













Gli store di feature per l’apprendimento automatico (ML) hanno attirato l’attenzione e l’utilizzo per applicazioni critiche per il business da quando Uber ha introdotto il concetto con Michelangelo nel 2017. In questo post di blog, approfondiremo i fondamenti degli store di feature ML e esploreremo perché e come ScyllaDB può essere parte cruciale della tua architettura di store di feature.
Per capire cosa sono gli store di feature, è importante prima comprendere cosa features siano.
Che cos’è una Feature?
Nell’apprendimento automatico, una feature è un insieme di punti dati che possono essere utilizzati per addestrare un modello e fare previsioni sul futuro sulla base di dati storici. Ad esempio, il nostro applicazione di esempio per store di feature ti permette di fare previsioni riguardo ai ritardi dei voli basandoti su registrazioni storiche dei voli.
Le features sono il risultato di complessi processi di elaborazione e trasformazione dei dati. Grandi quantità di dati di feature consentono previsioni accurate e progetti di apprendimento automatico riusciti.
Che cos’è uno Store di Feature?
A feature store is a central database in your machine-learning architecture that contains your real-time and historical features. Feature stores allow your data engineers and data scientists to use the same central repository to discover, monitor, and analyze features.
What does a feature store architecture look like?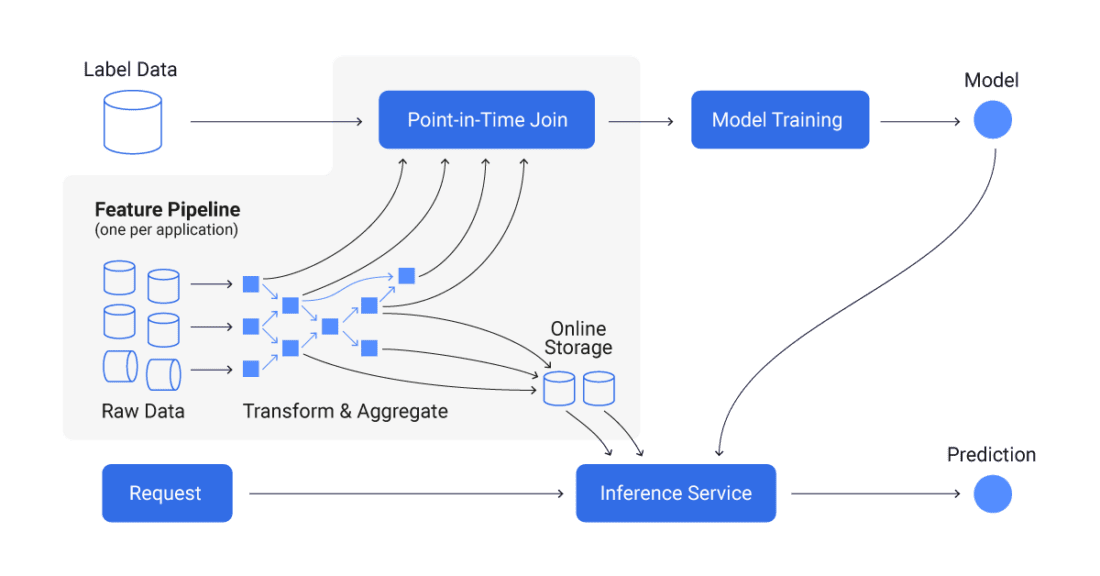
Database Online e Offline negli Store di Feature
Quando parliamo di store di feature, gli utenti di solito differenziano tra due tipi di database nella loro architettura. Da un lato, utilizzano un database online, e dall’altro, potrebbero anche avere un database offline. Questi database hanno scopi diversi.
Database offline: Questo tipo di database memorizza caratteristiche elaborate storiche, solitamente importate in batch. I database offline hanno dati delle caratteristiche che coprono un ampio arco temporale dalla storia; pertanto, sono utili per lavorare con un set di caratteristiche in un periodo specifico della storia.
Database online: Questo database potrebbe contenere dati provenienti da flussi di dati in tempo reale e dal database offline. La memorizzazione online viene utilizzata per alimentare il modello di produzione e altre applicazioni in tempo reale con i dati delle caratteristiche più aggiornati. La performance e la bassa latenza sono davvero importanti qui. Se il tuo database non è in grado di fornire caratteristiche in tempo reale abbastanza rapidamente, il tuo modello potrebbe utilizzare dati obsoleti o inaccurati per fare previsioni.
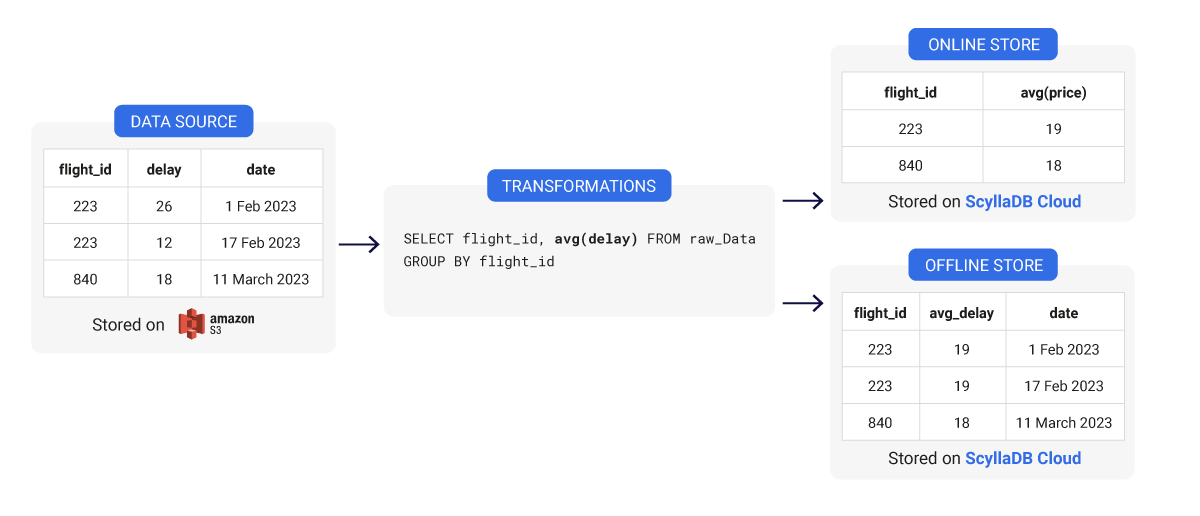
Modellazione dei dati dello Store di Caratteristiche: Design di Tabella Largo vs. Stretto
Quando progetti il modello dei dati all’interno del tuo store di caratteristiche, sia esso offline o online, puoi scegliere tra due tipi di design di tabelle: largo e stretto. Ognuno ha i propri vantaggi e svantaggi. Vediamo esempi concreti per entrambi e perché potrebbero o non potrebbero essere i migliori per il tuo caso d’uso:
Design di Tabella Largo
Il design di tabella largo include colonne separate per ogni caratteristica. Più tipi di caratteristiche vuoi memorizzare nella tabella, più colonne devi creare.
Esempio di Layout di Tabella Largo
| create table feature_store.wide_example( | |
| date TIMESTAMP, | |
| feature_id INT, | |
| feature_col1 FLOAT, | |
| feature_col2 FLOAT, | |
| feature_col3 FLOAT, | |
| feature_col4 FLOAT, | |
| feature_col5 FLOAT, | |
| feature_col6 FLOAT, | |
| feature_col7 FLOAT | |
| ) |
Questo tipo di layout può essere facile da iniziare, ma diventa anche più complicato da mantenere nel tempo e difficile da modificare. Ogni volta che vuoi introdurre una nuova caratteristica (o eliminare una esistente), devi modificare lo schema, il che può essere complicato.
Design di Tabella Stretto
I progetti di tabelle strette sono semplici e più facili da mantenere. Ciò è dovuto al fatto che il numero di colonne non è destinato ad aumentare o diminuire in futuro, anche se si aggiungono o rimuovono funzionalità.
Esempio di Layout di Tabella Stretta
| create table feature_store.narrow_example( | |
| feature_id INT, | |
| feature_name TEXT, | |
| feature_value FLOAT | |
| ) |
Utilizzando questo layout, è possibile limitarsi a due colonne fisse a lungo termine per memorizzare le funzionalità. Una per il nome della funzionalità (ad esempio, LATE_AIRCRAFT_DELAY) e una per il valore di quella funzionalità.
In generale, le tabelle strette potrebbero richiedere la conversione dei tipi di dati durante il recupero dei dati perché non sono nella forma corretta (ad esempio, il tipo di colonna è FLOAT, ma in realtà il valore dei dati è un INTEGER. Fortunatamente, quando parliamo di archivi di funzionalità, sia gli store online che offline hanno già i dati in formato numerico pulito (FLOAT) e tutti i valori hanno lo stesso tipo di dati, il che significa che questo non è uno svantaggio nel caso degli store di funzionalità.
Che cos’è ScyllaDB e come può essere utilizzato nell’architettura del tuo store di funzionalità?
Perché i team di machine learning costruiscano applicazioni di inferenza in tempo reale, hanno bisogno di database che possano restituire funzionalità su larga scala con bassa latenza. ScyllaDB è un database NoSQL ad alte prestazioni e bassa latenza in grado di gestire volumi elevati di operazioni di lettura e scrittura. Inoltre, ScyllaDB è un database affidabile per carichi di lavoro critici di store di funzionalità presso aziende come GE Healthcare o ShareChat. Grazie alla sua alta disponibilità e tolleranza ai guasti, può fare il lavoro pesante nella tua infrastruttura dove prestazioni e affidabilità sono importanti.
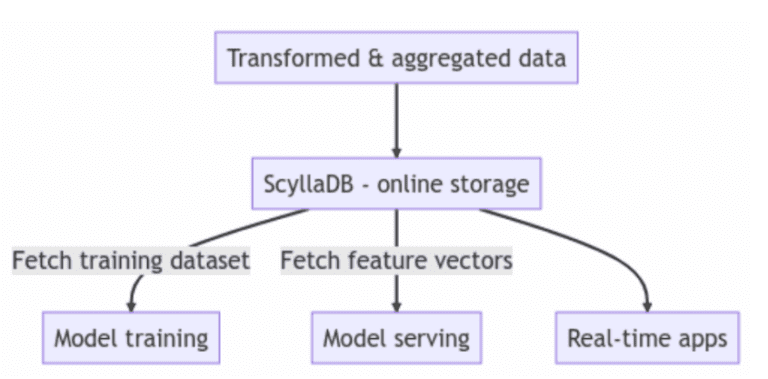
Oltre a utilizzare ScyllaDB come archivio online nella tua architettura di feature store, ScyllaDB viene anche utilizzato come soluzione di storage ibrido online/offline. Con questo approccio, puoi ridurre il carico di manutenzione per il tuo team avendo un unico database per gestire tutti i carichi di lavoro della feature store.
Gli utenti spesso posizionano ScyllaDB al centro della loro architettura per persistere e recuperare caratteristiche e metadati della feature store. In questo caso, ScyllaDB funge da archivio online. Altri utenti utilizzano anche ScyllaDB come loro storage ibrido online/offline. Le prestazioni sono un requisito chiave per accelerare lo sviluppo del modello, e le prestazioni di lettura e scrittura di ScyllaDB soddisfano costantemente o superano le aspettative degli utenti.
Infatti, alcuni utenti hanno scoperto che ScyllaDB potrebbe sostituire più database e fungere da unico archivio centrale per tutte le loro esigenze di dati per l’apprendimento automatico. Ad esempio, ScyllaDB può sostituire Redis (archivio online) e PostgreSQL (archivio offline) — rendendo la manutenzione dell’infrastruttura meno costosa e più semplice.
ScyllaDB si distingue nei casi d’uso in cui è richiesta bassa latenza e alta prestazione. Inoltre, ScyllaDB è compatibile con Cassandra e DynamoDB, il che significa che se utilizzi già uno di questi database, puoi migrare in modo fluido senza dover modificare le tue query.
Esercitazione: Archivio Online ScyllaDB
Per aiutarti a iniziare con ScyllaDB come archivio online, abbiamo creato un applicazione di esempio (disponibile anche su GitHub).
- Clona il repository
- Iscriviti a ScyllaDB Cloud o installa ScyllaDB localmente
- Crea lo schema:
cqlsh "node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud" 9042 -u scylla -p "password" -f schema.cql - Connettiti all’istanza con cqlsh e importa un dataset di esempio
cqlsh "node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud" 9042 -u scylla -p "password" scylla@cqlsh> COPY feature_store.flight_features FROM 'flight_features.csv';
Questo comando inserisce un dataset di esempio di voli:
| op_carrier_fl_num|actual_elapsed_time|air_time|arr_delay|arr_time|cancellation_code|cancelled|carrier_delay|crs_arr_time|crs_dep_time|crs_elapsed_time|dep_delay|dep_time|dest|distance|diverted|fl_date |late_aircraft_delay|nas_delay|op_carrier|origin|security_delay|taxi_in|taxi_out|weather_delay|wheels_off|wheels_on| | |
| —————–+——————-+——–+———+——–+—————–+———+————-+————+————+—————-+———+——–+—-+——–+——–+——————-+——————-+———+———-+——+————–+——-+——–+————-+———-+———+ | |
| 4317| 96.0| 73.0| -19.0| 2113.0| | 0.0| | 2132| 2040| 112.0| -3.0| 2037.0|MLI | 373.0| 0.0|2018-12-31 02:00:00| | |OO |DTW | | 5.0| 18.0| | 2055.0| 2108.0| | |
| 3372| 94.0| 74.0| 81.0| 1500.0| | 0.0| 0.0| 1339| 1150| 109.0| 96.0| 1326.0|RNO | 564.0| 0.0|2018-12-31 02:00:00| 81.0| 0.0|OO |SEA | 0.0| 3.0| 17.0| 0.0| 1343.0| 1457.0| | |
| 1584| 385.0| 348.0| -21.0| 2023.0| | 0.0| | 2034| 1700| 394.0| -9.0| 1658.0|SFO | 2565.0| 0.0|2018-12-31 02:00:00| | |UA |EWR | | 13.0| 33.0| | 1731.0| 2019.0| | |
| 4830| 119.0| 85.0| -35.0| 1431.0| | 0.0| | 1437| 1245| 136.0| -13.0| 1232.0|MSP | 546.0| 0.0|2018-12-31 02:00:00| | |OO |MSP | | 16.0| 18.0| | 1250.0| 1415.0| | |
| 2731| 158.0| 146.0| -19.0| 1911.0| | 0.0| | 1930| 1800| 160.0| -8.0| 1800.0|MSP | 842.0| 0.0|2018-12-31 02:00:00| | |WN |PVD | | 7.0| 7.0| | 1807.0| 1904.0| |
view rawgistfile1.txt hosted with ❤ by GitHub.
ScyllaDB + Feast
ScyllaDB si integra anche con strumenti di feature store come Feast. Feast è un popolare feature store open-source per il machine learning in produzione. Puoi utilizzare diversi database come tuo feature store online quando utilizzi Feast, incluso ScyllaDB.
Per configurare ScyllaDB come store online di Feast, è necessario modificare il file di configurazione di Feast e aggiungere le credenziali di ScyllaDB. ScyllaDB è compatibile con Cassandra, quindi puoi utilizzare il connettore Cassandra integrato di Feast.
| # feature_store.yaml | |
| project: scylla_feature_repo | |
| registry: data/registry.db | |
| provider: local | |
| online_store: | |
| type: cassandra | |
| hosts: | |
| – node-0.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-1.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-2.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| keyspace: feast | |
| username: scylla | |
| password: password |
view rawgistfile1.txt hosted with ❤ by GitHub.
Conclusioni
I feature store sono necessari per l’ingegneria dei feature e la costruzione di modelli di machine learning. Se stai costruendo un’infrastruttura di feature store in tempo reale, devi considerare attentamente le prestazioni. I requisiti di bassa latenza, alta prestazione e alto throughput rendono i database NoSQL un candidato perfetto come soluzione di archiviazione online nel tuo feature store.
Source:
https://dzone.com/articles/tutorial-whats-an-aiml-feature-store-and-how-to-bu