













После того как платформа Java приняла шестимесячный цикл выпусков, мы оставили позади вечные вопросы, такие как “Умрёт ли Java в этом году?” или “Стоит ли переходить на новую версию?”. Несмотря на то, что прошло 28 лет с момента первого выпуска, Java продолжает процветать и остаётся популярным выбором в качестве основного языка программирования для многих новых проектов.
Java 17 была значительным вехой, но теперь Java 21 заняла место 17-й версии как следующий релиз с долгосрочной поддержкой (LTS). Для разработчиков на Java важно быть в курсе изменений и новых функций, которые представляет эта версия. Вдохновившись моим коллегой Дареком, который подробно описал функции Java 17 в своей статье, я решил обсудить JDK 21 аналогичным образом (я также проанализировал функции Java 23 в следующем материале, так что обязательно посмотрите).
JDK 21 включает в себя всего 15 JEP (JDK Enhancement Proposals). Вы можете ознакомиться со всем списком на официальном сайте Java. В этой статье я выделил несколько JEP Java 21, которые, на мой взгляд, заслуживают особого внимания. А именно:
- Шаблоны строк
- Последовательные коллекции
- Сопоставление шаблонов для
switchи Шаблоны записей - Виртуальные потоки
Без дальнейших задержек давайте углубимся в код и изучим эти обновления.
Шаблоны строк (Предварительный просмотр)
Функция шаблонов Spring все еще находится в режиме предварительного просмотра. Чтобы использовать ее, вам нужно добавить флаг --enable-preview к аргументам вашего компилятора. Тем не менее, я решил упомянуть об этом, несмотря на его статус предварительного просмотра. Почему? Потому что меня очень раздражает каждый раз, когда мне нужно написать сообщение журнала или SQL-выражение, которое содержит множество аргументов, или расшифровать, какой заполнитель будет заменен данным аргументом. И шаблоны Spring обещают помочь мне (и вам) с этим.
Как говорится в документации JEP, цель шаблонов Spring заключается в том, чтобы «упростить написание программ на Java, сделав легким выражение строк, которые содержат значения, вычисленные во время выполнения».
Давайте проверим, действительно ли это проще.
«Старый способ» заключался в использовании метода formatted() на объекте String:
var msg = "Log message param1: %s, pram2: %s".formatted(p1, p2);
Теперь с StringTemplate.Processor (STR) это выглядит так:
var interpolated = STR."Log message param1: \{p1}, param2: \{p2}";
С коротким текстом, как выше, выгода может быть не так заметна — но поверьте мне, когда дело доходит до больших текстовых блоков (JSON, SQL-выражения и т.д.), именованные параметры очень вам помогут.
Последовательные коллекции
Java 21 ввела новую иерархию коллекций Java. Посмотрите на диаграмму ниже и сравните ее с тем, что, вероятно, вы узнали во время занятий по программированию. Вы заметите, что было добавлено три новых структуры (выделенных зеленым цветом).
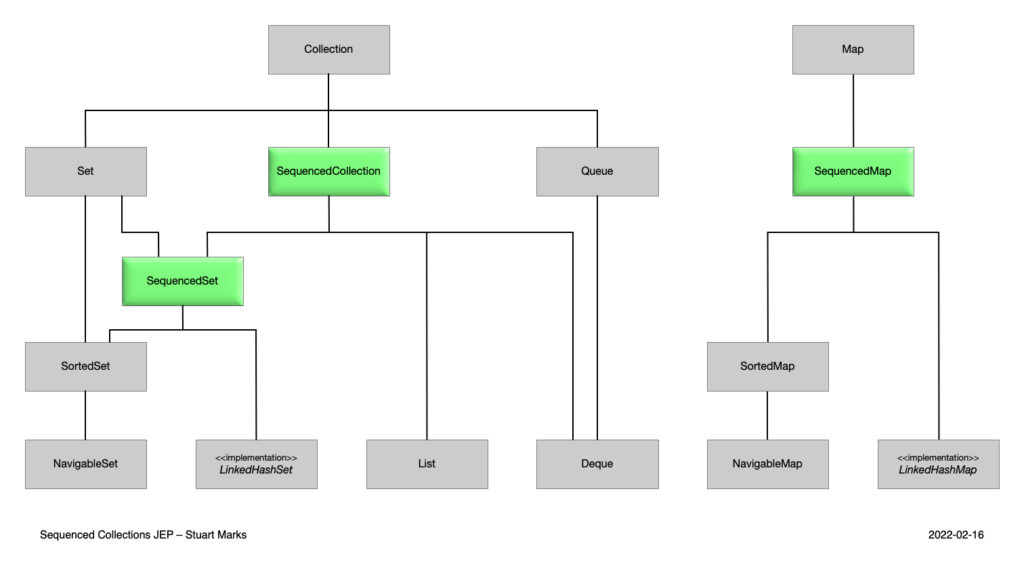 Источник изображения: JEP 431
Источник изображения: JEP 431
Последовательные коллекции представляют новый встроенный API Java, расширяющий операции над упорядоченными наборами данных. Этот API позволяет не только удобный доступ к первому и последнему элементам коллекции, но также обеспечивает эффективный обход, вставку на конкретные позиции и получение подпоследовательностей. Эти улучшения делают операции, зависящие от порядка элементов, более простыми и интуитивными, улучшая как производительность, так и читаемость кода при работе со списками и аналогичными структурами данных.
Это полный список интерфейса SequencedCollection:
public interface SequencedCollection<E> extends Collection<E> {
SequencedCollection<E> reversed();
default void addFirst(E e) {
throw new UnsupportedOperationException();
}
default void addLast(E e) {
throw new UnsupportedOperationException();
}
default E getFirst() {
return this.iterator().next();
}
default E getLast() {
return this.reversed().iterator().next();
}
default E removeFirst() {
var it = this.iterator();
E e = it.next();
it.remove();
return e;
}
default E removeLast() {
var it = this.reversed().iterator();
E e = it.next();
it.remove();
return e;
}
}Итак, теперь вместо:
var first = myList.stream().findFirst().get();
var anotherFirst = myList.get(0);
var last = myList.get(myList.size() - 1);Мы можем просто написать:
var first = sequencedCollection.getFirst();
var last = sequencedCollection.getLast();
var reversed = sequencedCollection.reversed();Это небольшое изменение, но на мой взгляд, это такая удобная и полезная функция.
Сопоставление шаблонов и шаблоны записей
Из-за схожести сопоставления шаблонов для switch и шаблонов записей, я опишу их вместе. Шаблоны записей — это новая функция: они были введены в Java 19 (в качестве предварительного просмотра). С другой стороны, сопоставление шаблонов для switch является своего рода продолжением расширенного выражения instanceof. Это вводит новую возможную синтаксис для операторов switch, который позволяет вам более легко выражать сложные запросы, ориентированные на данные.
Давайте забудем о основах ООП ради этого примера и вручную разберем объект сотрудника (employee — это класс POJO).
До Java 21 это выглядело так:
if (employee instanceof Manager e) {
System.out.printf("I’m dealing with manager of %s department%n", e.department);
} else if (employee instanceof Engineer e) {
System.out.printf("I’m dealing with %s engineer.%n", e.speciality);
} else {
throw new IllegalStateException("Unexpected value: " + employee);
}Что если бы мы могли избавиться от уродливого instanceof? Что ж, теперь мы можем, благодаря силе сопоставления шаблонов в Java 21:
switch (employee) {
case Manager m -> printf("Manager of %s department%n", m.department);
case Engineer e -> printf("I%s engineer.%n", e.speciality);
default -> throw new IllegalStateException("Unexpected value: " + employee);
}Говоря об операторе switch, мы также можем обсудить функцию шаблонов записей. При работе с записью Java, она позволяет нам делать гораздо больше, чем стандартный класс Java:
switch (shape) { // shape is a record
case Rectangle(int a, int b) -> System.out.printf("Area of rectangle [%d, %d] is: %d.%n", a, b, shape.calculateArea());
case Square(int a) -> System.out.printf("Area of square [%d] is: %d.%n", a, shape.calculateArea());
default -> throw new IllegalStateException("Unexpected value: " + shape);
}Как показывает код, с этим синтаксисом поля записи легко доступны. Более того, мы можем добавить некоторую дополнительную логику в наши операторы case:
switch (shape) {
case Rectangle(int a, int b) when a < 0 || b < 0 -> System.out.printf("Incorrect values for rectangle [%d, %d].%n", a, b);
case Square(int a) when a < 0 -> System.out.printf("Incorrect values for square [%d].%n", a);
default -> System.out.println("Created shape is correct.%n");
}Мы можем использовать аналогичный синтаксис для операторов if. Также в следующем примере мы видим, что шаблоны записей также работают для вложенных записей:
if (r instanceof Rectangle(ColoredPoint(Point p, Color c),
ColoredPoint lr)) {
//sth
}Виртуальные потоки
Функция виртуальных потоков, вероятно, является самой актуальной среди всех новшеств Java 21 — или, по крайней мере, одной из тех, чего ждали разработчики Java. Как говорится в документации JEP (ссылка в предыдущем предложении), одной из целей виртуальных потоков было «обеспечить возможность масштабирования серверных приложений, написанных в простом стиле поток на запрос, с почти оптимальным использованием аппаратных ресурсов». Однако означает ли это, что мы должны мигрировать наш весь код, который использует java.lang.Thread?
Сначала давайте рассмотрим проблему, существовавшую до Java 21 (фактически, практически с первого релиза Java). Мы можем приблизительно оценить, что один java.lang.Thread потребляет (в зависимости от ОС и конфигурации) около 2 до 8 МБ памяти. Однако важно отметить, что один поток Java сопоставляется 1:1 с потоком ядра. Для простых веб-приложений, которые используют подход «один поток на запрос», мы можем легко рассчитать, что либо нашу машину «убьют», когда трафик увеличится (она не сможет справиться с нагрузкой), либо нам придется приобрести устройство с большим объемом ОЗУ, и в результате наши счета в AWS возрастут.
Конечно, виртуальные потоки не являются единственным способом решения этой проблемы. У нас есть асинхронное программирование (фреймворки, такие как WebFlux, или нативный API Java, такой как CompletableFuture). Однако по какой-то причине — возможно, из-за «недружелюбного API» или высокой входной планки — эти решения не так популярны.
Виртуальные потоки не контролируются и не планируются операционной системой. Вместо этого их планирование осуществляется JVM. В то время как реальные задачи должны выполняться в платформенном потоке, JVM использует так называемые “переносные” потоки, по сути, платформенные потоки, для “переноса” любого виртуального потока, когда он готов к выполнению. Виртуальные потоки разработаны как легковесные и занимают значительно меньше памяти, чем стандартные платформенные потоки.
Диаграмма ниже показывает, как Виртуальные потоки связаны с платформенными и ОС потоками:
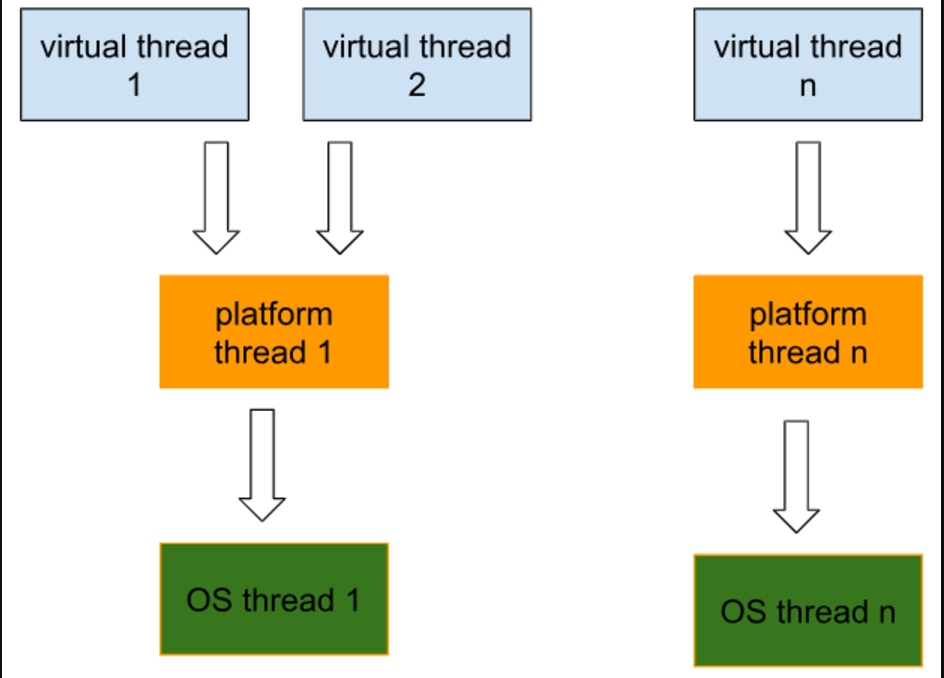
Итак, чтобы увидеть, как Виртуальные потоки используются Платформенными потоками, давайте запустим код, который стартует (1 + количество процессоров в машине, в моем случае 8 ядер) виртуальных потоков.
var numberOfCores = 8; //
final ThreadFactory factory = Thread.ofVirtual().name("vt-", 0).factory();
try (var executor = Executors.newThreadPerTaskExecutor(factory)) {
IntStream.range(0, numberOfCores + 1)
.forEach(i -> executor.submit(() -> {
var thread = Thread.currentThread();
System.out.println(STR."[\{thread}] VT number: \{i}");
try {
sleep(Duration.ofSeconds(1L));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}));
}Вывод выглядит следующим образом:
[VirtualThread[#29,vt-6]/runnable@ForkJoinPool-1-worker-7] VT number: 6
[VirtualThread[#26,vt-4]/runnable@ForkJoinPool-1-worker-5] VT number: 4
[VirtualThread[#30,vt-7]/runnable@ForkJoinPool-1-worker-8] VT number: 7
[VirtualThread[#24,vt-2]/runnable@ForkJoinPool-1-worker-3] VT number: 2
[VirtualThread[#23,vt-1]/runnable@ForkJoinPool-1-worker-2] VT number: 1
[VirtualThread[#27,vt-5]/runnable@ForkJoinPool-1-worker-6] VT number: 5
[VirtualThread[#31,vt-8]/runnable@ForkJoinPool-1-worker-6] VT number: 8
[VirtualThread[#25,vt-3]/runnable@ForkJoinPool-1-worker-4] VT number: 3
[VirtualThread[#21,vt-0]/runnable@ForkJoinPool-1-worker-1] VT number: 0Итак, ForkJonPool-1-worker-X Платформенные потоки являются нашими переносными потоками, которые управляют нашими виртуальными потоками. Мы наблюдаем, что Виртуальные потоки номер 5 и 8 используют один и тот же переносной поток номер 6.
Последнее, что я хочу показать о Виртуальных потоках, это как они могут помочь вам с блокирующими операциями ввода-вывода.
Когда Виртуальный поток сталкивается с блокирующей операцией, такой как задачи ввода-вывода, JVM эффективно отсоединяет его от основного физического потока (переносного потока). Это отсоединение критично, поскольку оно освобождает переносной поток для выполнения других Виртуальных потоков, вместо того чтобы простаивать в ожидании завершения блокирующей операции. В результате один переносной поток может мультиплексировать множество Виртуальных потоков, количество которых может достигать тысяч или даже миллионов, в зависимости от доступной памяти и характера выполняемых задач.
Давайте попробуем симулировать это поведение. Для этого мы заставим наш код использовать только одно ядро ЦП, с всего 2 виртуальными потоками — для большей ясности.
System.setProperty("jdk.virtualThreadScheduler.parallelism", "1");
System.setProperty("jdk.virtualThreadScheduler.maxPoolSize", "1");
System.setProperty("jdk.virtualThreadScheduler.minRunnable", "1");Поток 1:
Thread v1 = Thread.ofVirtual().name("long-running-thread").start(
() -> {
var thread = Thread.currentThread();
while (true) {
try {
Thread.sleep(250L);
System.out.println(STR."[\{thread}] - Handling http request ....");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
);Поток 2:
Thread v2 = Thread.ofVirtual().name("entertainment-thread").start(
() -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
var thread = Thread.currentThread();
System.out.println(STR."[\{thread}] - Executing when 'http-thread' hit 'sleep' function");
}
);Выполнение:
v1.join(); v2.join();Результат:
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#23,entertainment-thread]/runnable@ForkJoinPool-1-worker-1] - Executing when 'http-thread' hit 'sleep' function
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....Мы видим, что оба Виртуальных Потока (long-running-thread и entertainment-thread) обрабатываются только одним Платформенным Потоком, который называется ForkJoinPool-1-worker-1.
Подводя итог, эту модель позволяет Java-приложениям достигать высокого уровня параллелизма и масштабируемости с гораздо меньшими накладными расходами по сравнению с традиционными моделями потоков, где каждый поток прямо отображается на один операционный системный поток. Следует отметить, что виртуальные потоки — это обширная тема, и то, что я описал, составляет лишь малую долю. Я настоятельно рекомендую вам узнать больше о планировании, закрепленных потоках и внутренностях виртуальных потоков.
Резюме: Будущее языка программирования Java
Описанные выше функции я считаю самыми важными в Java 21. Большинство из них не настолько революционны, как некоторые вещи, представленные в JDK 17, но они все равно очень полезны и приятны как изменения, улучшающие качество жизни (Quality of Life).
Тем не менее, не стоит игнорировать и другие улучшения JDK 21 — я настоятельно рекомендую вам проанализировать полный список и глубже изучить все функции. Например, одной из вещей, которую я считаю особенно примечательной, является API векторов, который позволяет выполнять векторные вычисления на некоторых поддерживаемых архитектурах ЦП — что было невозможно ранее. В настоящее время он все еще находится на стадии инкубатора/экспериментальной фазы (поэтому я не выделял его более подробно здесь), но он обещает большие перспективы для будущего Java.
В целом, достижения Java в различных областях сигнализируют о постоянной приверженности команды к улучшению эффективности и производительности в приложениях с высокой нагрузкой.
Source:
https://dzone.com/articles/java-21-features-a-detailed-look