













XML is overal aanwezig. Ondanks het vervelende gebruik van hoekige haken, wordt het XML-formaat nog steeds veel gebruikt. Configuratiebestanden, RSS-feeds, Office-bestanden (de ‘x’ in de .docx) zijn slechts een gedeeltelijke lijst. Het gebruik van PowerShell om XML-bestanden te parseren is een essentiële stap in je PowerShell-reis.
Deze tutorial laat zien hoe je PowerShell XML-bestanden kunt parseren en valideren. Dit zal je van nul naar held brengen voor alle aspecten van het verkrijgen en evalueren van XML-gegevens. Je krijgt tools aangereikt die je helpen bij het valideren van de integriteit van XML-gegevens en het stoppen van defecte gegevens direct bij de poort van je scripts!
Vereisten
Om het gepresenteerde materiaal te volgen, moet je het volgende hebben:
- PowerShell-versie 3.0 en hoger. De voorbeelden zijn gemaakt op Windows PowerShell v5.1
- Notepad++, Visual Studio Code of een andere teksteditor die XML begrijpt.
Parse Powershell XML-elementen met Select-Xml
Laten we eerst een van de meest populaire en gemakkelijkste manieren behandelen om PowerShell te gebruiken om XML te parseren, en dat is met Select-Xml. De Select-Xml cmdlet stelt je in staat om een XML-bestand of -reeks te geven samen met een “filter” genaamd XPath om specifieke informatie op te halen.
XPath is een reeks elementnamen. Het maakt gebruik van een “padachtige” syntaxis om knooppunten in een XML-document te identificeren en te navigeren.
Stel dat je een XML-bestand hebt met een reeks computers en dit XML-bestand wilt analyseren met PowerShell. Elke computer heeft verschillende elementen zoals naam, IP-adres en een Include-element voor opname in een rapport.
Een element is een XML-gedeelte met een openingstag en een sluitingstag, mogelijk met wat tekst daartussen, zoals
<Name>SRV-01</Name>
Je wilt PowerShell gebruiken om de computernamen uit dit XML-bestand te halen. Hiervoor kun je de Select-Xml-opdracht gebruiken.
In het bovenstaande bestand verschijnen de computernamen in de innerlijke tekst (InnerXML) van het Name-element.
InnerXML is de tekst tussen de twee tags van het element.
Om de computernamen te vinden, zou je eerst de juiste XPath opgeven (/Computers/Computer/Name). Deze XPath-syntaxis zou alleen de Name-knooppunten onder de Computer-elementen retourneren. Vervolgens, om alleen de InnerXML van elk Name-element te krijgen, gebruik je de Node.InnerXML-eigenschap op elk element met een ForEach-Object-lus.
Het gebruik van PowerShell om XML-attributen te analyseren met Select-Xml
Nu laten we dit probleem van het vinden van computernamen vanuit een ander perspectief bekijken. Deze keer, in plaats van de computeraanduidingen vertegenwoordigd met XML elementen, worden ze vertegenwoordigd met XML attributen.
Een attribuut is een sleutel/waarde-deel zoals
name="SRV-01". Attributen verschijnen altijd binnen de openings-tag, direct na de tag-naam.
Hieronder staat het XML-bestand met computeraanduidingen vertegenwoordigd met attributen. Je kunt nu elke aanduiding zien als een attribuut in plaats van een element.
Aangezien elke aanduiding dit keer een attribuut is, pas het XPath een beetje aan om alleen de Computer elementen te vinden. Vervolgens, met behulp van een ForEach-Object cmdlet opnieuw, vind de waarde van het naam attribuut.
En inderdaad, dit brengt ook dezelfde resultaten met zich mee: SRV-01, SRV-02 en SRV-03 :

