













Grafana Loki הוא מערכת איגוד יומנים אשר ניתנת להרחבה באופן אופקתי וזמינות גבוהה. היא מיועדת לפשטות וליעילות מבחינת עלויות. נוצרה על ידי Grafana Labs בשנת 2018, Loki עלתה מהר להיות אלטרנטיבה משכנעת למערכות יומנים מסורתיות, בעיקר עבור סביבות ענן ו-Kubernetes.
Loki יכולה לספק מסע יומנים מקיף. אנו יכולים לבחור בזרמי הלוגים הנכונים ולסנן אותם כדי להתמקד בלוגים רלוונטיים. לאחר מכן אנו יכולים לנתח נתונים יומניים מובנים כדי להתאים אותם לצרכי הניתוח המותאמים שלנו. הלוגים יכולים גם להיהפך באופן רלוונטי להצגה, לדוגמה, או לעיבוד נוסף בצינור.
Loki משתלבת באופן חלק עם האקוסיסטמה הרחבה של Grafana. משתמשים יכולים לשאול את הלוגים באמצעות LogQL — שפת שאילתות שנועדה במיוחד לדמות את Prometheus PromQL. זה מספק חווית משתמש מוכרת למשתמשים שעבדו כבר עם נתוני Prometheus ומאפשר קורלציה חזקה בין מטריקות ולוגים בתוך לוחות הבקרה של Grafana.
מאמר זה מתחיל עם יסודות Loki, ואחריו מבט על מבנה בסיסי. לאחר מכן יבואו יסודות LogQL, ואנו נסיים עם ההתמודדות עם ההפסדים המעורבים.
יסודות Loki
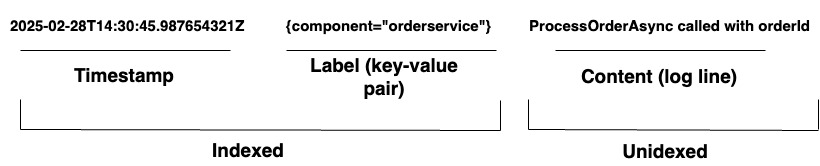
עבור ארגונים המנהלים מערכות מורכבות, Loki מספקת פתרון לוגים מאוחד. היא תומכת בקליטת לוגים מכל מקור דרך מגוון רחב של סוכנים או ה-API שלה, ומבטיחה כיסוי כולל של חומרה ותוכנה מגוונים. לוקי שומרת את הלוגים שלה כזרמי לוג, כפי שמוצג בדיאגרמה 1. לכל רשומה יש את הדברים הבאים:
- חותמת זמן בדיוק ננושני
- צמדי מפתח-ערך הנקראים תיוגים משמשים לחיפוש לוגים. תיוגים מספקים את המטא-דאטה עבור שורת הלוג. הם משמשים לזיהוי ולשליפת נתונים. הם מהווים את המדריך לזרמי הלוג ומבנים את אחסון הלוגים. כל שילוב ייחודי של תיוגים והערכים שלהם מגדיר זרם לוג נפרד. רשומות הלוג בתוך זרם מקובצות, דחוסות, ונשמרות במקטעים.
- התוכן האמיתי של הלוג. זהו קו הלוג הגולמי. הוא לא ממוין ונשמר בחתיכות דחוסות.
ארכיטקטורה
ננתח את הארכיטקטורה של לוקי על בסיס שלושה תכונות בסיסיות. קריאה, כתיבה, ואחסון לוגים. לוקי יכולה לפעול במצב מונוליטי (בינארי אחד) או במצב מיקרו-שירותים, שבו המרכיבים מופרדים לסקלינג עצמאי. פונקציות הקריאה והכתיבה יכולות להיות מסולקות באופן עצמאי כדי להתאים למקרים ספציפיים של שימוש. בואו נבחן כל נתיב בפירוט רב יותר.
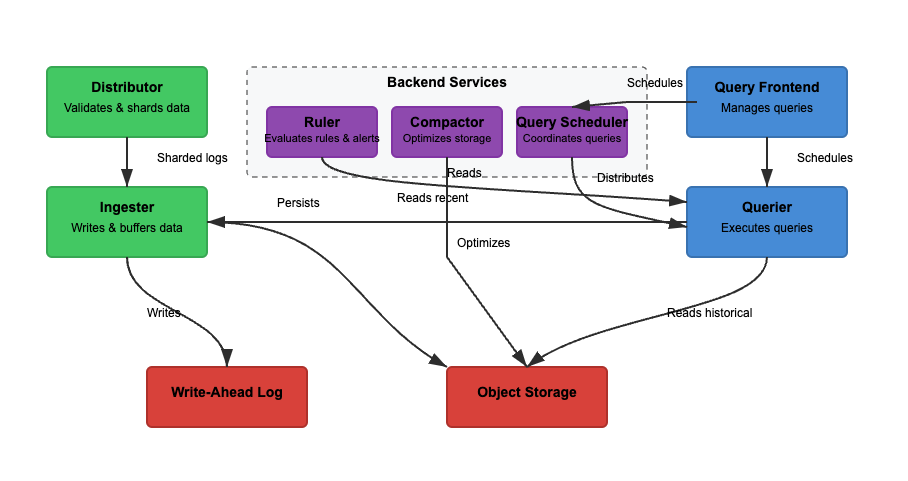
כתיבה
בתרשים 2, מסלול הכתיבה הוא המסלול הירוק. כאשר יומנים נכנסים ל-Loki, המפיץ מפצל את היומנים בהתאם לתוויות. המכניס שומר את היומנים בזיכרון, והמְכוֹבֵש אופטימיז את האחסון. הצעדים העיקריים המעורבים הם הבאים.
שלב 1: יומנים נכנסים ל-Loki
כתיבות עבור היומנים הנכנסים מגיעות למפיץ. היומנים מאורגנים כזרמים, עם תוויות (כמו {job="nginx", level="error"}). המפיץ מפצל את היומנים, מחלק את היומנים ושולח את היומנים למכניסים. הוא מחיש את התוויות של כל זרם ומקצה אותו למכניס באמצעות חישוב עקבי. המפיצים מאמתים את היומנים ומונעים נתונים פגומים. חישוב עקבי יכול להבטיח הפצה שווה של היומנים בין המכניסים.
שלב 2: אחסון לטווח קצר
המכניס שומר את היומנים בזיכרון לצורך שליפה מהירה. היומנים נערמים ונכתבים ליומני כתיבה מראש (WAL) כדי למנוע אובדן נתונים. WAL מסייע בעמידות אך אינו ניתן לשאול ישירות – המכניסים עדיין צריכים להישאר מחוברים לשאילת היומנים האחרונים.
באופן תקופתי, היומנים מתנקזים מהמכניסים לאחסון אובייקטים. השואל והמנהל קוראים מהמכניס כדי לגשת לנתונים העדכניים ביותר. השואל יכול בנוסף לגשת לנתוני אחסון האובייקטים.
שלב 3: היומנים מועברים לאחסון לטווח ארוך
המדחס מעבד באופן תדיר יומנים שמאוחסנים באחסון לטווח ארוך (object-storage). אחסון אובייקטים הוא זול ונמדד. זה מאפשר ל־Loki לאחסן כמויות עצומות של יומנים בלי עלויות גבוהות. המדחס מסנן יומנים חוזרים, דוחס יומנים ליעילות אחסון ומוחק יומנים ישנים על סמך הגדרות נשמרות. היומנים מאוחסנים בפורמט קטעים (לא מכיל אינדקס מלא של טקסט).
קריאה
בתרשים 2, נתיב הקריאה הוא הנתיב הכחול. שאילתות עוברות לשרת הקריאה, והמחפש מחזיר יומנים. היומנים מסוננים, מנותקים וננתחים באמצעות LogQL. השלבים העיקריים המעורבים הם הבאים.
שלב 1: שרת הקריאה מכוון בקשות
משתמשים שואלים שאילתות באמצעות LogQL ב־Grafana. שרת הקריאה מפצל שאילתות גדולות לחתיכות קטנות ומפזר אותן בין מספר של מחפשי שאילתות מרובים מכיוון שהרצת מקבילה מאיצה את השאילתות. הוא אחראי על האצת ביצוע השאילתות ועל הבטיחות של ניסיונות השאילתה במקרה של כשל. שרת הקריאה עוזר למנוע זמני המתנה ועומסים, בעוד ששאילות שנכשלות מנסות שוב באופן אוטומטי.
שלב 2: המחפש מביא יומנים
מחפשי שאילתות מנתקים את LogQL ושואלים מאינגסטרים ואחסון אובייקטים. יומנים אחרונים מתקבלים מהאינגסטרים, ויומנים ישנים מתוך אחסון אובייקטים. יומנים עם אותו חותמת זמן, תוויות ותוכן מושכפים.
מסנני Bloom ותוויות אינדקס משמשים למציאת יומנים ביעילות. שאילות אגרגציה, כמו count_over_time() רצים במהירות כי Loki לא אינדקס יומנים באופן מלא. בניגוד ל־Elasticsearch, Loki לא אינדקס תוכן מלא של יומנים.
במקום זאת, זה מאיץ תווי נתונים ({app="nginx", level="error"}), שעוזרים למצוא יומנים בצורה יעילה ובתקציב נמוך. חיפושים בטקסט מלא מבוצעים רק על קטעי יומן רלוונטיים, מה שמפחית את עלויות האחסון.
יסודות של LogQL
LogQL היא שפת שאילתות המשמשת ב-Grafana Loki כדי לחפש, לסנן ולהמיר יומנים בצורה יעילה. היא מורכבת משני רכיבים עיקריים:
- בורר זרמים – בוחר זרמי יומן על סמך התאמות תווי נתונים
- סינון והמרה – מוציא שורות יומן רלוונטיות, פותח נתונים מובנים ומעביר את תוצאות השאילתה לפורמט
בשילוב של תכונות אלו, LogQL מאפשר למשתמשים לקבל יומנים בצורה יעילה, לחלץ תובנות וליצור מדדים שימושיים מנתוני יומן.
בורר זרמים
בורר זרמים הוא השלב הראשון בכל שאילתת LogQL. הוא בוחר זרמי יומן על סמך התאמות תווי נתונים. כדי למשקל את תוצאות השאילתה לזרמי יומן ספציפיים, אפשר להשתמש באופרטורים בסיסיים כדי לסנן לפי תווי נתונים של Loki. שיפור הדיוק של בחירת זרם היומן שלנו ממזער את נפח הזרמים שנסרקים, ומחזק את מהירות השאילתה.
דוגמאות
{app="nginx"} # Selects logs where app="nginx"
{env=~"prod|staging"} # Selects logs from prod or staging environments
{job!="backend"} # Excludes logs from the backend jobסנני שורות
לאחר שהיומנים נבחרו, סנני שורות משפרים את התוצאות על ידי חיפוש אחר טקסט ספציפי או החלת תנאים לוגיים. סנני שורות עובדים על תוכן היומן, ולא על תווי נתונים.
דוגמאות
{app="nginx"} |= "error" # Select logs from nginx that contain "error"
{app="db"} != "timeout" # Exclude logs with "timeout"
{job="frontend"} |~ "5\d{2}" # Match HTTP 500-series errors (500-599)פרוסרים
לוקי יכול לקבל יומנים לא מסודרים, חצי מסודרים או מסודרים. אך הבנת פורמטי הלוגים שאנו עובדים איתם חיונית בעת עיצוב ובניית פתרונות ניטור. בכך נוכל לקלוט, לאחסן ולפענח נתוני לוגים כך שישמשו ביעילות. לוקי תומך במפענחי JSON, logfmt, pattern, regexp, ו-unpack.
דוגמאות
{app="payments"} | json # Extracts JSON fields
{app="auth"} | logfmt # Extracts key-value pairs
{app="nginx"} | regexp "(?P<status>\d{3})" # Extracts HTTP status codesסינוני תוויות
לאחר שהנתונים נפענחו, ניתן לסנן אותם לפי השדות שינובחו. ניתן לחלץ תוויות כחלק מצינור הלוגים באמצעות ביטויי פרוסר ועיצוב. ביטוי סינון התוויות יכול לשמש לסינון שורת הלוג שלנו באחת מתוויות אלו.
דוגמאות
{app="web"} | json | status="500" # Extract JSON, then filter by status=500
{app="db"} | logfmt | user="admin" # Extract key-value logs, filter by user=adminפורמט שורה
משמש לשינוי פלט הלוג על ידי חילוץ ועיצוב שדות. פורמט זה קובע כיצד הלוגים מוצגים ב-Grafana.
דוגמה
{app="nginx"} | json | line_format "User {user} encountered {status} error"פורמט תוויות
משמש לשינוי שם, שינוי, יצירה, או הסרת תוויות. הוא מקבל רשימה מופרדת בפסיקים של פעולות שוויון, ומאפשר ביצוע פעולות מרובות בו זמנית.
דוגמאות
1. {app="nginx"} | label_format new_label=old_label. #If a log has {old_label="backend"}, it is renamed to {new_label="backend"}. The original old_label is removed.
2. {app="web"} | label_format status="HTTP {{.status}}" #If {status="500"}, it becomes {status="HTTP 500"}.
3. {app="db"} | label_format severity="critical". #Adds {severity="critical"} to all logs.
4. {app="api"} | drop log_level # Drops log_level פתרונות
גרפנה לוקי מציע פתרון לוגינג יעיל מבחינת עלות, המאוחסן בקרקעות דחוסות עם אינדקסציה מינימלית. זה מביא עימו פתרונות על חשבון ביצועי שאילתות ומהירות אחזור. להבדיל ממערכות ניהול לוגים מסורתיות שאינן מאינדקסות את תוכן הלוג המלא, האינדקסציה המבוססת על תוויות של לוקי מאיצה את תהליך הסינון.
עם זאת, זה עשוי להאט חיפושים בטקסטים מורכבים. בנוסף, בעוד שלוקי מצטיין בטיפול בסביבות מבוזרות עם תפוקה גבוהה, הוא תלוי באחסון אובייקטים לצורך גמישות. זה יכול להציג השהיה ודורש בחירה קפדנית של תוויות כדי להימנע מבעיות של קרדינליות גבוהה.
גמישות וריבוי דיירים
לוקי מיועד לגמישות וריבוי דיירים. עם זאת, גמישות מגיעה עם פשרות ארכיטקטוניות. גידול כתיבות (ingesters) הוא פשוט הודות ליכולת לחלק יומנים על סמך חלוקה לפי תוויות. גידול קריאות (queriers) הוא מסובך יותר מכיוון שקריאת מערכות נתונים גדולות מאחסון אובייקטים יכולה להיות איטית. ריבוי דיירים נתמך, אך ניהול מכסות ספציפיות לדיירים, התפוצצות תוויות ואבטחה (הפרדת נתונים לפי דייר) דורש תצורה קפדנית.
קליטה פשוטה ללא פרסינג מקדים
לוקי אינו דורש פרסינג מקדים מכיוון שהוא אינו מייצר אינדקס לתוכן המלא של היומנים. הוא מאחסן יומנים בפורמט גולמי בחלקים דחוסים. מכיוון שלוקי חסר אינדקס טקסט מלא, קריאת יומנים מובנים (למשל, JSON) דורשת פרסינג של LogQL. זה אומר כי ביצועי השאילתות תלויים בכמה טוב היומנים מובנים לפני הקליטה. ללא יומנים מובנים, היעילות של השאילתות נפגעת כי הסינון חייב להתבצע בזמן השגת המידע, ולא בזמן הקליטה.
אחסון באחסון אובייקטים
לוקי משחרר חלקי יומנים לאחסון אובייקטים (למשל, S3, GCS, Azure Blob). זה מפחית את התלות באחסון בלוקים יקר כמו, למשל, מה ש-Elasticsearch דורש.
אף על פי שקריאת הלוגים מאחסון אובייקטים עשויה להיות איטית בהשוואה לשאילתות ישירות ממסד נתונים, Loki מתגבר על כך על ידי שמירת הלוגים האחרונים במאכלים לגישה מהירה יותר. הכיווץ מפחית את עלות האחסון, אך לטיפול בלוגים יכול להיות עדיין בעיה בשאילתות בקנה מידה גדול.
תוויות וקרדינליות
מאחר שתוויות משמשות לחיפוש בלוגים, הן חיוניות לשאילתות יעילות. תיוג רע עלול לגרום לבעיות קרדינליות גבוהות. שימוש בתוויות עם קרדינליות גבוהה (למשל, user_id, session_id) מגביר את שימוש הזיכרון ומאט שאילתות. Loki מפצל תוויות כדי להפיץ את הלוגים בין המאכלים, ולכן עיצוב תגיות רע עשוי לגרום להפצה לא אחידה של לוגים.
סינון מוקדם
מאחר ש-Loki שומרת על הלוגים הגולמיים המדוחסים באחסון אובייקטים, חשוב לסנן מוקדם אם רוצים שהשאילתות שלנו יהיו מהירות. עיבוד פריקות מורכבות על מערכות נתונים קטנות יגביר את זמן התגובה. על פי כלל זה, שאילתה טובה היא שאילתה 1, ושאילתה רעה היא שאילתה 2.
שאילתה 1
{job="nginx", status_code=~"5.."} | jsonשאילתה 1 מסננת לוגים בהם job="nginx" ו-status_code מתחיל ב-5 (שגיאות 500–599). לאחר מכן, היא מחלצת שדות JSON מובנים באמצעות | json. זה מקטין את מספר הלוגים שעברו על ידי פרשני JSON, והופך אותה למהירה יותר.
שאילתה 2
{job="nginx"} | json | status_code=~"5.."שאילתה 2 מחפשת קודם את כל הלוגים מ-nginx. זה עשוי להיות מיליוני רשומות. לאחר מכן, היא מפרקת JSON לכל רשומת לוג לפני הסינון לפי status_code. זה לא יעיל ואיטי באופן משמעותי.
סיכום
גרפנה לוקי הוא מערכת ריכוז לוגים חזקה וחסכונית, שנועדה להתרחבות ופשטות. על ידי אינדוקס רק של מטא-דאטה, הוא שומר על עלויות אחסון נמוכות בזמן שמאפשר שאילתות מהירות באמצעות LogQL.
הארכיטקטורה של המיקרו-שירותים שלו תומכת בפריסות גמישות, מה שמסייע לה להיות אידיאלית לסביבות מבוססות ענן. מאמר זה דן ביסודות של לוקי ושפת השאילתות שלו. על ידי ניווט דרך התכונות הבולטות של הארכיטקטורה של לוקי, נוכל להבין טוב יותר את הפשרות המעורבות.
Source:
https://dzone.com/articles/grafana-loki-fundamentals-and-architecture