













وحدة بانداس بايثون
- بانداس هي مكتبة مفتوحة المصدر في بايثون. توفر هياكل بيانات عالية الأداء جاهزة للاستخدام وأدوات تحليل البيانات.
- تعمل وحدة بانداس على قمة نمباي وتستخدم بشكل شائع في علوم البيانات وتحليل البيانات.
- نمباي هي هيكل بيانات منخفض المستوى يدعم مصفوفات متعددة الأبعاد ومجموعة واسعة من العمليات الرياضية على المصفوفات. بانداس لديها واجهة عالية المستوى. كما توفر ميزة تنسيق بيانات الجداول ووظائف قوية لسلاسل الزمن.
- الإطار البياني هو الهيكل البياني الرئيسي في بانداس. يتيح لنا تخزين البيانات الجدولية وتلاعبها كهيكل بيانات ثنائي الأبعاد.
- توفر بانداس مجموعة غنية من الميزات على الإطار البياني. على سبيل المثال، مواءمة البيانات، وإحصائيات البيانات، التقسيم، التجميع، دمج، اتصال البيانات، إلخ.
التثبيت والبدء في العمل مع بانداس
تحتاج إلى أن تكون لديك بايثون 2.7 وما فوق لتثبيت وحدة بانداس. إذا كنت تستخدم كوندا، فيمكنك تثبيتها باستخدام الأمر التالي.
conda install pandas
إذا كنت تستخدم PIP، قم بتشغيل الأمر التالي لتثبيت وحدة البانداس.
pip3.7 install pandas
ليتم استيراد بانداس ونمباي في برنامج Python الخاص بك، أضف الكود التالي:
import pandas as pd
import numpy as np
نظرًا لأن بانداس يعتمد على مكتبة نمباي، فإننا بحاجة لاستيراد هذا التبعية.
هياكل البيانات في وحدة بانداس
هناك 3 هياكل بيانات يوفرها وحدة بانداس، وهي كما يلي:
- سلسلة: هي هيكل بيانات ثنائي الأبعاد غير قابل للتغيير الحجم ويحتوي على بيانات متجانسة.
- إطار بيانات: هو هيكل بيانات ثنائي الأبعاد قابل للتغيير الحجم ويحتوي على أعمدة بأنواع مختلفة.
- لوحة: هو هيكل بيانات ثلاثي الأبعاد قابل للتغيير الحجم.
إطار بيانات بانداس
إطار البيانات هو أهم وأكثر هيكل بيانات استخدامًا وهو الطريقة القياسية لتخزين البيانات. يحتوي إطار البيانات على بيانات مرتبة في صفوف وأعمدة مثل جدول SQL أو قاعدة بيانات جدولية. يمكننا إما تضمين البيانات يدويًا في إطار البيانات أو استيراد ملف CSV، ملف TSV، ملف Excel، جدول SQL، إلخ. يمكننا استخدام البناء التالي لإنشاء كائن إطار البيانات.
pandas.DataFrame(data, index, columns, dtype, copy)
فيما يلي وصف مختصر للمعلمات:
- البيانات – إنشاء كائن DataFrame من البيانات المدخلة. يمكن أن تكون قائمة، قاموس، سلسلة، Numpy ndarrays أو حتى أي DataFrame آخر.
- index – لديه تسميات الصفوف
- columns – تستخدم لإنشاء تسميات الأعمدة
- dtype – تستخدم لتحديد نوع البيانات لكل عمود، معلمة اختيارية
- copy – تستخدم لنسخ البيانات، إذا كانت هناك
هناك العديد من الطرق لإنشاء DataFrame. يمكننا إنشاء كائن DataFrame من القواميس أو قائمة من القواميس. يمكننا أيضًا إنشاؤها من قائمة من الأزواج، CSV، ملف Excel، إلخ. دعونا نقوم بتشغيل كود بسيط لإنشاء DataFrame من قائمة القواميس.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)
الناتج:  الخطوة الأولى هي إنشاء قاموس. الخطوة الثانية هي تمرير القاموس كوسيط في طريقة DataFrame(). الخطوة النهائية هي طباعة DataFrame. كما ترى، يمكن مقارنة DataFrame بجدول يحتوي على قيم متنوعة. أيضًا، يمكن تعديل حجم DataFrame. لقد قمنا بتوريد البيانات على شكل خريطة وتعتبر مفاتيح الخريطة من قبل Pandas كتسميات الصفوف. يتم عرض الفهرس في العمود الأيسر ولديه تسميات الصفوف. يتم عرض رأس العمود والبيانات بشكل جدولي. من الممكن أيضًا إنشاء DataFrames مؤشرة. يمكن القيام بذلك عن طريق تكوين معلمة الفهرس في طريقة
الخطوة الأولى هي إنشاء قاموس. الخطوة الثانية هي تمرير القاموس كوسيط في طريقة DataFrame(). الخطوة النهائية هي طباعة DataFrame. كما ترى، يمكن مقارنة DataFrame بجدول يحتوي على قيم متنوعة. أيضًا، يمكن تعديل حجم DataFrame. لقد قمنا بتوريد البيانات على شكل خريطة وتعتبر مفاتيح الخريطة من قبل Pandas كتسميات الصفوف. يتم عرض الفهرس في العمود الأيسر ولديه تسميات الصفوف. يتم عرض رأس العمود والبيانات بشكل جدولي. من الممكن أيضًا إنشاء DataFrames مؤشرة. يمكن القيام بذلك عن طريق تكوين معلمة الفهرس في طريقة DataFrame().
استيراد البيانات من CSV إلى DataFrame
يمكننا أيضًا إنشاء DataFrame عن طريق استيراد ملف CSV. ملف CSV هو ملف نصي يحتوي على سجل واحد من البيانات في كل سطر. تتم فصل القيم داخل السجل باستخدام الحرف “الفاصلة المنقوطة”. توفر مكتبة Pandas طريقة مفيدة تسمى read_csv() لقراءة محتويات ملف CSV إلى DataFrame. على سبيل المثال، يمكننا إنشاء ملف يسمى “cities.csv” يحتوي على تفاصيل المدن الهندية. يتم تخزين ملف CSV في نفس الدليل الذي يحتوي على البرامج النصية بالبايثون. يمكن استيراد هذا الملف باستخدام:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
. هدفنا هو تحميل البيانات وتحليلها لاستخلاص الاستنتاجات. لذا، يمكننا استخدام أي طريقة مناسبة لتحميل البيانات. في هذا البرنامج التعليمي، نقوم بتضمين البيانات في DataFrame بشكل يدوي.
تفقد البيانات في DataFrame
تشغيل إطار البيانات باستخدام اسمه يعرض الجدول بالكامل. في الوقت الحقيقي، ستحتوي مجموعات البيانات التي نريد تحليلها على آلاف الصفوف. لتحليل البيانات، نحتاج إلى فحص البيانات من مجموعات بيانات ضخمة. توفر مكتبة بانداس العديد من الوظائف المفيدة لفحص البيانات التي نحتاجها فقط. يمكننا استخدام df.head(n) للحصول على أول n صفوف أو df.tail(n) لطباعة آخر n صفوف. على سبيل المثال، يطبع الكود أدناه أول 2 صفوف وآخر صف واحد من الإطار البيانات.
print(df.head(2))
الناتج: 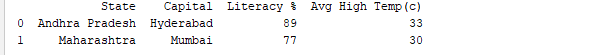
print(df.tail(1))
الناتج: 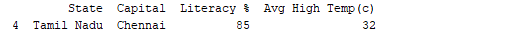 بالمثل،
بالمثل، print(df.dtypes) يطبع أنواع البيانات. الناتج: 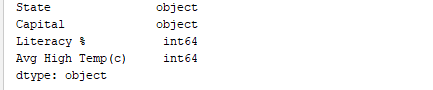
print(df.index) يطبع الفهرس. الناتج: 
print(df.columns) يطبع أعمدة إطار البيانات. الناتج: 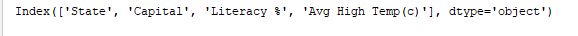
print(df.values) يعرض قيم الجدول. الناتج: 
1. الحصول على ملخص إحصائي للسجلات
يمكننا الحصول على ملخص إحصائي (العدد، المتوسط، الانحراف المعياري، الحد الأدنى، الحد الأقصى إلخ) للبيانات باستخدام وظيفة df.describe(). الآن، دعنا نستخدم هذه الوظيفة لعرض الملخص الإحصائي لعمود “نسبة القراءة”. للقيام بذلك، يمكننا إضافة الكود التالي:
print(df['Literacy %'].describe())
الناتج: 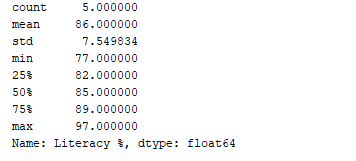 وظيفة
وظيفة df.describe() تعرض الملخص الإحصائي، إلى جانب نوع البيانات.
2. فرز السجلات
يمكننا فرز السجلات حسب أي عمود باستخدام وظيفة df.sort_values(). على سبيل المثال، دعنا نرتب عمود “نسبة القراءة” بترتيب تنازلي.
print(df.sort_values('Literacy %', ascending=False))
الناتج: 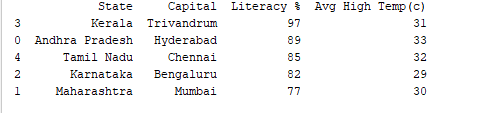
3. تقطيع السجلات
من الممكن استخراج بيانات عمود معين، عن طريق استخدام اسم العمود. على سبيل المثال، لاستخراج عمود “العاصمة”، نستخدم:
df['Capital']
أو
(df.Capital)
الناتج:  يمكن أيضًا تقسيم عدة أعمدة. يتم ذلك عن طريق تضمين أسماء عمود متعددة محاطة بقوسين مربعين ، حيث يتم فصل أسماء الأعمدة باستخدام فواصل. يقوم الكود التالي بتقسيم أعمدة ‘الولاية’ و ‘العاصمة’ لإطار البيانات.
يمكن أيضًا تقسيم عدة أعمدة. يتم ذلك عن طريق تضمين أسماء عمود متعددة محاطة بقوسين مربعين ، حيث يتم فصل أسماء الأعمدة باستخدام فواصل. يقوم الكود التالي بتقسيم أعمدة ‘الولاية’ و ‘العاصمة’ لإطار البيانات.
print(df[['State', 'Capital']])
الناتج:  يمكن أيضًا تقسيم الصفوف. يمكن تحديد عدة صفوف باستخدام عامل “:”. يُرجى العودة إلى الكود أدناه الذي يعيد الصفوف الثلاثة الأولى.
يمكن أيضًا تقسيم الصفوف. يمكن تحديد عدة صفوف باستخدام عامل “:”. يُرجى العودة إلى الكود أدناه الذي يعيد الصفوف الثلاثة الأولى.
df[0:3]
الناتج:  ميزة مثيرة للاهتمام في مكتبة بانداس هي تحديد البيانات استنادًا إلى تسميات الصف والعمود باستخدام وظيفة iloc[0]. في كثير من الأحيان ، قد نحتاج إلى عدد قليل فقط من الأعمدة للتحليل. يمكننا أيضًا تحديد حسب الفهرس باستخدام loc[‘index_one’]). على سبيل المثال ، لتحديد الصف الثاني ، يمكننا استخدام df.iloc[1,:]. لنفترض ، أننا بحاجة إلى تحديد العنصر الثاني من العمود الثاني. يمكن القيام بذلك باستخدام وظيفة df.iloc[1,1]. في هذا المثال ، تعرض الوظيفة df.iloc[1,1] “مومباي” كناتج.
ميزة مثيرة للاهتمام في مكتبة بانداس هي تحديد البيانات استنادًا إلى تسميات الصف والعمود باستخدام وظيفة iloc[0]. في كثير من الأحيان ، قد نحتاج إلى عدد قليل فقط من الأعمدة للتحليل. يمكننا أيضًا تحديد حسب الفهرس باستخدام loc[‘index_one’]). على سبيل المثال ، لتحديد الصف الثاني ، يمكننا استخدام df.iloc[1,:]. لنفترض ، أننا بحاجة إلى تحديد العنصر الثاني من العمود الثاني. يمكن القيام بذلك باستخدام وظيفة df.iloc[1,1]. في هذا المثال ، تعرض الوظيفة df.iloc[1,1] “مومباي” كناتج.
4. تصفية البيانات
يمكن أيضًا تصفية قيم العمود. على سبيل المثال ، يقوم الكود أدناه بتصفية الأعمدة التي تحتوي على نسبة القراءة أعلى من 90%.
print(df[df['Literacy %']>90])
يمكن استخدام أي مشغل مقارنة للتصفية، استنادًا إلى شرط معين. الإخراج:  طريقة أخرى لتصفية البيانات هي باستخدام
طريقة أخرى لتصفية البيانات هي باستخدام isin. فيما يلي الكود لتصفية الحالات الواحدة فقط ‘كارناتاكا’ و ‘تاميل نادو’.
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])
الإخراج: 
5. إعادة تسمية العمود
من الممكن استخدام الدالة df.rename() لإعادة تسمية عمود. تأخذ الدالة اسم العمود القديم واسم العمود الجديد كمعلمات. على سبيل المثال، دعونا نعيد تسمية العمود ‘نسبة القراءة’ إلى ‘نسبة القراءة’.
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())
الوسيطة `inplace=True` تجعل التغييرات على إطار البيانات. الإخراج: 
6. تهيئة البيانات
تتضمن علم البيانات معالجة البيانات بحيث يمكن للبيانات العمل بشكل جيد مع خوارزميات البيانات. تعتبر تهيئة البيانات عملية معالجة البيانات، مثل الدمج والتجميع والدمج. توفر مكتبة Pandas وظائف مفيدة مثل merge()، groupby() و concat() لدعم مهام تهيئة البيانات. لنقم بإنشاء 2 DataFrame وعرض وظائف تهيئة البيانات لفهمها بشكل أفضل.
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)
الناتج:  لنقم بإنشاء الـ DataFrame الثاني باستخدام الشيفرة التالية:
لنقم بإنشاء الـ DataFrame الثاني باستخدام الشيفرة التالية:
import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)
الناتج: 
a. Merging
الآن، لنقم بدمج الـ DataFrameين التي أنشأناها، بجانب قيم “رقم الموظف” باستخدام وظيفة merge():
print(pd.merge(df1, df2, on='Employee_id'))
الناتج:  يمكننا رؤية أن وظيفة merge() ترجع الصفوف من كلا الـ DataFrame تحتوي على نفس قيمة العمود، التي تم استخدامها أثناء الدمج.
يمكننا رؤية أن وظيفة merge() ترجع الصفوف من كلا الـ DataFrame تحتوي على نفس قيمة العمود، التي تم استخدامها أثناء الدمج.
b. Grouping
التجميع هو عملية جمع البيانات في فئات مختلفة. على سبيل المثال، في المثال أدناه، يحتوي حقل “اسم الموظف” على اسم “ميرا” مرتين. لذا، دعونا نقوم بتجميعه بواسطة عمود “اسم الموظف”.