In beide gevallen, of je nu elementen of attributen leest, de syntaxis van Select-Xml is omslachtig: het dwingt je om de XPath parameter te gebruiken, vervolgens het resultaat door te geven aan een lus, en uiteindelijk naar de gegevens te zoeken onder de Node eigenschap.
Gelukkig biedt PowerShell een handigere en intuïtievere manier om XML-bestanden te lezen. PowerShell laat je XML-bestanden lezen en ze converteren naar XML objecten.
Gerelateerd: Het gebruik van PowerShell Data Typen Accelerators om de codeersnelheid te verhogen
Het casten van XML-strings naar objecten
Een andere manier om PowerShell te gebruiken om XML te parsen, is door die XML om te zetten in objecten. De gemakkelijkste manier om dit te doen is met de [xml] typeversneller.
Door de variabelenamen te prefixen met [xml], zet PowerShell de originele platte tekst XML om in objecten waarmee je vervolgens kunt werken.
XML Object Elementen Lezen
Nu zijn zowel de $xmlElm als $xmlAttr variabelen XML-objecten die je toestaan eigenschappen te refereren via dot-notatie. Misschien moet je het IP-adres van elk computer element vinden. Aangezien het XML-bestand een object is, kun je dit doen door simpelweg het IP-element te refereren.
Vanaf PowerShell versie 3.0, krijgt het XML-object de attribuutwaarde met dezelfde syntaxis die gebruikt wordt voor het lezen van de innerlijke tekst van het element. Daarom worden de waarden van de IP-adressen gelezen uit het attributenbestand met exact dezelfde syntaxis als het elementenbestand.
XML Attributen Lezen
Met exact dezelfde dot-notatie, kun je ondanks verschillen in de XML-structuur ook XML-attributen lezen.
En de resultaten hieronder laten zien dat beide dezelfde gegevens hebben gekregen, elk uit zijn overeenkomstige bestand:
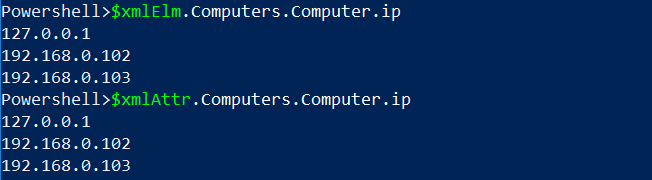
Bovendien, met het object, eenmaal geladen in het geheugen, krijg je zelfs IntelliSense om te tab-completeren als je de PowerShell ISE gebruikt. Bijvoorbeeld zoals hieronder getoond.
Itereren Door XML Gegevens
Zodra je XML-bestanden direct naar XML-object (door gebruik te maken van de [xml] typeversneller) kunt lezen, heb je alle volledige kracht van PowerShell-objecten.
Zeg, bijvoorbeeld, dat je verplicht bent om door alle computers te loopen die verschijnen in het XML-bestand met het attribuut include=”true” om hun verbindingsstatus te controleren. De onderstaande code laat zien hoe dit kan worden gedaan.
Deze script is:
- Het bestand lezen en het naar een XML-object casten.
- Door de relevante computers itereren om hun verbindingsstatus te verkrijgen.
- Tenslotte, het resultaatoutputobject naar de pipeline sturen.
En de resultaten van het bovenstaande script worden hieronder getoond:

XML-schema’s
In de vorige sectie zag je twee verschillende XML-bestanden die een dataset op twee verschillende manieren voorstelden. Die manieren worden XML-schema’s genoemd. Een XML-schema definieert de wettelijke bouwstenen van een specifiek XML-document:
- De namen van elementen en attributen die in dat specifieke document kunnen verschijnen.
- Het aantal en de volgorde van kind-elementen.
- De gegevenstypen voor elementen en attributen.
Het schema definieert in wezen de structuur van de XML.
XML-gegevens valideren
Een XML-bestand kan de juiste syntaxis hebben (editors zoals Notepad++ zullen klagen als dat niet het geval is), maar de gegevens ervan voldoen mogelijk niet aan de projectvereiste. Hier komt het schema in beeld. Wanneer je leunt op XML-gegevens, moet je ervoor zorgen dat alle gegevens geldig zijn volgens het gedefinieerde schema.
Het laatste wat je wilt, is ontdekken dat er gegevensfouten zijn opgetreden tijdens runtime, 500 regels diep in het midden van het script. Tegen die tijd kunnen er al onomkeerbare bewerkingen zijn uitgevoerd op het bestandssysteem en het register.
Dus, hoe kun je van tevoren controleren of de gegevens correct zijn? Laten we eerst naar enkele mogelijke fouttypen kijken.
Mogelijke fouten in XML-gegevens
Over het algemeen behoren fouten in XML-bestanden tot een van twee categorieën; metadatafouten en fouten in de gegevens zelf.
XML-metadatafouten
Dit bestand, MorePeople.xml hieronder, is perfect geldig qua syntaxis. Je kunt hieronder zien dat het bestand een enkel People-element heeft (het hoofdelement) met drie Person-elementen erin. Deze structuur is volkomen acceptabel. Toch bevat het een uitzondering, zie je het?
Maak je geen zorgen als je het niet zag, het verstopt zich gewoon. Het probleem zit in het eerste binnenste element:
Wat een Country had moeten zijn, was verkeerd gespeld, en Canada werd gedegradeerd tot een County.
Fouten in de XML-gegevens
Na het oplossen van het Country-probleem op MorePeople.xml, sloop er een ander probleem binnen:
De metagegevens, d.w.z. de elementen en attributen, zijn in orde. Dus wat is er mis? Deze keer is het probleem, opnieuw op de eerste regel Person , te vinden in een van de waarden. Iemand besloot dat ja een goed genoeg vervanging is voor true – maar code zoals hieronder zal falen om het eerste element te krijgen omdat het zoekt naar true, niet naar ja:
Het maken van een XML-schema
Nu je weet welke soorten fouten kunnen optreden, is het tijd om te laten zien hoe een schema-bestand helpt. De eerste stap is het maken van een voorbeeldgegevensbestand. Het voorbeeld kan het kleinste voorbeeld zijn en niets anders bevatten dan een enkel binnenste element. Voor de bovenstaande voorbeelden, laten we een voorbeeldbestand maken zoals dit Mensen.xml :
Maak nu een PowerShell-functie hieronder en gebruik deze met de voorbeeldgegevens om het .xsd-schema te maken.
Kopieer de functie naar je ISE of je favoriete Powershell-editor, laad deze in het geheugen en gebruik deze om het schema te maken. Met de geladen functie is de code om het schema te maken deze ene regel:
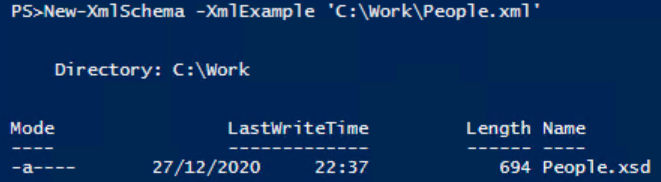
De resultaten tonen het pad naar het nieuw gemaakte schema:
Het gebruik van het schema-bestand om uw gegevens te valideren
Bekijk de locatie die hierboven is aangegeven. Als het .xsd-bestand daar staat, ben je op de juiste weg om de validatie in actie te zien. Gebruik voor de bevestigingsstap de onderstaande functie:
Laad de functie in het geheugen en gebruik deze om de MorePeople.xml te valideren aan de hand van de twee foutvoorbeelden. Gebruik de onderstaande opdracht om de validatie te triggeren:
De daadwerkelijke resultaten zijn afhankelijk van de inhoud van MorePeople.xml.
Laten we twee voorbeelden bekijken. Let op dat wanneer MorePeople.xml foutloos is, de bovenstaande functie True zal retourneren.

Als het bestand MorePeople.xml foutieve gegevens bevat (de sleutel Country verkeerd gespeld als County), zal de functie enkele foutdetails retourneren en False retourneren.

Zoals je kunt zien, is de fout die in de uitgebreide uitvoer wordt gespecificeerd zeer informatief: het verwijst naar het schuldige bestand en wijst naar het exacte onderdeel waar het probleem is opgetreden.
Fijnafstemming van het validatieschema
Laten we eens kijken naar het schemasbestand en vervolgens bekijken hoe we het nog beter kunnen maken.
Het schema dat standaard wordt gemaakt door New-XmlSchema is als volgt:
Het standaardschema hierboven is goed, maar niet perfect. Het heeft inderdaad de typfout met het attribuut Country opgemerkt. Maar als je het schema ongewijzigd laat, zullen eventuele andere verwachtingen die je hebt mogelijk niet worden gemeld als fouten door de validatie van Test-XmlBySchema. Laten we dit oplossen.
De tabel hieronder toont enkele gevallen die niet worden beschouwd als validatiefouten en onopgemerkt blijven door Test-XmlBySchema. In elke rij geeft de rechterkolom aan hoe u handmatig het schema kunt wijzigen om ondersteuning toe te voegen voor de benodigde bescherming.
A modified version of the schema file, with all protections added, is shown right after the table.
Toevoegen van instelling aan het standaardschema – voorbeelden
| Required Behavior | Relevant setting on the schema file |
| At least one Person element | Set the minOccurs value of the Person element to 1 |
| Make Name, Country and IsAdmin attributes mandatory | Add use=”required” to each of these attributes declaration |
| Allow only true/false values for IsAdmin | Set type=”xs:boolean” for the IsAdmin declaration |
| Allow only Country names between 3 and 40 characters | Use the xs:restriction (see detailed explanation after the schema text) |
Met de boolean beperking op zijn plaats voor het IsAdmin attribuut in het voorbeeld, moet de waarde ervan een kleine letter true of false zijn.
String Lengtevalidatie met xs:beperking
De validatie van de lengte van de tekenreeks is een beetje complex. Dus, hoewel het hierboven wordt getoond als onderdeel van het gewijzigde schema, verdient het een beetje meer aandacht.
Het oorspronkelijke schema-item voor het Country attribuut (nadat de use=”required” handmatig is toegevoegd), is als volgt:
Om de lengtebescherming toe te voegen, moet u het <xs:simpleType>-element toevoegen, en daarin de <xs:beperking base="xs:tekenreeks">. Deze beperking bevat op zijn beurt de vereiste limieten die zijn gedeclareerd op xs:minLengte en op xs:maxLengte.
Na al deze wijzigingen is de definitie van het laatste xs:attribuut element gegroeid van een enkele regel naar een reusachtige 8 regels knooppunt:
Als je hoofd niet tolde na de bovenstaande uitleg, heb je het recht verdiend om de validatie in actie te zien. Om dat te doen, laten we de waarde Canada opzettelijk verkorten tot een tweeledige lettergreep: Ca
Met de korte landnaam op zijn plaats, en MorePeople.xml opgeslagen, bent u klaar om de onderstaande validatieopdracht uit te voeren:
En de resultaten laten inderdaad zien dat het complexe schema zijn werk heeft gedaan:

XML-schemavalidatie kan complex worden en bijna elk patroon valideren dat je maar kunt bedenken, vooral wanneer het gecombineerd wordt met reguliere expressies.