













11 декабря 2024 года услуги OpenAI испытали значительное время простоя из-за проблемы, возникшей в результате развертывания новой службы телеметрии. Этот инцидент повлиял на API, ChatGPT и Sora, что привело к сбоям в работе, продолжавшимся несколько часов. Как компания, стремящаяся предоставить точные и эффективные ИИ-решения, OpenAI опубликовала подробный отчет о произошедшем, чтобы открыто обсудить, что пошло не так и как они планируют предотвратить аналогичные случаи в будущем.
В этой статье я опишу технические аспекты инцидента, разберу коренные причины и изучу ключевые уроки, которые разработчики и организации, управляющие распределенными системами, могут извлечь из этого события.
Хронология инцидента
Вот краткий обзор того, как разворачивались события 11 декабря 2024 года:
| Time (PST) | Event |
|---|---|
| 15:16 | Начало незначительного влияния на клиентов; наблюдается ухудшение сервиса |
| 15:27 | Инженеры начали перенаправлять трафик с пострадавших кластеров |
| 15:40 | Зафиксировано максимальное влияние на клиентов; крупные сбои во всех службах |
| 16:36 | Первый кластер Kubernetes начал восстанавливаться |
| 17:36 | Начало значительного восстановления для API-услуг |
| 17:45 | Наблюдается значительное восстановление для ChatGPT |
| 19:38 | Все услуги полностью восстановлены во всех кластерах |
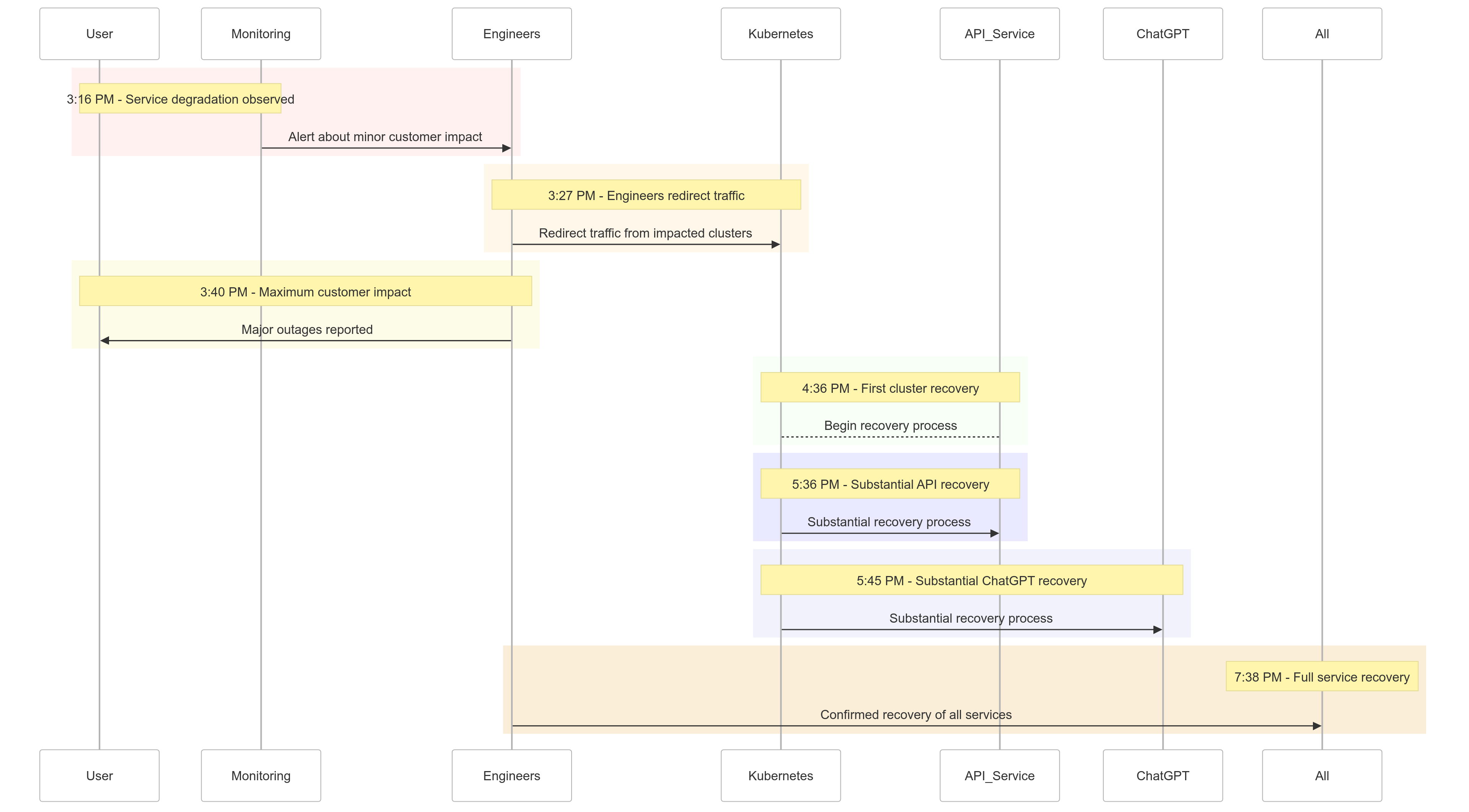
Рисунок 1: Хронология инцидента OpenAI – Снижение качества обслуживания до полного восстановления.
Анализ коренной причины
Корень инцидента заключался в новом телеметрическом сервисе, развернутом в 15:12 по тихоокеанскому времени, для улучшения наблюдаемости контрольных плоскостей Kubernetes. Этот сервис непреднамеренно перегрузил API-серверы Kubernetes в нескольких кластерах, что привело к каскадным сбоям.
Разбор ситуации
Развертывание телеметрического сервиса
Телеметрический сервис был предназначен для сбора детализированных метрик контрольной плоскости Kubernetes, но его конфигурация непреднамеренно вызвала ресурсоемкие операции API Kubernetes на тысячах узлов одновременно.
Перегруженная контрольная плоскость
Контрольная плоскость Kubernetes, отвечающая за администрирование кластера, была перегружена. Хотя плоскость данных (обрабатывающая запросы пользователей) оставалась частично функциональной, она зависела от контрольной плоскости для разрешения DNS. По мере истечения срока действия кэшированных записей DNS, услуги, полагавшиеся на разрешение DNS в реальном времени, начали выходить из строя.
Недостаточное тестирование
Развертывание тестировалось в тестовой среде, но тестовые кластеры не отражали масштабы производственных кластеров. В результате проблема с нагрузкой на API-сервер осталась неизвлеченной во время тестирования.
Как была смягчена проблема
Когда инцидент начался, инженеры OpenAI быстро определили основную причину, но столкнулись с трудностями при реализации исправления, поскольку перегруженная управляющая плоскость Kubernetes не позволяла получить доступ к API-серверам. Был принят многогранный подход:
- Сокращение размера кластера: Снижение количества узлов в каждом кластере снизило нагрузку на API-сервер.
- Блокировка сетевого доступа к административным API Kubernetes: Это предотвратило дополнительные запросы к API, позволяя серверам восстановиться.
- Увеличение числа API-серверов Kubernetes: Обеспечение дополнительных ресурсов помогло очистить ожидающие запросы.
Эти меры позволили инженерам восстановить доступ к управляющим плоскостям и удалить проблемную службу телеметрии, восстановив функциональность сервиса.
Извлеченные уроки
Этот инцидент подчеркивает критическую важность надежного тестирования, мониторинга и механизмов защиты в распределенных системах. Вот что OpenAI узнала (и реализовала) из сбоя:
1. Надежные поэтапные развертывания
Все изменения инфраструктуры теперь будут следовать поэтапным развертываниям с непрерывным мониторингом. Это гарантирует раннее обнаружение проблем и их устранение до масштабирования на весь парк.
2. Тестирование на внедрение ошибок
Путем моделирования сбоев (например, отключения управляющей плоскости или развертывания неудачных изменений) OpenAI будет проверять, могут ли их системы восстанавливаться автоматически и обнаруживать проблемы до того, как они повлияют на клиентов.
3. Доступ к аварийному управлению
Механизм «разбить стекло» обеспечит доступ инженеров к серверам API Kubernetes даже под высокой нагрузкой.
4. Разделение управляющего и данных
Чтобы уменьшить зависимости, OpenAI разделит плоскость данных Kubernetes (обрабатывающую рабочие нагрузки) и управляющую плоскость (ответственную за оркестрацию), что обеспечит продолжение работы критически важных сервисов даже во время сбоев в управляющей плоскости.
5. Более быстрые механизмы восстановления
Новые стратегии кэширования и ограничения по скорости улучшат время запуска кластера, обеспечивая более быстрое восстановление при сбоях.
Пример кода: пример поэтапного развертывания
Вот пример реализации поэтапного развертывания для Kubernetes с использованием Helm и Prometheus для наблюдения.
Развертывание Helm с поэтапными развертываниями:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
Запрос Prometheus для мониторинга нагрузки на сервер API:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
Этот запрос помогает отслеживать время отклика на запросы к серверу API, обеспечивая раннее обнаружение всплесков нагрузки.
Пример внедрения ошибок
С помощью chaos-mesh OpenAI может симулировать сбои в управляющей плоскости Kubernetes.
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
Эта конфигурация намеренно убивает под сервера API, чтобы проверить устойчивость системы.
Что это означает для вас
Этот инцидент подчеркивает важность проектирования устойчивых систем и применения строгих методологий тестирования. Независимо от того, управляете ли вы распределенными системами в большом масштабе или реализуете Kubernetes для своих рабочих нагрузок, вот некоторые выводы:
- Регулярно моделируйте сбои: Используйте инструменты хаос-инжиниринга, такие как Chaos Mesh, для тестирования надежности системы в условиях реального мира.
- Мониторинг на нескольких уровнях: Убедитесь, что ваш стек наблюдаемости отслеживает как метрики уровня сервиса, так и метрики здоровья кластера.
- Разделите критические зависимости: Сведите к минимуму зависимость от единичных точек отказа, таких как сервисное открытие на основе DNS.
Заключение
Хотя ни одна система не застрахована от сбоев, такие инциденты напоминают нам о ценности прозрачности, быстрого устранения проблем и непрерывного обучения. Проактивный подход OpenAI к публикации этого пост-мортема предоставляет план для других организаций по улучшению их операционных практик и надежности.
Приоритизируя надежные поэтапные развертывания, тестирование на внедрение ошибок и проектирование устойчивых систем, OpenAI задает сильный пример того, как справляться с крупными сбоями и учиться на них.
Для команд, управляющих распределенными системами, этот инцидент является отличным примером того, как подходить к управлению рисками и минимизировать время простоя для ключевых бизнес-процессов.
Давайте использовать это как возможность создать вместе более надежные системы.
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident