













No dia 11 de dezembro de 2024, os serviços da OpenAI enfrentaram um tempo de inatividade significativo devido a um problema decorrente de um novo serviço de telemetria implantado. Este incidente afetou os serviços de API, ChatGPT e Sora, resultando em interrupções que duraram várias horas. Como uma empresa que visa fornecer soluções de IA precisas e eficientes, a OpenAI compartilhou um relatório detalhado de pós-morte para discutir de forma transparente o que deu errado e como planejam evitar ocorrências semelhantes no futuro.
Neste artigo, descreverei os aspectos técnicos do incidente, analisarei as causas raiz e explorarei as lições-chave que desenvolvedores e organizações que gerenciam sistemas distribuídos podem extrair deste evento.
A Linha do Tempo do Incidente
Aqui está um resumo de como os eventos se desenrolaram no dia 11 de dezembro de 2024:
| Time (PST) | Event |
|---|---|
| 15:16 | Impacto menor nos clientes começou; degradação do serviço observada |
| 15:27 | Engenheiros começaram a redirecionar o tráfego dos clusters afetados |
| 15:40 | Impacto máximo nos clientes registrado; grandes interrupções em todos os serviços |
| 16:36 | O primeiro cluster Kubernetes começou a se recuperar |
| 17:36 | Recuperação substancial dos serviços de API começou |
| 17:45 | Recuperação substancial do ChatGPT observada |
| 19:38 | Todos os serviços totalmente recuperados em todos os clusters |
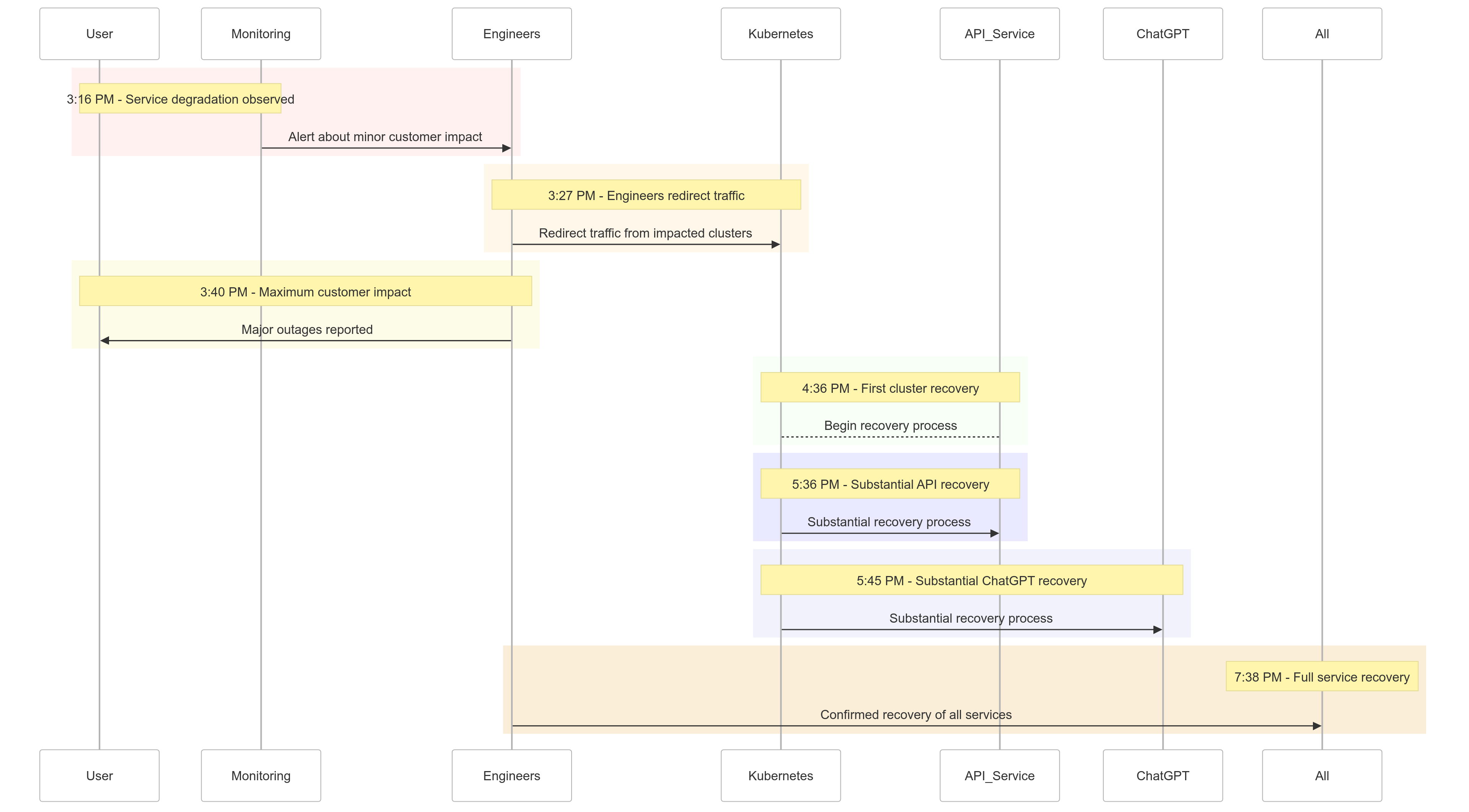
Figura 1: Cronograma do Incidente OpenAI – Degradação do Serviço até a Recuperação Completa.
Análise da Causa Raiz
A raíz do incidente estava em um novo serviço de telemetria implantado às 15h12 PST para melhorar a observabilidade dos planos de controle do Kubernetes. Este serviço sobrecarregou inadvertidamente os servidores de API do Kubernetes em vários clusters, levando a falhas em cascata.
Dividindo em Partes
Implantação do Serviço de Telemetria
O serviço de telemetria foi projetado para coletar métricas detalhadas do plano de controle do Kubernetes, mas sua configuração acionou inadvertidamente operações de API intensivas em recursos em milhares de nodes simultaneamente.
Plano de Controle Sobrecarregado
O plano de controle do Kubernetes, responsável pela administração do cluster, ficou sobrecarregado. Enquanto o plano de dados (lidando com solicitações do usuário) permaneceu parcialmente funcional, ele dependia do plano de controle para resolução de DNS. À medida que os registros de DNS em cache expiravam, os serviços que dependiam de resolução de DNS em tempo real começaram a falhar.
Testes Insuficientes
A implantação foi testada em um ambiente de preparação, mas os clusters de preparação não refletiam a escala dos clusters de produção. Como resultado, o problema de carga do servidor de API passou despercebido durante os testes.
Como o Problema Foi Mitigado
Quando o incidente começou, os engenheiros da OpenAI identificaram rapidamente a causa raiz, mas enfrentaram desafios na implementação de uma solução porque o plano de controle do Kubernetes sobrecarregado impediu o acesso aos servidores de API. Uma abordagem multiangular foi adotada:
- Reduzindo o Tamanho do Cluster: Reduzir o número de nós em cada cluster diminuiu a carga nos servidores de API.
- Bloqueio do Acesso à Rede aos APIs de Administração do Kubernetes: Impediu solicitações de API adicionais, permitindo que os servidores se recuperassem.
- Aumentando os Servidores de API do Kubernetes: O provisionamento de recursos adicionais ajudou a limpar as solicitações pendentes.
Essas medidas permitiram que os engenheiros recuperassem o acesso aos planos de controle e removessem o serviço de telemetria problemático, restaurando a funcionalidade do serviço.
Lições Aprendidas
Este incidente destaca a criticidade de testes robustos, monitoramento e mecanismos de segurança em sistemas distribuídos. Aqui está o que a OpenAI aprendeu (e implementou) a partir da interrupção:
1. Implantações em Fases Robustas
Todas as mudanças de infraestrutura seguirão agora implantações em fases com monitoramento contínuo. Isso garante que os problemas sejam detectados precocemente e mitigados antes de se expandirem para toda a frota.
2. Teste de Injeção de Falhas
Ao simular falhas (por exemplo, desabilitar o plano de controle ou implementar alterações ruins), a OpenAI verificará se seus sistemas podem se recuperar automaticamente e detectar problemas antes de impactar os clientes.
3. Acesso de Emergência ao Plano de Controle
Um mecanismo de “quebrar o vidro” garantirá que os engenheiros possam acessar os servidores de API do Kubernetes mesmo sob alta carga.
4. Desacoplamento dos Planos de Controle e Dados
Para reduzir dependências, a OpenAI desacoplará o plano de dados do Kubernetes (que lida com cargas de trabalho) do plano de controle (responsável pela orquestração), garantindo que serviços críticos possam continuar funcionando mesmo durante interrupções no plano de controle.
5. Mecanismos de Recuperação Mais Rápidos
Novas estratégias de cache e limitação de taxa melhorarão os tempos de inicialização do cluster, garantindo uma recuperação mais rápida durante falhas.
Código Exemplo: Exemplo de Lançamento Fásico
Aqui está um exemplo de como implementar um lançamento fásico para o Kubernetes usando Helm e Prometheus para observabilidade.
Implantação do Helm com lançamentos fásicos:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
Consulta do Prometheus para monitorar a carga do servidor de API:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
Esta consulta ajuda a rastrear os tempos de resposta para solicitações do servidor de API, garantindo a detecção precoce de picos de carga.
Exemplo de Injeção de Falhas
Usando chaos-mesh, a OpenAI poderia simular interrupções no plano de controle do Kubernetes.
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
Esta configuração mata intencionalmente um pod do servidor de API para verificar a resiliência do sistema.
O Que Isso Significa Para Você
Este incidente destaca a importância de projetar sistemas resilientes e adotar metodologias de teste rigorosas. Seja você responsável por gerenciar sistemas distribuídos em grande escala ou esteja implementando Kubernetes para suas cargas de trabalho, aqui estão algumas lições:
- Simule Falhas Regularmente: Use ferramentas de engenharia de caos como o Chaos Mesh para testar a robustez do sistema em condições do mundo real.
- Monitore em Múltiplos Níveis: Garanta que sua pilha de observabilidade rastreie tanto métricas de nível de serviço quanto métricas de saúde do cluster.
- Desacople Dependências Críticas: Reduza a dependência de pontos únicos de falha, como descoberta de serviço baseada em DNS.
Conclusão
Embora nenhum sistema seja imune a falhas, incidentes como este nos lembram do valor da transparência, da rápida remediação e do aprendizado contínuo. A abordagem proativa da OpenAI em compartilhar este pós-morte fornece um modelo para outras organizações melhorarem suas práticas operacionais e confiabilidade.
Ao priorizar lançamentos robustos em fases, testes de injeção de falhas e design de sistemas resilientes, a OpenAI está estabelecendo um forte exemplo de como lidar e aprender com interrupções em larga escala.
Para equipes que gerenciam sistemas distribuídos, este incidente é um excelente estudo de caso sobre como abordar a gestão de riscos e minimizar o tempo de inatividade para processos de negócios essenciais.
Vamos usar isso como uma oportunidade para construir juntos sistemas melhores e mais resilientes.
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident