













Grafana Loki – это горизонтально масштабируемая, высокодоступная система агрегации логов. Она разработана с упором на простоту и экономичность. Созданная Grafana Labs в 2018 году, Loki быстро стала привлекательной альтернативой традиционным системам логирования, особенно для облачных и сред Kubernetes.
Loki может обеспечить полноценный журнал логов. Мы можем выбрать правильные потоки логов, а затем отфильтровать их, сосредотачиваясь на необходимых логах. Затем мы можем разбирать структурированные данные логов для форматирования в соответствии с нашими потребностями в настраиваемом анализе. Логи также могут быть соответственно преобразованы для представления, например,или дальнейшей обработки в конвейере.
Loki интегрируется без проблем с широким экосистемой Grafana. Пользователи могут запрашивать логи, используя LogQL – язык запросов, специально разработанный для напоминания о PromQL в Prometheus. Это обеспечивает знакомый опыт для пользователей, уже работающих с метриками Prometheus, и позволяет мощную корреляцию между метриками и логами в рамках панелей управления Grafana.
Эта статья начинается с основ Loki, за которыми следует базовый архитектурный обзор. Затем идут основы LogQL, и мы заканчиваем разговором о принятых компромиссах.
Основы Loki
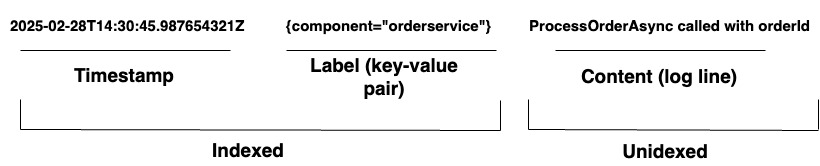
Для организаций, управляющих сложными системами, Loki предоставляет унифицированное решение для ведения журналов. Он поддерживает ввод журналов из любого источника через широкий спектр агентов или его API, обеспечивая всестороннее охват разнообразного аппаратного и программного обеспечения. Loki хранит свои журналы в виде потоков журналов, как показано на Диаграмме 1. Каждая запись имеет следующее:
- Отметка времени с точностью до наносекунд
- Пары ключ-значение, называемые метками, используются для поиска журналов. Метки предоставляют метаданные для строки журнала. Они используются для идентификации и извлечения данных. Они формируют индекс для потоков журналов и структурируют хранение журналов. Каждая уникальная комбинация меток и их значений определяет отдельный поток журналов. Записи журнала внутри потока группируются, сжимаются и хранятся в сегментах.
- Фактическое содержимое журнала. Это сырая строка журнала. Она не индексируется и хранится в сжатых блоках.
Архитектура
Мы проанализируем архитектуру Loki на основе трех основных функций. Чтение, запись и хранение журналов. Loki может работать в монолитном (однобинарном) или микросервисном режиме, где компоненты разделены для независимого масштабирования. Функциональность чтения и записи может быть масштабирована независимо для соответствия конкретным случаям использования. Рассмотрим каждый путь более подробно.
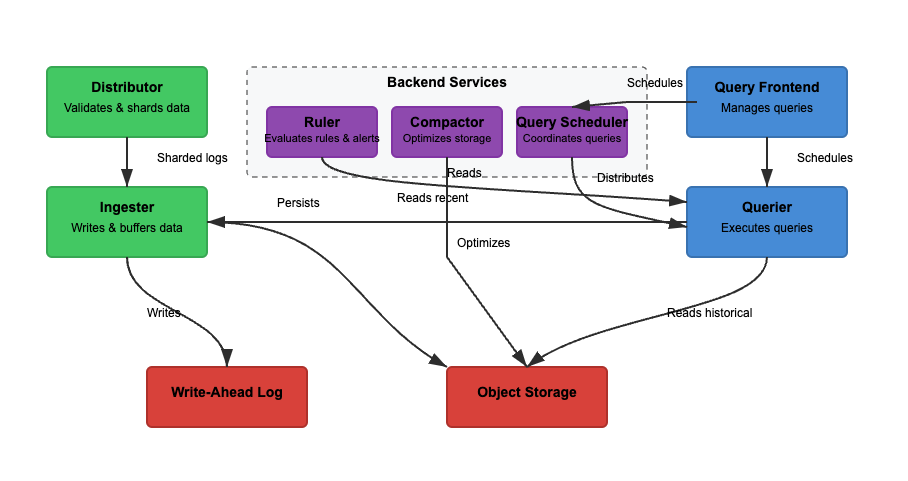
Запись
В Диаграмме 2 путь записи обозначен зеленым цветом. Когда логи поступают в Loki, дистрибьютор разбивает логи на шары на основе меток. Затем ингестер сохраняет логи в памяти, а компактор оптимизирует хранение. Основные шаги включают следующее.
Шаг 1: Логи поступают в Loki
Записи для поступающих логов поступают на дистрибьютор. Логи структурированы как потоки с метками (например, {job="nginx", level="error"}). Дистрибьютор разбивает логи на шары, разбивает их на части и отправляет в ингестеры. Он хеширует метки каждого потока и назначает их ингестеру с помощью согласованного хеширования. Дистрибьюторы проверяют логи и предотвращают некорректные данные. Согласованное хеширование может обеспечить равномерное распределение логов по ингестерам.
Шаг 2: Хранение на короткий срок
Ингестер хранит логи в памяти для быстрого доступа. Логи пакетируются и записываются в журналы предварительной записи (WAL) для предотвращения потери данных. WAL помогает обеспечить надежность, но не может быть запросим напрямую — ингестеры всё еще должны быть в сети для запроса недавних логов.
Периодически логи сбрасываются из ингестеров в объектное хранилище. Запросчик и правило читают ингестер для доступа к самым свежим данным. Запросчик также может получить доступ к данным в объектном хранилище.
Шаг 3: Логи перемещаются в долгосрочное хранение
Компактор периодически обрабатывает сохраненные журналы из долгосрочного хранения (object-storage). Объектное хранилище дешевое и масштабируемое. Оно позволяет Loki сохранять огромные объемы журналов без высоких затрат. Компактор удаляет дублирующиеся журналы, сжимает журналы для эффективного хранения и удаляет старые журналы на основе настроек хранения. Журналы хранятся в формате кусков (не индексируется полный текст).
Чтение
На диаграмме 2 путь чтения обозначен синим цветом. Запросы направляются на запросный фронтенд, и запросчик извлекает журналы. Журналы фильтруются, разбираются и анализируются с использованием LogQL. Основные этапы включают в себя следующее.
Шаг 1: Запросный фронтенд оптимизирует запросы
Пользователи запрашивают журналы с использованием LogQL в Grafana. Запросный фронтенд разбивает большие запросы на более мелкие части и распределяет их по нескольким запросчикам, поскольку параллельное выполнение ускоряет запросы. Он отвечает за ускорение выполнения запроса и обеспечивает повторы в случае сбоя. Запросный фронтенд помогает избежать превышения времени ожидания и перегрузок, а неудачные запросы повторяются автоматически.
Шаг 2: Запросчик извлекает журналы
Запросчики разбирают LogQL и запрашивают ингестеры и объектное хранилище. Недавние журналы извлекаются из ингестеров, а старые журналы извлекаются из объектного хранилища. Журналы с одинаковым временным штампом, метками и содержанием дедуплицируются.
Фильтры Блума и индексные метки используются для эффективного поиска журналов. Запросы агрегации, такие как count_over_time(), выполняются быстрее, потому что Loki не индексирует полностью журналы. В отличие от Elasticsearch, Loki не индексирует содержание журналов полностью.
Вместо этого оно индексирует метаданные ({app="nginx", level="error"}), что помогает эффективно и дешево находить логи. Полнотекстовый поиск выполняется только на соответствующих фрагментах логов, что снижает затраты на хранение.
Основы LogQL
LogQL – это язык запросов, используемый в Grafana Loki для эффективного поиска, фильтрации и преобразования логов. Он состоит из двух основных компонентов:
- Выбор потока – выбор потоков логов на основе сопоставителей меток
- Фильтрация и преобразование – извлекает соответствующие строки логов, анализирует структурированные данные и форматирует результаты запроса
Сочетая эти функции, LogQL позволяет пользователям эффективно извлекать логи, извлекать идеи и генерировать полезные метрики из логов.
Выбор потока
Выбор потока – первый шаг в каждом запросе LogQL. Он выбирает потоки логов на основе сопоставителей меток. Чтобы уточнить результаты запроса для конкретных потоков логов, мы можем использовать базовые операторы для фильтрации по меткам Loki. Улучшение точности выбора потока логов уменьшает объем отсканированных потоков, тем самым повышая скорость запроса.
Примеры
{app="nginx"} # Selects logs where app="nginx"
{env=~"prod|staging"} # Selects logs from prod or staging environments
{job!="backend"} # Excludes logs from the backend jobФильтры строк
После выбора логов фильтры строк уточняют результаты поиска, ища определенный текст или применяя логические условия. Фильтры строк работают с содержимым лога, а не с метками.
Примеры
{app="nginx"} |= "error" # Select logs from nginx that contain "error"
{app="db"} != "timeout" # Exclude logs with "timeout"
{job="frontend"} |~ "5\d{2}" # Match HTTP 500-series errors (500-599)Парсеры
Локи может принимать неструктурированные, полуструктурированные или структурированные журналы. Однако понимание форматов журналов, с которыми мы работаем, критично при проектировании и создании решений по обеспечению наблюдаемости. Таким образом, мы можем загружать, хранить и разбирать журнальные данные для эффективного использования. Локи поддерживает парсеры JSON, logfmt, pattern, regexp и unpack.
Примеры
{app="payments"} | json # Extracts JSON fields
{app="auth"} | logfmt # Extracts key-value pairs
{app="nginx"} | regexp "(?P<status>\d{3})" # Extracts HTTP status codesФильтры меток
После разбора журналы могут быть отфильтрованы по извлеченным полям. Метки могут быть извлечены как часть конвейера журналов с использованием выражений парсера и форматировщика. Затем выражение фильтра метки может быть использовано для фильтрации нашей строки журнала с любой из этих меток.
Примеры
{app="web"} | json | status="500" # Extract JSON, then filter by status=500
{app="db"} | logfmt | user="admin" # Extract key-value logs, filter by user=adminФормат строки
Используется для изменения вывода журнала путем извлечения и форматирования полей. Это определяет, как отображаются журналы в Grafana.
Пример
{app="nginx"} | json | line_format "User {user} encountered {status} error"Формат меток
Используется для переименования, изменения, создания или удаления меток. Он принимает список операций равенства, разделенных запятыми, позволяя выполнять несколько операций одновременно.
Примеры
1. {app="nginx"} | label_format new_label=old_label. #If a log has {old_label="backend"}, it is renamed to {new_label="backend"}. The original old_label is removed.
2. {app="web"} | label_format status="HTTP {{.status}}" #If {status="500"}, it becomes {status="HTTP 500"}.
3. {app="db"} | label_format severity="critical". #Adds {severity="critical"} to all logs.
4. {app="api"} | drop log_level # Drops log_level Компромиссы
Grafana Loki предлагает экономичное, масштабируемое решение по ведению журналов, которое хранит журналы в сжатых блоках с минимальным индексированием. Это сопряжено с компромиссами в производительности запросов и скорости извлечения. В отличие от традиционных систем управления журналами, индексирующих полное содержимое журнала, индексирование Loki на основе меток ускоряет фильтрацию.
Однако это может замедлить сложные текстовые поиски. Кроме того, если Loki отлично справляется с обработкой высоконагруженных распределенных сред, он полагается на объектное хранилище для масштабируемости. Это может привести к задержкам и требует тщательного выбора меток, чтобы избежать проблем с высокой кардинальностью.
Масштабируемость и мультиаренность
Loki разработан для масштабируемости и мультиаренности. Однако масштабируемость сопряжена с архитектурными компромиссами. Масштабирование записей (ingesters) просто благодаря возможности шардирования журналов на основе меток. Масштабирование чтения (queriers) сложнее, потому что выполнение запросов к большим наборам данных из объектного хранилища может быть медленным. Мультиаренность поддерживается, но управление квотами для арендаторов, взрыв меток и безопасность (изоляция данных для каждого арендатора) требует тщательной настройки.
Простое внесение данных без предварительного анализа
Loki не требует предварительного анализа, поскольку он не индексирует полное содержание журналов. Он сохраняет журналы в сжатом виде в виде сырых блоков. Поскольку у Loki нет индексации полного текста, для выполнения запросов к структурированным журналам (например, JSON) требуется разбор LogQL. Это означает, что производительность запроса зависит от того, насколько хорошо структурированы журналы перед внесением. Без структурированных журналов эффективность запроса страдает, потому что фильтрация должна происходить во время извлечения, а не во время внесения.
Хранение в объектном хранилище
Loki сбрасывает блоки журналов в объектное хранилище (например, S3, GCS, Azure Blob). Это снижает зависимость от дорогостоящего блочного хранилища, например, необходимого для Elasticsearch.
Однако считывание журналов из объектного хранилища может быть медленным по сравнению с запросами непосредственно из базы данных. Loki компенсирует это, храня недавние журналы в ингестерах для более быстрого извлечения. Компакция снижает избыточность хранения, но задержка извлечения журналов все еще может быть проблемой для запросов масштаба предприятия.
Метки и кардинальность
Поскольку метки используются для поиска журналов, они критичны для эффективных запросов. Плохая разметка может привести к проблемам с высокой кардинальностью. Использование меток с высокой кардинальностью (например, user_id, session_id) увеличивает использование памяти и замедляет запросы. Loki хеширует метки для распределения журналов по ингестерам, поэтому неправильное проектирование меток может вызвать неравномерное распределение журналов.
Фильтрация в начале
Поскольку Loki хранит сжатые исходные журналы в объектном хранилище, важно фильтровать их заранее, если мы хотим, чтобы наши запросы работали быстро. Обработка сложного разбора на небольших наборах данных увеличит время отклика. Согласно этому правилу, хороший запрос будет Запрос 1, а плохой запрос – Запрос 2.
Запрос 1
{job="nginx", status_code=~"5.."} | jsonЗапрос 1 фильтрует журналы, где job="nginx" и status_code начинается с 5 (ошибки 500–599). Затем он извлекает структурированные JSON-поля, используя | json. Это минимизирует количество журналов, обрабатываемых парсером JSON, что делает процесс быстрее.
Запрос 2
{job="nginx"} | json | status_code=~"5.."Запрос 2 сначала извлекает все журналы из nginx. Это может быть миллионы записей. Затем он разбирает JSON для каждой отдельной записи журнала перед фильтрацией по status_code. Это неэффективно и значительно медленнее.
Подведение итогов
Grafana Loki — это мощная и экономически эффективная система агрегации логов, разработанная для масштабируемости и простоты использования. Индексируя только метаданные, она сохраняет низкие затраты на хранение, обеспечивая при этом быстрые запросы с помощью LogQL.
Её архитектура микросервисов поддерживает гибкие развертывания, что делает её идеальной для облачных сред. В этой статье рассмотрены основы Loki и его языка запросов. Изучив основные характеристики архитектуры Loki, мы можем лучше понять связанные с ней компромиссы.
Source:
https://dzone.com/articles/grafana-loki-fundamentals-and-architecture