













2024年12月11日,由於新的遙測服務部署問題,OpenAI服務遭遇重大停機。此事件影響了API、ChatGPT和Sora服務,導致服務中斷,持續數小時。作為一家旨在提供準確和高效人工智能解決方案的公司,OpenAI已經分享了一份詳細的事後報告,以透明地討論出了什麼問題,以及他們計劃如何防止未來發生類似事件。
在本文中,我將描述事件的技術方面,分解根本原因,並探討開發人員和管理分散系統的組織可以從這次事件中得出的關鍵教訓。
事件時間軸
以下是2024年12月11日事件的發展快照:
| Time (PST) | Event |
|---|---|
| 下午3:16 | 開始出現輕微客戶影響;觀察到服務降級 |
| 下午3:27 | 工程師開始從受影響的集群重新定向流量 |
| 下午3:40 | 記錄到最大的客戶影響;所有服務出現重大故障 |
| 下午4:36 | 第一個Kubernetes集群開始恢復 |
| 下午5:36 | API服務開始大幅恢復 |
| 下午5:45 | 觀察到ChatGPT的大幅恢復 |
| 下午7:38 | 所有集群中的所有服務完全恢復 |
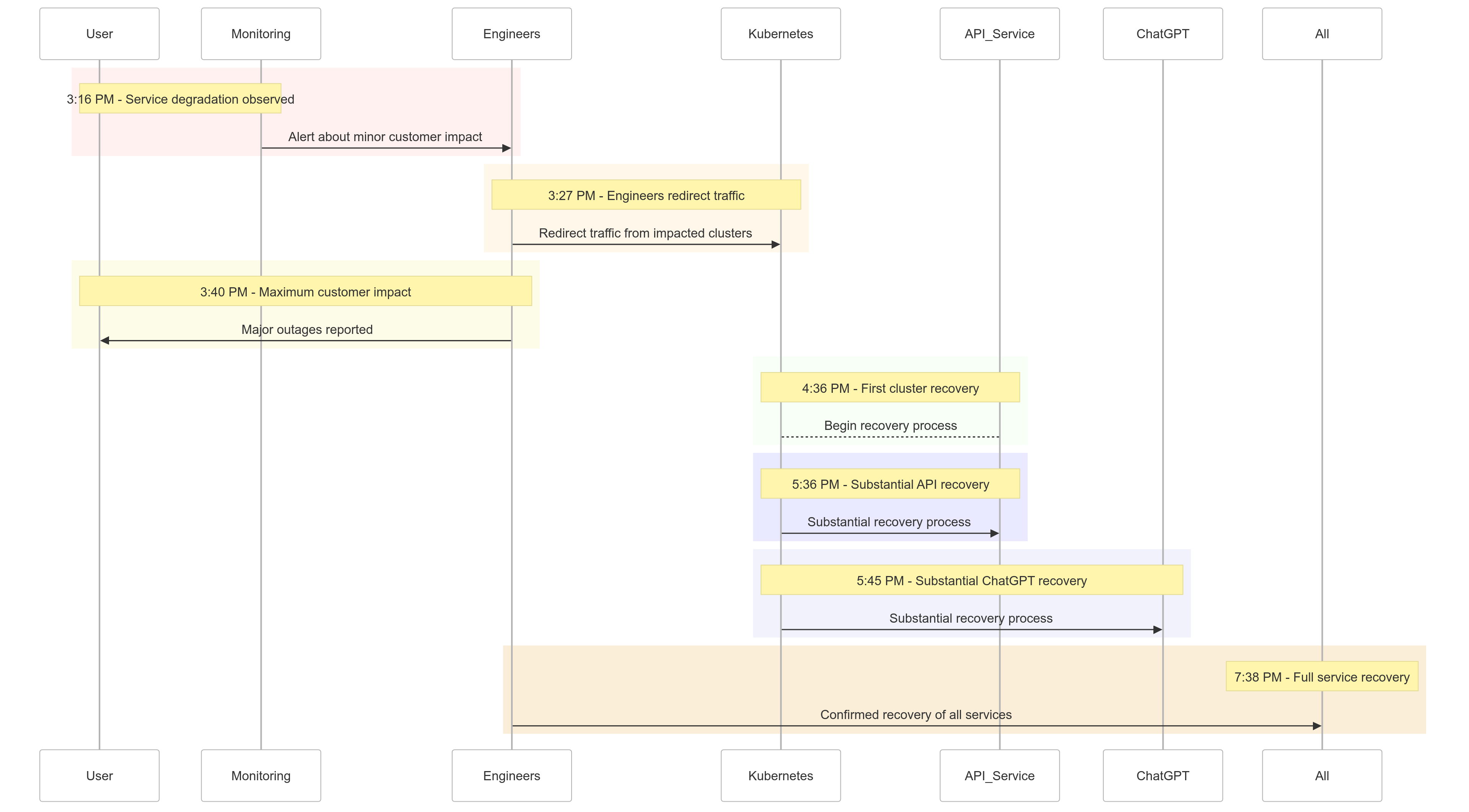
圖 1:OpenAI 事件時間軸 – 服務降級至完全恢復。
根本原因分析
事件的根源在於於下午 3:12 PST 部署的新遙測服務,旨在改善 Kubernetes 控制平面的可觀察性。該服務無意中壓倒了跨多個叢集的 Kubernetes API 伺服器,導致級聯失敗。
分解
遙測服務部署
遙測服務旨在收集詳細的 Kubernetes 控制平面指標,但其配置無意中觸發了跨數千個節點同時進行資源密集型 Kubernetes API 操作。
過載的控制平面
負責叢集管理的 Kubernetes 控制平面變得不堪重負。儘管數據平面(處理用戶請求)部分功能正常,但它依賴於控制平面進行 DNS 解析。隨著緩存的 DNS 記錄過期,依賴實時 DNS 解析的服務開始失敗。
測試不足
該部署在測試環境中進行了測試,但測試叢集並不反映生產叢集的規模。因此,在測試期間未能檢測到 API 伺服器負載問題。
問題的緩解方法
當事件發生時,OpenAI 的工程師迅速辨識出根本原因,但面臨挑戰在於因為超載的 Kubernetes 控制平面阻礙了對 API 伺服器的存取。採取了多管齊下的方法:
- 縮小集群規模: 降低每個集群中節點的數量可以減輕 API 伺服器的負載。
- 阻擋對 Kubernetes 管理 API 的網路存取:阻止額外的 API 請求,使伺服器得以恢復。
- 擴展 Kubernetes API 伺服器:提供額外資源有助於處理待處理的請求。
這些措施讓工程師們重新取得對控制平面的存取權並移除有問題的遙測服務,恢復服務功能。
經驗教訓
這次事件凸顯了在分散式系統中堅固測試、監控和故障安全機制的重要性。以下是 OpenAI 從這次中學到的(並實施了):
1. 堅固的分階段部署
所有基礎設施變更現在將遵循分階段部署並進行持續監控。這確保問題能夠在擴大到整個系統之前被早期檢測並緩解。
2. 故障注入測試
通過模擬故障(例如禁用控制平面或推出不良更改),OpenAI 將驗證他們的系統能夠自動恢復並在影響客戶之前檢測問題。
3. 緊急控制平面訪問
一個“緊急開門”機制將確保工程師可以在負載過重時訪問Kubernetes API伺服器。
4. 解耦控制和數據平面
為了減少依賴,OpenAI將解耦<Kubernetes數據平面(處理工作負載)和控制平面(負責編排),確保關鍵服務可以在控制平面故障期間繼續運行。
5. 更快的恢復機制
新的緩存和速率限制策略將改善集群啟動時間,確保在故障期間更快地恢復。
示例代碼:分階段部署示例
以下是使用Helm和Prometheus實現Kubernetes分階段部署的示例。
使用分階段部署的Helm部署:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
用於監控API伺服器負載的Prometheus查詢:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
此查詢有助於跟踪API伺服器請求的響應時間,確保及早檢測到負載峰值。
故障注入示例
使用chaos-mesh,OpenAI可以模擬Kubernetes控制平面的故障。
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
此配置故意終止API伺服器pod以驗證系統的韌性。
這對您意味著什麼
這一事件突顯了設計韌性系統和採用嚴格測試方法的重要性。無論您是管理大規模的分散式系統,還是為您的工作負載實施 Kubernetes,以下是一些要點:
- 定期模擬故障:使用像 Chaos Mesh 這樣的混沌工程工具,測試系統在現實條件下的穩健性。
- 在多層級進行監控: 確保您的可觀察性堆疊跟踪服務級別指標和集群健康指標。
- 解耦關鍵依賴:減少對單一故障點的依賴,例如基於 DNS 的服務發現。
結論
雖然沒有系統能夠完全免疫於故障,但這樣的事件提醒我們透明度、迅速修復和持續學習的價值。OpenAI 主動分享這篇事後分析為其他組織提供了改進其運營實踐和可靠性的藍圖。
通過優先考慮穩健的分階段推出、故障注入測試和韌性系統設計,OpenAI 樹立了如何應對和從大規模停機中學習的良好範例。
對於管理分散式系統的團隊來說,這一事件是如何進行風險管理和最小化核心業務流程停機時間的絕佳案例研究。
讓我們把這當作一起構建更好、更韌性系統的機會。
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident