













Depuis que la plateforme Java a adopté un cycle de publication de six mois, nous avons dépassé les questions perpétuelles telles que « Java va-t-il mourir cette année ? » ou « Vaut-il la peine de migrer vers la nouvelle version ? ». Malgré 28 ans depuis sa première sortie, Java continue de prospérer et reste un choix populaire comme langage de programmation principal pour de nombreux nouveaux projets.
Java 17 a été une étape importante, mais Java 21 a maintenant pris la place de Java 17 en tant que prochaine version de support à long terme (LTS). Il est essentiel pour les développeurs Java de rester informés des changements et des nouvelles fonctionnalités que cette version apporte. Inspiré par mon collègue Darek, qui a détaillé les fonctionnalités de Java 17 dans son article, j’ai décidé de discuter de JDK 21 de manière similaire (j’ai également analysé les fonctionnalités de Java 23 dans un article de suivi, alors n’hésitez pas à le consulter aussi).
JDK 21 comprend un total de 15 JEP (Propositions d’Amélioration de JDK). Vous pouvez consulter la liste complète sur le site officiel de Java. Dans cet article, je vais mettre en avant plusieurs JEPs de Java 21 que je considère particulièrement remarquables. À savoir :
- Modèles de Chaînes
- Collections Séquencées
- Correspondance de motifs pour
switchet Modèles d’enregistrement - Threads virtuels
Sans plus tarder, plongeons dans le code et explorons ces mises à jour.
Modèles de chaînes (Aperçu)
La fonctionnalité des modèles Spring est toujours en mode aperçu. Pour l’utiliser, vous devez ajouter le drapeau --enable-preview à vos arguments de compilateur. Cependant, j’ai décidé de la mentionner malgré son statut d’aperçu. Pourquoi ? Parce que je suis très irrité chaque fois que je dois écrire un message de journal ou une instruction SQL contenant de nombreux arguments ou déchiffrer quel espace réservé sera remplacé par un argument donné. Et les modèles Spring promettent de m’aider (et de vous aider) avec cela.
Comme le dit la documentation JEP, l’objectif des modèles Spring est de « simplifier l’écriture de programmes Java en facilitant l’expression de chaînes qui incluent des valeurs calculées à l’exécution. »
Vérifions si c’est vraiment plus simple.
La « vieille méthode » consisterait à utiliser la méthode formatted() sur un objet String :
var msg = "Log message param1: %s, pram2: %s".formatted(p1, p2);
Maintenant, avec StringTemplate.Processor (STR), cela ressemble à ceci :
var interpolated = STR."Log message param1: \{p1}, param2: \{p2}";
Avec un texte court comme celui-ci, le bénéfice peut ne pas être si visible — mais croyez-moi, quand il s’agit de grands blocs de texte (JSON, instructions SQL, etc.), les paramètres nommés vous aideront beaucoup.
Collections séquencées
Java 21 a introduit une nouvelle hiérarchie de collections Java. Regardez le diagramme ci-dessous et comparez-le à ce que vous avez probablement appris lors de vos cours de programmation. Vous remarquerez que trois nouvelles structures ont été ajoutées (mise en évidence par la couleur verte).
