













Module Python Pandas
- Pandas est une bibliothèque open source en Python. Il fournit des structures de données haute performance prêtes à l’emploi et des outils d’analyse de données.
- Le module Pandas s’exécute sur NumPy et est largement utilisé pour la science des données et l’analyse de données.
- NumPy est une structure de données de bas niveau qui prend en charge des tableaux multidimensionnels et une large gamme d’opérations mathématiques sur les tableaux. Pandas offre une interface de plus haut niveau. Il assure également un alignement simplifié des données tabulaires et une fonctionnalité puissante de séries chronologiques.
- Le DataFrame est la principale structure de données dans Pandas. Il nous permet de stocker et de manipuler des données tabulaires sous forme de structure de données 2D.
- Pandas offre un ensemble de fonctionnalités riches sur le DataFrame. Par exemple, l’alignement des données, les statistiques sur les données, le tranchage, le regroupement, la fusion, la concaténation des données, etc.
Installation et Démarrage avec Pandas
Vous devez avoir Python 2.7 et supérieur pour installer le module Pandas. Si vous utilisez conda, vous pouvez l’installer à l’aide de la commande suivante.
conda install pandas
Si vous utilisez PIP, exécutez la commande ci-dessous pour installer le module pandas.
pip3.7 install pandas
Pour importer Pandas et NumPy dans votre script Python, ajoutez le code ci-dessous:
import pandas as pd
import numpy as np
Comme Pandas dépend de la bibliothèque NumPy, nous devons importer cette dépendance.
Structures de données dans le module Pandas
Le module Pandas propose 3 structures de données, qui sont les suivantes:
- Série: Il s’agit d’une structure de type tableau de taille 1D, immuable et ayant des données homogènes.
- DataFrames: Il s’agit d’une structure tabulaire de taille 2D, mutable, avec des colonnes de types hétérogènes.
- Panel: Il s’agit d’un tableau de taille 3D, mutable.
DataFrames Pandas
Le DataFrame est la structure de données la plus importante et la plus largement utilisée, et c’est une manière standard de stocker des données. Le DataFrame a des données alignées en lignes et en colonnes, comme une table SQL ou une base de données de feuilles de calcul. Nous pouvons soit coder en dur des données dans un DataFrame, soit importer un fichier CSV, un fichier tsv, un fichier Excel, une table SQL, etc. Nous pouvons utiliser le constructeur ci-dessous pour créer un objet DataFrame.
pandas.DataFrame(data, index, columns, dtype, copy)
Voici une brève description des paramètres:
- data – créer un objet DataFrame à partir des données d’entrée. Il peut s’agir d’une liste, d’un dictionnaire, d’une série, de tableaux ndarrays Numpy ou même, de tout autre DataFrame.
- index – contient les étiquettes de ligne
- columns – utilisé pour créer des étiquettes de colonne
- dtype – utilisé pour spécifier le type de données de chaque colonne, paramètre facultatif
- copy – utilisé pour copier des données, le cas échéant
Il existe de nombreuses façons de créer un DataFrame. Nous pouvons créer un objet DataFrame à partir de dictionnaires ou d’une liste de dictionnaires. Nous pouvons également le créer à partir d’une liste de tuples, d’un fichier CSV, Excel, etc. Exécutons un code simple pour créer un DataFrame à partir de la liste de dictionnaires.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)
Sortie:  La première étape consiste à créer un dictionnaire. La deuxième étape consiste à passer le dictionnaire en argument dans la méthode DataFrame(). La dernière étape consiste à imprimer le DataFrame. Comme vous pouvez le voir, le DataFrame peut être comparé à une table ayant des valeurs hétérogènes. De plus, la taille du DataFrame peut être modifiée. Nous avons fourni les données sous forme de map et les clés de la map sont considérées par Pandas comme les étiquettes de ligne. L’index est affiché dans la colonne de gauche et contient les étiquettes de ligne. L’en-tête de colonne et les données sont affichés de manière tabulaire. Il est également possible de créer des DataFrames indexés. Cela peut être fait en configurant le paramètre d’index dans la méthode
La première étape consiste à créer un dictionnaire. La deuxième étape consiste à passer le dictionnaire en argument dans la méthode DataFrame(). La dernière étape consiste à imprimer le DataFrame. Comme vous pouvez le voir, le DataFrame peut être comparé à une table ayant des valeurs hétérogènes. De plus, la taille du DataFrame peut être modifiée. Nous avons fourni les données sous forme de map et les clés de la map sont considérées par Pandas comme les étiquettes de ligne. L’index est affiché dans la colonne de gauche et contient les étiquettes de ligne. L’en-tête de colonne et les données sont affichés de manière tabulaire. Il est également possible de créer des DataFrames indexés. Cela peut être fait en configurant le paramètre d’index dans la méthode DataFrame().
Importation de données depuis un CSV vers DataFrame
Nous pouvons également créer un DataFrame en important un fichier CSV. Un fichier CSV est un fichier texte avec un enregistrement de données par ligne. Les valeurs au sein de l’enregistrement sont séparées par le caractère “virgule”. Pandas fournit une méthode utile, nommée read_csv(), pour lire le contenu du fichier CSV dans un DataFrame. Par exemple, nous pouvons créer un fichier nommé ‘cities.csv’ contenant les détails des villes indiennes. Le fichier CSV est stocké dans le même répertoire qui contient les scripts Python. Ce fichier peut être importé en utilisant :
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
. Notre objectif est de charger les données et de les analyser pour tirer des conclusions. Ainsi, nous pouvons utiliser n’importe quelle méthode pratique pour charger les données. Dans ce tutoriel, nous codons en dur les données du DataFrame.
Inspection des données dans DataFrame
Exécuter le DataFrame en utilisant son nom affiche l’ensemble du tableau. En temps réel, les ensembles de données à analyser auront des milliers de lignes. Pour analyser les données, nous devons inspecter les données de volumes importants d’ensembles de données. Pandas fournit de nombreuses fonctions utiles pour inspecter uniquement les données dont nous avons besoin. Nous pouvons utiliser df.head(n) pour obtenir les n premières lignes ou df.tail(n) pour imprimer les n dernières lignes. Par exemple, le code ci-dessous imprime les 2 premières lignes et la dernière ligne du DataFrame.
print(df.head(2))
Sortie: 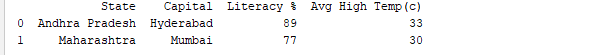
print(df.tail(1))
Sortie: 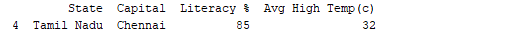 De même,
De même, print(df.dtypes) imprime les types de données. Sortie: 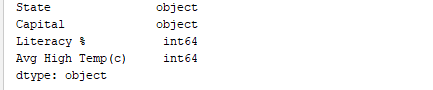
print(df.index) imprime l’index. Sortie: 
print(df.columns) imprime les colonnes du DataFrame. Sortie: 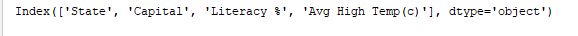
print(df.values) affiche les valeurs du tableau. Sortie: 
1. Obtenir un résumé statistique des enregistrements
Nous pouvons obtenir un résumé statistique (comptage, moyenne, écart type, min, max, etc.) des données en utilisant la fonction df.describe(). Maintenant, utilisons cette fonction pour afficher le résumé statistique de la colonne « Literacy % ». Pour ce faire, nous pouvons ajouter le code suivant :
print(df['Literacy %'].describe())
Output : 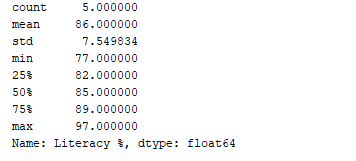 La fonction
La fonction df.describe() affiche le résumé statistique, ainsi que le type de données.
2. Tri des enregistrements
Nous pouvons trier les enregistrements par n’importe quelle colonne en utilisant la fonction df.sort_values(). Par exemple, trions la colonne « Literacy % » par ordre décroissant.
print(df.sort_values('Literacy %', ascending=False))
Output : 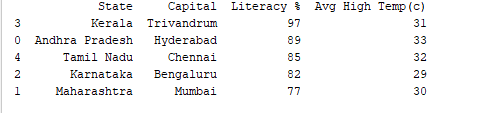
3. Tronçonnage des enregistrements
Il est possible d’extraire des données d’une colonne particulière en utilisant le nom de la colonne. Par exemple, pour extraire la colonne ‘Capital’, nous utilisons :
df['Capital']
ou
(df.Capital)
Sortie:  Il est également possible de découper plusieurs colonnes. Cela se fait en encadrant plusieurs noms de colonnes entre crochets, avec les noms de colonnes séparés par des virgules. Le code suivant découpe les colonnes ‘State’ et ‘Capital’ du DataFrame.
Il est également possible de découper plusieurs colonnes. Cela se fait en encadrant plusieurs noms de colonnes entre crochets, avec les noms de colonnes séparés par des virgules. Le code suivant découpe les colonnes ‘State’ et ‘Capital’ du DataFrame.
print(df[['State', 'Capital']])
Sortie:  Il est également possible de découper des lignes. Plusieurs lignes peuvent être sélectionnées en utilisant l’opérateur “:”. Le code ci-dessous retourne les trois premières lignes.
Il est également possible de découper des lignes. Plusieurs lignes peuvent être sélectionnées en utilisant l’opérateur “:”. Le code ci-dessous retourne les trois premières lignes.
df[0:3]
Sortie:  Une caractéristique intéressante de la bibliothèque Pandas est de sélectionner des données en fonction de leurs étiquettes de ligne et de colonne à l’aide de la fonction
Une caractéristique intéressante de la bibliothèque Pandas est de sélectionner des données en fonction de leurs étiquettes de ligne et de colonne à l’aide de la fonction iloc[0]. Souvent, nous pouvons avoir besoin de seulement quelques colonnes pour analyser. Nous pouvons également sélectionner par index en utilisant la fonction loc['index_one']). Par exemple, pour sélectionner la deuxième ligne, nous pouvons utiliser df.iloc[1,:]. Disons, nous devons sélectionner le deuxième élément de la deuxième colonne. Cela peut être fait en utilisant la fonction df.iloc[1,1]. Dans cet exemple, la fonction df.iloc[1,1] affiche “Mumbai” en sortie.
4. Filtrer les données
Il est également possible de filtrer sur les valeurs des colonnes. Par exemple, le code ci-dessous filtre les colonnes ayant un taux de littératie supérieur à 90 %.
print(df[df['Literacy %']>90])
Tout opérateur de comparaison peut être utilisé pour filtrer, en fonction d’une condition. Sortie :  Une autre façon de filtrer les données est d’utiliser le
Une autre façon de filtrer les données est d’utiliser le isin. Voici le code pour filtrer uniquement les 2 états ‘Karnataka’ et ‘Tamil Nadu’.
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])
Sortie : 
5. Renommer une colonne
Il est possible d’utiliser la fonction df.rename() pour renommer une colonne. La fonction prend en arguments l’ancien nom de la colonne et le nouveau nom de la colonne. Par exemple, renommons la colonne ‘Literacy %’ en ‘Pourcentage de l’alphabétisation’.
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())
L’argument `inplace=True` applique les modifications au DataFrame. Sortie : 
6. Traitement des données
La science des données implique le traitement des données afin que les algorithmes de données puissent bien fonctionner avec les données. Le nettoyage des données est le processus de traitement des données, tel que la fusion, le regroupement et la concaténation. La bibliothèque Pandas fournit des fonctions utiles telles que merge(), groupby() et concat() pour prendre en charge les tâches de nettoyage des données. Créons 2 DataFrames et montrons les fonctions de nettoyage des données pour mieux comprendre.
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)
Sortie:  Créons maintenant le deuxième DataFrame en utilisant le code ci-dessous :
Créons maintenant le deuxième DataFrame en utilisant le code ci-dessous :
import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)
Sortie: 
a. Merging
Maintenant, fusionnons les 2 DataFrames que nous avons créés, le long des valeurs de ‘Employee_id’ en utilisant la fonction merge() :
print(pd.merge(df1, df2, on='Employee_id'))
Sortie:  Nous pouvons voir que la fonction merge() renvoie les lignes des deux DataFrames ayant la même valeur de colonne, qui a été utilisée lors de la fusion.
Nous pouvons voir que la fonction merge() renvoie les lignes des deux DataFrames ayant la même valeur de colonne, qui a été utilisée lors de la fusion.
b. Grouping
Le regroupement est un processus de collecte de données dans différentes catégories. Par exemple, dans l’exemple ci-dessous, le champ « Employee_Name » a le nom « Meera » deux fois. Regroupons-le donc par la colonne « Employee_name ».
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
Le champ ‘Employee_name’ ayant pour valeur ‘Meera’ est regroupé par la colonne « Employee_name ». La sortie d’exemple est comme suit : Sortie: 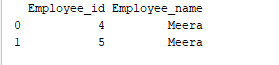
c. Concatenating
Concaténer des données implique d’ajouter un ensemble de données à un autre. Pandas fournit une fonction appelée concat() pour concaténer les DataFrames. Par exemple, concaténons les DataFrames df1 et df2 en utilisant :
print(pd.concat([df1, df2]))
Sortie : 
Créer un DataFrame en passant un dictionnaire de Séries
Pour créer une Série, nous pouvons utiliser la méthode pd.Series() et lui passer un tableau. Créons une Série simple comme suit :
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)
Sortie :  Nous avons créé une Série. Vous pouvez voir que 2 colonnes sont affichées. La première colonne contient les valeurs d’index à partir de 0. La deuxième colonne contient les éléments passés en tant que série. Il est possible de créer un DataFrame en passant un dictionnaire de `Series`. Créons un DataFrame formé en unissant et en passant les index des séries. Exemple
Nous avons créé une Série. Vous pouvez voir que 2 colonnes sont affichées. La première colonne contient les valeurs d’index à partir de 0. La deuxième colonne contient les éléments passés en tant que série. Il est possible de créer un DataFrame en passant un dictionnaire de `Series`. Créons un DataFrame formé en unissant et en passant les index des séries. Exemple
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
Sortie d’échantillon 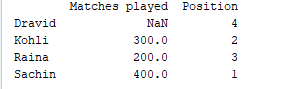 Pour la première série, comme nous n’avons pas spécifié l’étiquette ‘d’, NaN est retourné.
Pour la première série, comme nous n’avons pas spécifié l’étiquette ‘d’, NaN est retourné.
Sélection de colonnes, ajout, suppression
Il est possible de sélectionner une colonne spécifique du DataFrame. Par exemple, pour afficher uniquement la première colonne, nous pouvons réécrire le code ci-dessus comme suit:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
Le code ci-dessus n’imprime que la colonne « Matches played » du DataFrame. Sortie 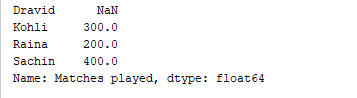 Il est également possible d’ajouter des colonnes à un DataFrame existant. Par exemple, le code ci-dessous ajoute une nouvelle colonne nommée « Runrate » au DataFrame ci-dessus.
Il est également possible d’ajouter des colonnes à un DataFrame existant. Par exemple, le code ci-dessous ajoute une nouvelle colonne nommée « Runrate » au DataFrame ci-dessus.
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
Sortie :  Nous pouvons supprimer des colonnes en utilisant les fonctions `delete` et `pop`. Par exemple, pour supprimer la colonne « Matches played » dans l’exemple ci-dessus, nous pouvons le faire de l’une des deux manières suivantes :
Nous pouvons supprimer des colonnes en utilisant les fonctions `delete` et `pop`. Par exemple, pour supprimer la colonne « Matches played » dans l’exemple ci-dessus, nous pouvons le faire de l’une des deux manières suivantes :
del df['Matches played']
ou
df.pop('Matches played')
Sortie : 
Conclusion
Dans ce tutoriel, nous avons eu une brève introduction à la bibliothèque Python Pandas. Nous avons également effectué des exemples pratiques pour libérer la puissance de la bibliothèque Pandas utilisée dans le domaine de la science des données. Nous avons également parcouru les différentes structures de données de la bibliothèque Python. Référence: Site Web officiel de Pandas
Source:
https://www.digitalocean.com/community/tutorials/python-pandas-module-tutorial