













Машинное обучение (ML) хранилища функций привлекают внимание и использование для критически важных бизнес-приложений с тех пор, как Uber ввел концепцию с Michelangelo в 2017 году. В этом блоге мы погрузимся в основы хранилищ функций ML и исследуем, почему и как ScyllaDB может стать ключевой частью вашей архитектуры хранилища функций.
Чтобы понять, что такое хранилища функций, важно сначала понять, что такое features.
Что Такое Feature?
В машинном обучении, feature – это набор данных, который может быть использован для обучения модели и предсказания будущего на основе исторических данных. Например, наша пример приложения хранилища функций позволяет делать прогнозы о задержках полетов на основе исторических записей полетов.
Features являются результатом сложных процессов обработки и трансформации данных. Огромное количество данных функций позволяет делать точные прогнозы и успешно реализовывать проекты машинного обучения.
Что Такое Хранилище Функций?
A feature store is a central database in your machine-learning architecture that contains your real-time and historical features. Feature stores allow your data engineers and data scientists to use the same central repository to discover, monitor, and analyze features.
What does a feature store architecture look like?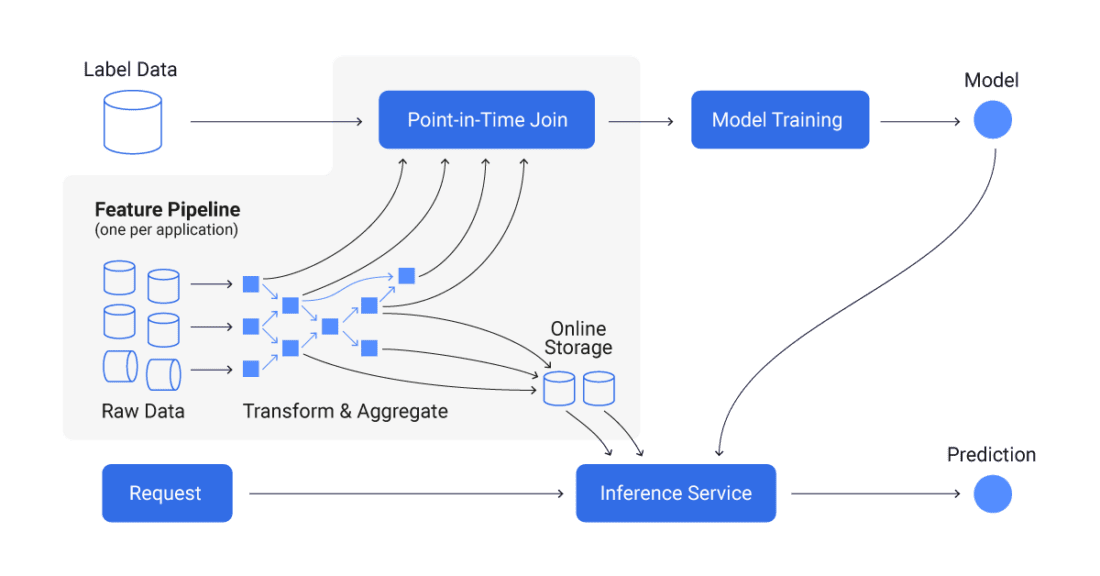
Онлайн и Оффлайн Базы Данных в Хранилище Функций
Говоря о хранилищах функций, пользователи обычно различают два вида баз данных в своей архитектуре. С одной стороны, они используют онлайн-базу данных, а с другой, они могут также иметь оффлайн-базу данных. Эти базы данных служат разным целям.
Офлайн-база данных: Такая база данных хранит исторически обработанные признаки, обычно загружаемые пакетами. Офлайн-базы данных содержат данные признаков, охватывающие большой временной интервал из истории, поэтому они полезны для работы с набором признаков в конкретный период истории.
Онлайн-база данных: Эта база данных может содержать данные из реальных потоков данных и офлайн-базы данных. Онлайн-хранилище используется для обслуживания производственной модели и других приложений в реальном времени с самыми актуальными данными признаков. В данном случае важны производительность и низкая задержка. Если ваша база данных не способна доставить реальные признаки достаточно быстро, то ваша модель может использовать устаревшие или неточные данные для прогнозирования.
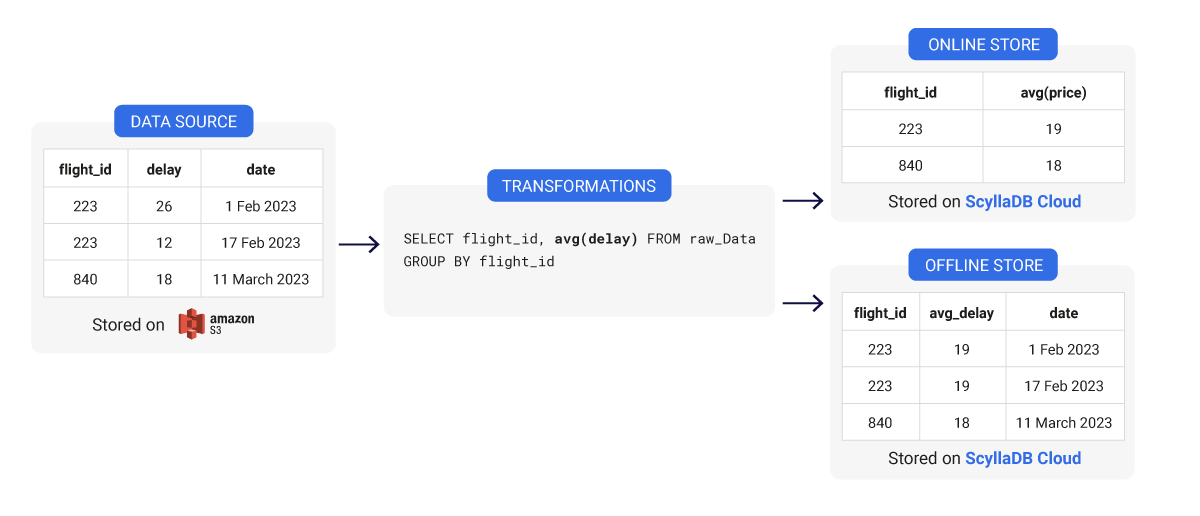
Моделирование данных хранилища признаков: Широкая vs. Узкая таблица
При проектировании модели данных в вашем хранилище признаков, будь то офлайн или онлайн, вы можете выбрать один из двух типов конструкций таблиц: широкую и узкую. Каждый из них имеет свои преимущества и недостатки. Давайте рассмотрим реальные примеры для обоих и почему они могут или не могут быть лучшим выбором для вашего случая:
Широкая таблица
Широкая таблица конструируется с отдельными столбцами для каждого признака. Чем больше типов признаков вы хотите хранить в таблице, тем больше столбцов вам придется создать.
Пример широкой таблицы
| create table feature_store.wide_example( | |
| date TIMESTAMP, | |
| feature_id INT, | |
| feature_col1 FLOAT, | |
| feature_col2 FLOAT, | |
| feature_col3 FLOAT, | |
| feature_col4 FLOAT, | |
| feature_col5 FLOAT, | |
| feature_col6 FLOAT, | |
| feature_col7 FLOAT | |
| ) |
Такой вид конструкции может быть прост в начале использования, но также становится более сложным в обслуживании с течением времени и трудно изменить. Всякий раз, когда вы хотите ввести новый признак (или удалить существующий), вам нужно будет изменить схему, что может быть сложно.
Узкая таблица
Проектирование узких таблиц проще и легче в обслуживании. Это связано с тем, что количество столбцов не предполагает увеличения или уменьшения в будущем, даже если добавляются или удаляются функции.
Пример узкой таблицы
| create table feature_store.narrow_example( | |
| feature_id INT, | |
| feature_name TEXT, | |
| feature_value FLOAT | |
| ) |
Используя такую структуру, можно обойтись всего двумя постоянными столбцами для хранения функций. Один для имени функции (например, LATE_AIRCRAFT_DELAY) и один для значения этой функции.
