













Python Pandas モジュール
- PandasはPythonのオープンソースライブラリです。高パフォーマンスのデータ構造とデータ分析ツールを提供します。
- PandasモジュールはNumPyの上で動作し、データサイエンスやデータ分析でよく使用されます。
- NumPyは多次元配列とさまざまな数学的な配列操作をサポートする低レベルのデータ構造です。Pandasはより高レベルなインターフェースを提供します。また、タブラーデータのシームレスな整列や強力な時系列機能も提供します。
- DataFrameはPandasの主要なデータ構造です。2次元のデータ構造としてタブラーデータを保存し操作することができます。
- PandasはDataFrameに豊富な機能を提供しています。例えば、データの整列、データの統計情報、スライシング、グループ化、データの結合、連結などです。
Pandasのインストールと始め方
Pandasモジュールをインストールするには、Python 2.7以上が必要です。もしcondaを使用している場合は、以下のコマンドを使用してインストールすることができます。
conda install pandas
PIPを使用している場合は、以下のコマンドを実行してpandasモジュールをインストールします。
pip3.7 install pandas
PythonスクリプトでPandasとNumPyをインポートするには、以下のコードを追加します。
import pandas as pd
import numpy as np
PandasはNumPyライブラリに依存しているため、この依存関係をインポートする必要があります。
Pandasモジュールのデータ構造
Pandasモジュールには、以下の3つのデータ構造が用意されています。
- Series:均質なデータを持つ、1次元のサイズが変更不可能な配列のような構造です。
- DataFrames:異種の型を持つ、2次元のサイズが変更可能な表状の構造です。
- Panel:3次元のサイズが変更可能な配列です。
Pandas DataFrame
DataFrameは最も重要で広く使用されるデータ構造であり、データを格納するための標準的な方法です。DataFrameは、行と列に沿ってデータが整列した形式でデータを保持します。DataFrameには、データをハードコードするか、CSVファイル、tsvファイル、Excelファイル、SQLテーブルなどをインポートすることができます。DataFrameオブジェクトを作成するためには、以下のコンストラクタを使用できます。
pandas.DataFrame(data, index, columns, dtype, copy)
以下は、パラメータの短い説明です。
- データ – 入力データからDataFrameオブジェクトを作成します。リスト、辞書、シリーズ、NumPyのndarrayなど、他のDataFrameでも構いません。
- index – 行ラベルを持ちます。
- columns – 列ラベルを作成するために使用します。
- dtype – 各列のデータ型を指定するために使用される、オプションのパラメータです。
- copy – データをコピーするために使用されます。
DataFrameを作成するための多くの方法があります。辞書や辞書のリストからDataFrameオブジェクトを作成することができます。また、タプルのリスト、CSV、Excelファイルなどからも作成することができます。次に、辞書のリストからDataFrameを作成するための簡単なコードを実行しましょう。
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)
出力:  最初のステップは辞書を作成することです。次に、辞書を
最初のステップは辞書を作成することです。次に、辞書をDataFrame()メソッドの引数として渡すことです。最後のステップはDataFrameを表示することです。DataFrameは異種の値を持つテーブルと比較できます。また、DataFrameのサイズは変更できます。データをマップの形式で提供し、マップのキーはPandasによって行ラベルと見なされます。インデックスは左端の列に表示され、行ラベルを持ちます。列ヘッダーとデータは表形式で表示されます。インデックス付きのDataFrameを作成することも可能です。これはDataFrame()メソッドのindexパラメータを設定することで行うことができます。
CSVからデータをDataFrameにインポートする
CSVファイルをインポートしてDataFrameを作成することもできます。CSVファイルは、1行ごとに1つのデータレコードを持つテキストファイルです。レコード内の値は「カンマ」文字を使用して区切られています。Pandasには、CSVファイルの内容をDataFrameに読み込むための便利なメソッドread_csv()が用意されています。たとえば、インドの都市の詳細を含む’cities.csv’という名前のファイルを作成できます。CSVファイルは、Pythonスクリプトが含まれている同じディレクトリに保存されます。このファイルは、次のようにインポートできます:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
。私たちの目的は、データを読み込んで分析し、結論を導くことです。したがって、データを読み込むために便利な方法を使用できます。このチュートリアルでは、DataFrameのデータをハードコーディングしています。
DataFrame内のデータを検査する
