













자바 플랫폼이 6개월 출시 주기를 채택한 이후, “올해 자바가 사라질까?” 또는 “새 버전으로 이전할 가치가 있을까?”와 같은 영구적인 질문을 넘어섰습니다. 처음 출시된 지 28년이 지난 지금도 자바는 계속해서 번창하며 많은 새로운 프로젝트의 주요 프로그래밍 언어로서 인기를 유지하고 있습니다.
자바 17은 중요한 이정표였지만, 이제 자바 21이 다음 장기 지원 릴리스(LTS)로 자바 17의 자리를 차지했습니다. 자바 개발자들은 이 버전이 가져오는 변화와 새로운 기능에 대해 지속적으로 정보를 얻는 것이 필수적입니다. 자바 17 기능에 대해 자세히 설명한 제 동료 다렉에게 영감을 받아, 저도 비슷한 방식으로 JDK 21에 대해 논의하기로 했습니다(후속 기사에서 자바 23 기능도 분석했으니, 그것도 확인해 보세요).
JDK 21은 총 15개의 JEP(JDK 개선 제안)를 포함하고 있습니다. 공식 자바 사이트에서 전체 목록을 확인할 수 있습니다. 이 기사에서는 특히 주목할 만한 몇 가지 자바 21 JEP를 강조하겠습니다. 즉:
더 이상 지체하지 않고, 코드를 살펴보고 이러한 업데이트를 탐구해 봅시다.
문자열 템플릿 (미리보기)
스프링 템플릿 기능은 여전히 미리보기 모드에 있습니다. 사용하려면 컴파일러 인수에 --enable-preview 플래그를 추가해야 합니다. 하지만 미리보기 상태에도 불구하고 언급하기로 결정했습니다. 왜냐하면 많은 인수가 포함된 로그 메시지나 SQL 문을 작성해야 할 때마다 매우 짜증이 나기 때문입니다. 어떤 자리 표시자가 주어진 인수로 대체될지 해독하는 것도요. 그리고 스프링 템플릿은 저(그리고 여러분)를 도와줄 것을 약속합니다.
JEP 문서에 따르면 스프링 템플릿의 목적은 “런타임에 계산된 값을 포함하는 문자열을 쉽게 표현할 수 있게 하여 자바 프로그램의 작성을 간소화하는 것”입니다.
이것이 정말 더 간단한지 확인해 봅시다.
“구식 방법”은 문자열 객체에서 formatted() 메서드를 사용하는 것이었습니다:
var msg = "Log message param1: %s, pram2: %s".formatted(p1, p2);
이제 StringTemplate.Processor (STR)를 사용하면 이렇게 보입니다:
var interpolated = STR."Log message param1: \{p1}, param2: \{p2}";
위와 같은 짧은 텍스트에서는 그 이점이 그리 뚜렷하지 않을 수 있지만, 믿어보세요. 큰 텍스트 블록(예: JSON, SQL 문 등)에서는 이름 있는 매개변수가 많은 도움을 줄 것입니다.
순서가 있는 컬렉션
Java 21은 새로운 Java 컬렉션 계층을 도입했습니다. 아래 다이어그램을 살펴보고 프로그래밍 수업에서 배운 내용을 비교해 보세요. 세 가지 새로운 구조가 추가된 것을 확인할 수 있습니다(녹색으로 강조 표시됨).
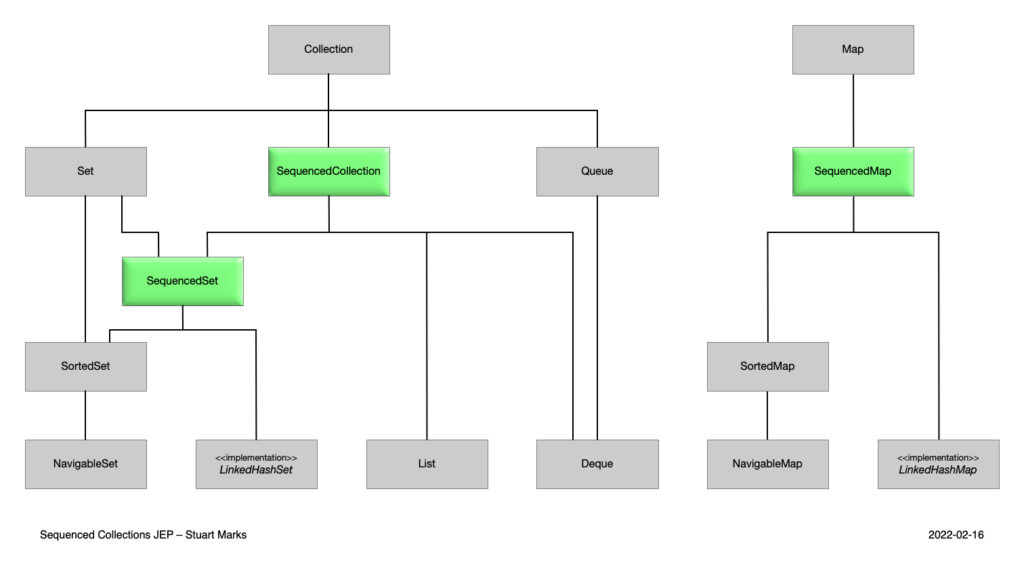 이미지 출처: JEP 431
이미지 출처: JEP 431
순차 컬렉션은 새로운 내장 Java API를 도입하여 정렬된 데이터 집합에 대한 작업을 향상시킵니다. 이 API는 컬렉션의 첫 번째 및 마지막 요소에 대한 편리한 접근을 허용할 뿐만 아니라 특정 위치에서의 효율적인 탐색, 삽입 및 하위 시퀀스 검색을 가능하게 합니다. 이러한 향상은 요소의 순서에 의존하는 작업을 더 간단하고 직관적으로 만들어 주며, 리스트 및 유사한 데이터 구조 작업 시 성능과 코드 가독성을 모두 향상시킵니다.
다음은 SequencedCollection 인터페이스의 전체 목록입니다:
public interface SequencedCollection<E> extends Collection<E> {
SequencedCollection<E> reversed();
default void addFirst(E e) {
throw new UnsupportedOperationException();
}
default void addLast(E e) {
throw new UnsupportedOperationException();
}
default E getFirst() {
return this.iterator().next();
}
default E getLast() {
return this.reversed().iterator().next();
}
default E removeFirst() {
var it = this.iterator();
E e = it.next();
it.remove();
return e;
}
default E removeLast() {
var it = this.reversed().iterator();
E e = it.next();
it.remove();
return e;
}
}이제 대신에:
var first = myList.stream().findFirst().get();
var anotherFirst = myList.get(0);
var last = myList.get(myList.size() - 1);우리는 그냥 쓸 수 있습니다:
var first = sequencedCollection.getFirst();
var last = sequencedCollection.getLast();
var reversed = sequencedCollection.reversed();이것은 작은 변화이지만, 제 생각에는 정말 편리하고 사용하기 좋은 기능입니다.
패턴 매칭 및 레코드 패턴
패턴 매칭의 유사성 때문에 switch와 레코드 패턴을 함께 설명하겠습니다. 레코드 패턴은 새로운 기능으로, 자바 19에서(미리보기로) 도입되었습니다. 반면, switch에 대한 패턴 매칭은 확장된 instanceof 표현식의 연속이라고 할 수 있습니다. 이는 복잡한 데이터 중심 쿼리를 더 쉽게 표현할 수 있게 해주는 새로운 구문을 switch 문에 도입합니다.
이 예제를 위해 OOP의 기본 개념은 잊고 employee 객체를 수동으로 분해해 보겠습니다(코드에서 employee는 POJO 클래스입니다).
자바 21 이전에는 이렇게 생겼습니다:
if (employee instanceof Manager e) {
System.out.printf("I’m dealing with manager of %s department%n", e.department);
} else if (employee instanceof Engineer e) {
System.out.printf("I’m dealing with %s engineer.%n", e.speciality);
} else {
throw new IllegalStateException("Unexpected value: " + employee);
}우리가 보기 흉한 instanceof를 없앨 수 있다면 어떨까요? 자바 21의 패턴 매칭의 힘 덕분에 이제 가능합니다:
switch (employee) {
case Manager m -> printf("Manager of %s department%n", m.department);
case Engineer e -> printf("I%s engineer.%n", e.speciality);
default -> throw new IllegalStateException("Unexpected value: " + employee);
} switch 문에 대해 이야기하면서, 레코드 패턴 기능에 대해서도 논의할 수 있습니다. Java 레코드를 다룰 때, 표준 Java 클래스보다 훨씬 더 많은 작업을 수행할 수 있습니다:
switch (shape) { // shape is a record
case Rectangle(int a, int b) -> System.out.printf("Area of rectangle [%d, %d] is: %d.%n", a, b, shape.calculateArea());
case Square(int a) -> System.out.printf("Area of square [%d] is: %d.%n", a, shape.calculateArea());
default -> throw new IllegalStateException("Unexpected value: " + shape);
}코드에서 알 수 있듯이, 그 구문을 사용하면 레코드 필드에 쉽게 접근할 수 있습니다. 또한, 케이스 문에 일부 추가 논리를 넣을 수 있습니다:
switch (shape) {
case Rectangle(int a, int b) when a < 0 || b < 0 -> System.out.printf("Incorrect values for rectangle [%d, %d].%n", a, b);
case Square(int a) when a < 0 -> System.out.printf("Incorrect values for square [%d].%n", a);
default -> System.out.println("Created shape is correct.%n");
}비슷한 구문을 if 문에도 사용할 수 있습니다. 또한, 아래 예제에서는 레코드 패턴이 중첩된 레코드에서도 작동하는 것을 볼 수 있습니다:
if (r instanceof Rectangle(ColoredPoint(Point p, Color c),
ColoredPoint lr)) {
//sth
}가상 스레드
Virtual Threads 기능은 아마도 Java 21에서 가장 뜨거운 기능 중 하나일 것입니다. 아니면 적어도 Java 개발자들이 가장 기다려온 기능 중 하나입니다. 앞서 언급한 JEP 문서에 따르면, 가상 스레드의 목표 중 하나는 “간단한 요청당 스레드 스타일로 작성된 서버 애플리케이션이 거의 최적의 하드웨어 활용도로 확장할 수 있도록 하는 것”이라고 합니다. 그러나 이것이 java.lang.Thread를 사용하는 전체 코드를 마이그레이션해야 한다는 의미일까요?
먼저, Java 21 이전에 존재했던 접근 방식의 문제를 살펴보겠습니다(사실 Java의 첫 출시 이후 거의 모든 경우에 해당합니다). 하나의 java.lang.Thread는 (운영 체제와 구성에 따라) 약 2MB에서 8MB의 메모리를 소모한다고 가정할 수 있습니다. 그러나 여기서 중요한 점은 하나의 Java 스레드가 1:1로 커널 스레드에 매핑된다는 것입니다. “요청당 하나의 스레드” 접근 방식을 사용하는 간단한 웹 앱의 경우, 트래픽이 증가할 때 우리의 머신이 “종료”될 것인지(하중을 처리할 수 없게 될 것인지) 아니면 더 많은 RAM을 가진 장치를 구매해야 할 것인지 쉽게 계산할 수 있으며, 그 결과 우리의 AWS 요금이 증가할 것입니다.
물론, 가상 스레드는 이 문제를 처리하는 유일한 방법이 아닙니다. 우리는 비동기 프로그래밍(예: WebFlux와 같은 프레임워크나 CompletableFuture와 같은 네이티브 Java API)을 가지고 있습니다. 그러나 어떤 이유에서인지 — 아마도 “불친절한 API”나 높은 진입 장벽 때문일 것입니다 — 이러한 솔루션은 그리 인기가 없습니다.
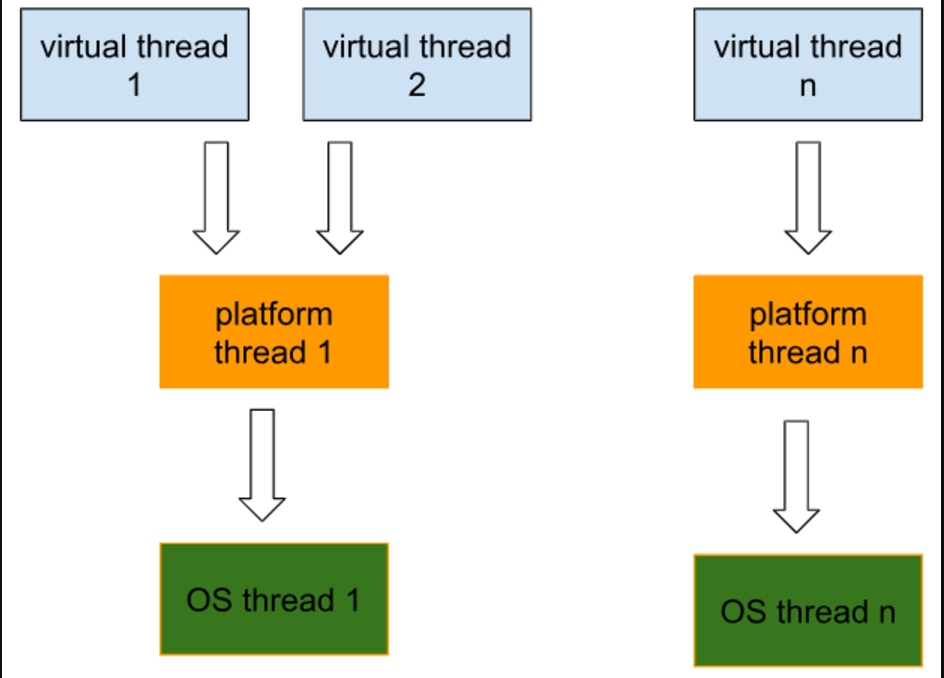
가상 스레드는 운영 체제에 의해 감독되거나 스케줄링되지 않습니다. 대신, 그들의 스케줄링은 JVM에 의해 처리됩니다. 실제 작업은 플랫폼 스레드에서 실행되어야 하지만, JVM은 실제로 플랫폼 스레드인 이른바 캐리어 스레드를 사용하여 실행할 때마다 가상 스레드를 “운반”합니다. 가상 스레드는 경량으로 설계되어 있으며 표준 플랫폼 스레드보다 훨씬 적은 메모리를 사용합니다.
아래의 다이어그램은 가상 스레드가 플랫폼 스레드 및 운영 체제 스레드와 어떻게 연결되는지를 보여줍니다:
그렇다면, 가상 스레드가 플랫폼 스레드에 의해 어떻게 사용되는지 보기 위해, (제 경우 8 코어인 머신의 CPU 수 + 1) 개의 가상 스레드를 시작하는 코드를 실행해 보겠습니다.
var numberOfCores = 8; //
final ThreadFactory factory = Thread.ofVirtual().name("vt-", 0).factory();
try (var executor = Executors.newThreadPerTaskExecutor(factory)) {
IntStream.range(0, numberOfCores + 1)
.forEach(i -> executor.submit(() -> {
var thread = Thread.currentThread();
System.out.println(STR."[\{thread}] VT number: \{i}");
try {
sleep(Duration.ofSeconds(1L));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}));
}출력은 다음과 같습니다:
[VirtualThread[#29,vt-6]/runnable@ForkJoinPool-1-worker-7] VT number: 6
[VirtualThread[#26,vt-4]/runnable@ForkJoinPool-1-worker-5] VT number: 4
[VirtualThread[#30,vt-7]/runnable@ForkJoinPool-1-worker-8] VT number: 7
[VirtualThread[#24,vt-2]/runnable@ForkJoinPool-1-worker-3] VT number: 2
[VirtualThread[#23,vt-1]/runnable@ForkJoinPool-1-worker-2] VT number: 1
[VirtualThread[#27,vt-5]/runnable@ForkJoinPool-1-worker-6] VT number: 5
[VirtualThread[#31,vt-8]/runnable@ForkJoinPool-1-worker-6] VT number: 8
[VirtualThread[#25,vt-3]/runnable@ForkJoinPool-1-worker-4] VT number: 3
[VirtualThread[#21,vt-0]/runnable@ForkJoinPool-1-worker-1] VT number: 0따라서, ForkJonPool-1-worker-X 플랫폼 스레드는 우리의 가상 스레드를 관리하는 캐리어 스레드입니다. 우리는 가상 스레드 번호 5와 8이 동일한 캐리어 스레드 번호 6을 사용하고 있음을 관찰합니다.
가상 스레드에 대해 보여주고 싶은 마지막 것은 그들이 차단 I/O 작업에 어떻게 도움이 되는지입니다.
가상 스레드가 I/O 작업과 같은 차단 작업에 직면할 때마다, JVM은 이를 효율적으로 기본 물리적 스레드(캐리어 스레드)에서 분리합니다. 이 분리는 중요합니다. 왜냐하면 캐리어 스레드가 차단 작업이 완료될 때까지 대기하는 대신 다른 가상 스레드를 실행할 수 있도록 해주기 때문입니다. 결과적으로, 단일 캐리어 스레드는 수천 또는 수백만의 가상 스레드를 멀티플렉싱할 수 있으며, 이는 사용 가능한 메모리와 수행되는 작업의 성격에 따라 달라질 수 있습니다.
이 동작을 시뮬레이션해 보겠습니다. 이를 위해 우리는 코드가 하나의 CPU 코어만 사용하도록 강제하고, 가독성을 높이기 위해 2개의 가상 스레드만 사용하겠습니다.
System.setProperty("jdk.virtualThreadScheduler.parallelism", "1");
System.setProperty("jdk.virtualThreadScheduler.maxPoolSize", "1");
System.setProperty("jdk.virtualThreadScheduler.minRunnable", "1");스레드 1:
Thread v1 = Thread.ofVirtual().name("long-running-thread").start(
() -> {
var thread = Thread.currentThread();
while (true) {
try {
Thread.sleep(250L);
System.out.println(STR."[\{thread}] - Handling http request ....");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
);스레드 2:
Thread v2 = Thread.ofVirtual().name("entertainment-thread").start(
() -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
var thread = Thread.currentThread();
System.out.println(STR."[\{thread}] - Executing when 'http-thread' hit 'sleep' function");
}
);실행:
v1.join(); v2.join();결과:
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#23,entertainment-thread]/runnable@ForkJoinPool-1-worker-1] - Executing when 'http-thread' hit 'sleep' function
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....우리는 두 개의 가상 스레드(long-running-thread와 entertainment-thread)가 오직 하나의 플랫폼 스레드인 ForkJoinPool-1-worker-1에 의해 처리되고 있음을 관찰합니다.
요약하자면, 이 모델은 Java 애플리케이션이 전통적인 스레드 모델보다 훨씬 낮은 오버헤드로 높은 수준의 동시성과 확장성을 달성할 수 있게 해줍니다. 각 스레드가 단일 운영 체제 스레드에 직접 매핑되는 방식입니다. 가상 스레드는 방대한 주제이며, 제가 설명한 것은 그 일부에 불과하다는 점에 유의할 가치가 있습니다. 스케줄링, 고정 스레드 및 가상 스레드의 내부 구조에 대해 더 많이 배우는 것을 강력히 권장합니다.
요약: Java 프로그래밍 언어의 미래
위에서 설명한 기능들은 제가 Java 21에서 가장 중요하다고 생각하는 것들입니다. 그 중 대부분은 JDK 17에서 도입된 것들처럼 혁신적이지는 않지만 여전히 매우 유용하며, 품질 개선(QOL) 변화를 제공하는 점이 좋습니다.
그러나 JDK 21의 다른 개선 사항도 간과해서는 안 됩니다 — 전체 목록을 분석하고 모든 기능을 더 탐색할 것을 강력히 권장합니다. 예를 들어, 제가 특히 주목할 만하다고 생각하는 것은 Vector API로, 이는 일부 지원되는 CPU 아키텍처에서 벡터 계산을 가능하게 합니다 — 이전에는 불가능했습니다. 현재 이 기능은 여전히 인큐베이터 상태/실험 단계에 있으며 (그래서 여기서 더 자세히 강조하지 않았습니다), 그러나 Java의 미래에 큰 가능성을 지니고 있습니다.
전반적으로 Java가 다양한 분야에서 이룬 발전은 팀이 고수요 애플리케이션에서 효율성과 성능을 개선하기 위한 지속적인 의지를 나타냅니다.
Source:
https://dzone.com/articles/java-21-features-a-detailed-look