













El almacenamiento de características de aprendizaje automático (ML) ha estado atrayendo atención y uso para aplicaciones críticas de negocios desde que Uber introdujo el concepto con Michelangelo en 2017. En esta publicación de blog, profundizaremos en los fundamentos de los almacenes de características de ML y exploraremos por qué y cómo ScyllaDB puede ser una parte crítica de la arquitectura de tu almacén de características.
Para entender qué son los almacenes de características, es importante primero comprender qué son las características.
¿Qué Es una Característica?
En el Aprendizaje Automático, una característica es un conjunto de puntos de datos que se pueden utilizar para enseñar un modelo y hacer predicciones sobre el futuro basadas en datos históricos. Por ejemplo, nuestra aplicación de ejemplo de almacén de características te permite hacer predicciones sobre retrasos en vuelos basadas en registros históricos de vuelos.
Las características son el resultado de complejos procesos de transformación y procesamiento de datos. Grandes cantidades de datos de características permiten predicciones precisas y proyectos de aprendizaje automático exitosos.
¿Qué Es un Almacén de Características?
A feature store is a central database in your machine-learning architecture that contains your real-time and historical features. Feature stores allow your data engineers and data scientists to use the same central repository to discover, monitor, and analyze features.
What does a feature store architecture look like?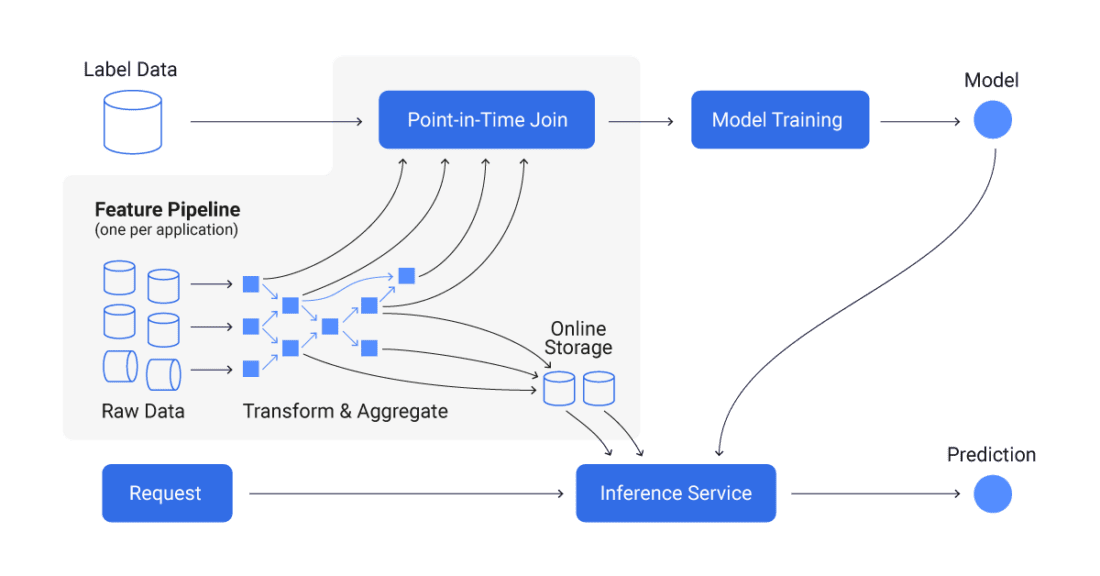
Bases de Datos en Línea y Fuera de Línea en el Almacén de Características
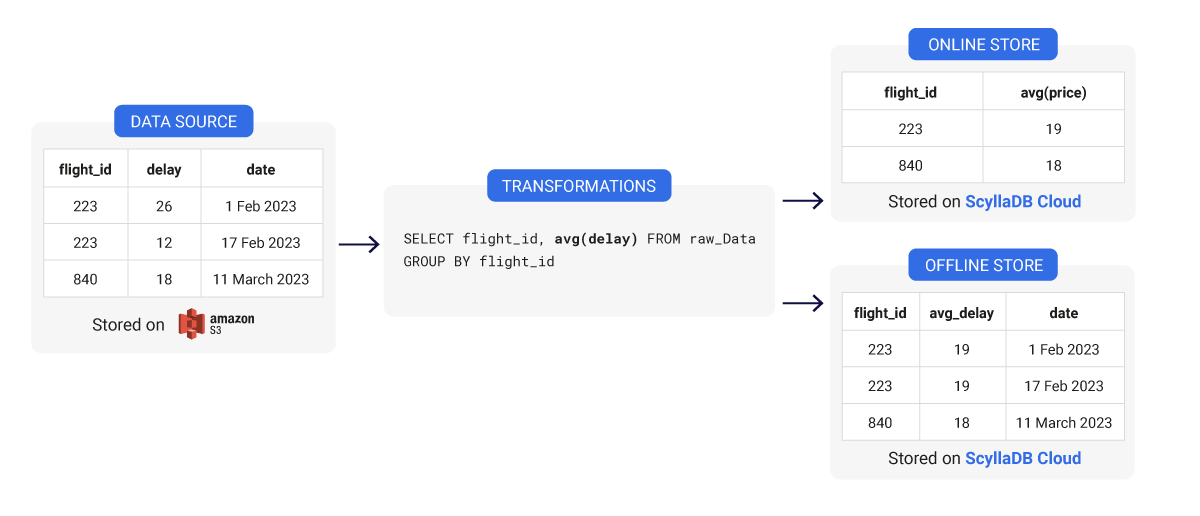
Cuando hablamos de almacenes de características, los usuarios suelen diferenciar entre dos tipos de bases de datos en su arquitectura. Por un lado, utilizan una base de datos en línea, y por otro, también pueden tener una base de datos fuera de línea. Estas bases de datos cumplen propósitos diferentes.
