













O Grafana Loki é um sistema de agregação de registros altamente escalável e altamente disponível. Ele é projetado para simplicidade e eficiência de custos. Criado pela Grafana Labs em 2018, o Loki rapidamente se tornou uma alternativa convincente aos sistemas de registro tradicionais, especialmente para ambientes nativos de nuvem e Kubernetes.
O Loki pode fornecer uma jornada de registro abrangente. Podemos selecionar os fluxos de log corretos e depois filtrar para focar nos logs relevantes. Podemos então analisar dados de log estruturados para serem formatados de acordo com nossas necessidades de análise personalizadas. Os logs também podem ser transformados adequadamente para apresentação, por exemplo, ou para processamento adicional em pipeline.
O Loki se integra perfeitamente com o ecossistema mais amplo do Grafana. Os usuários podem consultar logs usando LogQL – uma linguagem de consulta projetada intencionalmente para se assemelhar ao Prometheus PromQL. Isso proporciona uma experiência familiar para usuários que já trabalham com métricas do Prometheus e permite uma correlação poderosa entre métricas e logs dentro dos painéis do Grafana.
Este artigo começa com os fundamentos do Loki, seguido por uma visão arquitetônica básica. Os conceitos básicos do LogQL seguem, e concluímos com as compensações envolvidas.
Princípios Fundamentais do Loki
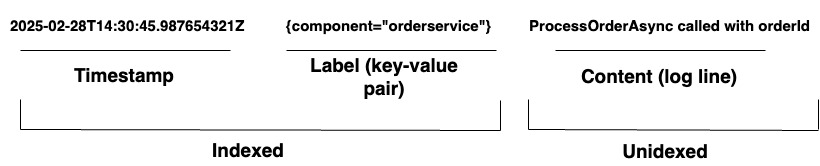
Para organizações que gerenciam sistemas complexos, o Loki fornece uma solução unificada de registro. Ele suporta a ingestão de registros de qualquer origem por meio de uma ampla variedade de agentes ou de sua API, garantindo uma cobertura abrangente de hardware e software diversos. O Loki armazena seus registros como fluxos de log, conforme mostrado no Diagrama 1. Cada entrada possui o seguinte:
- Um timestamp com precisão de nanossegundos
- Pares chave-valor chamados rótulos são usados para procurar registros. Os rótulos fornecem os metadados para a linha de log. Eles são usados para a identificação e recuperação de dados. Eles formam o índice para os fluxos de log e estruturam o armazenamento de log. Cada combinação única de rótulos e seus valores define um fluxo de log distinto. As entradas de log dentro de um fluxo são agrupadas, compactadas e armazenadas em segmentos.
- O conteúdo do log real. Esta é a linha de log bruta. Não é indexada e é armazenada em blocos comprimidos.
Arquitetura
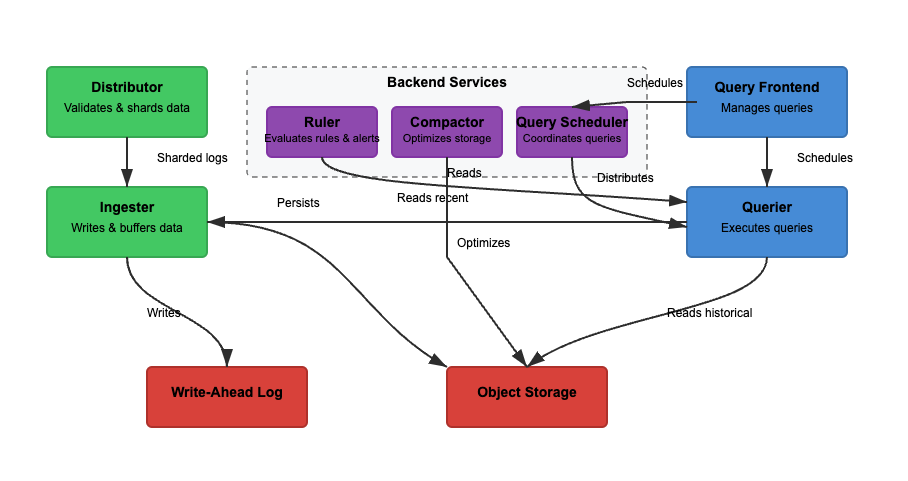
Vamos analisar a arquitetura do Loki com base em três características básicas. Leitura, escrita e armazenamento de logs. O Loki pode operar no modo monolítico (binário único) ou no modo de microsserviços, onde os componentes são separados para escalabilidade independente. A funcionalidade de leitura e escrita pode ser escalada independentemente para atender casos de uso específicos. Vamos considerar cada caminho com mais detalhes.
Escrita
No Diagrama 2, o caminho de escrita é o caminho verde. À medida que os logs entram no Loki, os shards distribuidores de logs com base em rótulos. O ingester armazena os logs na memória, e o compactador otimiza o armazenamento. Os principais passos envolvidos são os seguintes.
Passo 1: Logs Entram no Loki
As escritas para os logs recebidos chegam ao distribuidor. Os logs são estruturados como fluxos, com rótulos (como {job="nginx", level="error"}). O distribuidor divide os logs em shards, particiona os logs e envia os logs para os ingesters. Ele faz hash dos rótulos de cada fluxo e atribui a um ingester usando hash consistente. Os distribuidores validam os logs e impedem dados malformados. O hash consistente pode garantir uma distribuição uniforme de logs entre os ingesters.
Passo 2: Armazenamento de Curto Prazo
O ingester armazena os logs na memória para recuperação rápida. Os logs são agrupados e gravados nos Write-Ahead Logs (WAL) para evitar perda de dados. O WAL ajuda na durabilidade, mas não é consultável diretamente – os ingesters ainda precisam permanecer online para consultar logs recentes.
Periodicamente, os logs são descarregados dos ingesters para o armazenamento de objetos. O interrogador e o governante leem o ingester para acessar os dados mais recentes. O interrogador pode acessar adicionalmente os dados do armazenamento de objetos.
Passo 3: Logs Movem para o Armazenamento de Longo Prazo
O compactador processa periodicamente logs armazenados do armazenamento de longo prazo (object-storage). O armazenamento de objeto é barato e escalável. Isso permite que o Loki armazene grandes quantidades de logs sem custos altos. O compactador remove logs redundantes, comprime logs para eficiência de armazenamento e exclui logs antigos com base nas configurações de retenção. Os logs são armazenados em formato segmentado (não indexado em texto completo).
Leitura
No Diagrama 2, o caminho de leitura é o caminho azul. As consultas vão para o frontend de consulta, e o interrogador recupera os logs. Os logs são filtrados, analisados e analisados usando LogQL. Os principais passos envolvidos são os seguintes.
Passo 1: Frontend de Consulta Otimiza Solicitações
Os usuários consultam logs usando LogQL no Grafana. O frontend de consulta divide consultas grandes em pedaços menores e os distribui entre vários interrogadores, pois a execução paralela acelera as consultas. Ele é responsável por acelerar a execução da consulta e garantir tentativas em caso de falha. O frontend de consulta ajuda a evitar timeouts e sobrecargas, enquanto consultas falhadas são refeitas automaticamente.
Passo 2: Interrogador Recupera Logs
Os interrogadores analisam o LogQL e consultam ingesters e armazenamento de objetos. Logs recentes são recuperados dos ingesters, e logs mais antigos são recuperados do armazenamento de objetos. Logs com o mesmo carimbo de tempo, rótulos e conteúdo são deduplicados.
Filtros de Bloom e rótulos de índice são usados para encontrar logs de forma eficiente. Consultas de agregação, como count_over_time(), são executadas mais rapidamente porque o Loki não indexa totalmente os logs. Ao contrário do Elasticsearch, o Loki não indexa o conteúdo completo do log.
Em vez disso, ele indexa rótulos de metadados ({app="nginx", level="error"}), o que ajuda a encontrar logs de forma eficiente e barata. As pesquisas de texto completo são realizadas apenas em pedaços de log relevantes, reduzindo os custos de armazenamento.
Princípios básicos do LogQL
O LogQL é a linguagem de consulta usada no Grafana Loki para pesquisar, filtrar e transformar logs de forma eficiente. Ele consiste em dois componentes principais:
- Seletor de stream – Seleciona fluxos de log com base em combinadores de rótulos
- Filtragem e transformação – Extrai linhas de log relevantes, analisa dados estruturados e formata os resultados da consulta
Ao combinar esses recursos, o LogQL permite que os usuários obtenham logs de forma eficiente, extraiam insights e gerem métricas úteis a partir dos dados de log.
Seletor de Stream
O seletor de stream é o primeiro passo em cada consulta do LogQL. Ele seleciona fluxos de log com base em combinadores de rótulos. Para refinar os resultados da consulta para fluxos de log específicos, podemos empregar operadores básicos para filtrar por rótulos do Loki. Aumentar a precisão da seleção de fluxo de log minimiza o volume de fluxos verificados, aumentando assim a velocidade da consulta.
Exemplos
{app="nginx"} # Selects logs where app="nginx"
{env=~"prod|staging"} # Selects logs from prod or staging environments
{job!="backend"} # Excludes logs from the backend jobFiltros de Linha
Uma vez que os logs são selecionados, os filtros de linha refinam os resultados ao procurar por texto específico ou aplicar condições lógicas. Os filtros de linha trabalham no conteúdo do log, não nos rótulos.
Exemplos
{app="nginx"} |= "error" # Select logs from nginx that contain "error"
{app="db"} != "timeout" # Exclude logs with "timeout"
{job="frontend"} |~ "5\d{2}" # Match HTTP 500-series errors (500-599)Analisadores
Loki pode aceitar logs não estruturados, semi-estruturados ou estruturados. No entanto, entender os formatos de log com os quais estamos trabalhando é crucial ao projetar e construir soluções de observabilidade. Dessa forma, podemos ingerir, armazenar e analisar dados de log para serem usados de forma eficaz. Loki suporta parsers JSON, logfmt, pattern, regexp e unpack.
Exemplos
{app="payments"} | json # Extracts JSON fields
{app="auth"} | logfmt # Extracts key-value pairs
{app="nginx"} | regexp "(?P<status>\d{3})" # Extracts HTTP status codesFiltros de Etiqueta
Depois de analisados, os logs podem ser filtrados por campos extraídos. As etiquetas podem ser extraídas como parte do pipeline de log usando expressões de parser e formatador. A expressão do filtro de etiqueta pode então ser usada para filtrar nossa linha de log com qualquer uma dessas etiquetas.
Exemplos
{app="web"} | json | status="500" # Extract JSON, then filter by status=500
{app="db"} | logfmt | user="admin" # Extract key-value logs, filter by user=adminFormato de Linha
Usado para modificar a saída de log extraindo e formatando campos. Isso formata como os logs são exibidos no Grafana.
Exemplo
{app="nginx"} | json | line_format "User {user} encountered {status} error"Formato de Etiqueta
Usado para renomear, modificar, criar ou descartar etiquetas. Aceita uma lista separada por vírgulas de operações de igualdade, permitindo que várias operações sejam realizadas simultaneamente.
Exemplos
1. {app="nginx"} | label_format new_label=old_label. #If a log has {old_label="backend"}, it is renamed to {new_label="backend"}. The original old_label is removed.
2. {app="web"} | label_format status="HTTP {{.status}}" #If {status="500"}, it becomes {status="HTTP 500"}.
3. {app="db"} | label_format severity="critical". #Adds {severity="critical"} to all logs.
4. {app="api"} | drop log_level # Drops log_level Compromissos
O Grafana Loki oferece uma solução de logística escalável e econômica que armazena logs em pedaços comprimidos com um índice mínimo. Isso vem com compromissos no desempenho da consulta e na velocidade de recuperação. Ao contrário de sistemas tradicionais de gerenciamento de logs que indexam o conteúdo completo do log, a indexação baseada em etiquetas do Loki acelera a filtragem.
No entanto, isso pode retardar as buscas de texto complexas. Além disso, embora o Loki se destaque no manuseio de ambientes distribuídos de alto rendimento, ele depende do armazenamento de objetos para escalabilidade. Isso pode introduzir latência e requer uma seleção cuidadosa de rótulos para evitar problemas de alta cardinalidade.
Escalabilidade e Multi-inquilinato
O Loki é projetado para escalabilidade e multi-inquilinato. No entanto, a escalabilidade vem com compensações arquiteturais. Escalar gravações (ingestores) é direto devido à capacidade de particionar logs com base em rótulos. Escalar leituras (consultas) é mais complicado porque consultar grandes conjuntos de dados do armazenamento de objetos pode ser lento. O multi-inquilinato é suportado, mas gerenciar cotas específicas de inquilinos, explosão de rótulos e segurança (isolamento de dados por inquilino) requer uma configuração cuidadosa.
Ingestão Simples Sem Pré-processamento
O Loki não requer pré-processamento porque não indexa o conteúdo completo do log. Ele armazena logs no formato bruto em segmentos comprimidos. Como o Loki não possui indexação de texto completo, consultar logs estruturados (por exemplo, JSON) requer análise LogQL. Isso significa que o desempenho da consulta depende de quão bem os logs são estruturados antes da ingestão. Sem logs estruturados, a eficiência da consulta é prejudicada porque a filtragem deve ocorrer no momento da recuperação, não na ingestão.
Armazenamento em Armazenamento de Objetos
O Loki descarrega segmentos de log no armazenamento de objetos (por exemplo, S3, GCS, Azure Blob). Isso reduz a dependência de armazenamento de bloco caro como, por exemplo, o Elasticsearch requer.
No entanto, a leitura de logs do armazenamento de objetos pode ser lenta em comparação com a consulta direta de um banco de dados. O Loki compensa isso mantendo logs recentes nos ingestores para uma recuperação mais rápida. A compactação reduz a sobrecarga de armazenamento, mas a latência de recuperação de logs ainda pode ser um problema para consultas em grande escala.
Rótulos e Cardinalidade
Como os rótulos são usados para pesquisar logs, eles são críticos para consultas eficientes. Uma rotulagem ruim pode levar a problemas de alta cardinalidade. O uso de rótulos de alta cardinalidade (por exemplo, user_id, session_id) aumenta o uso de memória e diminui a velocidade das consultas. O Loki faz hash dos rótulos para distribuir logs entre os ingestores, portanto, um design ruim de rótulos pode causar uma distribuição desigual de logs.
Filtragem Antecipada
Como o Loki armazena logs brutos comprimidos no armazenamento de objetos, é importante filtrar antecipadamente se quisermos que nossas consultas sejam rápidas. O processamento de análises complexas em conjuntos de dados menores aumentará o tempo de resposta. De acordo com essa regra, uma boa consulta seria a Consulta 1 e uma má consulta seria a Consulta 2.
Consulta 1
{job="nginx", status_code=~"5.."} | jsonA Consulta 1 filtra logs onde job="nginx" e o status_code começa com 5 (erros de 500 a 599). Em seguida, extrai campos JSON estruturados usando | json. Isso minimiza o número de logs processados pelo analisador JSON, tornando-o mais rápido.
Consulta 2
{job="nginx"} | json | status_code=~"5.."A Consulta 2 primeiro recupera todos os logs do nginx. Isso pode ser milhões de entradas. Em seguida, analisa o JSON para cada entrada de log antes de filtrar por status_code. Isso é ineficiente e significativamente mais lento.
Finalizando
O Grafana Loki é um sistema de agregação de logs poderoso e econômico, projetado para escalabilidade e simplicidade. Ao indexar apenas metadados, ele mantém os custos de armazenamento baixos, permitindo consultas rápidas usando LogQL.
Sua arquitetura de microsserviços suporta implantações flexíveis, tornando-o ideal para ambientes nativos de nuvem. Este artigo abordou o básico do Loki e sua linguagem de consulta. Ao navegar pelas características mais importantes da arquitetura do Loki, podemos obter uma melhor compreensão das compensações envolvidas.
Source:
https://dzone.com/articles/grafana-loki-fundamentals-and-architecture