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
يتم تجميع حقل “اسم الموظف” الذي يحتوي على قيمة “ميرا” بواسطة العمود “اسم الموظف”. الناتج عينة على النحو التالي: الناتج: 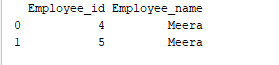
c. Concatenating
تكوين البيانات يتضمن إضافة مجموعة من البيانات إلى أخرى. توفر Pandas وظيفة تسمى concat() لدمج الإطارات البيانية. على سبيل المثال، دعونا نقوم بدمج الإطارات البيانية df1 و df2 باستخدام:
print(pd.concat([df1, df2]))
الناتج: 
إنشاء إطار بيانات عن طريق تمرير قاموس من السلاسل
لإنشاء سلسلة، يمكننا استخدام الطريقة pd.Series() وتمرير مصفوفة إليها. دعونا نقوم بإنشاء سلسلة بسيطة كما يلي:
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)
الناتج:  لقد قمنا بإنشاء سلسلة. يمكنكم رؤية أن 2 عمودًا معروضان. يحتوي العمود الأول على قيم الفهرس التي تبدأ من 0. يحتوي العمود الثاني على العناصر الممررة كسلسلة. من الممكن إنشاء إطار بيانات عن طريق تمرير قاموس من `السلاسل`. دعونا نقوم بإنشاء إطار بيانات تم تشكيله بوحدة وتمرير فهارس السلسلة. مثال
لقد قمنا بإنشاء سلسلة. يمكنكم رؤية أن 2 عمودًا معروضان. يحتوي العمود الأول على قيم الفهرس التي تبدأ من 0. يحتوي العمود الثاني على العناصر الممررة كسلسلة. من الممكن إنشاء إطار بيانات عن طريق تمرير قاموس من `السلاسل`. دعونا نقوم بإنشاء إطار بيانات تم تشكيله بوحدة وتمرير فهارس السلسلة. مثال
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
الناتج عينة 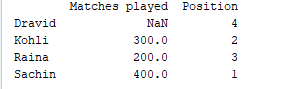 بالنسبة للسلسلة الأولى، حيث لم نحدد العلامة ‘d’، يتم إرجاع NaN.
بالنسبة للسلسلة الأولى، حيث لم نحدد العلامة ‘d’، يتم إرجاع NaN.
اختيار العمود، الإضافة، الحذف
من الممكن تحديد عمود معين من الإطار البيانات. على سبيل المثال، لعرض العمود الأول فقط، يمكننا إعادة كتابة الكود أعلاه كما يلي:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
يطبع الكود أعلاه فقط عمود “المباريات الملعوبة” من الإطار البيانات. الناتج 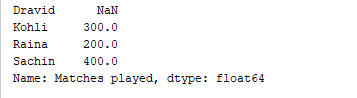 كما يمكننا إضافة أعمدة إلى إطار بيانات موجود. على سبيل المثال، يضيف الكود أدناه عمودًا جديدًا بعنوان “معدل التشغيل” إلى الإطار البيانات السابق.
كما يمكننا إضافة أعمدة إلى إطار بيانات موجود. على سبيل المثال، يضيف الكود أدناه عمودًا جديدًا بعنوان “معدل التشغيل” إلى الإطار البيانات السابق.
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
الناتج:  يمكننا حذف الأعمدة باستخدام وظائف `delete` و `pop`. على سبيل المثال، لحذف العمود “المباريات الملعوبة” في المثال أعلاه، يمكننا القيام بذلك بأحد الطريقتين التاليتين:
يمكننا حذف الأعمدة باستخدام وظائف `delete` و `pop`. على سبيل المثال، لحذف العمود “المباريات الملعوبة” في المثال أعلاه، يمكننا القيام بذلك بأحد الطريقتين التاليتين:
del df['Matches played']
أو
df.pop('Matches played')
الناتج: 
الاستنتاج
Source:
https://www.digitalocean.com/community/tutorials/python-pandas-module-tutorial