













Введение
В этой статье мы создадим одну из первых сверточных нейронных сетей (LeNet5). Мы строим эту CNN с нуля в PyTorch и также проверим, как она работает с реальными данными.
Мы начнем с исследования архитектуры LeNet5. Затем мы загрузим и анализируем нашу базу данных MNIST, используя предоставленный класс из модуля torchvision. Utilizing PyTorch, мы строим нашу LeNet5 с нуля и обучаем ее на наших данных. Наконец, мы увидим, как модель выполняет свои функции на не известных тестовых данных.
Преrequisites
Знания о нейронных сетях будут полезны для понимания этой статьи. Это означает, что нужно быть знакомыми с различными слоями нейронных сетей (input layer, hidden layers, output layer), активационными функциями, оптимизационными алгоритмами (вариантами градиентного спуска), функциями потерь и т. д. Кроме того, знание синтаксиса Python и библиотеки PyTorch является необходимым для понимания приведенных в статье выдержек кода.
Произведение, которое представлено ниже, является результатом работы Google Translate, и может содержать ошибки.
Понимание сетей сверточных нейронных (CNN) также рекомендуется. Это включает знание сверточных层次, пуллинговых层次 и их роли в извлечении признаков из входных данных. Понимание таких концепций, как сдвиг, дополнение и влияние размера ядра/фильтра, полезно.
LeNet5
LeNet5 использовался для распознавания рукописных символов и был предложен Yann LeCun и другими в 1998 году в статье “Gradient-Based Learning Applied to Document Recognition”.Gradient-Based Learning Applied to Document Recognition
Давайте посмотрим на архитектуру LeNet5, изображенную на рисунке ниже:
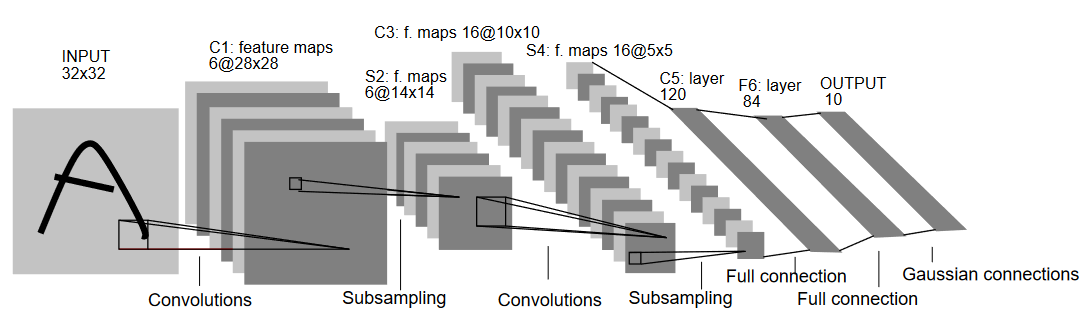
Как указывает название, LeNet5 имеет 5层次, включая два сверточных层次 и три полносвязанных层次. Начнем с входных данных. LeNet5 принимает входной градационный снимок 32×32, что указывает, что архитектура не подходит для изображений RGB (множество каналов). Таким образом, входное изображение должно содержать только один канал. После этого мы начинаем с наших сверточных层次
Первое сверточное层次 имеет размерность фильтра 5×5 с 6 такими фильтрами. Это уменьшит размер изображения, увеличив глубину (число каналов). Выход будет 28x28x6. После этого применяется пуллинговая операция, уменьшая карты признаков вдвое, т.е., 14x14x6. Те же фильтры (5×5) с 16 фильтрами применяются сейчас к выходу, затем следует пуллинговая层次. Это уменьшает выходную карту признаков до 5x5x16.
После этого применяется слой конвалюции размером 5×5 с 120 фильтрами, который размягчет feature map до 120 значений. Затем идет первый слой полной связи с 84 нейронами. В конце находится выходной слой с 10 нейронами, так как данные MNIST имеют 10 классов для каждого из представленных 10 цифр.
Загрузка данных
Начнем с загрузки и анализа данных. Мы будем использовать набор данных MNIST. Данный набор содержит изображения рукописных цифр. Изображения являются градациями серого цвета, все с размером 28×28, и состоит из 60,000 изображений для тренировки и 10,000 для теста.
Вы можете увидеть некоторые образцы изображений ниже:

Импорт библиотек
Начнем с импорта необходимых библиотек и определения некоторых переменных (гиперпараметры и device также детально описываются, чтобы помочь пакету определить, следует ли тренироваться на GPU или CPU):
# Загрузите соответствующие библиотеки и алиас, где это оправдано
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# Определите соответствующие переменные для машинного обучения
batch_size = 64
num_classes = 10
learning_rate = 0.001
num_epochs = 10
# Device определит, следует ли проводить тренировку на GPU или CPU.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Загрузка и трансформация данных
Используя torchvision, мы загрузим набор данных, чтобы упростить выполнение любых вспомогательных операций по предварительной обработке.
#Загрузка набора данных и предварительная обработка
train_dataset = torchvision.datasets.MNIST(root = './data',
train = True,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1307,), std = (0.3081,))]),
download = True)
test_dataset = torchvision.datasets.MNIST(root = './data',
train = False,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1325,), std = (0.3105,))]),
download=True)
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = True)
Посмотрим на пример кода:
- Для начала, данные MNIST нельзя использовать в качестве исходных для архитектуры LeNet5. Архитектура LeNet5 требует, чтобы входной импульс был 32×32, а изображения MNIST размером 28×28. Мы можем修正 это, увеличивая размер изображений, нормализуя их с помощью предварительно вычисленного среднего и стандартного отклонения (доступных онлайн) и, наконец, сохраняя их в виде тензоров.
- Мы устанавливаем
download=True, чтобы данные были загружены, если они еще не загружены. - Далее мы используем д loaders. Возможно, это не скажется на производительности для небольших наборов данных, таких как MNIST, но оно сильно ограничивает производительность для больших наборов данных и обычно считается хорошей практикой. Loaders позволяют нам итерировать по данным в блоках, и данные загружаются во время итерации, а не сразу при запуске.
- Мы указываем размерность блока и перемешиваем набор данных при загрузке, чтобы каждый блок имел некоторую вариацию в типах метки. Это улучшит эффективность нашей будущей модели.
LeNet5 с нуля
Первоначально посмотрим на код:
#Определение конволюционной нейронной сети
class LeNet5(nn.Module):
def __init__(self, num_classes):
super(ConvNeuralNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.fc = nn.Linear(400, 120)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(120, 84)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
out = self.relu(out)
out = self.fc1(out)
out = self.relu1(out)
out = self.fc2(out)
return out
Определение модели LeNet5
Я объясню код线性но:
- В PyTorch мы определяем нейронную сеть, создавая класс, наследующийся от
nn.Module, так как он содержит много методов, которые нам понадобятся для использования. - Далее идут два основных шага. Первый – инициализация слоев, которые мы будем использовать в нашем CNN, внутри
__init__, а второй – определение последовательности, в которой эти слои будут обрабатывать изображение. Это определено внутри функцииforward. - Что касается самой архитектуры, мы сначала определяем конволюционные слои, используя функцию
nn.Conv2Dс соответствующим размером ядра и каналами ввода/вывода. Мы также применяем максимальное охватывание с помощью функцииnn.MaxPool2D. Одной из хороших особенностей PyTorch является возможность объединять конволюционный слой, активационную функцию и максимальное охватывание в один единый слой (они будут отдельно применены, но это помогает с организацией) с помощью функцииnn.Sequential. - Теперь мы определим полностью связанные слои. Обратите внимание, что здесь мы могли бы использовать и
nn.Sequential, сочетая активационные функции и линейные слои, но я хотел показать, что один из двух вариантов возможен. - Конечно, наш последний слой выдает 10 нейронов, которые являются нашими окончательными предсказаниями для цифр.
Настройка гиперпараметров
Перед обучением нам нужно установить несколько гиперпараметров, таких как функция потерь и оптимизатор, который будет использоваться.
model = LeNet5(num_classes).to(device)
#Установка функции потерь
cost = nn.CrossEntropyLoss()
#Установка оптимизатора с параметрами модели и скоростью обучения
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#это определено для печати остальных шагов во время обучения
total_step = len(train_loader)
Мы начинаем с инициализации нашей модели используя количество классов в качестве аргумента, который в нашем случае равен 10. Затем мы определяем нашу функцию ошибки как потерю с учетом entropy и оптимизатор как Adam. Есть много вариантов для них, но эти, как правило, дают хорошие результаты с моделью и данными. Наконец, мы определяем total_step, чтобы лучше отслеживать шаги во время обучения.
Обучение модели
Теперь мы можем начать обучение модели:
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
#Проход вперед
outputs = model(images)
loss = cost(outputs, labels)
#Обратноеpropagation и оптимизация
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 400 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
Давайте посмотрим, что делает этот код:
- Мы начинаем с итерации по числу эпох, а затем по batch-ам в нашей тренировочной данных.
- Мы конвертируем изображения и метки согласно устройству, которое мы используем, то есть GPU или CPU.
- В качестве итерации вперед мы делаем предсказания с помощью нашей модели иcalculaем потерю на основе этих предсказаний и наших настоящих метк.
- Далее мы делаем обратный проход, где мы на самом деле обновляем наши веса для улучшения модели
- Далее мы устанавливаем градиенты в нуль перед каждым обновлением с использованием функции
optimizer.zero_grad(). - После этого мы вычисляем новые градиенты с помощью функции
loss.backward(). - И, наконец, мы обновляем веса с помощью функции
optimizer.step().
Мы можем видеть вывод следующим образом:
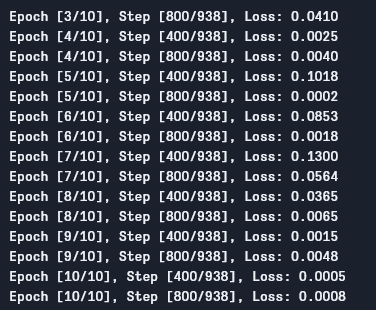
Как мы можем видеть, потеря уменьшается с каждой эпохой, что показывает, что наша модель действительно учится. Заметим, что эта потеря на тренировочной выборке, и если потеря слишком мала (как в нашем случае), это может указывать на переобучение. Есть много способов решения этой проблемы, таких как регуляризация, data augmentation и так далее, но мы не будем касаться этого в этой статье. Теперь давайте проверим нашу модель, чтобы увидеть, как она работает.
Тестирование модели
Теперь мы тестируем нашу модель:
# Тестирование модели
# В тестовом режиме нам не требуется вычислять градиенты ( для эффективности памяти )
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
Как вы можете видеть, код не сильно отличается от того, который использовался для обучения. единственное различие состоит в том, что мы не вычисляем градиенты ( используя with torch.no_grad() ), а также не вычисляем потерю, поскольку здесь нам не требуется реализовать обратное проPropagation. Чтобы вычислить окончательную точность модели, мы можем просто вычислить общее количество правильных предсказаний по отношению к общему количеству изображений.
Используя эту модель, мы получаем около 98,8% точности, что довольно хорошо:

Точность теста
Обратите внимание, что набор данных MNIST довольно прост и маленьк в сравнении с современными стандартами, и подобные результаты трудно получить для других наборов данных. Тем не менее, это хороший starting point для изучения глубокого обучения и CNNs.
Заключение
Теперь let’s结東 на что мы делали в этой статье:
- Мы начали с изучения архитектуры LeNet5 и различных типов слоев в нем.
- Далее мы исследовали набор данных MNIST и загрузили данные с использованием
torchvision. - Потом мы построили LeNet5 с нуля, а также определили гиперпараметры модели.
- В конечном итоге наша модель была тренирована и тестирована на наборе данных MNIST, и, кажется, она справилась хорошо с испытанием на наборе данных теста.
Будущая работа
хотя это кажется хорошим введением в глубинное обучение с использованием PyTorch, вы можете расширить эту работу, чтобы leaned more:
- Вы можете essay using different datasets, but for this model you will need gray scale datasets. One such dataset is FashionMNIST.
- You can experiment with different hyperparameters and see the best combination of them for the model.
- Finally, you can try adding or removing layers from the dataset to see their impact on the capability of the model.
Source:
https://www.digitalocean.com/community/tutorials/writing-lenet5-from-scratch-in-python