













Введение
В data science, а особенно в прикладной自然语言处理 (Natural Language Processing), обобщение (summarization) является темой интенсивного интереса и всегда был в центре внимания.尽管文本摘要方法已经存在了一段时间,但近年来在自然语言处理和深度学习方面看到了重大发展。在主题上,大型互联网公司,如最近的ChatGPT,发表了许多关于此主题的论文。尽管在这个研究课题上做了大量工作,但关于人工智能驱动的摘要的实践实现却很少有文字记载。解析宽泛的陈述的困难是有效摘要的一个障碍。
摘要新闻文章和财务利润报告是两回事。在处理长度或主题 matter(技术,体育,金融,旅游等)不同的文本特征时,摘要变成了具有挑战性的数据科学任务。在深入了解应用概述之前,必须在摘要理论方面做一些基础工作。
Выдержка
Процесс экстрактивного обобщения заключается в выборе наиболее реlevantных предложений из статьи и систематическом их организации. Предложения, составляющие обобщение, взяты следующими словами из исходного материала.
Системы экстрактивного обобщения, как мы их знаем сейчас, вращаются around три фундаментальные операции:
Строительство промежуточного представления входного текста
Представление по теме и представление индикатора являются примерами методов, основанных на представлениях. Чтобы понять темы, упомянутые в тексте, представление по теме преобразует текст в промежуточное представление.
Оценка предложений на основе представления
В момент генерации промежуточного представления каждое предложение получает оценку значимости. При использовании метода, основанного на представлении по теме, оценка предложения отражает, насколько эффективно оно объясняет ключевые концепции в тексте. В представлении индикатора оценка вычисляется путем агрегирования доказательства от различных взвешенных индикаторов.
Выбор краткого обозрения, состоящего из нескольких предложений
Для генерации краткого обозрения, программа-сводчик выбирает n самых важных предложений. Например, некоторые методы используют стратегию охоты за сохранением выбора, чтобы определить, какие предложения являются наиболее релевантными, в то время как другие могут преобразовать выбор предложений в оптимизационную проблему, в которой подходит набор предложений, сохраняя при этом максимум общей важности и связности, минимизируя при этом количество излишней информации.
Давайте более подробно ознакомься с методами, упомянутыми ранее:
Методы представления темы
Тематические слова: Благодаря этому методу можно обнаружить слова, связанные с темой в входном документе. значимость предложения может быть оценена двумя способами: вначале, как функция количества тематических подписей, оно содержит; во-вторых, как доля тематических подписей, оно содержит.
While первый метод приводит к вышению оценок для длинных предложений с большим количеством слов, второй метод измеряет плотность тематических слов.
Подходы, основанные на частоте: Через этот метод даются относительные важности словам. Если термин соответствует теме, он получает 1 балл; иначе, он достигает нуля. В зависимости от того, как они реализованы, веса могут быть непрерывными. представления темы могут быть достигнуты с помощью одного из двух методов:
Вероятность слов: Она берет частоту слова, чтобы указать ее важность. Чтобы вычислить вероятность слова w, мы делим его частоту встречаемости, f(w), на общее количество слов, N.
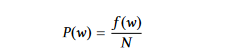
Средняя важность слов в предложении дает важность предложения при использовании вероятности слов.
TFIDF (терминологическая частота обратной документной частоты): Этот метод является улучшением метода вероятности слов. Здесь веса определяются с использованием подхода TF-IDF. Technique TFIDF (Term Frequency Inverse Document Frequency) gives less importance to terms that often appear in most documents. The weight of each word w in document d is computed as follows:
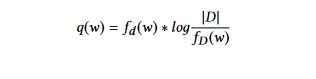
где fd (w) – частота встречаемости слова w в документе d,
fD (w) – количество документов, содержащих слово w, и |D| – количество документов в коллекции D.
Latent Semantic Analysis : Latent semantic analysis (LSA) является ненадзорным методом для извлечения представления текстовой семантики на основе наблюдаемых слов. Процесс LSA начинается со строительства матрицы термо-предложения (n по m), где каждая строка представляет слово из входа (n-слова), а каждая колонка представляет предложение (m предложения). В матрице вес слова i в предложении j определен значением элемента aij . Согласно методу TFIDF, каждое слово в предложении принимает определенный вес, а значение零 присваивается термам, не включенным в предложение.
Методы представления индикаторами
Методы на основе графов
Графовые методы, влияющие на алгоритм PageRank, представляют документы в виде связанного графа. Словарем вершин графа являются предложения, а ребра, соединяющие предложения, показывают степень взаимосвязи между двумя предложениями. Одним из методов, часто используемых для связывания двух вершин, является оценка степени сходства двух предложений, и если степень сходства выше определенного порога, то вершины соединяются. Возможны два результата с помощью этой графической представления. Во-первых, разделы графа (субграфы) определяют индивидуальные категории информации, охваченные документами. Второй результат заключается в том, что ключевые предложения документа были выделены. Предложения, соединенные с многими другими предложениями в разделе,可能是 графом и скорее всего включены в резюме.ECHWORD Both single- and multi-document Summarization can benefit from using graph-based techniques.
Machine Learning
Методы машинного обучения рассматривают проблему резюмевання как проблему классификации. Модели стремятся классифицировать предложения в категории резюме и нерезюме на основе их особенностей. У нас есть тренировочный набор, состоящий из документов и рукописно проверенных выделенных резюме, на котором можно обучить наши алгоритмы. Это обычно делается с использованием Naive Bayes, Decision Tree или Support Vector Machine.
Абстрактная Сводка
В отличие от извлекательного обобщения, абстрактное обобщение является более эффективным методом. Capacity to create unique sentences that convey vital information from text sources has contributed to this rising appeal.
Абстрактный сумmarizer представляет материал в логической, хорошо организованной и грамматически правильной форме. Qualité d’une résumé peut être considérablement améliorée en la rendant plus lisible ou en améliorant sa qualité linguistique. (include image).
Il y a deux approches : La structure basée sur l’approche et l’approche sémantique.
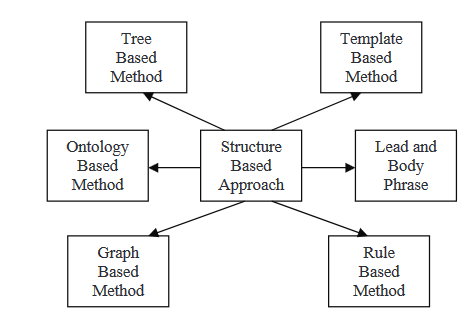
STRUCTURE-BASED APPROACH
Dans une structure premièrement basée sur la méthode, les informations les plus importantes du document (s) sont encodées à l’aide de schémas de caractéristiques psychologiques tels que des modèles, des règles d’extraction et des structures alternatives, y compris l’arbre, l’ontologie, le sommaire et le corps, la règle et la structure graphique. Dans la suite, nous lirons sur certaines des méthodes diverses qui sont intégrées dans cette stratégie.
Деревовидные методы
В этом методе документ представлен в виде дерева зависимостей. Выбор материала для оглавления может осуществляться с помощью нескольких других техник, таких как алгоритм взаимозамыкания темы или тот, который использует местную алгоритмическую настройку привязки между анализированными предложениями. Этот подход использует либо генератор языка, либо алгоритм ассоциированного степени для генерации оглавления. В статье авторы предлагают метод слияния предложений, который использует местное многопотоковое слияние снизу вверх, чтобы найти общие информационные фразы. Системы многогенной резюме используют технику называемую слияние предложений.
В этом методе используется набор документов в качестве входных данных, обрабатываемых алгоритмом выбора темы для извлечения центральной темы, затем используется алгоритм кластеризации для упорядочивания фраз по важности. После упорядочения предложений их сливают с помощью слияния предложений, и генерируется статистическое резюме. Структурированный метод кодирует наиболее важные данные из документа(ов) с помощью психологических схем, таких как шаблоны, правила выделения и альтернативные структуры, такие как дерево, онтология, заголовки и тело, правила и графовые структуры.
Методы на основе шаблонов
В этом методе используется гид для представления всего документа. Языковые модели или критерии выделения сравниваются для идентификации текстовых отрезков, которые могут быть сопоставлены с ячейками гида. Эти текстовые отрезки являются индикаторами единиц контента очерёдности. В этом публикации предложены два метода (однодокументной и многодокументной суммаризации) для суммаризации документов. Чтобы создавать выдержки и аннотации из документов, они следовали методам, описанным в GISTEXTER.
Разработанный для информационного выделения, GISTEXTER — это система суммаризации, которая идентифицирует связанную с темой информацию в входном тексте и преобразует её в записи базы данных; предложения затем добавляются в резюме в зависимости от запросов пользователей.

Методы на основе онтологии
Многие исследователи пытались улучшить эффективность резюме с использованием онтологии (базы знаний). Большинство интернет-документов имеет общий ядро,意味着 они все касаются одной и the same general subject. Oncology is a powerful representation of the unique information structure of each domain.
This paper proposes using fuzzy ontology, which models uncertainty and accurately describes domain knowledge, to summarize Chinese news. In this method, domain experts first define the domain ontology for news events, and then the Document preparation phase extracts semantic words from the news corpus and the Chinese news dictionary.
Lead and body phrase method
This approach involves rewriting the lead sentence by performing operations on phrases (insertion and substitution) with the same syntactic head chunk in the lead and body of the sentence. Using syntactic analysis of phrase pieces, Tanaka suggested a technique for summarizing broadcast news. Sentence fusion methods are used to infer the foundation of this concept.
Разъяснение новостных трансляций предполагает определение фраз, содержащихся в заголовке и теле новости, затем их вставки и замены для создания резюме с помощью редактирования предложений. Сначала применяется синтаксический анализатор для заголовка и тела новостей. Затем идентифицируются пары триггеров для поиска, и, наконец, используются различные критерии сходства и выравнивания для выравнивания фраз. Последний этап может быть either вставкой или заменой или ими оба.
Процесс вставки включает выбор точки вставки, проверку на дублирование и проверку дискурса на внутреннюю согласованность для обеспечения связности и устранения дублирования. Шаг замещения обеспечивает увеличение информации, замещая фразу тела новости в заголовке.
Метод на основе правил
В этом методе документы, которые требуют резюме, изображаются с помощью классов и списка аспектов. Модуль выбора содержимого выбирает наиболее эффективного кандидата из тех, что были созданы правилами экстракции данных, чтобы ответить на один или несколько аспектов категории. Наконец, используются порождающие модели для создания очертательных предложений.
Для идентификации слов, выделяющихся по значению (существительных и глаголов), Пьер-Этьен и др. предложили набор критериев для извлечения информации. После извлечения данные направляются на шаг выбора содержимого, который стремится отфильтровать кандидатов смешанных качеств. Это используется для структуры предложения и слов в прямолинейном построении модели. После генерации производится контент-управляемая обобщение.
Методы на основе графов
MANY RESEARCHERS USE A GRAPH DATA STRUCTURE TO REPRESENT LANGUAGE DOCUMENT. GRAPHS ARE A POPULAR CHOICE FOR REPRESENTING DOCUMENT IN THE LINGUISTICS STUDY COMMUNITY. EACH NODE IN THE SYSTEM STANDS FOR A WORD UNIT THAT, ALONGSIDE DIRECTED EDGES, DEFINES THE STRUCTURE OF A SENTENCE. TO ENHANCE THE PERFORMANCE OF THE SUMMARIZATION, ДИНДИН WANG ET AL. PROPOSED MULTI-DOCUMENT SUMMARIZATION SYSTEMS THAT USE A WIDE RANGE OF STRATEGIES, SUCH AS THE CENTROID-BASED METHOD, THE GRAPH-BASED METHOD, ETC., TO EVALUATE VARIOUS BASELINE COMBINATION METHODS, SUCH AS AVERAGE SCORE, AVERAGE RANK, BORDA COUNT, MEDIAN AGGREGATION, ETC.
A UNIQUE WEIGHTED CONSENSUS METHODOLOGY IS DEVELOPED TO COLLECT THE RESULTS OF DIFFERENT SUMMARIZATION STRATEGIES. IN A SEMANTIC-BASED APPROACH, A LINGUISTIC ILLUSTRATION OF A DOCUMENT OR DOCUMENTS IS USED TO FEED A NATURAL LANGUAGE GENERATION (NLG) SYSTEM. THIS TECHNIQUE SPECIALIZES IN IDENTIFYING NOUN PHRASES AND VERB PHRASES BY LINGUISTIC DATA.
СЕМАНТИЧЕСКИЙ подход
Семантические подходы используют языковую иллюстрацию документа для подачи системе自然语言生成 (NLG). Эта методика обрабатывает языковые данные для идентификации словосочетаний и глагольных фраз.
- Мультимодальный семантический модель: В этом методе создается языковая модель, которая охватывает понятия и связи между идеями, чтобы описать содержимое мультимодальных документов, таких как текст и изображения. Ключевые идеи оцениваются с помощью нескольких критериев, а выбранные понятия затем выражаются в виде предложений для создания резюме.
- Метод, основанный на информационных элементах: В этом подходе, вместо использования предложений из источных документов, используется абстрактное представление этих документов для генерации содержимого резюме. Абстрактное изображение является информационным элементом, который является smallest part of coherent information in a text.
- Семантическая графовая модель: Этот метод направлен на создание резюме документа, строя богатую семантическую граф (RSG) для исходного документа, затем уменьшая созданную языковую графу и генерируя окончательную выделительную о summary from the reduced linguistic graph.
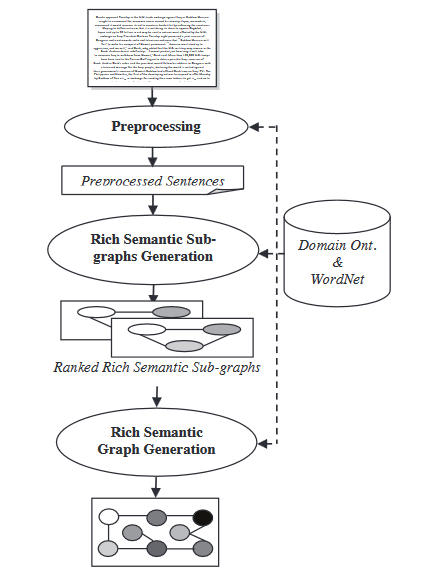
В модуле генерации богатой семантической граф, набор heuristic rules применяется к созданной богатой семантической граф к упрощению ее, слиянию, удалением или консолидированием графовых узлов.
- Семантическая текстовая репрезентация модель: Этот метод анализирует входной текст, используя семантику слов, а не синтаксис/структуру текста.
Примеры деятельности в бизнесе
- Программирование в компьютерных языках: Было предпринято много усилий для разработки технологии AI, способной автономно писать код и разрабатывать сайты. В будущем программисты могут использовать специализированные “обобщатели кода”, чтобы извлечь суть из новых проектов.
- Помощь людям с физическими недостатками: Люди, которые имеют трудности с слухом, могут обнаружить, что обобщения помогают им лучше следовать за содержанием, учитывая прогресс технологии голос-текст.
- Конференции и другие видеосессии: С развитием телеработы, возрастает необходимость в возможности записывать важные идеи и содержание из взаимодействий. Было бы замечательно, если бы ваши командные встречи могли быть обобщены с использованием метода голос-текст.
- Поиск патентов:Find relevant patent information might be time-consuming. A patent summary generator might save you time whether you’re doing market intelligence research or preparing to register a new patent.
- Книги и литература: Обобщения помогают, поскольку они дают читателям краткое представление о содержании книги, которое они могут ждать, прежде чем принять решение о покупке ее.
- Реклама через социальные медиа: Organisationы, которые создают белые книги, электронные книги и блоги компании, могут использовать обобщение, чтобы сделать свои работы более потребительскими и способными к обмену на платформах, таких как Twitter и Facebook.
- Исследование экономики: Деловая профессия инвестиционного банкинга тратит огромные суммы денег на приобретение данных для использования в принятии решений, например, автоматизированной торговли акциями. любой финансовый аналитик, который проводит всю день, изучая рыночные данные и новости, в конечном итоге достигает уровня информационного перегрузки. Финансовые документы, такие как отчеты о прибылях и финансовая информация, могли бы выиграть от систем résumé, которые позволяют аналитикам быстро извлекать рыночные сигналы из содержимого.
- Размещение вашего бизнеса с использованием оптимизации поисковых систем: оценки оптимизации поисковых систем (SEO) требуют глубокого знания тем, которые обсуждены в содержимом конкурентов. Это особенно важно с учетом недавних изменений алгоритмов Google и последующего усиления внимания к авторитету темы. способность быстро определять общность между несколькими документами, идентифицировать общие особенности и просканировать ключевую информацию может стать мощным инструментом исследований.
Заключение
хотя абстрактный обзор менее надежден, чем экстрактивные подходы, он предполагает более удивительные перспективы для создания резюме, соответствующих тому, как люди бы написали их.鉴于此, в этой области, скорее всего, появится множество новых вычислительных, когнитивных и лингвистических техник.
Примечания
Source:
https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques