













XML est partout. Malgré son utilisation agaçante de chevrons, le format XML est encore largement utilisé. Les fichiers de configuration, les flux RSS, les fichiers Office (le ‘x’ dans .docx) ne sont qu’une liste partielle. Utiliser PowerShell pour analyser des fichiers XML est une étape essentielle de votre parcours PowerShell.
Ce tutoriel vous montrera comment utiliser PowerShell pour analyser et valider des fichiers XML. Cela vous guidera de zéro à héros pour tous les aspects de l’obtention et de l’évaluation des données XML. Vous disposerez d’outils qui vous aideront à valider l’intégrité des données XML et à arrêter les données défectueuses dès l’entrée de vos scripts !
Prérequis
Pour suivre le matériel présenté, vous devez disposer de :
- PowerShell version 3.0 et supérieure. Les exemples ont été créés avec Windows PowerShell v5.1
- Notepad++, Visual Studio Code ou un autre éditeur de texte qui comprend XML.
Analyse des éléments XML avec PowerShell et Select-Xml
Commençons par couvrir l’une des façons les plus populaires et les plus faciles d’utiliser PowerShell pour analyser XML, c’est-à-dire avec Select-Xml. La cmdlet Select-Xml vous permet de fournir un fichier XML ou une chaîne XML ainsi qu’un « filtre » appelé XPath pour extraire des informations spécifiques.
XPath est une chaîne de noms d’éléments. Il utilise une syntaxe « chemin similaire » pour identifier et naviguer dans les nœuds d’un document XML.
Supposons que vous ayez un fichier XML avec un tas d’ordinateurs et que vous vouliez utiliser PowerShell pour analyser ce fichier XML. Chaque ordinateur a divers éléments comme le nom, l’adresse IP et un élément Inclure pour l’inclusion dans un rapport.
Un élément est une partie XML avec une balise d’ouverture et une balise de fermeture, éventuellement avec un peu de texte entre les deux, comme
<Name>SRV-01</Name>
Vous souhaitez utiliser PowerShell pour analyser ce fichier XML et obtenir les noms d’ordinateurs. Pour ce faire, vous pouvez utiliser la commande Select-Xml.
Dans le fichier ci-dessus, les noms des ordinateurs apparaissent dans le texte interne (InnerXML) de l’élément Name.
InnerXML est le texte entre les balises des deux éléments.
Pour trouver les noms des ordinateurs, vous fourniriez d’abord le XPath approprié (/Ordinateurs/Ordinateur/Nom). Cette syntaxe XPath ne renverrait que les nœuds Nom sous les éléments Ordinateur. Ensuite, pour obtenir uniquement le InnerXML de chaque élément Nom, accédez à la propriété Node.InnerXML sur chaque élément avec une boucle ForEach-Object.
Utilisation de PowerShell pour analyser les attributs XML avec Select-Xml
Abordons maintenant ce problème de recherche de noms d’ordinateurs sous un angle différent. Cette fois-ci, au lieu des descripteurs d’ordinateurs représentés par des éléments XML, ils sont représentés par des attributs XML.
Un attribut est une partie clé/valeur telle que
name="SRV-01". Les attributs apparaissent toujours à l’intérieur de la balise d’ouverture, juste après le nom de la balise.
Voici le fichier XML avec les descripteurs d’ordinateurs représentés par des attributs. Vous pouvez maintenant voir chaque descripteur comme un attribut plutôt qu’un élément.
Étant donné que chaque descripteur est un attribut cette fois-ci, ajustez légèrement le XPath pour ne trouver que les éléments Computer. Ensuite, en utilisant à nouveau la cmdlet ForEach-Object, trouvez la valeur de l’attribut name.
Et en effet, cela donne également les mêmes résultats : SRV-01, SRV-02 et SRV-03 :

Dans les deux cas, que vous lisiez des éléments ou des attributs, la syntaxe de Select-Xml est fastidieuse : elle vous oblige à utiliser le paramètre XPath, puis à rediriger le résultat vers une boucle, et enfin à rechercher les données sous la propriété Node.
Heureusement, PowerShell offre une façon plus pratique et intuitive de lire les fichiers XML. PowerShell vous permet de lire des fichiers XML et de les convertir en objets XML.
Articles connexes : Utiliser les accélérateurs de types de données PowerShell pour accélérer le codage
Conversion des chaînes XML en objets.
Une autre façon d’utiliser PowerShell pour analyser XML est de convertir ce XML en objets. Le moyen le plus simple de le faire est avec l’accélérateur de type [xml].
En préfixant les noms des variables avec [xml], PowerShell convertit le XML en texte brut en objets avec lesquels vous pouvez ensuite travailler.
Lecture des éléments d’objet XML
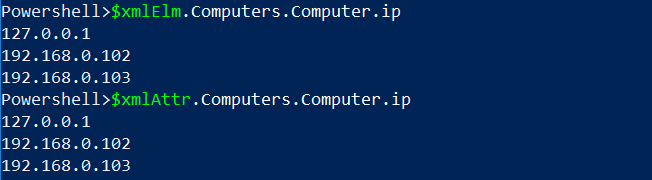
Maintenant, les variables $xmlElm et $xmlAttr sont toutes deux des objets XML vous permettant de référencer les propriétés via la notation par point. Peut-être avez-vous besoin de trouver l’adresse IP de chaque élément d’ordinateur. Étant donné que le fichier XML est un objet, vous pouvez le faire en référençant simplement l’élément IP.
À partir de la version 3.0 de PowerShell, l’objet XML obtient la valeur de l’attribut avec la même syntaxe utilisée pour lire le texte interne de l’élément. Par conséquent, les valeurs des adresses IP sont lues à partir du fichier d’attributs avec exactement la même syntaxe que pour le fichier d’éléments.
Lecture des attributs XML
En utilisant exactement la même notation par point, vous pouvez également lire les attributs XML malgré les différences de structure XML.
Les résultats ci-dessous montrent que les deux ont obtenu les mêmes données, chacun à partir de son fichier correspondant:
De plus, avec l’objet, une fois qu’il est chargé en mémoire, vous bénéficiez même de l’IntelliSense pour compléter automatiquement si vous utilisez PowerShell ISE. Par exemple, comme indiqué ci-dessous.
Itérer à travers les données XML
Une fois que vous parvenez à lire directement des fichiers XML en tant qu’objet XML (en tirant parti de l’accélérateur de type [xml]), vous disposez de toute la puissance des objets PowerShell.
Disons, par exemple, que vous devez parcourir tous les ordinateurs qui apparaissent dans le fichier XML avec l’attribut include= »true » pour vérifier leur statut de connexion. Le code ci-dessous montre comment cela peut être fait.
Ce script est:
- Lecture du fichier et conversion en objet XML.
- Itérer à travers les ordinateurs concernés pour obtenir leur statut de connexion.
- Enfin, envoyer l’objet de sortie du résultat au pipeline.
Et les résultats du script ci-dessus sont affichés ci-dessous:

Schémas XML
Dans la section précédente, vous avez vu deux fichiers XML différents représentant un ensemble de données de deux manières différentes. Ces manières sont appelées schémas XML. Un schéma XML définit les éléments constitutifs légaux d’un document XML spécifique:
- Les noms des éléments et des attributs pouvant apparaître dans ce document spécifique.
- Le nombre et l’ordre des éléments enfants.
- Les types de données pour les éléments et les attributs.
Le schéma définit essentiellement la structure du XML.
Validation des données XML
Un fichier XML peut avoir une syntaxe correcte (les éditeurs comme Notepad++ se plaindront sinon), mais ses données peuvent ne pas correspondre aux exigences du projet. C’est là que le schéma entre en jeu. Lorsque vous travaillez avec des données XML, vous devez vous assurer que toutes les données sont valides selon le schéma défini.
La dernière chose que vous voulez, c’est découvrir des erreurs de données pendant l’exécution, en plein milieu d’un script de 500 lignes. À ce moment-là, il aurait peut-être déjà effectué des opérations irréversibles sur le système de fichiers et le registre.
Alors, comment pouvez-vous vérifier à l’avance que les données sont correctes ? Voyons d’abord quelques types d’erreurs possibles.
Erreurs possibles dans les données XML
En général, les erreurs trouvées dans les fichiers XML appartiennent à l’une des deux catégories suivantes : les erreurs de métadonnées et les erreurs dans les données elles-mêmes.
Erreurs de métadonnées XML
Ce fichier MorePeople.xml ci-dessous est syntaxiquement parfaitement valide. Vous pouvez voir qu’il contient un seul élément People (l’élément racine) avec trois éléments Person à l’intérieur. Cette structure est tout à fait acceptable. Pourtant, il contient une exception, la voyez-vous ?
Ne vous inquiétez pas si vous ne l’avez pas vue, elle est juste cachée. Le problème se trouve dans le premier élément interne :
Ce qui aurait dû être un Country a été mal orthographié, et le Canada a été réduit à un County.
Erreurs dans les données XML
Après avoir corrigé le problème du Country sur MorePeople.xml, un autre problème s’est glissé :
Les métadonnées, c’est-à-dire les éléments et attributs, sont bons. Alors qu’est-ce qui ne va pas? Cette fois, le problème, encore une fois sur la première ligne Personne , se trouve dans l’un des valeurs. Quelqu’un a décidé que oui est un substitut suffisant pour vrai – mais le code ci-dessous échouera à obtenir le premier élément car il recherche vrai, et non pas oui :
Création d’un Schéma XML
Maintenant que vous connaissez les types d’erreurs qui peuvent survenir, il est temps de montrer comment un fichier de schéma aide. La première étape consiste à créer un fichier de données d’exemple. L’exemple peut être le plus petit exemple et ne contenir rien d’autre qu’un seul élément interne. Pour les exemples ci-dessus, créons un fichier d’exemple comme ceci Personnes.xml :
Maintenant, construisez une fonction PowerShell ci-dessous et utilisez-la avec les données d’exemple pour créer le schéma .xsd.
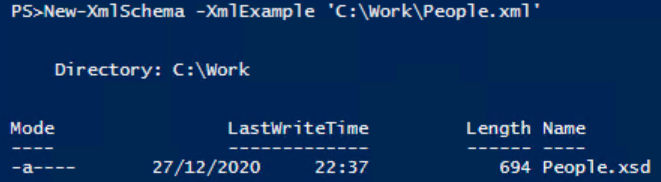
Copiez la fonction dans votre ISE ou votre éditeur Powershell préféré, chargez-la en mémoire et utilisez-la pour créer le schéma. Avec la fonction chargée, le code pour créer le schéma est cette ligne :
Les résultats afficheront le chemin vers le nouveau schéma créé:
Utiliser le Fichier de Schéma pour Valider Vos Données
Jetez un œil à l’emplacement spécifié par les résultats ci-dessus. Si le fichier .xsd est présent, vous êtes sur la bonne voie pour voir la validation en action. Pour l’étape de confirmation, utilisez la fonction ci-dessous :
Chargez la fonction en mémoire et utilisez-la pour valider le fichier MorePeople.xml à partir des deux exemples d’erreurs. Pour déclencher la validation, utilisez la commande ci-dessous :
Les résultats réels dépendent du contenu de MorePeople.xml.
Voyons deux exemples. Remarquez que lorsque le fichier MorePeople.xml ne contient pas d’erreurs, la fonction ci-dessus renverra Vrai.

Lorsque le fichier MorePeople.xml contient des données incorrectes (la clé Country est mal orthographiée en County), la fonction renverra des détails sur l’échec et retournera Faux.

Comme vous pouvez le voir, l’erreur spécifiée dans la sortie verbeuse est très informative : elle indique le fichier fautif et pointe exactement le composant où le problème s’est produit.
Peaufinage du schéma de validation
Jetons un œil au fichier de schéma, puis voyons comment nous pouvons l’améliorer encore.
Le schéma créé par New-XmlSchema par défaut est le suivant :
Le schéma par défaut ci-dessus est bon, mais pas parfait. En effet, il a détecté la faute de frappe avec l’attribut Country. Mais si vous laissez le schéma tel quel, dans le cas où d’autres attentes que vous pourriez avoir ne seraient pas respectées, ces problèmes ne seraient pas signalés comme des erreurs par la validation Test-XmlBySchema. Résolvons cela.
Le tableau ci-dessous présente quelques cas qui ne sont pas considérés comme des erreurs de validation et passeront inaperçus par Test-XmlBySchema. Sur chaque ligne, la colonne de droite montre comment modifier manuellement le schéma pour ajouter le support nécessaire à la protection requise.
A modified version of the schema file, with all protections added, is shown right after the table.
Ajout de paramètres au schéma par défaut – exemples
| Required Behavior | Relevant setting on the schema file |
| At least one Person element | Set the minOccurs value of the Person element to 1 |
| Make Name, Country and IsAdmin attributes mandatory | Add use=”required” to each of these attributes declaration |
| Allow only true/false values for IsAdmin | Set type=”xs:boolean” for the IsAdmin declaration |
| Allow only Country names between 3 and 40 characters | Use the xs:restriction (see detailed explanation after the schema text) |
Avec la restriction booléenne en place pour l’attribut IsAdmin dans l’exemple, sa valeur doit être en minuscules vrai ou faux.
Validation de la longueur de la chaîne avec xs:restriction
La validation de la longueur de la chaîne est un peu complexe. Donc, même si elle est indiquée ci-dessus comme faisant partie du schéma modifié, elle mérite un peu plus d’attention.
L’élément de schéma d’origine pour l’attribut Pays (après avoir ajouté manuellement le utilisation= »required »), est comme suit:
Pour ajouter la protection de longueur, vous devez ajouter l’élément <xs:simpleType>, et à l’intérieur, la <xs:restriction base="xs:string">. Cette restriction contient à son tour les limites requises déclarées sur xs:minLength et sur xs:minLength.
À la suite de tous ces changements, la déclaration finale de l’attribut xs:attribute est passée d’une seule ligne à un nœud géant de 8 lignes:
Si votre tête ne tourne pas après l’explication ci-dessus, vous avez gagné le droit de voir la validation en action. Pour ce faire, raccourcissons intentionnellement la valeur Canada à une syllabe de deux caractères : Ca
Avec le nom de pays court en place, et MorePeople.xml sauvegardé, vous êtes prêt à exécuter la commande de validation ci-dessous:
et les résultats montrent en effet que le schéma complexe a fait son travail :

La validation du schéma XML peut devenir complexe et valider à peu près n’importe quel motif auquel vous pouvez penser, surtout lorsqu’elle est combinée avec des expressions régulières.