













קדמה
במאמר זה, אנחנו נבנה אחד מהמערכות הקונוולציונליות הראשונות שהוצגו אי פעם, (LeNet5). אנחנו נבנה את ה CNN הזה מדגימה ב PyTorch, ונראה גם איך הוא מבין את המאגר המקורי הזה.
אנחנו נתחיל על מנת להביט במבנה של LeNet5. אחר כך, אנחנו נטען וננתח את המאגר שלנו, MNIST, בעזרת הקטגוריה הספקטרית המסוגלת מתוך torchvision. בעזרת PyTorch, אנחנו נבנה את ה LeNet5 הזה מדגימה ונאמן אותו על המידע שלנו. בסוף, נראה איך המודל מבין את המידע הבדיקה הלא נתון.
דרישות קדמות
ידע על מערכות קונוולציונליות יהיה מועיל בהבנה של המאמר הזה. זה אומר שצריך להיות מורגל לשכבות המערכות הקונוולציונליות (שכבה קבלה, שכבות חבילה, שכבה יוצאת), פונקציות הפעלה, אלגוריתמים העיסקה (סוגים של היפודרמיד גראד), פונקציות אובדן, ועוד. בנוסף, מורגלות לסYNTAX של ה Python ולספקטריה של PyTorch היא בעיקר חיונית עבור הבנה של קטעי קוד המציגים במאמר זה.
מומחית במונחים של CNNs מומחה בעל ידיעה על שכבות הרשת, שכבות הבצעת, והתפקידם בסיפור קלט ממוצע. הבנה על הערכים כמו ההתקדם, השמירה, וההשפעה של גודל המנעד/מסנן היא מועילה.
LeNet5
LeNet5 נעשה בשביל זיהוי תווי כתוביות ידניות ונועד על ידי יאן לקון ואחרים ב-1998 במאמר, Gradient-Based Learning Applied to Document Recognition.
בואו נבין את הארכיטקטורה של LeNet5 כפי שמראה בתמונה הבאה:
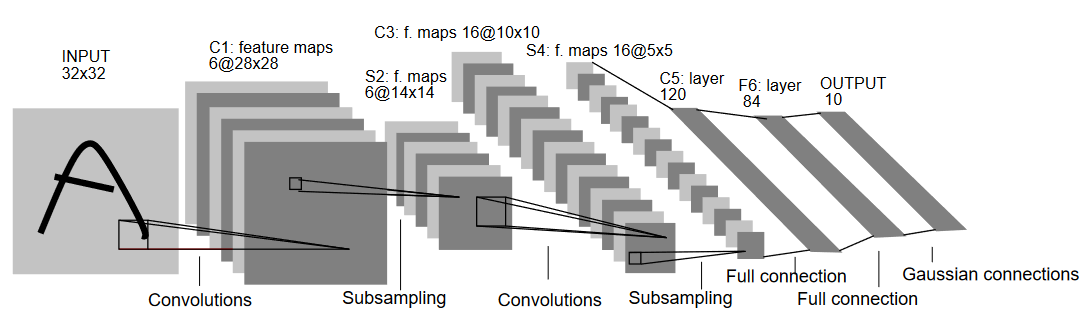
כפי שהשם אומר, LeNet5 מכיל 5 שכבות עם שתי שכבות קונבולציונליות ושלושה שכבות מחוברות באופן מלאי קישורים. בואו נתחיל עם הקלט. LeNet5 מקבל קלט בצורת תמונה אפורה של 32×32, שמרמז שהארכיטקטורה איננה מועדה לתמונות RGB (עוד ערוצים). כך שהתמונה הקלטת צריכה להכיל רק אחד ערץ. אחרי זה, אנחנו מתחילים עם השכבות הקונבולציונליות שלנו
השכבה הקונבולציונלית הראשונה מקבלת גודל מנעד 5×5 עם 6 מסננים אלה. זה יצמצם את הרוחב והגובה של התמונה בעוד שיגבירה את העומס (מספר הערוצים). התוצאה תהיה 28x28x6. אחרי זה, מיועדת השיטה לצמצום מפתחים בחצי, כלומר, 14x14x6. אותו גודל מנעד (5×5) עם 16 מסננים ניתן עכשיו להשתמש בתוצאה ובנוי עליו שכבה של צמצום. זה יצמצם את מפתח התוצאות ל5x5x1
אחרי זה, מיועד שימוש בשכבה קונבולציונלית בעלת גודל 5×5 עם 120 סינפסורים כדי להתמוטט את המפה של התכונות ל-120 ערכים. אחר כך מגיעה השכבה המקושרת לחלוטין הראשונה, עם 84 ניורונים. לבסוף יש את השכבה היוצאת, שיש בה 10 תאי יוצאים, בגלל שלמינIST יש 10 הפעמים לכל אחד מ-10 הספרות המיוצגות בתמונות.
טעינת מידע
בואו נתחיל בטעינת ואנליזה של המידע. אנחנו נהשתמש במאגר המידע MNIST. במאגר המידע MNIST יש תמונות של ספרות כתובות ביד. התמונות הן בצבעים אפלים, כולן בגודל 28×28, והוא מורכב מ-60,000 תמונות להכשרה ו-10,000 תמונות לבחינה.
ניתן לראות את חלק מהדגימות הבאות של התמונות למטה:

ייבאות הספרות
בואו נתחיל בייבאות הספרות הנדרשות והגדירה של חלק מהמשתנים (ההיפרפארמטרים והערך device נפוצים גם כדי לעזור לארגז להבין האם להאמץ את האימון על הGPU או הCPU):
# טעינת ספרות הדרושות, ואליאזים במקום המתאים
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# הגדירה של משתנים רלוונטיים למטרה המלאכותית
batch_size = 64
num_classes = 10
learning_rate = 0.001
num_epochs = 10
# המכשיר יבחינה האם לבצע את האימון על הGPU או הCPU.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
טעינת ומימוץ המידע
בשימוש ב torchvision , נטען את הנתונים בגלל שזה יאפשר לנו לבצע שלבים של עיבוד קדם בקלות.
#טעינת הנתונים ועיבוד קדם
train_dataset = torchvision.datasets.MNIST(root = './data',
train = True,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1307,), std = (0.3081,))]),
download = True)
test_dataset = torchvision.datasets.MNIST(root = './data',
train = False,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1325,), std = (0.3105,))]),
download=True)
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = True)
בואו נבין את הקוד:
- ראשית, הנתונים של MNIST לא יכולים להיות בשימוש במבנה LeNet5 במצב רגיל. המבנה LeNet5 מקבל קלט בגודל 32×32, בעוד התמונות של MNIST הן בגודל 28×28. אנחנו יכולים לתקן את זה על-ידי הגדלת התמונות, המידות שלהן באופן נורמלי בעזרת הממוצע והסטנדרטים הקדמונים שנמצאים ברשת (זמינים ברשת), ולבסוף אחסנים אותם בתנסורים.
- אנחנו מגדירים
download=Trueבמקרה שהנתונים עדיין לא נוטעו. - בהמשך, אנחנו משתמשים במאבקני נתונים. זה יכול לא להשפיע על הביצוע במקרה של נתונים קטנים כמו MNIST, אך הוא יכול באמת להשפיע על הביצוע במקרה של נתונים גדולים והוא בד "" כ נחשב למנהג טוב. מאבקנים הנתונים מאפשרים לנו להתבעבע בנתונים במבנים, והנתונים נטענים בזמן ההתבעבע ולא בזמן ההתחלה.
- אנחנו מספקים את הגודל המקבץ ומערבבים את הנתונים בזמן הטעינה כך שכל מקבץ יש סוג של התנגדות בסוגי התוויות שלו. זה יגביר את יעילות המודל הסוף שלנו.
LeNet5 מתחילים
בואו נסתכל קודה:
# הגדרה של רשת מוליכה מערך
class LeNet5(nn.Module):
def __init__(self, num_classes):
super(ConvNeuralNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.fc = nn.Linear(400, 120)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(120, 84)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
out = self.relu(out)
out = self.fc1(out)
out = self.relu1(out)
out = self.fc2(out)
return out
הגדרת מודל LeNet5
אני אסביר את הקוד בדרך לינארית:
- ב PyTorch, אנחנו מגדירים רשת מוליכה על ידי יצירת מבנה שיישר אחרי
nn.Moduleמפני שהוא מכיל הרבה של השיטות שאנחנו נזדקק להשתמש בהן. - יש שתי שלבים עיקריים אחרי זאת. הראשון הוא ההתחלה של השכבות שאנחנו נשתמש בהן ברשת ה CNN בתוך
__init__, והשני הוא להגדיר את הסדר בו השכבות האלה יעבדו את התמונה. זה מוגדר בתוך הפונקצייתforward. - עבור הארכיטקטורה עצמה, אנחנו מגדירים את השכבות המבניות בעזרת הפונקצייה
nn.Conv2Dעם הגודל המתאים של המנתח והערות הקלט/יוצאת. אנחנו גם יוצרים מייק פולינג בעזרת הפונקצייהnn.MaxPool2D. הדבר הנחמד על פי Torch הוא שאנחנו יכולים לשלב בתוך שכבה אחת את השכבה המבנית, תפקיד ההפעלה, והמייק פולינג, והם ייישמו באופן נפרד (הם יישמו באופן נפרד, אבל זה עוזר בארגון) בעזרת הפונקצייהnn.Sequential. - אז אנחנו מגדירים את השכבות המקרחות לחלוטין. שימו לב שאנחנו יכולים להשתמש ב
nn.Sequentialפה גם ולשלב את הפעלולים והשכבות הלינאריות, אבל רציתי להראות שגם אחד מהם אפשרי. - סוף סוף, השכבה האחרונה מייצרת 10 ניורונים שהם ההערכים הסופיים שלנו לספרות.
הגדרת הגיוסרמטרים
לפני ההכשרה, אנחנו צריכים להגדיר כמה גיוסרמטרים, כמו הפעלה והאופטימיzer שישתמשו.
model = LeNet5(num_classes).to(device)
#הגדרת הפעלה
cost = nn.CrossEntropyLoss()
#הגדרת האופטימיzer עם הפרמטרים של המודל וקצב הלמידה
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#זה מגדיר כדי להדפיס כמה צעדים נותרים בהכשרה
total_step = len(train_loader)
אנחנו מתחילים על ידי הגדרת המודל בעזרת מספר המחלוקות כאן שהוא 10. אחר כך אנחנו מגדירים את התמחות שלנו כפעלה מעברית ואופטימיzer כאדם. יש הרבה בחירות לאלה, אך הם נוטים לתת תוצאות טובות עם המודל והמידע הנתנים. לבסוף, אנחנו מגדירים total_step כדי לשמור טוב יותר על הצעדים בהכשרה.
הכשרת המודל
עכשיו, אנחנו יכולים להכשיר את המודל שלנו:
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
#העברה קדמית
outputs = model(images)
loss = cost(outputs, labels)
#חזרה אחורה והגדלה
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 400 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
פירוט(epoch+1, num_epochs, i+1, total_step, loss.item()))
בואו נראה מה הקוד עושה:
- אנו מתחילים עם היבטרציה במספר הפרקים, ואז בערכות הנתונים במאגר ההכשרה שלנו.
- אנו ממירים את התמונות והתוויות לפי המכשיר שאנו משתמשים בו, כלומר, GPU או CPU.
- בעברה הקדימה, אנו עושים הערכות עם המודל שלנו ומחשבים את האובדן בהתבסס על ההערכות הללו ועל התוויות האמיתיות שלנו.
- לאחר מכן, אנו מבצעים העברה האחורה שבה אנו למעשה מעדכנים את המשקלים כדי לשפר את המודל שלנו
- אנו אז מקבלים את השיפועים לאפס לפני כל עדכון באמצעות פעולת
optimizer.zero_grad(). - אחר כך, אנו מחשבים את השיפועים החדשים באמצעות הפעולה
loss.backward(). - ולבסוף, אנו מעדכן את המשקלים באמצעות הפעולה
optimizer.step().
ניתן לראות את הפלט כך:
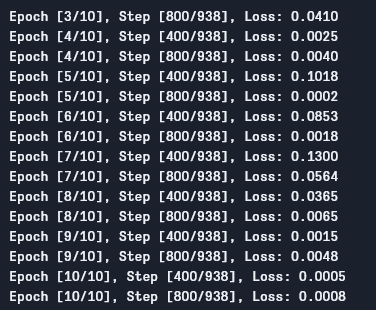
כפי שניתן לראות, האובדן יורד עם כל פרק, שמראה שהמודל שלנו באמת לומד. תשומת לב שזהו האובדן על המאגר ההכשרה, ואם האובדן קטן מדי (כפי שהוא במקרה שלנו), זה עשוי להצביע על עברה. ישנם דרכים רבות לפתור בעיה זו כמו הסדרה, העלאה של נתונים, וכו', אך לא נכנס במאמר זה. בואו נבדוק את המודל שלנו כדי לראות איך הוא מבצע.
בדיקת המודל
בואו נבדוק את המודל שלנו:
# בדיקת המודל
# בשלב הבדיקה, אנחנו לא צריכים לחשב גרידים (בגלל יעילות הזיכרון)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
כפי שאתם יכולים לראות, הקוד אינו שונה לגמרי מזה של האימון. ההבדל היחיד הוא שאנחנו לא מחשבים גרידים (בעזרת with torch.no_grad()), וגם לא מחשבים את האחריות מפני שאנחנו לא צריכים להפעיל חזרה חוט. כדי לחשב את הדיוק התוצאה של המודל, אנחנו יכולים פשוט לחשב את מספר ההערכים הנכונים מתוך מספר התמונות הכללי.
בעזרת המודל הזה, אנחנו מקבלים סבירות של כ-98.8% שזה די טוב:

סבירות בדיקה
שימו לב שתוך קטע מאד פשוט וקטן כמו מני斯特 קשה לקבל תוצאות דומות עבור קבצי נתונים אחרים. עדיין, זה נקודה טובה להתחיל בלמידת ה深度学习 וה CNNs.
סיכום
בואו נסיק על מה שעשינו במאמר הזה:
- התחלנו בלמידת המבנה של LeNet5 והמעטים השונים של השכבות בתוכו.
- בהמשך, חקרנו את קבצת המני斯特 והוטלטנו את הנתונים בעזרת
torchvision. - אחר כך, בנינו LeNet5 מן התחלה ביחד עם הגדרת ההיפרפרמטרים למודל.
- לבסוף, אנחנו אימנו ובדקנו את המודל שלנו על מידע קבוצת ה-MNIST, והמודל הזה היה מסוגל לבצע טוב על המידע הבדיקה.
עבודה עתידית
למרות שזו נראית כמו הקדמה מצוינת ללמידת עמוקה בPyTorch, אתה יכול להרחיב על העבודה הזו על מנת ללמד יותר:
- אתה יכול לנסות להשתמש במידע סטטוס אחרים, אך עבור המודל הזה תצטרך מידע סגול בעל צבעים אחדים. אחד מהמידע האלה הוא FashionMNIST.
- אתה יכול לבצע ניסויים עם הגדלים האחרים ולראות את השילוב הטוב ביותר שלהם עבור המודל.
- לבסוף, אתה יכול לנסות להוסיף או להסיר שכבות מהמידע כדי לראות את ההשפעה שלהם על יכולת המודל.
Source:
https://www.digitalocean.com/community/tutorials/writing-lenet5-from-scratch-in-python