













Scikit Learn
 Scikit-learn是用于Python的机器学习库。它包含多种回归、分类和聚类算法,包括支持向量机(SVM)、梯度提升、k-means、随机森林和DBSCAN。它旨在与Python Numpy 和 SciPy 兼容。Scikit-learn项目最初由David Cournapeau作为scikits.learn的Google夏令营(也称为GSoC)项目启动。它的名字来自于“Scikit”,这是SciPy的一个独立第三方扩展。
Scikit-learn是用于Python的机器学习库。它包含多种回归、分类和聚类算法,包括支持向量机(SVM)、梯度提升、k-means、随机森林和DBSCAN。它旨在与Python Numpy 和 SciPy 兼容。Scikit-learn项目最初由David Cournapeau作为scikits.learn的Google夏令营(也称为GSoC)项目启动。它的名字来自于“Scikit”,这是SciPy的一个独立第三方扩展。
Python Scikit-learn
Scikit大部分是用Python编写的,其核心算法中的一些部分使用Cython编写以获得更好的性能。Scikit-learn用于构建模型,不推荐将其用于读取、操作和总结数据,因为有更好的框架可用于此目的。它是开源的,并在BSD许可下发布。
安装Scikit Learn
Scikit假设您的设备上已经运行Python 2.7或更高版本,并且安装了NumPY(1.8.2及以上)和SciPY(0.13.3及以上)包。一旦安装了这些包,我们就可以继续安装。对于pip安装,请在终端中运行以下命令:
pip install scikit-learn
如果您喜欢conda,您也可以使用conda进行包安装,运行以下命令:
conda install scikit-learn
使用Scikit-Learn
安装完成后,您可以通过将其导入为以下方式轻松在Python代码中使用scikit-learn:
import sklearn
加载Scikit Learn数据集
让我们从加载一个数据集开始。让我们加载一个名为Iris的简单数据集。这是一个关于花的数据集,包含150个关于花的不同测量的观察值。让我们看看如何使用scikit-learn加载数据集。
# 导入 scikit learn
from sklearn import datasets
# 载入数据
iris= datasets.load_iris()
# 打印数据形状以确认数据已加载
print(iris.data.shape)
为了方便起见,我们打印出数据的形状,如果您愿意,也可以打印整个数据集,运行代码会得到以下输出: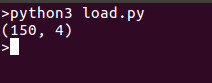
Scikit Learn 支持向量机 – 学习和预测
现在我们已经加载了数据,让我们尝试从中学习并在新数据上进行预测。为此,我们必须创建一个估算器,然后调用其 fit 方法。
from sklearn import svm
from sklearn import datasets
# 载入数据集
iris = datasets.load_iris()
clf = svm.LinearSVC()
# 从数据中学习
clf.fit(iris.data, iris.target)
# 对未见过的数据进行预测
clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
# 可以通过使用下划线结尾的属性更改模型的参数
print(clf.coef_ )
运行此脚本时,我们得到以下结果: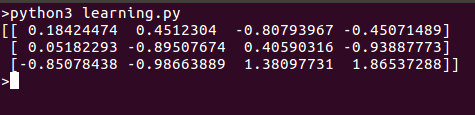
Scikit Learn 线性回归
使用 scikit-learn 创建各种模型相当简单。让我们从一个回归的简单示例开始。
#import模型
from sklearn import linear_model
reg = linear_model.LinearRegression()
# 使用它来拟合数据
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
让我们来看看拟合的数据
print(reg.coef_)
运行模型应该返回一个可以在同一条线上绘制的点: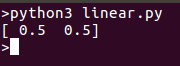
k-Nearest neighbour classifier
让我们尝试一个简单的分类算法。这个分类器使用基于球树的算法来表示训练样本。
from sklearn import datasets
# 加载数据集
iris = datasets.load_iris()
# 创建并拟合最近邻分类器
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target)
# 预测并打印结果
result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(result)
让我们运行分类器并检查结果,分类器应该返回0。让我们尝试一下例子:
K-means clustering
这是最简单的聚类算法。集合被分为’k’个簇,每个观察值被分配到一个簇。这是通过迭代地执行直到簇收敛来完成的。我们将在以下程序中创建一个这样的聚类模型:
from sklearn import cluster, datasets
# 加载数据
iris = datasets.load_iris()
# 为k=3创建簇
k=3
k_means = cluster.KMeans(k)
# 拟合数据
k_means.fit(iris.data)
# 打印结果
print( k_means.labels_[::10])
print( iris.target[::10])
运行程序后,我们将在列表中看到分离的簇。以下是上述代码片段的输出: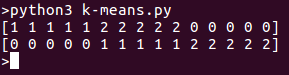
结论
在这个教程中,我们已经看到Scikit-Learn使得使用多个机器学习算法变得很容易。我们已经看到了回归、分类和聚类的示例。Scikit-Learn仍处于开发阶段,由志愿者开发和维护,但在社区中非常受欢迎。去尝试一下你自己的示例吧。
Source:
https://www.digitalocean.com/community/tutorials/python-scikit-learn-tutorial