













Les magasins de caractéristiques de machine learning (ML) attirent l’attention et l’utilisation pour les applications vitales pour les entreprises depuis que Uber a introduit le concept avec Michelangelo en 2017. Dans cet article de blog, nous plongerons dans les bases des magasins de caractéristiques ML et explorerons pourquoi et comment ScyllaDB peut être une partie critique de votre architecture de magasin de caractéristiques.
Pour comprendre ce qu’est un magasin de caractéristiques, il est important de d’abord comprendre ce qu’caractéristiques sont.
Qu’est-ce qu’une Caractéristique?
En Machine Learning, une caractéristique est un ensemble de points de données qui peuvent être utilisés pour enseigner un modèle et faire des prédictions sur l’avenir basées sur des données historiques. Par exemple, notre application d’exemple de magasin de caractéristiques vous permet de faire des prédictions concernant les retards de vol en fonction des dossiers de vols historiques.
Les caractéristiques sont le résultat de pipelines complexes de traitement et de transformation des données. D’énormes quantités de données de caractéristiques permettent des prédictions précises et des projets réussis de machine learning.
Qu’est-ce qu’un Magasin de Caractéristiques?
A feature store is a central database in your machine-learning architecture that contains your real-time and historical features. Feature stores allow your data engineers and data scientists to use the same central repository to discover, monitor, and analyze features.
What does a feature store architecture look like?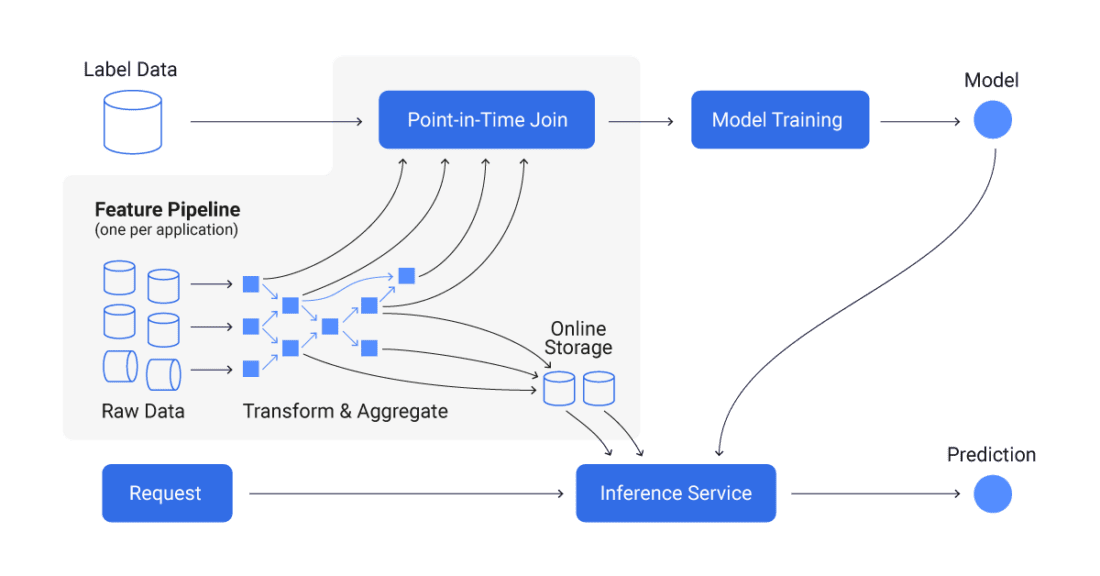
Bases de données en ligne et hors ligne dans le Magasin de Caractéristiques
Lorsque nous parlons de magasins de caractéristiques, les utilisateurs distinguent généralement entre deux types de bases de données dans leur architecture. D’un côté, ils utilisent une base de données en ligne, et de l’autre, ils pourraient également avoir une base de données hors ligne. Ces bases de données ont des objectifs différents.
Base de données hors ligne : Ce type de base de données stocke des caractéristiques traitées historiques, généralement ingérées par lots. Les bases de données hors ligne ont des données de caractéristiques couvrant une grande période à partir de l’histoire; par conséquent, elles sont utiles pour travailler avec un ensemble de caractéristiques dans une période spécifique de l’histoire.
Base de données en ligne : Cette base de données peut contenir des données provenant de flux de données en temps réel et de la base de données hors ligne également. Le stockage en ligne est utilisé pour servir le modèle de production et d’autres applications en temps réel avec les données de caractéristiques les plus à jour. La performance et la faible latence comptent vraiment ici. Si votre base de données n’est pas capable de fournir des caractéristiques en temps réel assez rapidement, alors votre modèle pourrait utiliser des données obsolètes ou inexactes pour faire des prédictions.
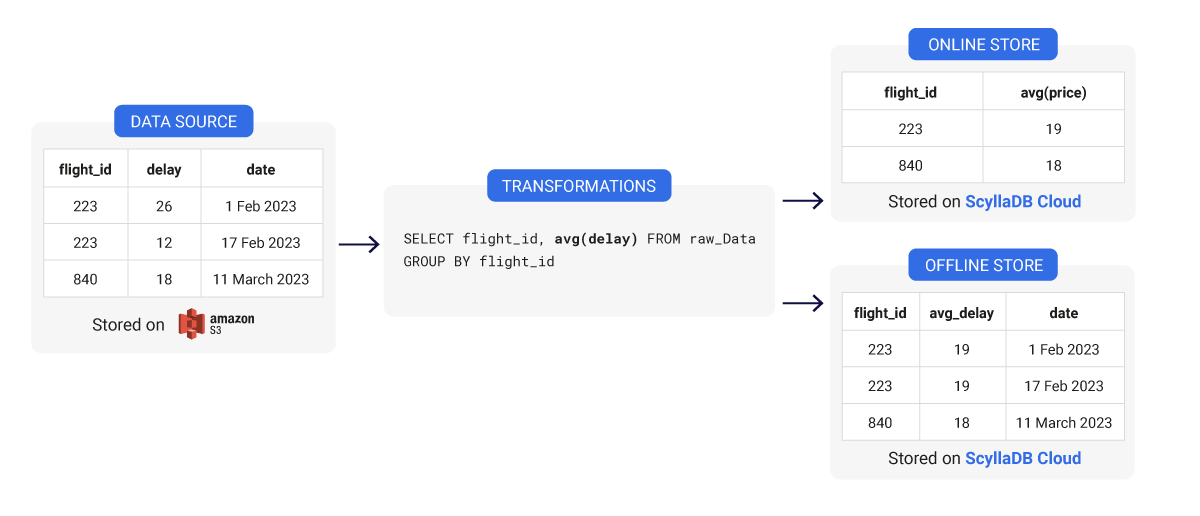
Modélisation des données du Feature Store: Design de table large vs. étroit
Lorsque vous concevez le modèle de données dans votre magasin de caractéristiques, qu’il soit hors ligne ou en ligne, vous pouvez choisir entre deux types de conceptions de table: large et étroit. Chacun a ses propres avantages et inconvénients. Voyons des exemples concrets pour les deux et pourquoi ils pourraient ou ne pourraient pas être les meilleurs pour votre cas d’utilisation:
Design de table large
Le design de table large inclut des colonnes distinctes pour chaque caractéristique. Plus vous souhaitez stocker de types de caractéristiques dans la table, plus vous devez créer de colonnes.
Exemple de mise en page de table large
| create table feature_store.wide_example( | |
| date TIMESTAMP, | |
| feature_id INT, | |
| feature_col1 FLOAT, | |
| feature_col2 FLOAT, | |
| feature_col3 FLOAT, | |
| feature_col4 FLOAT, | |
| feature_col5 FLOAT, | |
| feature_col6 FLOAT, | |
| feature_col7 FLOAT | |
| ) |
Ce type de mise en page peut être facile à démarrer, mais il devient également plus compliqué à maintenir au fil du temps et difficile à modifier. Chaque fois que vous souhaitez introduire une nouvelle caractéristique (ou supprimer une existante), vous devez modifier le schéma, ce qui peut être compliqué.
Design de table étroit
Les conceptions de tableaux étroits sont simples et plus faciles à maintenir. C’est parce que le nombre de colonnes n’est pas destiné à augmenter ou diminuer à l’avenir, même si vous ajoutez ou supprimez des fonctionnalités.
Exemple de mise en page de table étroite
| create table feature_store.narrow_example( | |
| feature_id INT, | |
| feature_name TEXT, | |
| feature_value FLOAT | |
| ) |
En utilisant cette mise en page, vous pouvez vous contenter d’utiliser uniquement deux colonnes fixes à long terme pour stocker les fonctionnalités. Une pour le nom de la fonctionnalité (par exemple, LATE_AIRCRAFT_DELAY) et une pour la valeur de cette fonctionnalité.
En général, les tableaux étroits peuvent nécessiter un transtypage des types de données lors de la récupération des données, car elles ne sont pas sous la forme correcte (par exemple, le type de colonne est FLOAT, mais en réalité, la valeur de données est un ENTIER. Heureusement, lorsque nous parlons de magasins de fonctionnalités, les magasins en ligne et hors ligne contiennent déjà les données sous une forme numérique propre (FLOAT) et toutes les valeurs ont le même type de données, ce qui signifie que ce n’est pas un inconvénient dans le cas des magasins de fonctionnalités.
Qu’est-ce que ScyllaDB et comment peut-il être utilisé dans votre architecture de magasin de fonctionnalités?
Afin que les équipes d’apprentissage automatique puissent créer des applications d’inférence en temps réel, elles ont besoin de bases de données capables de retourner des fonctionnalités à grande échelle avec une faible latence. ScyllaDB est une base de données NoSQL de haute performance et à faible latence capable de gérer de grandes quantités d’opérations de lecture et d’écriture. De plus, ScyllaDB est une base de données fiable pour les charges de travail critiques de magasin de fonctionnalités chez des entreprises comme GE Healthcare ou ShareChat. En raison de sa haute disponibilité et de sa tolérance aux pannes, il peut assumer le rôle de base de données performante et fiable dans votre infrastructure.
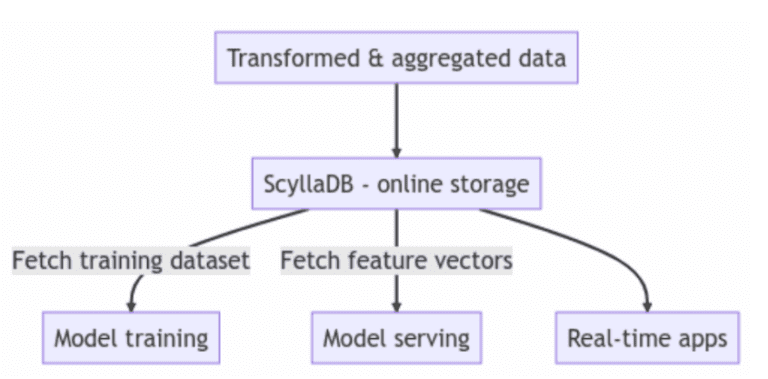
Outre l’utilisation de ScyllaDB comme magasin en ligne dans votre architecture de magasin de fonctionnalités, ScyllaDB est également utilisé comme solution de stockage hybride en ligne/hors ligne. Avec cette approche, vous pouvez réduire la charge de maintenance de votre équipe en ayant une seule base de données pour servir tous vos travaux de magasin de fonctionnalités.
Les utilisateurs placent souvent ScyllaDB au centre de leur architecture pour conserver et récupérer des fonctionnalités et des métadonnées de magasin de fonctionnalités. Dans ce cas, ScyllaDB agit comme un magasin en ligne. D’autres utilisateurs utilisent également ScyllaDB comme stockage hybride en ligne/hors ligne. La performance est un critère clé afin de pouvoir accélérer le développement de modèles, et les performances de lecture et d’écriture de ScyllaDB répondent constamment ou dépassent les attentes des utilisateurs.
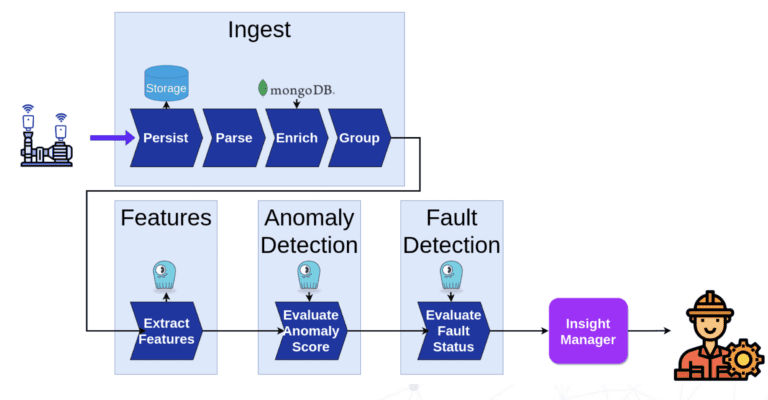
En réalité, certains utilisateurs ont constaté que ScyllaDB pouvait remplacer plusieurs bases de données et servir de stockage central unique pour toutes leurs besoins en données d’apprentissage automatique. Par exemple, ScyllaDB peut remplacer Redis (magasin en ligne) et PostgreSQL (magasin hors ligne) — rendant la maintenance de l’infrastructure moins coûteuse et plus simple.
ScyllaDB se distingue dans les cas d’utilisation où vous avez besoin de faible latence et de haute performance. De plus, ScyllaDB est compatible avec Cassandra et DynamoDB, ce qui signifie que si vous utilisez déjà l’une de ces bases de données, vous pouvez migrer en douceur sans avoir à modifier vos requêtes.
Tutoriel : Magasin en ligne ScyllaDB
Pour vous aider à démarrer avec ScyllaDB en tant que magasin en ligne, nous avons créé une application d’exemple (également disponible sur GitHub).
- Cloner le dépôt
- Inscrivez-vous sur ScyllaDB Cloud ou installez ScyllaDB localement
- Créez le schéma:
cqlsh "node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud" 9042 -u scylla -p "password" -f schema.cql - Connectez-vous à l’instance avec cqlsh et importez un jeu de données d’exemple
cqlsh "node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud" 9042 -u scylla -p "password" scylla@cqlsh> COPY feature_store.flight_features FROM 'flight_features.csv';
Cette commande ingère un jeu de données d’exemple de vols:
| op_carrier_fl_num|actual_elapsed_time|air_time|arr_delay|arr_time|cancellation_code|cancelled|carrier_delay|crs_arr_time|crs_dep_time|crs_elapsed_time|dep_delay|dep_time|dest|distance|diverted|fl_date |late_aircraft_delay|nas_delay|op_carrier|origin|security_delay|taxi_in|taxi_out|weather_delay|wheels_off|wheels_on| | |
| —————–+——————-+——–+———+——–+—————–+———+————-+————+————+—————-+———+——–+—-+——–+——–+——————-+——————-+———+———-+——+————–+——-+——–+————-+———-+———+ | |
| 4317| 96.0| 73.0| -19.0| 2113.0| | 0.0| | 2132| 2040| 112.0| -3.0| 2037.0|MLI | 373.0| 0.0|2018-12-31 02:00:00| | |OO |DTW | | 5.0| 18.0| | 2055.0| 2108.0| | |
| 3372| 94.0| 74.0| 81.0| 1500.0| | 0.0| 0.0| 1339| 1150| 109.0| 96.0| 1326.0|RNO | 564.0| 0.0|2018-12-31 02:00:00| 81.0| 0.0|OO |SEA | 0.0| 3.0| 17.0| 0.0| 1343.0| 1457.0| | |
| 1584| 385.0| 348.0| -21.0| 2023.0| | 0.0| | 2034| 1700| 394.0| -9.0| 1658.0|SFO | 2565.0| 0.0|2018-12-31 02:00:00| | |UA |EWR | | 13.0| 33.0| | 1731.0| 2019.0| | |
| 4830| 119.0| 85.0| -35.0| 1431.0| | 0.0| | 1437| 1245| 136.0| -13.0| 1232.0|MSP | 546.0| 0.0|2018-12-31 02:00:00| | |OO |MSP | | 16.0| 18.0| | 1250.0| 1415.0| | |
| 2731| 158.0| 146.0| -19.0| 1911.0| | 0.0| | 1930| 1800| 160.0| -8.0| 1800.0|MSP | 842.0| 0.0|2018-12-31 02:00:00| | |WN |PVD | | 7.0| 7.0| | 1807.0| 1904.0| |
view rawgistfile1.txt hosted with ❤ by GitHub.
ScyllaDB + Feast
ScyllaDB s’intègre également avec des outils de magasin de fonctionnalités comme Feast. Feast est un magasin de fonctionnalités open-source populaire pour la production ML. Vous pouvez utiliser plusieurs bases de données comme votre magasin de fonctionnalités en ligne lors de l’utilisation de Feast, y compris ScyllaDB.
Pour configurer ScyllaDB en tant que magasin en ligne Feast, vous devez modifier le fichier de configuration de Feast et ajouter vos informations d’identification ScyllaDB. ScyllaDB est compatible avec Cassandra, vous pouvez donc utiliser le connecteur Cassandra intégré de Feast.
| # feature_store.yaml | |
| project: scylla_feature_repo | |
| registry: data/registry.db | |
| provider: local | |
| online_store: | |
| type: cassandra | |
| hosts: | |
| – node-0.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-1.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-2.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| keyspace: feast | |
| username: scylla | |
| password: password |
view rawgistfile1.txt hosted with ❤ by GitHub.
Conclusion
Les magasins de fonctionnalités sont nécessaires pour l’ingénierie des fonctionnalités et la construction de modèles d’apprentissage automatique. Si vous construisez une infrastructure de magasin de fonctionnalités en temps réel, vous devez tenir compte attentivement des performances. Les exigences de faible latence, de haute performance et de débit élevé font des bases de données NoSQL un candidat parfait en tant que solution de stockage en ligne dans votre magasin de fonctionnalités.
Source:
https://dzone.com/articles/tutorial-whats-an-aiml-feature-store-and-how-to-bu