DataFrameの名前を使用して実行すると、テーブル全体が表示されます。リアルタイムでは、分析するデータセットは数千行になります。データを分析するためには、膨大なデータセットからデータを検査する必要があります。Pandasは、必要なデータのみを検査するための多くの便利な関数を提供しています。最初のn行を取得するためにdf.head(n)を使用したり、最後のn行を表示するためにdf.tail(n)を使用することができます。以下のコードは、DataFrameから最初の2行と最後の1行を表示します。
print(df.head(2))
出力: 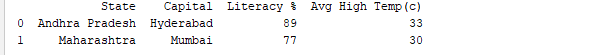
print(df.tail(1))
出力: 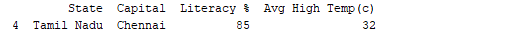 同様に、
同様に、print(df.dtypes)はデータ型を表示します。出力: 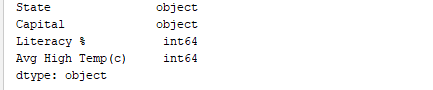
print(df.index)はインデックスを表示します。出力: 
print(df.columns)はDataFrameの列を表示します。出力: 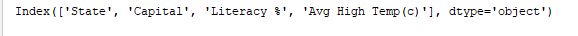
print(df.values)はテーブルの値を表示します。出力: 
1. レコードの統計的な要約の取得
私たちは、df.describe()関数を使用してデータの統計的な要約(カウント、平均、標準偏差、最小値、最大値など)を取得することができます。さて、この関数を使用して、「Literacy %」列の統計的な要約を表示しましょう。これを行うには、以下のコードを追加します:
print(df['Literacy %'].describe())
出力: 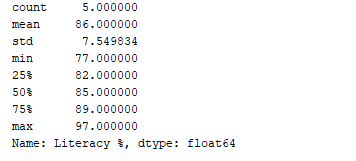
df.describe()関数は、統計的な要約とデータ型を表示します。
2. レコードのソート
df.sort_values()関数を使用して、任意の列でレコードをソートすることができます。例えば、「Literacy %」列を降順でソートしましょう。
print(df.sort_values('Literacy %', ascending=False))
出力: 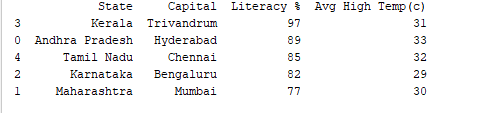
3. レコードのスライス
特定の列のデータを抽出することも可能です。例えば、’Capital’列を抽出するには、以下のようにします:
df['Capital']
または
(df.Capital)
出力:  複数の列をスライスすることも可能です。これは、2つの角括弧で囲まれた複数の列名を使用し、列名をコンマで区切って指定します。次のコードは、DataFrameの「State」と「Capital」の列をスライスします。
複数の列をスライスすることも可能です。これは、2つの角括弧で囲まれた複数の列名を使用し、列名をコンマで区切って指定します。次のコードは、DataFrameの「State」と「Capital」の列をスライスします。
print(df[['State', 'Capital']])
出力:  行のスライスも可能です。複数の行を選択するには、「:」演算子を使用します。以下のコードは最初の3行を返します。
行のスライスも可能です。複数の行を選択するには、「:」演算子を使用します。以下のコードは最初の3行を返します。
df[0:3]
出力:  Pandasライブラリの興味深い機能の1つは、
Pandasライブラリの興味深い機能の1つは、iloc[0]関数を使用して行と列のラベルに基づいてデータを選択することです。多くの場合、分析に必要なのは一部の列だけです。また、loc['index_one'])を使用してインデックスで選択することもできます。たとえば、2行目を選択するには、df.iloc[1,:] を使用します。2番目の列の2番目の要素を選択する場合は、df.iloc[1,1]関数を使用します。この例では、df.iloc[1,1]関数は「Mumbai」という出力を表示します。
4. データのフィルタリング
列の値でフィルタリングすることも可能です。たとえば、以下のコードはLiteracy%が90%を超える列をフィルタリングします。
print(df[df['Literacy %']>90])
条件に基づいてフィルタリングするために、任意の比較演算子を使用することができます。 出力:  データをフィルタリングする別の方法は、
データをフィルタリングする別の方法は、isinを使用することです。以下は、州が「カルナータカ州」と「タミル・ナードゥ州」のみをフィルタリングするコードです。
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])
出力: 
5. 列の名前を変更する
列の名前を変更するには、df.rename()関数を使用することができます。この関数は、古い列名と新しい列名を引数として受け取ります。例えば、列名「Literacy %」を「Literacy percentage」に変更してみましょう。
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())
引数`inplace=True`は、変更をDataFrameに反映します。 出力: 
6. データの整形
データサイエンスは、データを処理してデータアルゴリズムとうまく連携させることを目的としています。データの整形は、結合、グループ化、連結などの処理を行うプロセスです。Pandasライブラリには、データの整形タスクをサポートするための便利な関数(merge()、groupby()、concat())が提供されています。2つのDataFrameを作成し、データ整形の関数を示しましょう。
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)
出力:  以下のコードを使用して、2番目のDataFrameを作成しましょう:
以下のコードを使用して、2番目のDataFrameを作成しましょう:
import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)
出力: 
a. Merging
さて、作成した2つのDataFrameを、’Employee_id’の値を使用してmerge()関数で結合しましょう:
print(pd.merge(df1, df2, on='Employee_id'))
出力:  マージ関数は、結合時に使用された列の値が同じである両方のDataFrameから行を返します。
マージ関数は、結合時に使用された列の値が同じである両方のDataFrameから行を返します。
b. Grouping
グループ化は、データを異なるカテゴリにまとめるプロセスです。以下の例では、「Employee_Name」フィールドに2回「Meera」という名前があります。したがって、「Employee_name」列でグループ化しましょう。
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
値が「Meera」である「Employee_name」フィールドが、「Employee_name」列でグループ化されます。サンプルの出力は以下のようになります:出力: 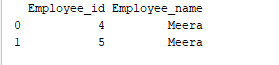
c. Concatenating
データの連結は、1つのデータセットを他のデータセットに追加することを意味します。Pandasは、DataFrameを連結するためのconcat()という関数を提供しています。たとえば、DataFrame df1とdf2を連結する場合、次のようにします:
print(pd.concat([df1, df2]))
出力: 
Dict of Seriesを渡してDataFrameを作成する
Seriesを作成するには、pd.Series()メソッドを使用して、配列を渡すことができます。次のように、単純なSeriesを作成してみましょう:
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)
出力:  Seriesが作成されました。インデックス値が0から始まる最初の列が表示されています。2番目の列には、シリーズとして渡された要素が含まれています。`Series`のインデックスを結合して渡すことでDataFrameを作成することができます。次のように、シリーズのインデックスを結合してDataFrameを作成しましょう。例
Seriesが作成されました。インデックス値が0から始まる最初の列が表示されています。2番目の列には、シリーズとして渡された要素が含まれています。`Series`のインデックスを結合して渡すことでDataFrameを作成することができます。次のように、シリーズのインデックスを結合してDataFrameを作成しましょう。例
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
サンプル出力 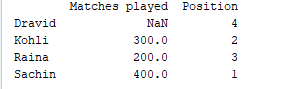 シリーズの1つでは、ラベル ‘d’ が指定されていないため、NaNが返されます。
シリーズの1つでは、ラベル ‘d’ が指定されていないため、NaNが返されます。
列の選択、追加、削除
DataFrameから特定の列を選択することができます。たとえば、上記のコードを以下のように書き換えることで、最初の列のみを表示することができます:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
上記のコードは、DataFrameの「Matches played」列のみを表示します。 出力 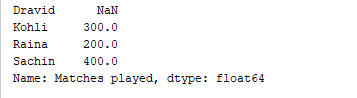 また、既存のDataFrameに列を追加することも可能です。たとえば、以下のコードは上記のDataFrameに「Runrate」という新しい列を追加します。
また、既存のDataFrameに列を追加することも可能です。たとえば、以下のコードは上記のDataFrameに「Runrate」という新しい列を追加します。
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
出力:  `delete`と`pop`関数を使用して列を削除することもできます。たとえば、上記の例で「Matches played」列を削除するには、以下のいずれかの方法で行うことができます:
`delete`と`pop`関数を使用して列を削除することもできます。たとえば、上記の例で「Matches played」列を削除するには、以下のいずれかの方法で行うことができます:
del df['Matches played']
または
df.pop('Matches played')
出力: 
まとめ
このチュートリアルでは、PythonのPandasライブラリについて簡単に紹介しました。また、データサイエンスの分野で使用されるPandasライブラリのパワーを引き出すための実践的な例も行いました。Pythonライブラリの異なるデータ構造にも触れました。参考:Pandas公式ウェブサイト
Source:
https://www.digitalocean.com/community/tutorials/python-pandas-module-tutorial