













简介
在本文中,我们将构建最早期的卷积神经网络之一,(LeNet5)。我们将使用PyTorch从头开始构建这个CNN,并将观察它在现实世界数据集上的表现。
我们首先探索LeNet5的架构。然后,我们将使用来自torchvision的提供的类加载和分析我们的数据集MNIST。使用PyTorch,我们将从头开始构建我们的LeNet5并在我们的数据上对其进行训练。最后,我们将看看模型在未见过的测试数据上的表现。
先决条件
了解神经网络将对理解本文有所帮助。这意味着熟悉神经网络的不同层(输入层、隐藏层、输出层)、激活函数、优化算法(梯度下降的各种变体)、损失函数等。此外,熟悉Python语法和PyTorch库对于理解本文中呈现的代码片段至关重要。
了解CNNs也是推荐的。这包括卷积层、池化层以及它们从输入数据中提取特征的作用。了解像步长、填充以及核/滤波器大小的影响这样的概念是有益的。
LeNet5
LeNet5用于手写字符的识别,是由Yann LeCun和其他人在1998年的论文《Gradient-Based Learning Applied to Document Recognition》中提出的。
让我们了解一下下图所示的LeNet5的架构:
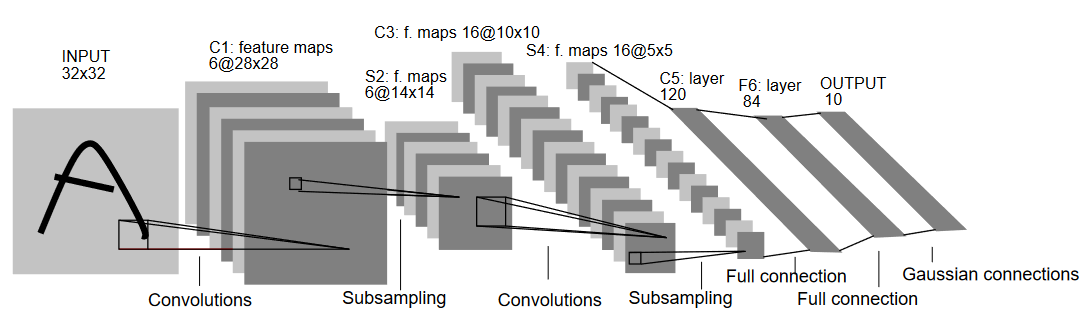
正如名称所示,LeNet5有5层,包括两个卷积层和三个全连接层。我们从输入开始。LeNet5接受32×32的灰度图像作为输入,这表明该架构不适用于RGB图像(多个通道)。所以输入图像应该只包含一个通道。之后,我们开始使用卷积层。
第一个卷积层有5×5的滤波器大小,配有6个这样的滤波器。这将减少图像的宽度和高度,同时增加深度(通道数)。输出将是28x28x6。在此之后,应用池化层以将特征图减少一半,即14x14x6。现在对输出应用相同滤波器大小(5×5)的16个滤波器,随后是一个池化层。这会将输出特征图减少到5x5x16。
此后,应用一个大小为5×5的卷积层,拥有120个过滤器,将特征图展平为120个值。然后是第一个全连接层,有84个神经元。最后,我们有一个输出层,有10个输出神经元,因为MNIST数据代表了10个数字,每个数字都有10个类别。
数据加载
让我们先加载并分析数据。我们将使用MNIST数据集。MNIST数据集包含手写数字的图像。这些图像都是灰度的,所有图像的大小都是28×28,由60,000个训练图像和10,000个测试图像组成。
您可以看到一些图像样本如下:

