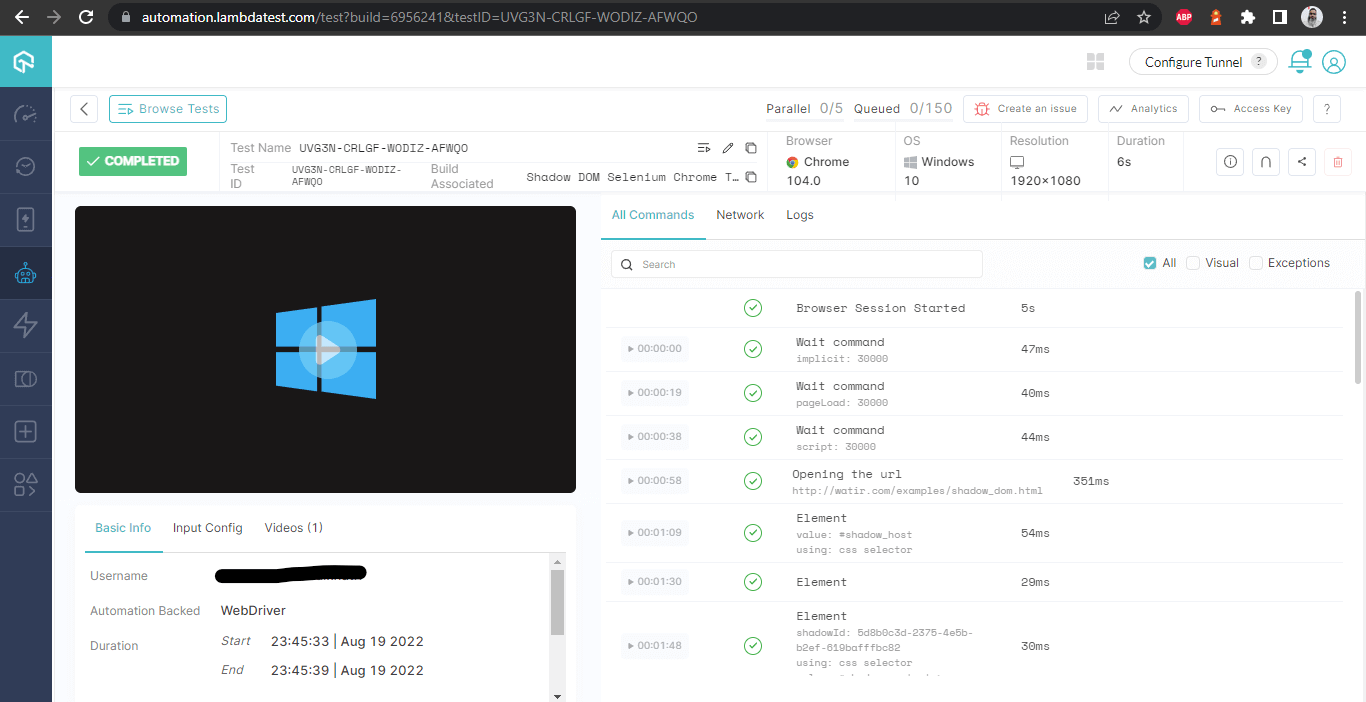 构建详情
构建详情
此屏幕详细展示了所有指标,从测试者的角度来看,非常有帮助,可以检查在哪个浏览器上运行了哪些测试,并据此查看自动化Shadow DOM的Selenium日志。
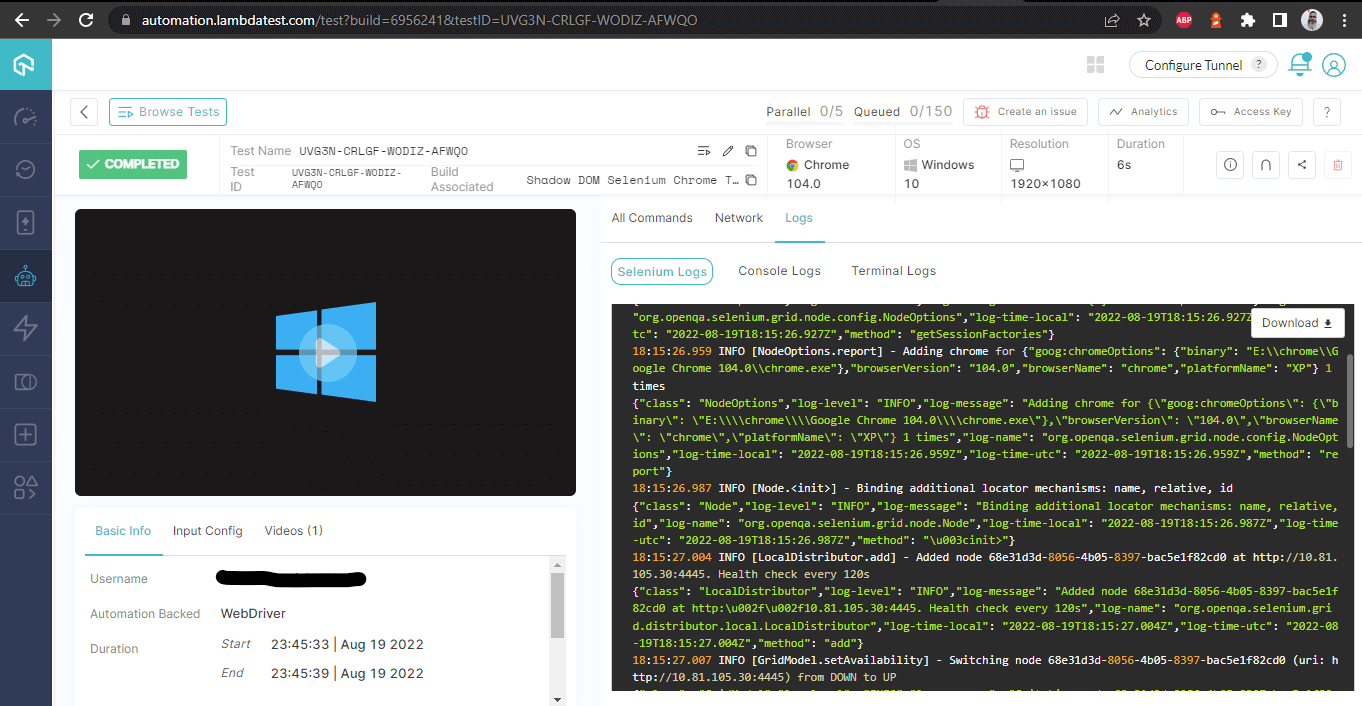 构建详情 – 含日志
构建详情 – 含日志
您可以通过LambdaTest分析仪表板访问最新的测试结果、其状态以及通过或失败的测试总数。此外,您还可以在测试概览部分查看最近执行的测试运行的快照。
结论
在本篇关于Selenium中自动化Shadow DOM的博客中,我们探讨了如何使用Selenium WebDriver 4.0.0及以上版本引入的getShadowRoot()方法查找并自动化Shadow DOM元素。
我们还讨论了如何使用JavaScriptExecutor在Selenium WebDriver中定位并自动化Shadow DOM元素,并在LambdaTest平台上运行测试,该平台展示了使用Selenium WebDriver日志运行的测试的详细信息。
I hope this blog on Shadow DOM in Selenium gives you a fair idea about automating Shadow DOM elements using Selenium WebDriver.
祝您测试愉快!
Source:
https://dzone.com/articles/how-to-automate-shadow-dom-in-selenium-webdriver