













Python Pandas模块
- Pandas是Python中的一个开源库。它提供了可直接使用的高性能数据结构和数据分析工具。
- Pandas模块运行在NumPy之上,广泛用于数据科学和数据分析。
- NumPy是一个低级数据结构,支持多维数组和各种数学数组操作。Pandas具有更高级别的接口。它还提供了流畅的表格数据对齐和强大的时间序列功能。
- DataFrame是Pandas中的关键数据结构。它允许我们将表格数据存储和操作为2-D数据结构。
- Pandas在DataFrame上提供了丰富的功能集。例如,数据对齐,数据统计,切片,分组,合并,连接数据等。
安装并开始使用Pandas
您需要安装Python 2.7及以上版本才能安装Pandas模块。如果您使用的是conda,则可以使用以下命令进行安装。
conda install pandas
如果你正在使用PIP,则运行以下命令来安装pandas模块。
pip3.7 install pandas
要在你的Python脚本中导入Pandas和NumPy,请添加以下代码片段:
import pandas as pd
import numpy as np
由于Pandas依赖于NumPy库,我们需要导入这个依赖。
Pandas模块中的数据结构
由Pandas模块提供了3种数据结构,分别是:
- Series:它是一个1-D的大小不可变的数组结构,具有同质数据。
- DataFrames:它是一个2-D的大小可变的表格结构,具有异构类型的列。
- Panel:它是一个3-D的、大小可变的数组。
Pandas DataFrame
DataFrame是最重要和广泛使用的数据结构,是存储数据的标准方式。DataFrame中的数据以行和列对齐,类似于SQL表或电子表格数据库。我们可以将数据硬编码到DataFrame中,也可以导入CSV文件、tsv文件、Excel文件、SQL表等。我们可以使用以下构造函数来创建一个DataFrame对象。
pandas.DataFrame(data, index, columns, dtype, copy)
下面是参数的简要说明:
- 数据 – 从输入数据创建一个DataFrame对象。它可以是列表、字典、Series、Numpy ndarrays,甚至任何其他DataFrame。
- 索引 – 包含行标签
- 列 – 用于创建列标签
- dtype – 用于指定每列的数据类型,可选参数
- 复制 – 用于复制数据,如果有的话
创建DataFrame有许多方法。我们可以从字典或字典列表创建DataFrame对象。我们也可以从元组列表、CSV、Excel文件等创建。让我们运行一个简单的代码,从字典列表创建一个DataFrame。
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)
输出:  第一步是创建一个字典。第二步是将字典作为参数传递给DataFrame()方法。最后一步是打印DataFrame。正如你所见,DataFrame可以看作是一个具有异构值的表格。此外,DataFrame的大小可以修改。我们已经以映射的形式提供了数据,映射的键被Pandas视为行标签。索引显示在最左侧列中,具有行标签。列标题和数据以表格形式显示。还可以创建带索引的DataFrame。这可以通过在
第一步是创建一个字典。第二步是将字典作为参数传递给DataFrame()方法。最后一步是打印DataFrame。正如你所见,DataFrame可以看作是一个具有异构值的表格。此外,DataFrame的大小可以修改。我们已经以映射的形式提供了数据,映射的键被Pandas视为行标签。索引显示在最左侧列中,具有行标签。列标题和数据以表格形式显示。还可以创建带索引的DataFrame。这可以通过在DataFrame()方法中配置索引参数来完成。
从CSV导入数据到DataFrame
我们还可以通过导入CSV文件来创建一个DataFrame。CSV文件是一个文本文件,每行包含一条数据记录。记录内的值使用“逗号”字符分隔。Pandas提供了一个有用的方法,名为read_csv(),用于将CSV文件的内容读取到DataFrame中。例如,我们可以创建一个名为‘cities.csv’的文件,其中包含印度城市的详细信息。CSV文件存储在包含Python脚本的同一目录中。可以使用以下方式导入这个文件:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
。我们的目标是加载数据并分析以得出结论。因此,我们可以使用任何方便的方法加载数据。在本教程中,我们正在对DataFrame的数据进行硬编码。
检查DataFrame中的数据
运行DataFrame使用它的名称显示整个表格。在实时情况下,要分析的数据集将有数千行。为了分析数据,我们需要检查来自大量数据集的数据。 Pandas提供了许多有用的函数,只检查我们需要的数据。我们可以使用df.head(n)来获取前n行,或者df.tail(n)来打印最后n行。例如,下面的代码从DataFrame中打印前2行和最后1行。
print(df.head(2))
输出: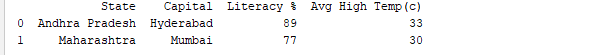
print(df.tail(1))
输出: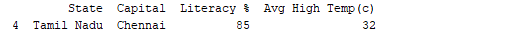 类似地,
类似地,print(df.dtypes)打印数据类型。输出: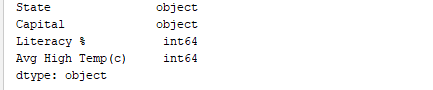
print(df.index)打印索引。输出:
print(df.columns)打印DataFrame的列。输出: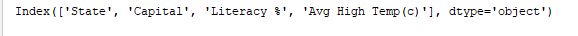
print(df.values)显示表格值。输出:
1. 获取记录的统计摘要
我们可以使用df.describe()函数获取数据的统计摘要(计数、均值、标准差、最小值、最大值等)。现在,让我们使用这个函数来显示“Literacy %”列的统计摘要。为此,我们可以添加下面的代码片段:
print(df['Literacy %'].describe())
输出: 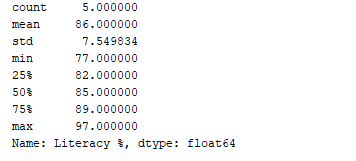
df.describe()函数显示了统计摘要,以及数据类型。
2. 排序记录
我们可以使用df.sort_values()函数按任何列对记录进行排序。例如,让我们按降序对“Literacy %”列进行排序。
print(df.sort_values('Literacy %', ascending=False))
输出: 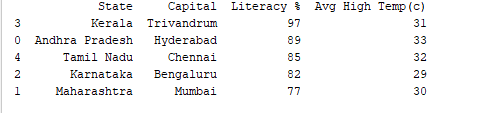
3. 切片记录
可以通过使用列名来提取特定列的数据。例如,要提取‘Capital’列,我们使用:
df['Capital']
或
(df.Capital)
也可以对多列进行切片。方法是将多个列名放在两个方括号中,并用逗号分隔。以下代码对DataFrame的“State”和“Capital”列进行切片。
print(df[['State', 'Capital']])
输出:  也可以对行进行切片。可以使用“:”运算符选择多行。以下代码返回前3行。
也可以对行进行切片。可以使用“:”运算符选择多行。以下代码返回前3行。
df[0:3]
输出:  Pandas库的一个有趣特性是使用
Pandas库的一个有趣特性是使用iloc[0]函数基于其行和列标签选择数据。许多时候,我们可能只需要分析几列。我们也可以使用loc['index_one'])按索引选择。例如,要选择第二行,我们可以使用df.iloc[1,:]。假设我们需要选择第二列的第二个元素。这可以通过使用df.iloc[1,1]函数来实现。在这个例子中,函数df.iloc[1,1]的输出为“Mumbai”。
4. 数据筛选
也可以根据列值进行筛选。例如,下面的代码筛选了文化程度大于90%的列。
print(df[df['Literacy %']>90])
任何比较运算符都可以用于根据条件进行过滤。输出:  另一种过滤数据的方法是使用
另一种过滤数据的方法是使用isin。以下是仅过滤出“Karnataka”和“Tamil Nadu”两个州的代码。
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])
输出: 
5. 重命名列
可以使用df.rename()函数来重命名列。该函数以旧列名和新列名作为参数。例如,让我们将列“Literacy %”重命名为“Literacy percentage”。
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())
参数`inplace=True`将更改应用于DataFrame。输出: 
6. 数据整理
数据科学涉及对数据的处理,使数据能够与数据算法良好配合。数据整理是处理数据的过程,如合并、分组和连接。Pandas库提供了有用的函数,如 merge()、groupby() 和 concat(),以支持数据整理任务。让我们创建两个数据框,并展示数据整理函数,以更好地理解它。
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)
输出:  现在,让我们使用以下代码创建第二个数据框:
现在,让我们使用以下代码创建第二个数据框:
import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)
输出: 
a. Merging
现在,让我们通过 ‘Employee_id’ 列的值合并我们创建的两个数据框,使用 merge() 函数:
print(pd.merge(df1, df2, on='Employee_id'))
输出:  我们可以看到,merge() 函数返回具有相同列值的两个数据框的行,这些值在合并时使用。
我们可以看到,merge() 函数返回具有相同列值的两个数据框的行,这些值在合并时使用。
b. Grouping
分组是将数据收集到不同类别的过程。例如,在下面的示例中,“Employee_Name”字段两次具有名称“Meera”。因此,让我们按“Employee_name”列对其进行分组。
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
“Employee_name”字段的值为“Meera”已按“Employee_name”列进行分组。示例输出如下:输出: 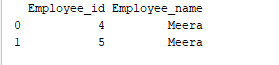
c. Concatenating
连接数据涉及将一组数据添加到另一组数据中。 Pandas提供了一个名为concat()的函数来连接数据框。例如,让我们使用以下方式连接数据框df1和df2:
print(pd.concat([df1, df2]))
输出: 
通过传递系列字典创建数据框
要创建一个系列,我们可以使用pd.Series()方法并将数组传递给它。让我们创建一个简单的系列,如下所示:
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)
输出:  我们已经创建了一个系列。您可以看到显示了2列。第一列包含从0开始的索引值。第二列包含作为系列传递的元素。可以通过传递`Series`字典来创建数据框。让我们创建一个由系列的索引联合和传递而成的数据框。例子
我们已经创建了一个系列。您可以看到显示了2列。第一列包含从0开始的索引值。第二列包含作为系列传递的元素。可以通过传递`Series`字典来创建数据框。让我们创建一个由系列的索引联合和传递而成的数据框。例子
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
示例输出 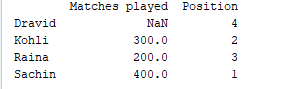 对于第一个系列,因为我们没有指定标签‘d’,所以返回NaN。
对于第一个系列,因为我们没有指定标签‘d’,所以返回NaN。
列选择,添加,删除
可以从DataFrame中选择特定的列。例如,要仅显示第一列,我们可以将上述代码改写为:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
上述代码仅打印DataFrame的“比赛场次”列。输出 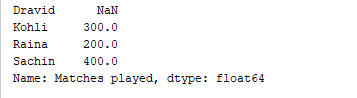 还可以向现有的DataFrame中添加列。例如,下面的代码向上述DataFrame中添加了一个名为“Runrate”的新列。
还可以向现有的DataFrame中添加列。例如,下面的代码向上述DataFrame中添加了一个名为“Runrate”的新列。
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
输出:  我们可以使用`delete`和`pop`函数删除列。例如,要删除上面示例中的‘比赛场次’列,可以通过以下两种方式之一:
我们可以使用`delete`和`pop`函数删除列。例如,要删除上面示例中的‘比赛场次’列,可以通过以下两种方式之一:
del df['Matches played']
或
df.pop('Matches played')
输出: 
结论
在这个教程中,我们对Python Pandas库进行了简要介绍。我们还进行了实际示例,以释放在数据科学领域中使用的Pandas库的强大功能。我们还介绍了Python库中的不同数据结构。参考:Pandas官方网站
Source:
https://www.digitalocean.com/community/tutorials/python-pandas-module-tutorial