导入库
让我们先导入所需的库,并定义一些变量(超参数和device也详细说明,以帮助包确定是否在GPU或CPU上进行训练):
# 导入相关库,并适当别名
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# 为机器学习任务定义相关变量
batch_size = 64
num_classes = 10
learning_rate = 0.001
num_epochs = 10
# 设备将决定是否在GPU或CPU上运行训练。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
加载和转换数据
使用 torchvision,我们将加载数据集,因为它将允许我们轻松执行任何预处理步骤。
# 加载数据集和预处理
train_dataset = torchvision.datasets.MNIST(root = './data',
train = True,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1307,), std = (0.3081,))]),
download = True)
test_dataset = torchvision.datasets.MNIST(root = './data',
train = False,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1325,), std = (0.3105,))]),
download=True)
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = True)
让我们理解代码:
- 首先,原始的MNIST数据不能用于LeNet5架构。LeNet5架构接受的输入是32×32,而MNIST图像是28×28。我们可以通过调整图片大小、使用预计算的均值和标准差(网上可获得)进行归一化,最后将它们存储为张量来解决这个问题。
- 我们将
download=True设置为True,以防数据尚未下载。 - 接下来,我们使用数据加载器。对于像MNIST这样的小数据集,这可能不会影响性能,但在处理大数据集时,这可能会严重影响性能,通常被认为是一个好习惯。数据加载器允许我们以批量方式遍历数据,在迭代过程中加载数据,而不是一次性在开始时加载。
- 我们在加载时指定批量大小并打乱数据集,以便每个批次在标签类型上都有所不同。这将提高我们最终模型的效果。
从零开始实现LeNet5
我们首先来看一下代码:
#定义卷积神经网络
class LeNet5(nn.Module):
def __init__(self, num_classes):
super(ConvNeuralNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.fc = nn.Linear(400, 120)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(120, 84)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
out = self.relu(out)
out = self.fc1(out)
out = self.relu1(out)
out = self.fc2(out)
return out
定义LeNet5模型
我将线性解释一下代码:
- 在PyTorch中,我们通过创建一个继承自
nn.Module的类来定义一个神经网络,因为它包含了我们将要使用的许多方法。 - 那之后有两个主要步骤。第一个是在
__init__中初始化我们将在CNN中使用的层,另一个是定义这些层处理图像的顺序。这定义在forward函数中。 - 对于架构本身,我们首先使用
nn.Conv2D函数定义卷积层,并设置适当的核大小和输入/输出通道。我们还使用nn.MaxPool2D函数应用最大池化。PyTorch的一个好处是我们可以将卷积层、激活函数和最大池化组合成一个单一的层(它们将分别应用,但这有助于组织)使用nn.Sequential函数。 - 最后,我们定义了全连接层。请注意,我们在这里也可以使用
nn.Sequential,并将激活函数和线性层组合起来,但是我想展示这两种方法都是可行的。 - 最后,我们的最后一层输出10个神经元,这些是我们的数字预测的最终结果。
设置超参数
在训练之前,我们需要设置一些超参数,例如损失函数和要使用的优化器。
model = LeNet5(num_classes).to(device)
#设置损失函数
cost = nn.CrossEntropyLoss()
#设置带有模型参数和学习率的优化器
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#这定义了在训练时打印还剩下多少步
total_step = len(train_loader)
我们首先使用类数作为参数初始化我们的模型,这里的类数是10。然后我们将损失函数定义为交叉熵损失,优化器定义为Adam。对于这些参数,有很多选择,但这些通常在与模型和给定数据相结合时能给出良好的结果。最后,我们定义了total_step,以便在训练时更好地跟踪步骤。
模型训练
现在,我们可以开始训练我们的模型:
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
#前向传播
outputs = model(images)
loss = cost(outputs, labels)
#反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 400 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
以下是翻译结果:
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
我们来看看这段代码的作用:
- 我们首先遍历训练周期数,然后遍历我们训练数据中的每个批次。
- 我们根据所使用的设备(即GPU或CPU)转换图像和标签。
- 在正向传递过程中,我们使用模型进行预测,并基于这些预测和实际标签计算损失。
- 接下来,我们进行反向传递,实际上是通过更新权重来改善我们的模型。
- 然后,我们使用`optimizer.zero_grad()`函数在每次更新前将梯度设置为零。
- 接着,我们使用`loss.backward()`函数计算新的梯度。
- 最后,我们使用`optimizer.step()`函数更新权重。
我们可以看到如下输出:
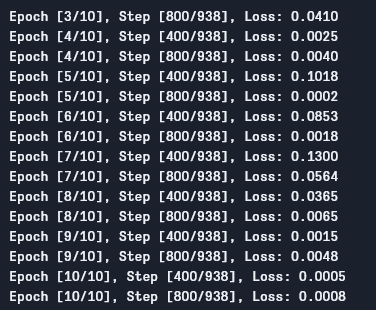
正如我们所见,每一次训练周期,损失都在下降,这表明我们的模型确实在学习。需要注意的是,这个损失是在训练集上计算的,如果损失太小(在我们这个案例中就是如此),这可能表明出现了过拟合问题。解决这个问题有多种方法,例如正则化、数据增强等,但本文不会深入探讨这些问题。现在让我们测试一下我们的模型,看看它的表现如何。
模型测试
现在让我们来测试一下我们的模型:
# 测试模型
# 在测试阶段,我们不需要计算梯度(出于内存效率考虑)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
正如你所看到的,代码与训练时的代码并没有太大区别。唯一不同的是,我们不在计算梯度(使用`with torch.no_grad()`),同时也不计算损失,因为我们这里不需要反向传播。为了计算模型的准确率,我们可以简单地计算模型正确预测的次数除以图像总次数。
使用这个模型,我们得到了大约98.8%的准确率,这是相当不错的:

测试准确率
请注意,MNIST数据集对于今天的标准来说相当基础且数据量小,对于其他数据集来说,获得类似的结果很难。尽管如此,这对于学习深度学习和卷积神经网络来说是一个不错的起点。
结论
现在让我们总结一下本文我们所做的事情:
- 我们首先学习了LeNet5的结构以及其中不同的层次。
- 接下来,我们探索了MNIST数据集并使用`torchvision`加载数据。
- 然后,我们从头开始构建LeNet5,并定义了模型的超参数。
- 最后,我们在MNIST数据集上训练并测试了我们的模型,模型在测试数据上表现得似乎很好。
未来工作
虽然这似乎是一个很好的PyTorch深度学习入门,但你可以将这项工作扩展以学习更多内容:
- 你可以尝试使用不同的数据集,但对于这个模型,你需要灰度数据集。这样一个数据集是FashionMNIST。
- 你可以尝试不同的超参数组合,并找出对模型最好的组合。
- 最后,你可以尝试从数据集中添加或删除层,以观察它们对模型能力的影响。
Source:
https://www.digitalocean.com/community/tutorials/writing-lenet5-from-scratch-in-python