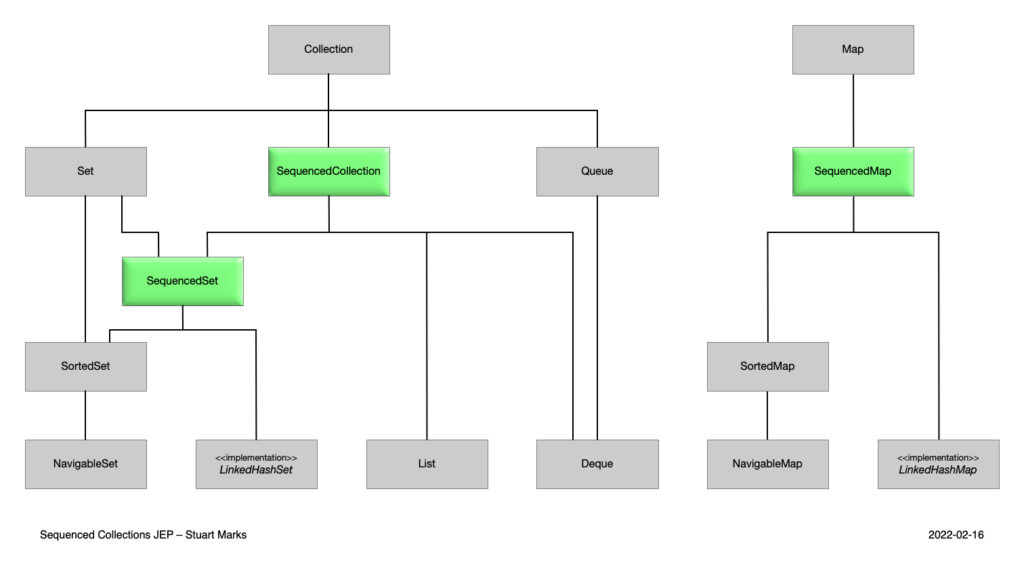 Source de l’image : JEP 431
Source de l’image : JEP 431
Les collections séquencées introduisent une nouvelle API Java intégrée, améliorant les opérations sur les ensembles de données ordonnées. Cette API permet non seulement un accès pratique aux premiers et derniers éléments d’une collection, mais elle permet également une traversal efficace, l’insertion à des positions spécifiques, et la récupération de sous-séquences. Ces améliorations simplifient et rendent plus intuitives les opérations qui dépendent de l’ordre des éléments, améliorant à la fois les performances et la lisibilité du code lors du travail avec des listes et des structures de données similaires.
Ceci est la liste complète de l’interface SequencedCollection:
public interface SequencedCollection<E> extends Collection<E> {
SequencedCollection<E> reversed();
default void addFirst(E e) {
throw new UnsupportedOperationException();
}
default void addLast(E e) {
throw new UnsupportedOperationException();
}
default E getFirst() {
return this.iterator().next();
}
default E getLast() {
return this.reversed().iterator().next();
}
default E removeFirst() {
var it = this.iterator();
E e = it.next();
it.remove();
return e;
}
default E removeLast() {
var it = this.reversed().iterator();
E e = it.next();
it.remove();
return e;
}
}Donc, maintenant, au lieu de:
var first = myList.stream().findFirst().get();
var anotherFirst = myList.get(0);
var last = myList.get(myList.size() - 1);Nous pouvons simplement écrire:
var first = sequencedCollection.getFirst();
var last = sequencedCollection.getLast();
var reversed = sequencedCollection.reversed();C’est un petit changement, mais à mon humble avis, c’est une fonctionnalité si pratique et utilisable.
Correspondance de modèles et modèles d’enregistrement
En raison de la similarité entre le Correspondance de Modèles pour switch et les Modèles d’Enregistrement, je vais les décrire ensemble. Les modèles d’enregistrement sont une nouvelle fonctionnalité : ils ont été introduits dans Java 19 (en tant qu’aperçu). D’autre part, la Correspondance de Modèles pour switch est en quelque sorte une continuation de l’ expression instanceof étendue. Cela apporte une nouvelle syntaxe possible pour les instructions switch qui vous permet d’exprimer des requêtes orientées données plus facilement.
Oublions les bases de la POO pour les besoins de cet exemple et déconstruisons manuellement l’objet employé (employee est une classe POJO).
Avant Java 21, cela ressemblait à ceci :
if (employee instanceof Manager e) {
System.out.printf("I’m dealing with manager of %s department%n", e.department);
} else if (employee instanceof Engineer e) {
System.out.printf("I’m dealing with %s engineer.%n", e.speciality);
} else {
throw new IllegalStateException("Unexpected value: " + employee);
}Que se passerait-il si nous pouvions nous débarrasser du vilain instanceof ? Eh bien, maintenant nous pouvons, grâce à la puissance de la Correspondance de Modèles de Java 21 :
switch (employee) {
case Manager m -> printf("Manager of %s department%n", m.department);
case Engineer e -> printf("I%s engineer.%n", e.speciality);
default -> throw new IllegalStateException("Unexpected value: " + employee);
}En parlant de l’instruction switch, nous pouvons également discuter de la fonctionnalité des Modèles d’Enregistrement. Lorsqu’il s’agit d’un Enregistrement Java, cela nous permet de faire beaucoup plus qu’avec une classe Java standard :
switch (shape) { // shape is a record
case Rectangle(int a, int b) -> System.out.printf("Area of rectangle [%d, %d] is: %d.%n", a, b, shape.calculateArea());
case Square(int a) -> System.out.printf("Area of square [%d] is: %d.%n", a, shape.calculateArea());
default -> throw new IllegalStateException("Unexpected value: " + shape);
}Comme le montre le code, avec cette syntaxe, les champs d’enregistrement sont facilement accessibles. De plus, nous pouvons ajouter une logique supplémentaire à nos instructions de cas :
switch (shape) {
case Rectangle(int a, int b) when a < 0 || b < 0 -> System.out.printf("Incorrect values for rectangle [%d, %d].%n", a, b);
case Square(int a) when a < 0 -> System.out.printf("Incorrect values for square [%d].%n", a);
default -> System.out.println("Created shape is correct.%n");
}Nous pouvons utiliser une syntaxe similaire pour les instructions if. De plus, dans l’exemple ci-dessous, nous pouvons voir que les Modèles d’Enregistrement fonctionnent également pour les enregistrements imbriqués :
if (r instanceof Rectangle(ColoredPoint(Point p, Color c),
ColoredPoint lr)) {
//sth
}Threads Virtuels
La fonctionnalité des Threads Virtuels est probablement la plus en vogue parmi toutes les nouveautés de Java 21 — ou du moins, c’est l’une des attentes les plus importantes des développeurs Java. Comme le dit la documentation JEP (liée dans la phrase précédente), l’un des objectifs des threads virtuels était de « permettre aux applications serveur écrites dans le style simple thread-par-requête de s’adapter avec une utilisation matérielle quasi optimale ». Cependant, cela signifie-t-il que nous devrions migrer tout notre code qui utilise java.lang.Thread?
Tout d’abord, examinons le problème avec l’approche qui existait avant Java 21 (en fait, pratiquement depuis la première version de Java). Nous pouvons estimer qu’un java.lang.Thread consomme (en fonction du système d’exploitation et de la configuration) environ 2 à 8 Mo de mémoire. Cependant, ce qui est important ici, c’est qu’un Thread Java est mappé 1:1 à un thread du noyau. Pour les applications web simples qui utilisent une approche « un thread par requête », nous pouvons facilement calculer que soit notre machine sera « tuée » lorsque le trafic augmentera (elle ne pourra pas gérer la charge), soit nous serons contraints d’acheter un appareil avec plus de RAM, et nos factures AWS augmenteront en conséquence.
Bien sûr, les threads virtuels ne sont pas la seule manière de gérer ce problème. Nous avons la programmation asynchrone (des frameworks comme WebFlux ou l’API Java native comme CompletableFuture). Cependant, pour une raison quelconque — peut-être à cause de l’« API peu conviviale » ou d’un seuil d’entrée élevé — ces solutions ne sont pas si populaires.
Les threads virtuels ne sont pas supervisés ni programmés par le système d’exploitation. Au contraire, leur planification est gérée par la JVM. Alors que les tâches réelles doivent être exécutées dans un thread de plateforme, la JVM utilise ce qu’on appelle des threads porteurs — essentiellement des threads de plateforme — pour « porter » tout thread virtuel lorsqu’il est prêt à être exécuté. Les threads virtuels sont conçus pour être légers et utilisent beaucoup moins de mémoire que les threads de plateforme standard.
Le diagramme ci-dessous montre comment les threads virtuels sont connectés aux threads de plateforme et aux threads du système d’exploitation :
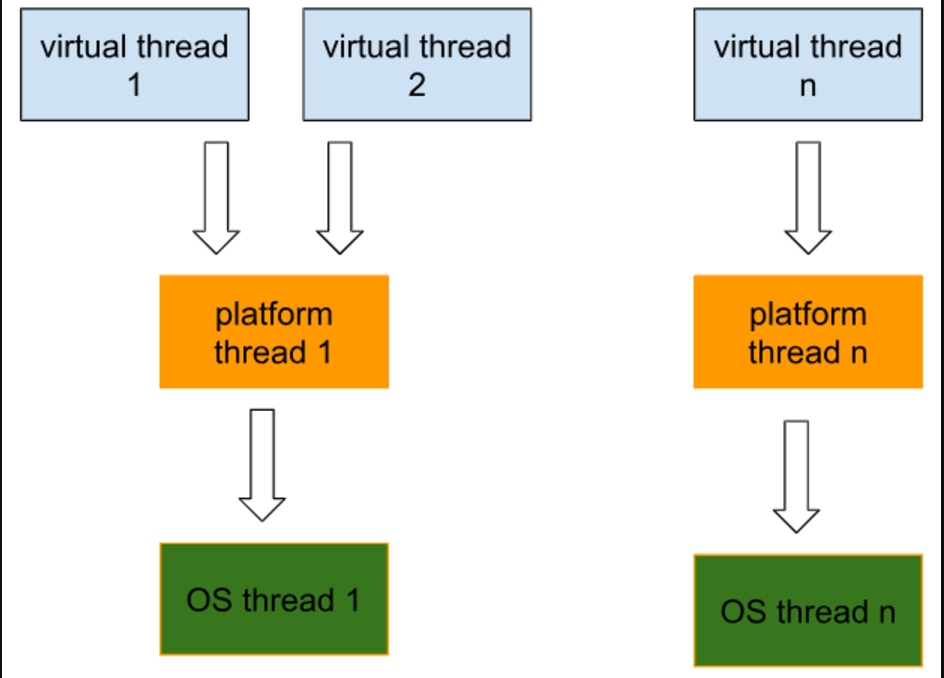
Pour voir comment les threads virtuels sont utilisés par les threads de plateforme, exécutons un code qui démarre (1 + le nombre de CPU que la machine possède, dans mon cas 8 cœurs) des threads virtuels.
var numberOfCores = 8; //
final ThreadFactory factory = Thread.ofVirtual().name("vt-", 0).factory();
try (var executor = Executors.newThreadPerTaskExecutor(factory)) {
IntStream.range(0, numberOfCores + 1)
.forEach(i -> executor.submit(() -> {
var thread = Thread.currentThread();
System.out.println(STR."[\{thread}] VT number: \{i}");
try {
sleep(Duration.ofSeconds(1L));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}));
}La sortie ressemble à ceci :
[VirtualThread[#29,vt-6]/runnable@ForkJoinPool-1-worker-7] VT number: 6
[VirtualThread[#26,vt-4]/runnable@ForkJoinPool-1-worker-5] VT number: 4
[VirtualThread[#30,vt-7]/runnable@ForkJoinPool-1-worker-8] VT number: 7
[VirtualThread[#24,vt-2]/runnable@ForkJoinPool-1-worker-3] VT number: 2
[VirtualThread[#23,vt-1]/runnable@ForkJoinPool-1-worker-2] VT number: 1
[VirtualThread[#27,vt-5]/runnable@ForkJoinPool-1-worker-6] VT number: 5
[VirtualThread[#31,vt-8]/runnable@ForkJoinPool-1-worker-6] VT number: 8
[VirtualThread[#25,vt-3]/runnable@ForkJoinPool-1-worker-4] VT number: 3
[VirtualThread[#21,vt-0]/runnable@ForkJoinPool-1-worker-1] VT number: 0Ainsi, ForkJonPool-1-worker-X Les threads de plateforme sont nos threads porteurs qui gèrent nos threads virtuels. Nous observons que les threads virtuels numéro 5 et 8 utilisent le même thread porteur numéro 6.
La dernière chose à propos des threads virtuels que je veux vous montrer est comment ils peuvent vous aider avec les opérations d’E/S bloquantes.
Chaque fois qu’un thread virtuel rencontre une opération bloquante, comme des tâches d’E/S, la JVM le détache efficacement du thread physique sous-jacent (le thread porteur). Ce détachement est essentiel car il libère le thread porteur pour exécuter d’autres threads virtuels au lieu d’être inactif, attendant la fin de l’opération bloquante. En conséquence, un seul thread porteur peut multiplexe de nombreux threads virtuels, qui pourraient atteindre des milliers voire des millions, en fonction de la mémoire disponible et de la nature des tâches effectuées.
Essayons de simuler ce comportement. Pour ce faire, nous allons forcer notre code à n’utiliser qu’un seul cœur de CPU, avec seulement 2 threads virtuels — pour plus de clarté.
System.setProperty("jdk.virtualThreadScheduler.parallelism", "1");
System.setProperty("jdk.virtualThreadScheduler.maxPoolSize", "1");
System.setProperty("jdk.virtualThreadScheduler.minRunnable", "1");Thread 1:
Thread v1 = Thread.ofVirtual().name("long-running-thread").start(
() -> {
var thread = Thread.currentThread();
while (true) {
try {
Thread.sleep(250L);
System.out.println(STR."[\{thread}] - Handling http request ....");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
);Thread 2:
Thread v2 = Thread.ofVirtual().name("entertainment-thread").start(
() -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
var thread = Thread.currentThread();
System.out.println(STR."[\{thread}] - Executing when 'http-thread' hit 'sleep' function");
}
);Exécution:
v1.join(); v2.join();Résultat:
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#23,entertainment-thread]/runnable@ForkJoinPool-1-worker-1] - Executing when 'http-thread' hit 'sleep' function
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....Nous observons que les deux Threads Virtuels (long-running-thread et entertainment-thread) sont gérés par un seul Thread de Plateforme, qui est ForkJoinPool-1-worker-1.
Pour résumer, ce modèle permet aux applications Java d’atteindre de hauts niveaux de simultanéité et d’évolutivité avec beaucoup moins de surcharge que les modèles de threads traditionnels, où chaque thread correspond directement à un seul thread du système d’exploitation. Il convient de noter que les threads virtuels sont un sujet vaste, et ce que j’ai décrit n’est qu’une petite fraction. Je vous encourage vivement à en apprendre davantage sur la planification, les threads épinglés et les détails internes des Threads Virtuels.
Résumé : L’avenir du langage de programmation Java
Les fonctionnalités décrites ci-dessus sont celles que je considère comme les plus importantes dans Java 21. La plupart d’entre elles ne sont pas aussi révolutionnaires que certaines des choses introduites dans JDK 17, mais elles restent très utiles et apportent de bons changements en termes de qualité de vie (QOL).
Cependant, vous ne devriez pas négliger les autres améliorations de JDK 21 non plus — je vous encourage vivement à analyser la liste complète et à explorer toutes les fonctionnalités plus en détail. Par exemple, une chose que je trouve particulièrement remarquable est l’API Vector, qui permet des calculs vectoriels sur certaines architectures CPU prises en charge — ce qui n’était pas possible auparavant. Actuellement, elle est encore en phase d’incubation/statut expérimental (c’est pourquoi je ne l’ai pas mise en avant plus en détail ici), mais elle promet beaucoup pour l’avenir de Java.
Dans l’ensemble, les avancées réalisées par Java dans divers domaines signalent l’engagement continu de l’équipe à améliorer l’efficacité et la performance des applications très exigeantes.
Source:
https://dzone.com/articles/java-21-features-a-detailed-look