













紹介
この記事では、最早に提唱されたConvolutional Neural Network(CNN)の1つ、(LeNet5)を構築します。私たちはPyTorchでこのCNNを最初から作成し、また、実際のデータセットでの性能を見ます。
まず、LeNet5のアーキテクチャを調査します。そして、MNISTというデータセットを提供されたtorchvisionのクラスを使用して読み込みと分析を行います。PyTorchを使用して、LeNet5を最初から作成し、データに訓練します。最後に、未見のテストデータでモデルの性能を確認します。
前提知識
この記事を理解するためには、神経망の知識が必要です。これは、神経망の異なる層(入力層、隠れ層、出力層)、激活関数、最適化アルゴリズム(勾配下降の変体)、損失関数などを熟悉していることを意味します。また、PythonのスyntaxとPyTorchライブラリの熟悉が、この記事で示されるコードスニップで理解するために欠かせません。
CNNの理解が推奨されます。これには、畳み込み層、プーリング層、そして入力データから特徴を抽出する役割についての知識が含まれます。ストライド、パディング、カーネル/フィルターサイズの影響についての概念を理解することが有益です。
LeNet5
LeNet5は手書き文字の認識に使用され、1998年にYann LeCunらが論文「Gradient-Based Learning Applied to Document Recognition」で提案しました。
以下の図に示されるように、LeNet5のアーキテクチャを理解しましょう:
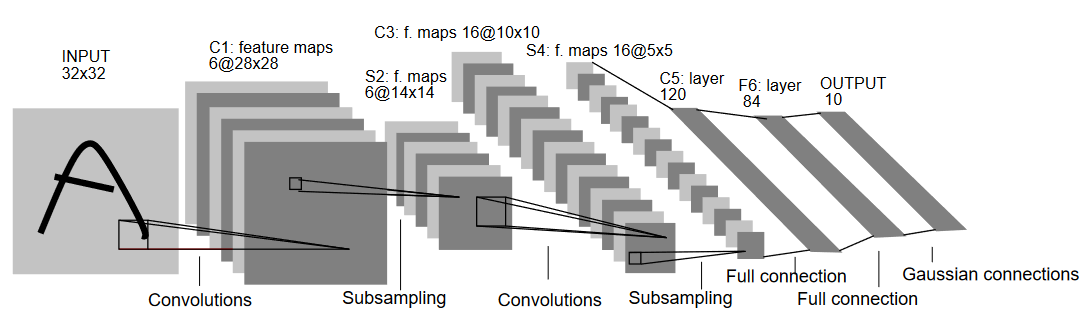
名前が示すように、LeNet5は5層で、2層の畳み込み層と3層の完全に接続された層を持っています。入力から始めましょう。LeNet5は32×32のグレースケール画像を入力として受け取ります。これはアーキテクチャがRGB画像(複数のチャンネル)には適していないことを示しています。したがって、入力画像は1つのチャンネルだけを含む必要があります。これから、畳み込み層で始めます。
最初の畳み込み層は5×5のフィルターサイズを持ち、6つのそのようなフィルターがあります。これにより、画像の幅と高さが縮小される一方、深さ(チャンネル数)が増加します。出力は28x28x6です。これに続いて、プーリングが適用され、特徴マップが半分に縮小されます。つまり、14x14x6です。次に、5×5の同じフィルターサイズを持つ16個のフィルターが適用され、プーリング層が続きます。これにより、出力特徴マップが5x5x16に縮小されます。
これに後続的に、5×5の畳み込み層を適用し、特徴マップを120個の値に平坦化します。その後、最初の全結合層が来て、84のニューロンがあります。最後に、MNISTデータは10の数字に対応する10のクラスがあるので、出力層は10のニューロンしかない出力層があります。
データ読み込み
データの読み込みと分析を始めましょう。私たちはMNISTデータセットを使用します。MNISTデータセットには、手書きの数字画像が含まれています。画像はグレースケールで、すべての画像のサイズは28×28で、60,000のトレーニング画像と10,000のテスト画像で構成されています。
以下に画像のいくつかのサンプルが表示されます:

ライブラリの導入
まず、必要なライブラリを導入し、いくつかの変数(超 Parameters とdevice)を定義しましょう。これらは、パッケージがGPUまたはCPUでトレーニングを行うか否かを決定するのを助けるために詳細に指定されています。
# 必要なライブラリを読み込み、適切に別名を設定する
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# MLの課題に関連した変数を定義する
batch_size = 64
num_classes = 10
learning_rate = 0.001
num_epochs = 10
# Deviceは、トレーニングをGPUまたはCPUで行うか決定するdevice。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
データの読み込みと変換
torchvisionを使用してデータセットを読み込みます。これにより、前処理のステップを簡単に実行することができます。
#データセットの読み込みと前処理
train_dataset = torchvision.datasets.MNIST(root = './data',
train = True,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1307,), std = (0.3081,))]),
download = True)
test_dataset = torchvision.datasets.MNIST(root = './data',
train = False,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1325,), std = (0.3105,))]),
download=True)
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = True)
コードを理解しましょう。
- 最初に、MNISTデータはLeNet5アーキテクチャに直接使用できません。LeNet5アーキテクチャは32×32の入力を受け取りますが、MNIST画像は28×28です。画像をリサイズし、事前に計算された平均と標準偏差(オンラインで利用可能)を使用して正規化し、最後にテンソルとして保存することでこれを修正することができます。
download=Trueを設定しており、データがまだダウンロードされていない場合にダウンロードします。- 次に、データローダーを使用します。MNISTのような小さいデータセットの場合はパフォーマンスに影響しないかもしれませんが、大きなデータセットの場合にパフォーマンスが劣化する可能性があり、一般的には良い習慣とされています。データローダーを使用することで、バッチごとにデータを反復処理することができ、データは一度に全て読み込まず、反復処理中に読み込まれます。
- バッチサイズを指定し、読み込み時にデータセットをシャッフルします。これにより、各バッチに異なるタイプのラベルが含まれるようになり、最終的なモデルの効率性が向上します。
LeNet5を从头から
まず、コードを見てみましょう。
#畳み込み神经网路の定義
class LeNet5(nn.Module):
def __init__(self, num_classes):
super(ConvNeuralNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.fc = nn.Linear(400, 120)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(120, 84)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
out = self.relu(out)
out = self.fc1(out)
out = self.relu1(out)
out = self.fc2(out)
return out
LeNet5モデルの定義
コードを線形に説明します。
- PyTorchでは、
nn.Moduleから派生するクラスを作成することで、多くの必要なメソッドを含んだ神经网路を定義します。 - その後、主に2つの手順があります。第1は、
__init__内で使用する CNNのレイヤーを初期化すること、第2は、それらのレイヤーが画像を処理する順序をforward関数内で定義することです。 - アーキテクチャ自体においては、適切な核サイズと入力/出力チャンネルを使用して
nn.Conv2D関数を用いて畳み込み層を第1に定義し、nn.MaxPool2D関数を使用して最大プーリングを適用します。PyTorchの利点は、畳み込み層、激活関数、及び最大プーリングを1つの単一の層に結合することができることです(これらは個別に適用されますが、組織化に役立ちます)。これはnn.Sequential関数を使用して行います。 - 最後に、私は完全に接続された層を定義します。ここでは、
nn.Sequentialを使用して、活性化関数と線形層を結合することができますが、それぞれに可能なことを示すために、私はそれぞれに可能であることを示しています。 - 最後の層は10の神経細胞を出力し、これは数字の最終的な予測です。
超 Parameter 設定
学習前に、損失関数や使用する最適化器などのいくつかの超 Parameter を設定する必要があります。
model = LeNet5(num_classes).to(device)
#損失関数の設定
cost = nn.CrossEntropyLoss()
#最適化器をモデルパラメータと学習率として設定
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#これは学習中に残りのステップ数を表示するために定義されています
total_step = len(train_loader)
まず、クラス数を引数としてモデルを初期化します。これは、この場合は10です。次に、私は交叉エントロピー損失をコスト関数と、Adamを最適化器として定義します。これらには多くの選択肢がありますが、これらはモデルと与えられたデータで良い結果をもたらすことがあります。最後に、total_stepを定義して、学習中のステップをよりよく追跡することができます。
モデル学習
今、私たちはモデルを訓練することができます。
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
#前向きパス
outputs = model(images)
loss = cost(outputs, labels)
#後向きパスと最適化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 400 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
コードの動作を見てみましょう。
- エポック数とトレーニングデータ内のバッチを繰り返し処理します。
- 使用しているデバイス、つまりGPUまたはCPUに応じて画像とラベルを変換します。
- フォワードパスでは、モデルを使用して予測を行い、それらの予測と実際のラベルに基づいて損失を計算します。
- 次に、バックワードパスを行い、モデルを改善するために実際に重みを更新します。
- その後、
optimizer.zero_grad()関数を使用して、各更新前に勾配をゼロに設定します。 - 次に、
loss.backward()関数を使用して新しい勾配を計算します。 - そして最後に、
optimizer.step()関数で重みを更新します。
出力は次のように確認できます。
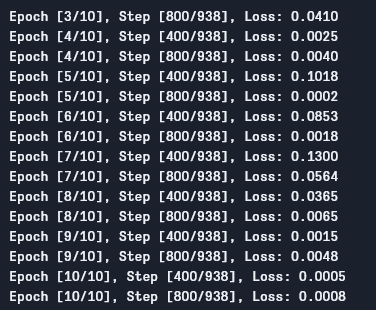
見ての通り、エポックごとに損失が減少しており、モデルが学習していることがわかります。この損失はトレーニングセット上のものであり、損失が非常に小さい場合(今回のケースではそうです)、過学習を示している可能性があります。この問題を解決するための方法は複数あり、正則化やデータ拡張などがありますが、この記事ではその詳細には触れません。それでは、モデルをテストしてパフォーマンスを確認しましょう。
モデルテスト
それでは、モデルをテストしてみましょう。
# モデルをテストします
# テスト段階では、勾配を計算する必要はありません(メモリ効率のため)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
ご覧のように、コードは学習用のものとはあまり異なりません。唯一の違いは、勾配を計算していません(with torch.no_grad()を使用して)。また、損失を計算する必要もないのは、ここでバックプロパゲーションする必要がないからです。モデルの結果の精度を計算するには、合計の画像数に対する正しい予測の数を計算するだけです。
このモデルを使用して、約98.8%の精度を得ますが、相当に良い結果です:

テスト精度
MNISTデータセットは、今日の標準に比べてとても基本的で小さいですから、他のデータセットにおいては相似の結果を得るのが困難です。しかしながら、深層学習とCNNを学ぶ際の良い出发点です。
結論
この記事で行ったことを現在までにまとめましょう:
- まず、LeNet5のアーキテクチャとその中に含まれる異なる種類の層について学びました。
- 次に、MNISTデータセットを探りましたし、
torchvisionを使用してデータを読み込みました。 - その後、LeNet5を从头から作成し、モデル用のハイパーパラメーターを定義しました。
- 最終的に、私たちはMNISTデータセットでモデルの学習とテストを行い、モデルがテストデータセットで良く機能しているようです。
将来的な研究
これはPyTorchで深層学習の素晴らしい入門と思われますが、この研究を引き続き拡張してより多く学ぶことができます:
- 異なるデータセットを試してみることができますが、このモデルにはグレースケールのデータセットが必要です。その1つはFashionMNISTです。
- 異なる超参数を試して、それらの最適な組み合わせをモデルに見つけることができます。
- 最終的に、データセットからレイヤーを追加または削除して、それらがモデルの機能に及ぼす影響を確認することができます。
Source:
https://www.digitalocean.com/community/tutorials/writing-lenet5-from-scratch-in-python