Как правило, узкие таблицы могут требовать приведения типов данных при извлечении, так как данные не находятся в правильной форме (например, тип столбца FLOAT, но на самом деле значение данных — INTEGER). К счастью, когда речь идет о хранилищах функций, онлайн и офлайн хранилища уже содержат данные в надлежащей, чистой форме (FLOAT), и все значения имеют одинаковый тип данных, что означает, что это не является недостатком в случае хранилищ функций.
Что такое ScyllaDB и как его можно использовать в архитектуре вашего хранилища функций?
Для того чтобы команды машинного обучения могли создавать приложения реального времени для вывода, им нужны базы данных, которые могут возвращать функции масштабируемо и с низкой задержкой. ScyllaDB — это высокопроизводительная, низкозатратная NoSQL-база данных, способная обрабатывать большие объемы операций чтения и записи. Кроме того, ScyllaDB является надежной базой данных для критически важных рабочих нагрузок хранилищ функций в таких компаниях, как GE Healthcare или ShareChat. Благодаря высокой доступности и устойчивости к сбоям, он может выполнять тяжелую работу в вашей инфраструктуре там, где важны производительность и надежность.
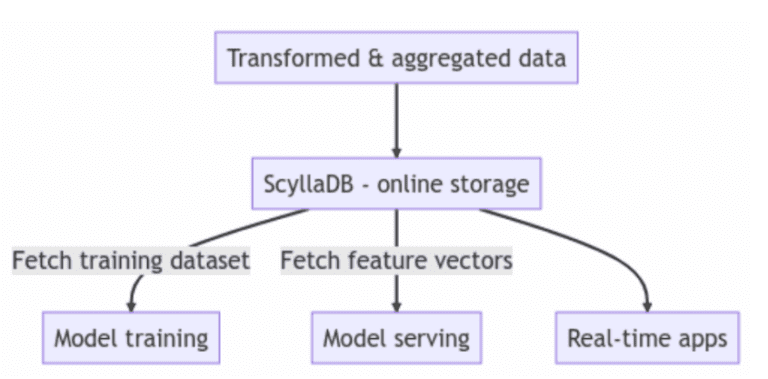
Помимо использования ScyllaDB в качестве онлайн-магазина в архитектуре вашего хранилища функций, ScyllaDB также применяется как гибридное решение для онлайн/офлайн хранения. С этим подходом вы можете уменьшить нагрузку на ваш команды, имея единую базу данных для обслуживания всех рабочих нагрузок вашего хранилища функций.
Пользователи часто размещают ScyllaDB в центре своей архитектуры для сохранения и извлечения функций и метаданных хранилища функций. В этом случае ScyllaDB выступает в качестве онлайн-магазина. Другие пользователи также используют ScyllaDB в качестве своего гибридного хранилища онлайн/офлайн. Производительность является ключевым требованием для ускорения разработки моделей, и производительность чтения и записи ScyllaDB постоянно соответствует или превышает ожидания пользователей.
На самом деле, некоторые пользователи обнаружили, что ScyllaDB может заменить несколько баз данных и служить единым центральным хранилищем для всех их потребностей в данных машинного обучения. Например, ScyllaDB может заменить Redis (онлайн-магазин) и PostgreSQL (офлайн-магазин) — делая обслуживание инфраструктуры менее дорогим и проще.
ScyllaDB выделяется в случаях, когда требуется низкая задержка и высокая производительность. Более того, ScyllaDB совместим с Cassandra и DynamoDB, что означает, если вы уже используете одну из этих баз данных, вы можете бесшовно перенестись, не меняя свои запросы.
Учебник: Онлайн-магазин ScyllaDB
Чтобы помочь вам начать работу с ScyllaDB в качестве вашего онлайн-магазина, мы создали пример приложения (также доступный на GitHub).
- Клонировать репозиторий
- Зарегистрироваться на ScyllaDB Cloud или установить ScyllaDB локально
- Создать схему:
cqlsh "node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud" 9042 -u scylla -p "password" -f schema.cql - Подключиться к экземпляру с помощью cqlsh и импортировать образец данных
cqlsh "node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud" 9042 -u scylla -p "password" scylla@cqlsh> COPY feature_store.flight_features FROM 'flight_features.csv';
Эта команда вводит образец данных о полете:
| op_carrier_fl_num|actual_elapsed_time|air_time|arr_delay|arr_time|cancellation_code|cancelled|carrier_delay|crs_arr_time|crs_dep_time|crs_elapsed_time|dep_delay|dep_time|dest|distance|diverted|fl_date |late_aircraft_delay|nas_delay|op_carrier|origin|security_delay|taxi_in|taxi_out|weather_delay|wheels_off|wheels_on| | |
| —————–+——————-+——–+———+——–+—————–+———+————-+————+————+—————-+———+——–+—-+——–+——–+——————-+——————-+———+———-+——+————–+——-+——–+————-+———-+———+ | |
| 4317| 96.0| 73.0| -19.0| 2113.0| | 0.0| | 2132| 2040| 112.0| -3.0| 2037.0|MLI | 373.0| 0.0|2018-12-31 02:00:00| | |OO |DTW | | 5.0| 18.0| | 2055.0| 2108.0| | |
| 3372| 94.0| 74.0| 81.0| 1500.0| | 0.0| 0.0| 1339| 1150| 109.0| 96.0| 1326.0|RNO | 564.0| 0.0|2018-12-31 02:00:00| 81.0| 0.0|OO |SEA | 0.0| 3.0| 17.0| 0.0| 1343.0| 1457.0| | |
| 1584| 385.0| 348.0| -21.0| 2023.0| | 0.0| | 2034| 1700| 394.0| -9.0| 1658.0|SFO | 2565.0| 0.0|2018-12-31 02:00:00| | |UA |EWR | | 13.0| 33.0| | 1731.0| 2019.0| | |
| 4830| 119.0| 85.0| -35.0| 1431.0| | 0.0| | 1437| 1245| 136.0| -13.0| 1232.0|MSP | 546.0| 0.0|2018-12-31 02:00:00| | |OO |MSP | | 16.0| 18.0| | 1250.0| 1415.0| | |
| 2731| 158.0| 146.0| -19.0| 1911.0| | 0.0| | 1930| 1800| 160.0| -8.0| 1800.0|MSP | 842.0| 0.0|2018-12-31 02:00:00| | |WN |PVD | | 7.0| 7.0| | 1807.0| 1904.0| |
view rawgistfile1.txt hosted with ❤ by GitHub.
ScyllaDB + Feast
ScyllaDB также интегрируется с инструментами хранилища функций, такими как Feast. Feast – популярное открытое хранилище функций для ML в производстве. Вы можете использовать несколько баз данных в качестве вашего онлайн-хранилища функций при использовании Feast, включая ScyllaDB.
Чтобы настроить ScyllaDB в качестве онлайн-хранилища Feast, вам нужно отредактировать файл конфигурации Feast и добавить учетные данные ScyllaDB. ScyllaDB совместим с Cassandra, поэтому вы можете использовать встроенный соединитель Cassandra от Feast.
| # feature_store.yaml | |
| project: scylla_feature_repo | |
| registry: data/registry.db | |
| provider: local | |
| online_store: | |
| type: cassandra | |
| hosts: | |
| – node-0.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-1.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-2.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| keyspace: feast | |
| username: scylla | |
| password: password |
view rawgistfile1.txt hosted with ❤ by GitHub.
Заключение
Хранилища функций необходимы для разработки функций и создания моделей машинного обучения. Если вы строите инфраструктуру реального времени для хранилища функций, вам нужно тщательно учитывать производительность. Требования к низкой задержке, высокой производительности и высокой пропускной способности делают NoSQL базы данных идеальным кандидатом в качестве решения для онлайн-хранения в вашем хранилище функций.
Source:
https://dzone.com/articles/tutorial-whats-an-aiml-feature-store-and-how-to-bu