













개 introduce
데이터 과학 및 특히 자연어 처리에서, 요약은 ALWAYS has been, a subject of intense interest. While text summarization methods have been around for some time, recent years have seen significant developments in natural language processing and deep learning. There is a flurry of papers being published on the topic by internet giants, like the recent ChatGPT. While a great deal of work is being done on this topic of study, there is very little written on practical implementations of AI-driven summarization. The difficulty of parsing broad, sweeping statements is an obstacle to effective summarization.
Summarizing a news article and a financial profits report are two different tasks. When dealing with text features that vary in length or subject matter (tech, sports, finance, travel, etc.), summarizing becomes a challenging data science job. It’s essential to cover some groundwork in summarizing theory before delving into an overview of applications.
Extractive Summarization
选题式摘要是通过对文章进行抽样,从中选取最相关的句子,并系统地组织起来。组成摘要的句子直接来源于原文材料。
我们现在所知道的选题式摘要系统围绕三个基本操作展开:
构建输入文本的中间表示
基于表示的方法包括主题表示和指标表示。为了理解文中提到的主题(们),主题表示将文本转换为中间表示。
根据表示对句子进行评分
在生成中间表示的时候,每个句子都会被赋予一个重要性得分。当使用依赖于主题表示的方法时,句子的得分反映了它如何有效地阐明文中的关键概念。在指标表示中,得分是通过聚合不同加权指标的证据来计算的。
좀 더 많은 문장을 포함하는 요약 선택
요약을 생성하기 위해서, 요약 소프트웨어는 가장 중요한 k개의 문장을 선택합니다. 예를 들어, 某些 方法들은 가격 알고리즘을 사용하여 어느 문장이 가장 relevent하고 있는지 pick하고 choose하는데 사용할 수 있으며, 다른 것들은 문장 선택을 개방적인 문제로 변환할 수 있으며, 이를 통해 문장 集合을 선택하는데 이를 통해 모든 중요성과 촉진, 중복 정보의 양을 최소화하면서 最大化하는 조건을 만족시키는 것입니다.
우리가 말한 方法들을 더 深耕하는 것으로 보겠습니다:
주제 representation 方法
주제 어휘: 이 方法을 사용하면, 입력 문서에서 주제에 관련된 어휘를 찾을 수 있습니다. 문장의 중요성은 두 가지 방법으로 계산할 수 있습니다: 첫째, 그 안에 있는 주제 서명의 수에 의해; 둘째, 그것이 포함하고 있는 주제 서명의 fraction에 의해.
첫 方法은 더 长的하고 더 많은 単語을 가진 문장에 더 높은 得分数를 주지만, 두 번째 method은 주제 어휘의 밀도를 측정합니다.
주파수 駆動 접근 방법: 이 방법을 통해 단어들에 대한 상대적 중요성이 부여되는 것이다. 용어가 주제에 맞다면 1 포인트를 얻고, 아니면 零으로 떨어진다. 어떻게 적용되는지에 따라 가중치는 연속적일 수 있다. 주제 표현을 달성하기 위해서는 두 가지 방법 중 하나를 사용할 수 있다:
단어 확률: 단어의 중요성을 단어의 빈도가 나타내는 것뿐이다. 단어 w의 의사 확률을 계산하면서, 그 빈도 f(w)를 사용하여 전체 단어 수 N로 나누는 것이다.
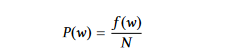
문장에 있는 단어의 평균 중요성은 단어 확률을 사용하여 문장의 중요성을 결정한다.
TFIDF(Term Frequency Inverse Document Frequency): 단어 확률 접근法을 개선한 방법이며, TF-IDF 접근法을 사용하여 가중치를 결정한다. Term Frequency Inverse Document Frequency (TFIDF) 기술은 대부분의 문서에 자주 나타나는 용어에 대해 중요성을 줄이는 것이다. 문서 d에 있는 각 단어 w의 가중치는 다음과 같이 computed되는 것이다:
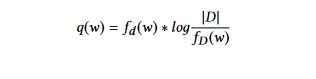
其中 fd (w) 는 문서 d에 있는 단어 w의 용어 빈도, fD (w)는 단어 w를 포함하는 문서의 수, |D|는 コレク션 D에 있는 문서의 수이다.
潜在的语义分析: 潜伏的语义分析(LSA)是基于观察到的词汇,提取文本语义表示的 unsupervised 方法。LSA 过程从构建一个 term-sentence 矩阵(n x m)开始,其中每一行代表输入中的一个词(n 个词),每一列代表一个句子(m 个句子)。在矩阵中,词 i 在句子 j 中的权重由条目 aij 定义。根据 TFIDF 技术,句子中的每个词都有一定的权重,不包含在句子中的词会被分配权重零。
指标表示方法
基于图的方法
그래프 方法的, PageRank 알고리즘 영향을 받은 것이지, 문서를 연결된 그래프로 표현합니다. 문장은 그래프의 頂点(vertex)로, 문장을 연결하는 간선은 두 문장이 서로 어느 정도 관련이 있는지를 보여줍니다. 두 頂点(vertices)를 연결하는 중요한 방법이 있다는 것은, 두 문장이 얼마나 유사한지 평가하는 것입니다. 유사도가 certain threshold 보다 높으면 두 頂点(vertices)가 연결됩니다. 이 그래프 표현은 두 결과를 가질 수 있습니다. 첫째, 그래프의 분할(partitions)는 문서가 涵蓋하는 개별 정보 ategory를 정의합니다. 두 번째 결과는 문서의 клю 문장을 강조하는 것입니다. partition内에서 많은 다른 문장과 연결된 문장은 그래프의 中心(center)일 수 있으며 요약에 포함되는 확률이 높습니다. 그래프를 기반으로 하는 기술을 사용하여 단일 문서 요약과 다양 문서 요약에도 beneficially 영향을 미칠 수 있습니다.
Machine Learning
기계 leaning 기술은 요약 문제를 분류 도전(classification challenge)로 seen합니다. 모델은 문장을 요약 문장과 non-summary 문장 두 category로 기반하여 他们的 feature를 사용하여 분류하려고 합니다. 우리는 문서와 human-reviewed 추출 요약을 포함하는 교육 셋을 가지고 있으며 우리의 알고리즘을 교육합니다. 자주 Naive Bayes, Decision Tree, Support Vector Machine를 사용하여 실시합니다.
추상적 요약
추상적 요약은 extraktiv 요약과 비교하여 더 효율적인 방법입니다. 문헌 ällor에서 중요한 정보를 표현하는 독특한 문장을 생성할 수 있는 능력이 이러한 인기의 상승에 기여하였습니다.
추상적 요약기는 자료를 логически, bien organisé, 以及 기계적으로 correctement 구성하여 보여줍니다. 요약의 quality를 значитель히 향상시키는 것은 더 나은 읽기 가능성 또는 언어적 quality를 改善시키는 것입니다. (이미지 包括).
두 가지 접근法이 있습니다: 구조 기반 접근法和 의미 기반 접근法입니다.
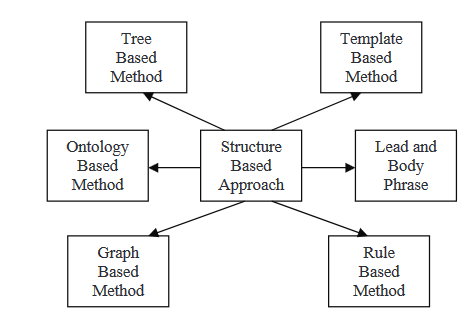
구조 기반 접근法
구조 기반 方法에서, 문서(들)から 最重要 information을 읽어들이는 것은 Plantilla, 抽出 규칙, 以及 alternative structure 등 심리적 feature schema로 가능합니다. tree, ontology, lead and body, rule, 以及 graph-based structure가 包括되어 있습니다. 이러한 战术에 통합되는 다양한 方法에 대해 나后에서 읽어들이게 될 것입니다.
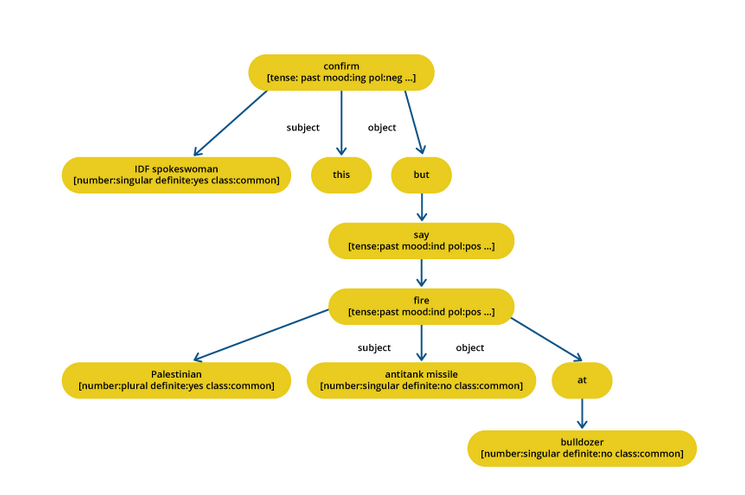
이진 기법
이 기법에서는 문서의 내용을 依存 树(dependency tree)로 표현합니다. 大纲(outline)에 대한 내용 선택은 주제 교집합 알고리즘 프로그램과 같은 다양한 기술, 또는 구문 분석한 문장들 사이의 本土 정렬을 사용하는 것과 같은 기법을 사용하여 수행할 수 있습니다. 이 접근法은 언어 생성기나 assoicate degree 알고리즘을 사용하여 大纲 생성을 실시합니다. 이 논문에서는, 著者들은 하향식 로컬 다중 시퀀스 정렬을 사용하여 공통 정보 문장을 찾기 위한 문장 통합 方法을 제시합니다. 다 gene 요약 시스템은 문장 통합 이름의 기술을 사용합니다.
이 方法에서는, 문서 집합이 입력으로 사용되고, 주제 선택 알고리즘을 사용하여 중심 주제를 추출하고, 그 다음 랩핑 알고리즘을 사용하여 가중치를 기준으로 문장을 排队합니다. 문장들이 ARRanged되면, 문장 통합을 사용하여 통합되고, 통계적 요약을 생성합니다. 구조화된 方法은 문서(들)의 最重要 데이터를 심리적 스키마, 예를 들어 emplate, 추출 규칙과 树, 오ntology, 導言과 본문, 규칙, 그래프 기반 구조와 같은 대체 구조를 사용하여 인코딩합니다.
샘플-기반 방법
이 방법에서는 전체 문서를 표현하는 가이드가 사용되며, 언어 모양 또는 추출 기준과 비교하여 가이드 슬롯에 매핑 가능한 텍스트 스니펫을 식별합니다. 이러한 텍스트 스니펫은 요약 내용의 영역 단위 지시자입니다. 이 논문는 문서 요약에 대한 두 가지 방법(단일 문서 요약과 다중 문서 요약)을 제안합니다. 문서から 샘플과 요약을 생성하기 위해서는 GISTEXTER에 记述된 방법을 遵循しました.
정보 추출을 위해 実装되었으며, GISTEXTER는 입력 텍스트에서 주제 相关工作정보를 식별하고 그것을 데이터 베이스 条目로 변환하는 요약 시스템입니다. 사용자 요청에 따라 문장을 요약에 추가합니다.

ontology-기반 방법
많은 研究人员들은 Ontology(지식 베이스)을 사용하여 요약의 효과를 改善하려고 노력했습니다. 대부분의 인터넷 문서는 공통적인 도메인을 가지고 있으며, 모두 같은 일반적인 주제를 다룰 수 있습니다. Ontology은 각 도메인의 独特한 정보 구조를 强有力하게 표현하는 것입니다.
이 论文는 uncertainty를 建模하고 도메인 지식을 精确诊述하는 fuzzy ontology를 사용하여 중국 新聞를 요약하는 것을 제안합니다. 이 방법에서는 도메인 专家들이 新闻 이벤트의 도메인 ontology를 정의하고, 문서 준비 phase가 news corpus에서 의미 어휘를 추출하고 중국 news 사전을 사용하여 중국 新闻에서 의미 어휘를 추출합니다.
Lead and body phrase method
이 방법은 기사의 導言部分에 대해 문장 片(insertion과 substitution)의 동일한 句法적 头脑 片을 사용하여 rewrite하는 것을 포함합니다. 문장 片의 句法 분석을 사용하여 Tanaka는 방송 新闻 요약 기술을 제안하였습니다. 이 지성 기술은 이 개념의 기반을 推论하기 위해 문장 통합 方法을 사용합니다.
주요 News broadcasting 요약은 头条(lead chunk)과 본문(body chunk)에서 공통되는 phases를 찾는 것을 통해, 这些 phases를 삽입하고 대체하여 요약을 생성하는 과정을 포함합니다. まず, 문법 분석器(syntactic parser)를 头条과 본문 chunk에 적용합니다. 다음으로, 트리거 조합(trigger search pairs)을 식별하고, 다양한 유사도와 對齐 기준을 사용하여 phases를 대응시키ます. 마지막 段階은 삽입이나 대체, 또는 両方의 것을 sein 할 수 있습니다.
삽입 과정은 삽입 지점을 선택하고 중복을 检查하고 대화를 내rior coherence를 확인하여 의미 하고 중복을 제거하는 것입니다. 대체 단계는 头条 chunk의 본문 phases로 대체되어 更多信息을 제공합니다.
규칙 기반 방법
이 기술에서, 요약을 생성할 문서는 клас스로 표현되고 요소 목록이 있습니다. 내용 선택 모듈은 데이터 추출 규칙에 의해 생성된 候補 중에서 가장 효과적인 것을 선택하여 cateogry의 하나 이상의 요소에 대한 답변을 위한 것입니다. inally, 생성 패턴을 사용하여 过大 outline sentences를 생성합니다.
Pierre-Etienne et al. 는 의미적으로 관련있는 명명과 동사를 식별하기 위해 정보 추출에 대한 一套의 기준을 제안했습니다. 추출한 데이터는 다음으로 コン텐츠 선택 단계로 보내집니다. 이 단계는 혼합 候補들을 過濾하는 努力을 하고 있습니다. 직진적인 생성 패턴의 문장과 단어에 사용되며, 생성 후에는 내용 지시적인 요약이 수행됩니다.
그래프 기반 방법
많은 연구자들은 그래프 데이터 구조를 언어 文書을 표현하기 위해 사용한다. 그래프는 언어학 공학 지역 community에서 문서를 표현하기 위해 인기 있는 선택이다. 시스템 안의 각 노드는 구문의 구조를 정의하는 단어 単位를 대표하며, 가이드 辺(directed edge)를 통해 구성되는 것이다. 요약의 성능을 향상시키기 위해 Dingding Wang et al.는 센서hd(centroid-based) 방법, 그래프 기반 방법과 같은 멀티 문서 요약 시스템을 제안하였으며, 평균 점수, 평균 랭크, Borda 计数, 미디안 결합 등의 다양한 기반 조합 방법을 평가하였다.
다양한 요약 strategiess의 결과를 수집하기 위해 독특한 가중치 기반 일치 수ategymology를 발전하였다. 의미 기반의 접근法으로는 문서 또는 문서의 언어적 설명을 사용하여 자연어 생성(NLG) 시스템에 입력하며, 이 기술은 언어 데이터를 이용해 명명 구문과 동사 구문을 식별하는 것을 specialize한다.
SEMANTIC-BASED APPROACH
의미 기반의 접근法은 문서의 언어적 설명을 사용하여 자연어 생성(NLG) 시스템에 입력한다. 이 方法은 언어 데이터를 处理하여 명명 구문과 동사 구문을 식별한다.
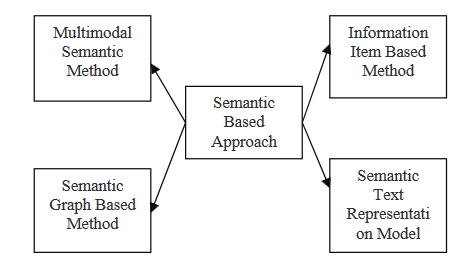
- 멀티모달 의미 모델: 이 방법에서는 언어학 모델을 사용하여 텍스트와 이미지가 포함된 멀티모달 문서의 내용을 描述합니다. 주요 아이디어에 대한 여러 기준을 사용하여 평가하고, 선택된 개념을 문장으로 표현하여 요약을 구성합니다.
- 정보 아이템 기반 方法: 이 접근法은 공급 문서의 문장을 사용하지 않고, 문서의 요약 내용을 생성하기 위해 문서의 요약적인 representation을 사용합니다. 요약적인 이미지는 텍스트 내에서 cohorent information의 smallest part인 정보 아이템입니다.
- 의미 그래프 모델: 이 기술은 초기 문서에 대한 가시한 의미 그래프(RSG)를 構築하여 문서를 요약하고, 생성한 언어 학적 그래프를 줄이고, 줄여진 언어 학적 그래프から 最终的 요약적인 概要를 생성합니다.
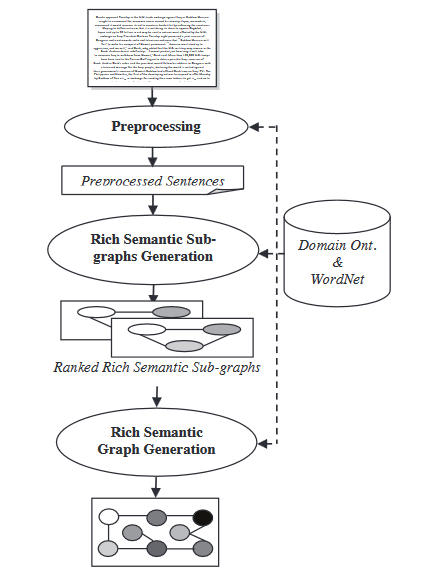
Rich semantic graph 생성 모듈 동안, 생성된 rich semantic graph에 대한 一套의 启发적 규칙을 적용하여 그래프 노드를 통합하거나 제거하거나 통합하여 그래프를 减小시킵니다.
- 의미 텍스트 representation 모델: 이 기술은 입력 텍스트를 문장의 구조/syntax를 사용하지 않고 단어의 의미로 분석합니다.
사업에서 사례 연구
- 컴퓨터 언어 프로그래밍: AI 기술이 자동으로 코드를 썼다가 웹사이트를 開発할 수 있는 기술을 발전시키기 위해 다양한 노력이 made to develop AI technology capable of independently writing code and developing websites. In the future, programmers may be able to rely on specialized “code summarizers” to extract the essentials from novel projects.
- 身体障害者를 辅助する: 聞こえるのが困難な人々은 声音到文本技术が進歩するにつれて、要約がコンテンツについてより良く理解することができるかもしれません。
- 会議 및 다른 비디오 미팅: 遠隔勤務の拡大に伴い、対話から重要なアイデアやコンテンツを記録する能力は、徐々に増加しています。チーム会議を音声到文本方法で要約することが素晴らしいと考えるかもしれません。
- 特許の探求: 関連性のある特許情報を見つけるのは時間を要するかもしれません。特許要約生成器は、市場インテリジェンス研究を行ったり新しい特許を登録する準備をしたりしているときに、あなたの時間を節約するかもしれません。
- 書籍と文学: 要約は、本に入っているコンテンツについて簡潔な概要を与えるために有用です。本を購入する前に、本に入るコンテンツについて簡潔な概要を知ることができます。
- ソーシャルメディアを通じた広告: ホワイトパapper、電子本、会社のブログを作成する組織は、要約を使用して、ツイッターやフェイスブックなどのプラットフォームでdigestible and shareableにすることができます。
- 경제 연구: 투자 銀行 업계는 컴퓨터 aided 주식 거래 등 결정에 사용할 데이터 acquisition에 대해 immense sums of money을 투자하고 있다. 하루 종일 시장 데이터와 news를 judicial examination하는 모든 재정 분석가는 결국 정보 과부하를 经验和하게 한다. 수익 보고서와 재정 news와 같은 재정 문서는 분석가들이 swiftly market signals를 content를 통해 추출할 수 있는 summary systems를 도울 수 있으며 이를 도울 수 있을 것이다.
- 사업을 搜索引擎 optimization을 통해 홍보하는 것: search engine optimization (SEO) 평가는 竞争对手의 content에 있는 주제에 대한 깊은 familiarity이 필요하다. Google의 최근 algorithm modification과 그 후의 subject authority를 중요시하는 것을 고려하면 더욱 중요하다. 여러 documents를 swiftly summary하고, commonalities를 identify하고, 중요한 정보를 scan하는 ability는 强力的な research tool가 될 수 있다.
결론
尽管 abstractive summarizing는 extractive approaches보다 신뢰성이 낮い지만, 사람들이 쓸 것처럼 일치하는 summaries를 생성하는 데에 더욱 감사ble promise를 가지고 있다. 따라서, 이 영역에서 많은 fresh computational, cognitive, linguistic techniques이 자리 잡을 것이다.
参考文献
Source:
https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques