













Модуль Python Pandas
- Pandas – это библиотека с открытым исходным кодом на языке Python. Она предоставляет готовые высокопроизводительные структуры данных и инструменты для анализа данных.
- Модуль Pandas работает поверх NumPy и широко используется для науки о данных и аналитики данных.
- NumPy – это низкоуровневая структура данных, которая поддерживает многомерные массивы и широкий спектр математических операций с массивами. Pandas имеет более высокоуровневый интерфейс. Он также обеспечивает удобную выравнивание табличных данных и мощную функциональность временных рядов.
- DataFrame является основной структурой данных в Pandas. Он позволяет хранить и обрабатывать табличные данные в виде двумерной структуры данных.
- Pandas предоставляет богатый набор функций для работы с DataFrame. Например, выравнивание данных, статистика данных, срезы, группировка, объединение, конкатенация данных и т. д.
Установка и начало работы с Pandas
Для установки модуля Pandas вам понадобится Python версии 2.7 и выше. Если вы используете conda, то вы можете установить его с помощью следующей команды.
conda install pandas
Если вы используете PIP, то выполните следующую команду для установки модуля pandas.
pip3.7 install pandas
Чтобы импортировать Pandas и NumPy в ваш сценарий Python, добавьте следующий код:
import pandas as pd
import numpy as np
Поскольку Pandas зависит от библиотеки NumPy, нам нужно импортировать эту зависимость.
Структуры данных в модуле Pandas
Модуль Pandas предоставляет 3 структуры данных, которые следующие:
- Серия: Это одномерный массив неизменяемого размера, похожий на структуру данных с однородными данными.
- Фрейм данных: Это двумерная изменяемая таблица с колонками разных типов.
- Панель: Это трехмерный изменяемый массив.
Фрейм данных Pandas
Фрейм данных является наиболее важной и широко используемой структурой данных и является стандартным способом хранения данных. Фрейм данных имеет данные, выровненные по строкам и столбцам, аналогично таблице SQL или базе данных электронных таблиц. Мы можем либо жестко закодировать данные во фрейм данных, либо импортировать файл CSV, файл tsv, файл Excel, таблицу SQL и т. д. Мы можем использовать следующий конструктор для создания объекта фрейма данных.
pandas.DataFrame(data, index, columns, dtype, copy)
Ниже приведено краткое описание параметров:
- данные – создает объект DataFrame из входных данных. Это может быть список, словарь, серия, массивы Numpy или даже любой другой DataFrame.
- индекс – содержит метки строк
- столбцы – используются для создания меток столбцов
- dtype – используется для указания типа данных каждого столбца, необязательный параметр
- copy – используется для копирования данных, если они есть
Существует множество способов создания DataFrame. Мы можем создать объект DataFrame из словарей или списка словарей. Мы также можем создать его из списка кортежей, CSV-файла, файла Excel и т. Д. Давайте запустим простой код для создания DataFrame из списка словарей.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)
Вывод:  Первый шаг – создать словарь. Второй шаг – передать словарь в качестве аргумента в метод DataFrame(). Финальный шаг – вывести DataFrame. Как видите, DataFrame можно сравнить с таблицей, имеющей гетерогенные значения. Кроме того, размер DataFrame можно изменить. Мы предоставили данные в виде отображения, и ключи отображения рассматриваются Pandas в качестве меток строк. Индекс отображается в самом левом столбце и содержит метки строк. Заголовок столбца и данные отображаются в виде таблицы. Также возможно создание индексированных DataFrames. Это можно сделать, настроив параметр индекса в методе
Первый шаг – создать словарь. Второй шаг – передать словарь в качестве аргумента в метод DataFrame(). Финальный шаг – вывести DataFrame. Как видите, DataFrame можно сравнить с таблицей, имеющей гетерогенные значения. Кроме того, размер DataFrame можно изменить. Мы предоставили данные в виде отображения, и ключи отображения рассматриваются Pandas в качестве меток строк. Индекс отображается в самом левом столбце и содержит метки строк. Заголовок столбца и данные отображаются в виде таблицы. Также возможно создание индексированных DataFrames. Это можно сделать, настроив параметр индекса в методе DataFrame().
Импорт данных из CSV в DataFrame
Мы также можем создать DataFrame, импортировав файл CSV. Файл CSV – это текстовый файл с одной записью данных на каждой строке. Значения внутри записи разделены с помощью символа “запятая”. Pandas предоставляет полезный метод с именем read_csv(), чтобы прочитать содержимое файла CSV в DataFrame. Например, мы можем создать файл с именем ‘cities.csv’, содержащий данные о городах Индии. Файл CSV хранится в том же каталоге, что и скрипты Python. Этот файл можно импортировать с помощью:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
. Наша цель – загрузить данные и проанализировать их для получения выводов. Поэтому мы можем использовать любой удобный метод для загрузки данных. В этом учебнике мы жестко закодировали данные DataFrame.
Осмотр данных в DataFrame
Запуск DataFrame с использованием его имени отображает всю таблицу. В реальном времени наборы данных для анализа будут содержать тысячи строк. Для анализа данных нам необходимо изучать данные из огромных объемов наборов данных. Pandas предоставляет много полезных функций для осмотра только тех данных, которые нам нужны. Мы можем использовать df.head(n), чтобы получить первые n строк, или df.tail(n), чтобы вывести последние n строк. Например, в следующем коде выводятся первые 2 строки и последняя 1 строка из DataFrame.
print(df.head(2))
Результат: 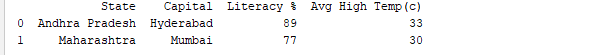
print(df.tail(1))
Результат: 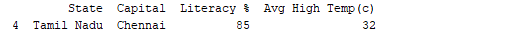 Аналогично,
Аналогично, print(df.dtypes) выводит типы данных. Результат: 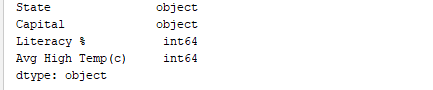
print(df.index) выводит индекс. Результат: 
print(df.columns) выводит столбцы DataFrame. Результат: 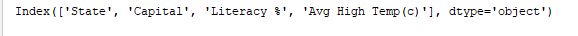
print(df.values) отображает значения таблицы. Результат: 
1. Получение статистического резюме записей
Мы можем получить статистическую сводку (количество, среднее значение, стандартное отклонение, минимум, максимум и т. д.) данных, используя функцию df.describe(). Теперь давайте используем эту функцию, чтобы отобразить статистическую сводку столбца “Образованность %”. Для этого мы можем добавить следующий код:
print(df['Literacy %'].describe())
Результат: 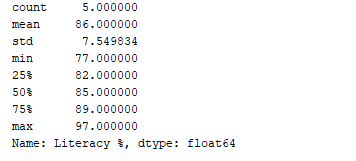 Функция
Функция df.describe() отображает статистическую сводку вместе с типом данных.
2. Сортировка записей
Мы можем сортировать записи по любому столбцу с помощью функции df.sort_values(). Например, отсортируем столбец “Образованность %” в порядке убывания.
print(df.sort_values('Literacy %', ascending=False))
Результат: 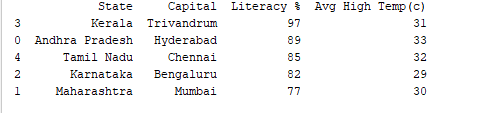
3. Выделение записей
Мы можем извлекать данные определенного столбца, используя его название. Например, чтобы извлечь столбец “Столица”, мы используем:
df['Capital']
или
(df.Capital)
Вывод:  Также можно выбрать несколько столбцов. Для этого нужно заключить имена столбцов в двойные квадратные скобки и разделить их запятыми. Следующий код выбирает столбцы ‘State’ и ‘Capital’ из DataFrame.
Также можно выбрать несколько столбцов. Для этого нужно заключить имена столбцов в двойные квадратные скобки и разделить их запятыми. Следующий код выбирает столбцы ‘State’ и ‘Capital’ из DataFrame.
print(df[['State', 'Capital']])
Вывод:  Также можно выбирать строки. Несколько строк можно выбрать с помощью оператора “:”. Нижний код возвращает первые 3 строки.
Также можно выбирать строки. Несколько строк можно выбрать с помощью оператора “:”. Нижний код возвращает первые 3 строки.
df[0:3]
Вывод:  Интересной особенностью библиотеки Pandas является возможность выбора данных на основе меток строк и столбцов с использованием функции
Интересной особенностью библиотеки Pandas является возможность выбора данных на основе меток строк и столбцов с использованием функции iloc[0]. Во многих случаях нам может потребоваться только несколько столбцов для анализа. Мы также можем выбирать по индексу, используя функцию loc['index_one']). Например, чтобы выбрать вторую строку, мы можем использовать df.iloc[1,:]. Допустим, нам нужно выбрать второй элемент второго столбца. Это можно сделать с помощью функции df.iloc[1,1]. В этом примере функция df.iloc[1,1] выводит “Мумбаи” как результат.
4. Фильтрация данных
Также можно фильтровать значения по столбцам. Например, нижний код фильтрует столбцы, у которых процент грамотности выше 90%.
print(df[df['Literacy %']>90])
Любой оператор сравнения может быть использован для фильтрации на основе условия. Вывод:  Другой способ фильтрации данных – использование
Другой способ фильтрации данных – использование isin. Ниже приведен код для фильтрации только двух штатов «Карнатака» и «Тамилнад».
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])
Вывод: 
5. Переименование столбца
Возможно использование функции df.rename() для переименования столбца. В функцию передаются старое имя столбца и новое имя столбца. Например, давайте переименуем столбец «Процент грамотности» в «Процент грамотности».
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())
Аргумент `inplace=True` вносит изменения в DataFrame. Вывод: 
6. Обработка данных
Data Science включает в себя обработку данных, чтобы данные хорошо взаимодействовали с алгоритмами обработки данных. Data Wrangling – это процесс обработки данных, такой как объединение, группировка и конкатенация. Библиотека Pandas предоставляет полезные функции, такие как merge(), groupby() и concat(), для поддержки задач обработки данных. Давайте создадим 2 DataFrame и покажем функции Data Wrangling, чтобы лучше понять их.
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)
Вывод:  Создадим второй DataFrame, используя следующий код:
Создадим второй DataFrame, используя следующий код:
import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)
Вывод: 
a. Merging
Теперь объединим два созданных DataFrame по значениям «Employee_id» с помощью функции merge():
print(pd.merge(df1, df2, on='Employee_id'))
Вывод:  Мы видим, что функция merge() возвращает строки из обоих DataFrame с одинаковым значением столбца, использованного при объединении.
Мы видим, что функция merge() возвращает строки из обоих DataFrame с одинаковым значением столбца, использованного при объединении.
b. Grouping
Группировка – это процесс сбора данных в разные категории. Например, в приведенном ниже примере поле “Employee_Name” содержит имя “Meera” два раза. Давайте сгруппируем его по столбцу “Employee_name”.
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
Поле ‘Employee_name’ со значением ‘Meera’ сгруппировано по столбцу “Employee_name”. Пример вывода:Вывод: 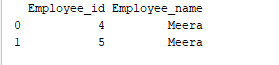
c. Concatenating
Конкатенация данных включает добавление одного набора данных к другому. Pandas предоставляет функцию с именем concat() для объединения DataFrame. Например, давайте объединим DataFrame df1 и df2 с помощью:
print(pd.concat([df1, df2]))
Output: 
Создание DataFrame путем передачи словаря серий
Для создания серии мы можем использовать метод pd.Series() и передать ему массив. Давайте создадим простую серию следующим образом:
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)
Output:  Мы создали серию. Вы можете видеть, что отображаются 2 столбца. Первый столбец содержит индексные значения, начиная с 0. Второй столбец содержит элементы, переданные в качестве серии. Возможно создать DataFrame, передав словарь `Series`. Давайте создадим DataFrame, который формируется путем объединения и передачи индексов серий. Пример
Мы создали серию. Вы можете видеть, что отображаются 2 столбца. Первый столбец содержит индексные значения, начиная с 0. Второй столбец содержит элементы, переданные в качестве серии. Возможно создать DataFrame, передав словарь `Series`. Давайте создадим DataFrame, который формируется путем объединения и передачи индексов серий. Пример
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
Пример вывода 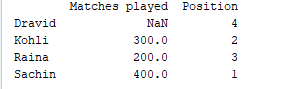 Для серии one, поскольку мы не указали метку ‘d’, возвращается NaN.
Для серии one, поскольку мы не указали метку ‘d’, возвращается NaN.
Выделение столбцов, добавление, удаление
Возможно выбрать определенный столбец из DataFrame. Например, чтобы отобразить только первый столбец, мы можем переписать вышеприведенный код следующим образом:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
Вышеприведенный код выводит только столбец “Matches played” DataFrame. Результат 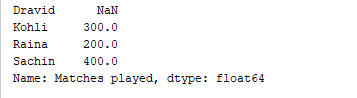 Также возможно добавлять столбцы к существующему DataFrame. Например, следующий код добавляет новый столбец с именем “Runrate” в вышеприведенный DataFrame.
Также возможно добавлять столбцы к существующему DataFrame. Например, следующий код добавляет новый столбец с именем “Runrate” в вышеприведенный DataFrame.
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
Результат:  Мы можем удалять столбцы с помощью функций `delete` и `pop`. Например, чтобы удалить столбец ‘Matches played’ в приведенном выше примере, мы можем сделать это одним из двух способов:
Мы можем удалять столбцы с помощью функций `delete` и `pop`. Например, чтобы удалить столбец ‘Matches played’ в приведенном выше примере, мы можем сделать это одним из двух способов:
del df['Matches played']
или
df.pop('Matches played')
Результат: 
Заключение
В этом учебнике мы кратко познакомились с библиотекой Python Pandas. Мы также провели практические примеры, чтобы раскрыть возможности библиотеки Pandas, используемые в области науки о данных. Мы также изучили различные структуры данных в библиотеке Python. Ссылка: Официальный веб-сайт Pandas
Source:
https://www.digitalocean.com/community/tutorials/python-pandas-module-tutorial