Base de datos fuera de línea: Este tipo de base de datos almacena características procesadas históricamente, generalmente ingeridas en lotes. Las bases de datos fuera de línea tienen datos de características que abarcan un gran período de tiempo desde el pasado; por lo tanto, son útiles para trabajar con un conjunto de características en un período específico en la historia.
Base de datos en línea: Esta base de datos puede contener datos de flujos de datos en tiempo real y la base de datos fuera de línea también. El almacenamiento en línea se utiliza para servir al modelo de producción y otras aplicaciones en tiempo real con los datos de características más actualizados. El rendimiento y la baja latencia son realmente importantes aquí. Si su base de datos no es capaz de entregar características en tiempo real lo suficientemente rápido, entonces su modelo podría utilizar datos obsoletos o inexactos para hacer predicciones.
Modelado de datos de Feature Store: Diseño de Tablas Anchas vs. Estrechas
Cuando está diseñando el modelo de datos dentro de su almacén de características, ya sea un almacén fuera de línea o en línea, puede decidir entre dos tipos de diseños de tablas: anchas y estrechas. Cada uno tiene sus propios beneficios y desventajas. Veamos ejemplos reales para ambos y por qué podrían o no ser los mejores para su caso de uso:
Diseño de Tabla Ancha
El diseño de tabla ancha incluye columnas separadas para cada característica. Cuantos más tipos de características desee almacenar en la tabla, más columnas tendrá que crear.
Ejemplo de Diseño de Tabla Ancha
| create table feature_store.wide_example( | |
| date TIMESTAMP, | |
| feature_id INT, | |
| feature_col1 FLOAT, | |
| feature_col2 FLOAT, | |
| feature_col3 FLOAT, | |
| feature_col4 FLOAT, | |
| feature_col5 FLOAT, | |
| feature_col6 FLOAT, | |
| feature_col7 FLOAT | |
| ) |
Este tipo de diseño puede ser fácil de comenzar, pero también se vuelve más complicado de mantener con el tiempo y difícil de cambiar. Cada vez que desee introducir una nueva característica (o eliminar una existente), deberá modificar el esquema, lo cual puede ser complicado.
Diseño de Tabla Estrecha
Los diseños de tablas estrechas son simples y fáciles de mantener. Esto se debe a que el número de columnas no está destinado a aumentar o disminuir en el futuro, incluso si agrega o elimina características.
Ejemplo de diseño de tabla estrecha
| create table feature_store.narrow_example( | |
| feature_id INT, | |
| feature_name TEXT, | |
| feature_value FLOAT | |
| ) |
Usando este diseño, puede prescindir de usar solo dos columnas fijas a largo plazo para almacenar características. Una para el nombre de la característica (por ejemplo, LATE_AIRCRAFT_DELAY) y otra para el valor de esa característica.
En general, las tablas estrechas pueden requerir la conversión de los tipos de datos al recuperar datos porque no están en la forma correcta (por ejemplo, el tipo de columna es FLOAT, pero en realidad, el valor de los datos es un INTEGER. Afortunadamente, cuando hablamos de tiendas de características, las tiendas en línea y fuera de línea ya tienen los datos en el formato limpio adecuado (FLOAT) y todos los valores tienen el mismo tipo de datos, lo que significa que esto no es una desventaja en el caso de las tiendas de características.
¿Qué es ScyllaDB y cómo se puede utilizar en la arquitectura de su almacén de características?
Para que los equipos de aprendizaje automático construyan aplicaciones de inferencia en tiempo real, necesitan bases de datos que puedan devolver características a escala con baja latencia. ScyllaDB es una base de datos NoSQL de alto rendimiento y baja latencia que puede manejar volúmenes elevados de operaciones de lectura y escritura. Además, ScyllaDB es una base de datos confiable para cargas de trabajo críticas de almacenes de características en empresas como GE Healthcare o ShareChat. Debido a su alta disponibilidad y tolerancia a fallos, puede hacer el trabajo pesado en su infraestructura donde el rendimiento y la confiabilidad importan.
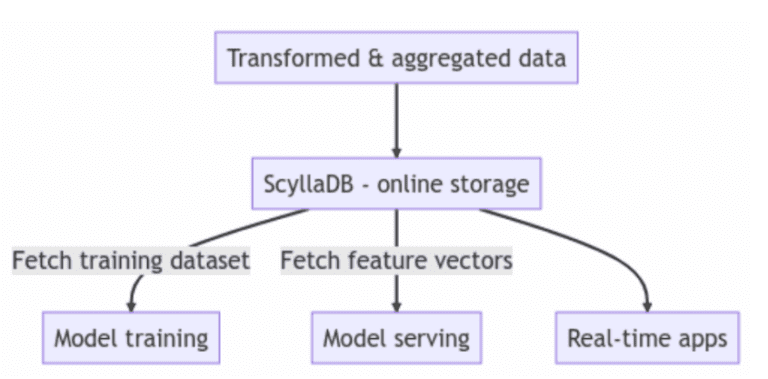
Además de aprovechar ScyllaDB como tienda en línea en su arquitectura de tienda de características, ScyllaDB también se utiliza como una solución de almacenamiento híbrido en línea/offline. Con este enfoque, puede reducir la carga de mantenimiento en su equipo al tener una sola base de datos para atender todos sus trabajos de la tienda de características.
A menudo, los usuarios colocan a ScyllaDB en el centro de su arquitectura para persistir y recuperar características y metadatos de la tienda de características. En este caso, ScyllaDB actúa como una tienda en línea. Otros usuarios también utilizan ScyllaDB como su almacenamiento híbrido en línea/offline. El rendimiento es un requisito clave para acelerar el desarrollo del modelo, y el rendimiento de lectura y escritura de ScyllaDB cumple o supera consistentemente las expectativas de los usuarios.
De hecho, algunos usuarios encontraron que ScyllaDB podría reemplazar múltiples bases de datos y servir como una sola tienda central para todas sus necesidades de datos de aprendizaje automático. Por ejemplo, ScyllaDB puede reemplazar a Redis (tienda en línea) y PostgreSQL (tienda offline) — haciendo que el mantenimiento de la infraestructura sea menos costoso y más simple.
ScyllaDB brilla en casos de uso donde requiere baja latencia y alto rendimiento. Además, ScyllaDB es compatible con Cassandra y DynamoDB, lo que significa que si ya utiliza una de estas bases de datos, puede migrar sin problemas sin tener que cambiar sus consultas.
Tutorial: Tienda en línea ScyllaDB
Para ayudarlo a comenzar con ScyllaDB como su tienda en línea, hemos creado una aplicación de muestra (también disponible en GitHub).
- Clonar el repositorio
- Registrarse en ScyllaDB Cloud o instalar ScyllaDB localmente
- Crear el esquema:
cqlsh “node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud” 9042 -u scylla -p “password” -f schema.cql - Conectar al instancia con cqlsh e importar un conjunto de datos de muestra
cqlsh “node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud” 9042 -u scylla -p “password” scylla@cqlsh> COPY feature_store.flight_features FROM ‘flight_features.csv’;
Este comando ingiere un conjunto de datos de vuelos de muestra:
| op_carrier_fl_num|actual_elapsed_time|air_time|arr_delay|arr_time|cancellation_code|cancelled|carrier_delay|crs_arr_time|crs_dep_time|crs_elapsed_time|dep_delay|dep_time|dest|distance|diverted|fl_date |late_aircraft_delay|nas_delay|op_carrier|origin|security_delay|taxi_in|taxi_out|weather_delay|wheels_off|wheels_on| | |
| —————–+——————-+——–+———+——–+—————–+———+————-+————+————+—————-+———+——–+—-+——–+——–+——————-+——————-+———+———-+——+————–+——-+——–+————-+———-+———+ | |
| 4317| 96.0| 73.0| -19.0| 2113.0| | 0.0| | 2132| 2040| 112.0| -3.0| 2037.0|MLI | 373.0| 0.0|2018-12-31 02:00:00| | |OO |DTW | | 5.0| 18.0| | 2055.0| 2108.0| | |
| 3372| 94.0| 74.0| 81.0| 1500.0| | 0.0| 0.0| 1339| 1150| 109.0| 96.0| 1326.0|RNO | 564.0| 0.0|2018-12-31 02:00:00| 81.0| 0.0|OO |SEA | 0.0| 3.0| 17.0| 0.0| 1343.0| 1457.0| | |
| 1584| 385.0| 348.0| -21.0| 2023.0| | 0.0| | 2034| 1700| 394.0| -9.0| 1658.0|SFO | 2565.0| 0.0|2018-12-31 02:00:00| | |UA |EWR | | 13.0| 33.0| | 1731.0| 2019.0| | |
| 4830| 119.0| 85.0| -35.0| 1431.0| | 0.0| | 1437| 1245| 136.0| -13.0| 1232.0|MSP | 546.0| 0.0|2018-12-31 02:00:00| | |OO |MSP | | 16.0| 18.0| | 1250.0| 1415.0| | |
| 2731| 158.0| 146.0| -19.0| 1911.0| | 0.0| | 1930| 1800| 160.0| -8.0| 1800.0|MSP | 842.0| 0.0|2018-12-31 02:00:00| | |WN |PVD | | 7.0| 7.0| | 1807.0| 1904.0| |
view rawgistfile1.txt hosted with ❤ by GitHub.
ScyllaDB + Feast
ScyllaDB también se integra con herramientas de almacén de características como Feast. Feast es un popular almacén de características de código abierto para el ML de producción. Puedes usar varios bases de datos como tu almacén de características en línea cuando uses Feast, incluyendo ScyllaDB.
Para configurar ScyllaDB como almacén en línea de Feast, necesitas editar el archivo de configuración de Feast y agregar las credenciales de ScyllaDB. ScyllaDB es compatible con Cassandra, por lo que puedes usar el conector integrado de Cassandra de Feast.
| # feature_store.yaml | |
| project: scylla_feature_repo | |
| registry: data/registry.db | |
| provider: local | |
| online_store: | |
| type: cassandra | |
| hosts: | |
| – node-0.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-1.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-2.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| keyspace: feast | |
| username: scylla | |
| password: password |
view rawgistfile1.txt hosted with ❤ by GitHub.
Conclusión
Los almacenes de características son necesarios para la ingeniería de características y la construcción de modelos de aprendizaje automático. Si estás construyendo una infraestructura de almacén de características en tiempo real, debes considerar cuidadosamente el rendimiento. Los requisitos de baja latencia, alto rendimiento y alta tasa de transferencia hacen que las bases de datos NoSQL sean un candidato perfecto como solución de almacenamiento en línea en tu almacén de características.
Source:
https://dzone.com/articles/tutorial-whats-an-aiml-feature-store-and-how-to-bu