













XML повсюду. Несмотря на его раздражающее использование угловых скобок, формат XML все еще широко используется. Файлы конфигурации, RSS-ленты, файлы Office (с ‘x’ в .docx) – это всего лишь частичный список. Использование PowerShell для анализа файлов XML – это важный шаг в вашем путешествии с PowerShell.
Этот учебник покажет вам, как использовать PowerShell для анализа и валидации файлов XML. Он проведет вас от нуля до героя во всех аспектах получения и оценки данных XML. Вам будут предоставлены инструменты, которые помогут вам проверять целостность данных XML и блокировать неисправные данные прямо у ворот ваших сценариев!
Предварительные требования
Для работы с представленным материалом вам потребуется:
- PowerShell версии 3.0 и выше. Примеры были созданы в Windows PowerShell v5.1
- Notepad++, Visual Studio Code или другой текстовый редактор, который понимает XML.
Анализ элементов PowerShell XML с использованием Select-Xml
Давайте сначала рассмотрим один из самых популярных и простых способов использования PowerShell для анализа XML – с помощью Select-Xml. Командлет Select-Xml позволяет вам предоставить файл или строку XML вместе с “фильтром”, известным как XPath, для извлечения определенной информации.
XPath – это цепочка имен элементов. Он использует синтаксис “похожий на путь”, чтобы идентифицировать и перемещаться по узлам в XML-документе.
Предположим, у вас есть XML-файл с набором компьютеров, и вы хотели бы использовать PowerShell для разбора этого XML-файла. У каждого компьютера есть различные элементы, такие как имя, IP-адрес, и элемент Include для включения в отчет.
Элемент – это часть XML с открывающим тегом и закрывающим тегом, возможно, с каким-то текстом между ними, например,
<Name>SRV-01</Name>
Вы хотели бы использовать PowerShell для разбора этого XML-файла и получения имен компьютеров. Для этого вы можете использовать команду Select-Xml.
В файле выше имена компьютеров появляются в тексте между тегами Name.
InnerXML – это текст между двумя тегами элемента.
Чтобы найти имена компьютеров, сначала укажите соответствующий XPath (/Computers/Computer/Name). Этот синтаксис XPath вернет только узлы Name под элементами Computer. Затем, чтобы получить только InnerXML каждого элемента Name, используйте свойство Node.InnerXML на каждом элементе с помощью цикла ForEach-Object.
Использование PowerShell для разбора XML-атрибутов с Select-Xml
Теперь давайте рассмотрим эту проблему по-другому, а именно поиска имен компьютеров. В этот раз, вместо того чтобы представлять дескрипторы компьютера с использованием XML-элементов , они представлены атрибутами XML .
Атрибут – это часть ключа/значения, такая как
name="SRV-01". Атрибуты всегда появляются внутри открывающего тега, сразу после имени тега.
Ниже приведен XML-файл с дескрипторами компьютеров, представленными в виде атрибутов. Теперь каждый дескриптор можно видеть как атрибут, а не элемент.
Поскольку каждый дескриптор является атрибутом на этот раз, немного измените XPath, чтобы найти только элементы Computer. Затем, снова используя cmdlet ForEach-Object, найдите значение атрибута name.
И, действительно, это также приносит те же результаты: SRV-01, SRV-02 и SRV-03:

В обоих случаях, будь то чтение элементов или атрибутов, синтаксис Select-Xml громоздок: он заставляет вас использовать параметр XPath, затем направлять результат в цикл и, наконец, искать данные в свойстве Node.
К счастью, PowerShell предлагает более удобный и интуитивно понятный способ для чтения XML-файлов. PowerShell позволяет читать XML-файлы и преобразовывать их в XML-объекты.
Связано: Использование ускорителей типов данных PowerShell для ускорения кодирования
Приведение строк XML к объектам
Еще один способ использования PowerShell для разбора XML-файлов – преобразовать XML в объекты. Самый простой способ сделать это – использовать ускоритель типа [xml].
Путем добавления префикса к именам переменных с [xml] PowerShell преобразует исходный текст XML в объекты, с которыми затем можно работать.
Чтение элементов объекта XML
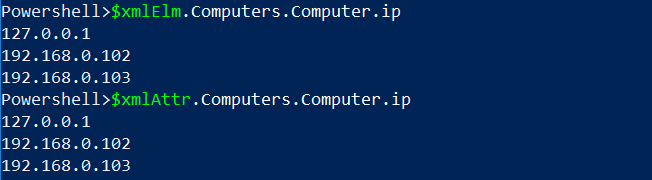
Теперь переменные $xmlElm и $xmlAttr являются объектами XML, которые позволяют ссылаться на свойства с использованием точечной нотации. Возможно, вам нужно найти IP-адрес каждого компьютерного элемента. Поскольку XML-файл является объектом, вы можете просто обратиться к элементу IP.
Начиная с версии PowerShell 3.0, для получения значения атрибута объекта XML используется та же синтаксическая конструкция, что и для чтения внутреннего текста элемента. Таким образом, значения IP-адресов считываются из файла атрибутов точно таким же синтаксисом, как и из файла элементов.
Чтение атрибутов XML
Используя точно такую же точечную нотацию, вы можете читать атрибуты XML, несмотря на различия в структуре XML.
И результаты ниже показывают, что оба получили одни и те же данные, каждый из соответствующего файла:
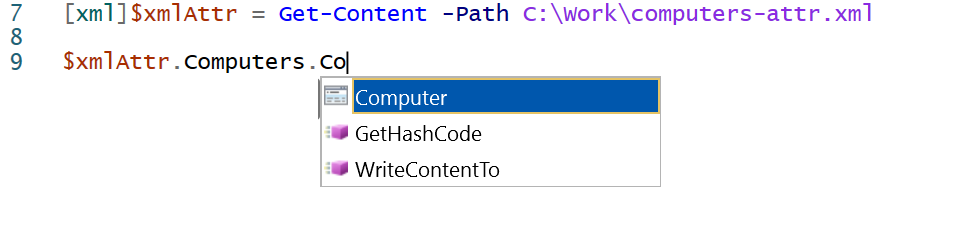
Более того, с объектом, после его загрузки в память, вы даже получаете подсказки IntelliSense для автозаполнения, если используете PowerShell ISE. Например, как показано ниже.
Итерирование по данным XML
Как только вы освоите чтение XML-файлов непосредственно в объект XML (используя ускоритель типа [xml]), у вас есть весь потенциал объектов PowerShell.
Скажем, например, вам необходимо выполнить цикл по всем компьютерам, которые появляются в XML-файле с атрибутом include=”true”, чтобы проверить их статус подключения. Ниже приведен код, показывающий, как это можно сделать.
Этот скрипт:
- Чтение файла и преобразование его в объект XML.
- Итерация по соответствующим компьютерам для получения их статуса подключения.
- Наконец, отправка результирующего объекта вывода в конвейер.
Результаты вышеуказанного скрипта показаны ниже:

XML-схемы
В предыдущем разделе вы видели два разных XML-файла, представляющих набор данных двумя разными способами. Эти способы называются XML-схемами. XML-схема определяет правильные строительные блоки конкретного XML-документа:
- Имена элементов и атрибутов, которые могут появляться в этом конкретном документе.
- Количество и порядок дочерних элементов.
- Типы данных для элементов и атрибутов.
Схема в основном определяет структуру XML.
Проверка данных XML
XML-файл может иметь правильный синтаксис (редакторы типа Notepad++ будут жаловаться, если нет), но его данные могут не соответствовать требованиям проекта. Здесь и вступает схема. Когда вы оперируете данными XML, вы должны убедиться, что все данные действительны согласно определенной схеме.
Последнее, что вы хотите, это обнаружить ошибки данных во время выполнения, на глубине в 500 строк в середине сценария. К тому времени уже могли быть выполнены некоторые необратимые операции в файловой системе и реестре.
Итак, как можно заранее проверить, что данные корректны? Давайте сначала рассмотрим некоторые возможные типы ошибок.
Возможные ошибки в данных XML
В общем, ошибки, найденные в файлах XML, принадлежат к одной из двух категорий: ошибки метаданных и ошибки в самих данных.
Ошибки метаданных XML
Этот файл MorePeople.xml ниже с точки зрения синтаксиса является абсолютно допустимым. Вы видите, что в файле есть один элемент People (корневой элемент) с тремя элементами Person внутри. Эта структура вполне приемлема. Тем не менее в ней есть одно исключение, видите ли вы его?
Не беспокойтесь, если вы не заметили, оно просто скрыто. Проблема заключается в первом внутреннем элементе:
То, что должно было быть Country, было написано с ошибкой, и Канада была унижена до County.
Ошибки в данных XML
После исправления проблемы с Country в файле MorePeople.xml, появилась другая проблема:
Метаданные, то есть элементы и атрибуты, в порядке. Так в чем проблема? На этот раз проблема, снова на первой строке Person , заключается в одном из значений. Кто-то решил, что yes достаточно хорошая замена для true – но код, подобный приведенному ниже, не сможет получить первый элемент, так как он ищет true, а не yes:
Создание схемы XML
Теперь, когда вы знаете, какие ошибки могут возникнуть, пришло время показать, как помогает файл схемы. Первый шаг – создание образца файла данных. Образец может быть самым маленьким примером и содержать только один внутренний элемент. Для приведенных выше примеров давайте создадим файл-образец, подобный этому People.xml:
Теперь создайте функцию PowerShell ниже и используйте ее с образцом данных для создания .xsd схемы.
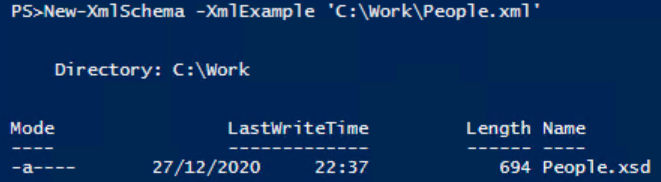
Скопируйте функцию в ваш ISE или ваш редактор PowerShell, загрузите ее в память и используйте для создания схемы. После загрузки функции код для создания схемы будет выглядеть следующим образом:
Результаты покажут путь к только что созданной схеме:
Использование файла схемы для проверки ваших данных
Взгляните на указанное местоположение в выдаче выше. Если там есть файл .xsd, значит, вы на верном пути, чтобы увидеть проверку в действии. Для шага подтверждения используйте следующую функцию:
Загрузите функцию в память и используйте ее для проверки файла MorePeople.xml из двух примеров ошибок. Чтобы запустить проверку, используйте следующую команду:
Фактические результаты зависят от содержания файла MorePeople.xml.
Давайте рассмотрим два примера. Обратите внимание, что когда MorePeople.xml не содержит ошибок, указанная выше функция вернет True.

Когда файл MorePeople.xml содержит неверные данные (ключ Country опечатан как County), функция вернет некоторые подробности о неудаче и вернет False.

Как вы можете видеть, указанная в подробном выводе ошибка очень информативна: она указывает на файл-виновника и указывает на точный компонент в нем, где произошла проблема.
Настройка схемы проверки
Давайте взглянем на файл схемы, а затем посмотрим, как мы можем сделать его еще лучше.
Схема, созданная по умолчанию с помощью New-XmlSchema, приведена ниже:
Схема по умолчанию выше хороша, но не идеальна. Действительно, она обнаружила опечатку с атрибутом Country. Однако, если оставить схему как есть, в случае, если другие ожидания не будут выполнены, эти проблемы не будут сообщаться как ошибки при проверке с помощью Test-XmlBySchema. Давайте решим эту проблему.
Таблица ниже представляет некоторые случаи, которые не считаются ошибками валидации и останутся незамеченными Test-XmlBySchema. В каждой строке в правом столбце показано, как вручную изменить схему для добавления поддержки необходимой защиты.
A modified version of the schema file, with all protections added, is shown right after the table.
Добавление параметра в схему по умолчанию – примеры
| Required Behavior | Relevant setting on the schema file |
| At least one Person element | Set the minOccurs value of the Person element to 1 |
| Make Name, Country and IsAdmin attributes mandatory | Add use=”required” to each of these attributes declaration |
| Allow only true/false values for IsAdmin | Set type=”xs:boolean” for the IsAdmin declaration |
| Allow only Country names between 3 and 40 characters | Use the xs:restriction (see detailed explanation after the schema text) |
При наличии ограничения типа boolean для атрибута IsAdmin в приведенном примере его значение должно быть строчным true или false.
Проверка длины строки с использованием xs:restriction
Проверка длины строки немного сложна. Так что, даже если она показана выше как часть измененной схемы, ей заслуживает немного больше внимания.
Исходный элемент схемы для атрибута Country (после ручного добавления use=”required”) выглядит следующим образом:
Чтобы добавить защиту по длине, вы должны добавить элемент <xs:simpleType>, а внутри него <xs:restriction base="xs:string">. Это ограничение, в свою очередь, содержит необходимые ограничения, объявленные на xs:minLength и xs:minLength.
После всех этих изменений объявление окончательного xs:attribute выросло из одной строки в огромный узел из 8 строк:
Если ваша голова не кружится после объяснения выше, вы заработали право увидеть валидацию в действии. Для этого давайте намеренно сократим значение Canada до двух символов слога: Ca
С коротким названием страны на месте и сохраненным файлом MorePeople.xml, вы готовы выполнить следующую команду валидации:
и результаты действительно показывают, что сложная схема сделала свою работу:

Проверка схемы XML может стать более сложной и проверять практически любой шаблон, который вы можете себе представить, особенно когда она сочетается с регулярными выражениями.