













紹介
データ科学において、特に自然言語処理において、要約は常に热い研究段階であり、いつものことです。テキスト要約の方法はいつものようにあったが、近年、自然言語処理と深層学习において重要な発展が見られています。インターネットの巨大企業が最近のChatGPTのように、この题材に関する多くの論文を発表しています。この研究题材には多くの取り組みが行われていますが、AI駆動の要約の実践的な実装に関する記述はほとんど存在しません。幅広い、大幅な声明を解析することの困難は、効果的な要約に壁を作ります。
ニュース記事を要約すると、財務利益報告書を要約するはまったく異なる作業です。テキスト特徴が長さや主題によって変わる場合(テクノロジー、スポーツ、財務、旅行など)、要約は難しいデータ科学の仕事となります。要約理論の基础を学ぶことが重要であり、その後、適用の概要に入ります。
抽出的な要約
抽出行文のプロセスは、記事から最も関連性のある文を選び、体系的にそれらを組織することで構成されます。概要を構成する文は、原文材料から直接引用されます。
現在の抽出行文システムは、3つの基本的な操作に围绕しています。
入力テキストの中介的な表現の構築
选题表現と指标表現は、表現基盤方法の例です。テキスト内で提到了される主题について理解するために、选题表現はテキストを中介的な表現に変換します。
表現に基づいて文を評価する
中介的な表現の生成の時に、各文に重要度スコアが与えられます。选题表現に基づく方法を使用する場合、文のスコアは、それがテキストの重要な概念を明らかにする効果的性を反映しています。指标表現では、異なる重み付けされた指標から証拠を集積してスコアを計算します。
いくつかの文章を含む要約の選定
要約を生成するために、要約生成ソフトは最も重要で相关性の高い文章を選択するトップ k 文を選択する。例えば、いくつかの方法では、贪欲法則を用いて最も関連性の高い文を選び出し、他の方法では、文の選択を最適化問題として変換し、文の集合が最も重要で统一性を持ち、重複しすぎない情報を最小限に保ちながら選ばれることを保証することを条件にして選択される。
今お話しした方法に深入りしましょう:
トピック表現アプローチ
トピック語:この方法を使用すると、入力文にトピックに関連した語を見つけることができます。文の重要性は2つの方法で計算できます:まず、トピックのサインaturesを含んでいる文の数に関する関数;そして、2番目に、トピック語の密度に対する割合です。第1の方法はより長い文や更多の語を持つ文により高いスコアを与えますが、第2の方法はトピック語の密度を測定します。
周波数駆動のアプローチ:この方法を通じて、言葉は相対的な重要性を与えられます。その用語がトピックに合致する場合は1ポイント、そうでない場合は0になります。実装方法によって、重みは連続的になることもあります。トピック表現は2つの方法のいずれかを用いることで実現できます:
単語の概率:単語の出現頻度だけを用いてその重要性を示すことです。単語wの出現の可能性を計算するためには、wが出現する频率f(w)を全ての単語の数Nに比べて割ることです。
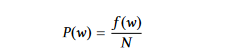
文の中の単語の平均重要性は、単語の出現の可能性を用いて文の重要性を与えます。
TFIDF(Term Frequency Inverse Document Frequency):この方法は、単語の出現の可能性のアプローチを改善しています。ここでは、TF-IDFアプローチを用いて重みを決定します。Term Frequency Inverse Document Frequency (TFIDF)技術は、多くの文書によく出現するときに重要性を低減します。文書d中の各単語wの重みは以下のように計算されます:
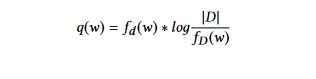
其中、fd (w)は文書d中の単語wのterm frequency、fD (w)は単語wを含む文書の数、|D|はコレクションD中の文書の数です。
潜在的语义分析: 潜在的语义分析(LSA)は、観察された語と文の関係に基づいて、テキストの意味表現を抽出する非監督的な方法です。LSAのプロセスは、n×mの語句矩形行列の構築を始めます。ここで、各行は入力の語(nの語)を表し、各列は文(mの文)を表します。この矩形行列で、語iが文jにおける重みは、エントリーaijによって定義されます。TFIDF技術に従って、文の中の各語は一定の重みを与えられ、文に含まれない語には零の重みが割り当てられます。
指标表現手法
グラフ基方法
グラフ方法は、PageRankアルゴリズムに影響を受けて、文書を接続されたグラフとして表現する。文の頂点となる文句と、文句間のエッジは、2つの文がお互いにどの程度関連しているかを示している。2つの頂点をリンクするためには、2つの文が似ている程度を評価する方法が一般的で、似性の程度が特定の閾値を超える場合、頂点は接続される。このグラフ表現では、2つの結果が可能である。まず、グラフの分割(サブグラフ)は、文書に含まれる情報の個别的なカテゴリを定義する。第2の結果は、文書のキー文が強調されていることである。分割内で多くの他の文に接続されている文は、おそらくグラフの中心に位置しており、要約に含まれる可能性が高いであろう。グラフ基の技術を使用することで、単一文書や複数文書の要約にどちらも利益がある。
機械学習
機械学習技法は、要約問題を分類問題として見ている。モデルは、特徴に基づいて、文が要約と非要約のカテゴリに分类することを試みる。私たちは、文書と人間による审査された抽出された要約から成るトレーニングセットを持っており、これを利用してアルゴリズムをトレーニングする。これは通常、ナイブベイス、決定木、またはサポートベクターマシンを使用して行われる。
抽象的な要提高
抽出行のサマリーとは対照的に、抽象的な要提高はより効果的な手法です。テキスト源から重要な情報を伝達する独自の文を作る能力が、この関心の高まりに貢献しています。
抽象的な要提高は、論理的で整然と組織され、文法に従っている形で資料を示します。より読みやすくすることや、言語の品質を向上させることによって、サマリーの品質を大幅に向上させることができます。(画像を含む)
2つの取り組み方があります:構造ベースの取り組み方と意味ベースの取り組み方です。
構造ベースの取り組み方
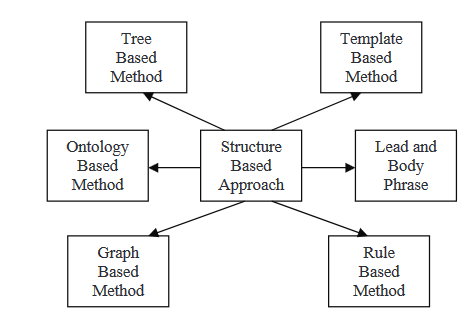
構造ベースの取り組み方では、文書(の複数)から最も重要な情報を、テンプレート、抽出ルール、代替構造など心理的な特性スキーマを使用してエンコードします。これには、ツリー、オントロジー、レッドとボディ、ルール、およびグラフベースの構造が含まれます。以下では、この戦略に組み込まれたいくつかの方法について読み込むことができます。
木構造の手法
この手法では、文書の内容を依存木として表現します。アウトラインの内容選択は、トピック交差アルゴリズムなどのさまざまな技術を用いて行われます。この取り組みでは、言語生成器または関連度アルゴリズムを用いてアウトライン生成を行います。この論文では、著者が下位の局部的なマルチシーケンスアラインメントを用いる方法を提唱しています。マルチゲノサマリーシステムは、文句融合と呼ばれる技術を用います。
この手法では、複数の文書のセットが入力とし、トピック選択アルゴリズムを用いて中心テーマを抽出し、その後、クラスタリングアルゴリズムを用いて重要度の順に phrases を並べます。文が整列された後、文句融合を用いて結合され、統計的な要提高が生成されます。構造化された手法は、文書(複数の文書)から最も重要なデータを心理的スキーマとして変換します。例えば、テンプレートや抽出行き则などの心理的スキーマを用います。また、木、オントロジー、リードと本文、規則、およびグラフ基の構造などの代替的な構造も用います。
テンプレート基礎の手法
この方法では、全体の文書を表現するガイドを使用します。言語パターンまたは抽出基準と比較することで、ガイドのスロットにマッピングできるテキストのスニペットを识別します。これらのテキストのスニペットは、アウトラインコンテンツの領域単位の指标です。この論文は、文書の要提高について2つの手法(単文書要提高抽取とマルチ文書要提高抽取)を提案しました。文書から抽出を作成し、要提高を抽出するために、GISTEXTERで説明された手法に従っています。
情報抽出のために実装され、GISTEXTERは、入力テキスト内のトピック関連情報を特定し、データベースエントリに変換する要提高抽取システムであり、ユーザーの要求に基づいて要提高に句を追加します。

オントロジー基础の手法
多くの研究者が、知識ベースを使用して要約の効果を改善しようと試みてきました。多くのインターネット文書は共通の領域を持っており、すべて同じ一般的な主題に取り組んでいます。知識ベースは、各領域の独特な情報構造を強力に表現することができます。
この論文は、不確実性を模倣し、領域知識を正確に描述する模糊知識ベースを使用して、中国のニュースを要約する方法を提案します。この方法では、領域の専門家がまずニュース事件の領域知識を定義し、次にドキュメント準備段階でニュースコーパスから意味のある語を抽出し、中国のニュース辞書に基づいています。
先行句と本文句法方法
この手法は、先行句と本文の同一の句法頭チャンクに対する短語(插入と置換)の操作を行い、先行句を再稿しようとします。句片の句法分析を使用して、田中は放送ニュースの要約技術を提案しました。この概念の基礎を推論するために、文 fusion 方法が使用されます。
ニュース報道を要約するためには、主要な部分と本文部分に共通するphraseを特定し、それらphraseを挿入して置き換えることで、文 revisionを通じて要約を生成する必要があります。まず、 leadsとbody部分に対してsyntactic parserを適用します。次に、trigger search pairsを特定し、最後に、various similarityとalignment criteriaを使用してphraseをalignします。最後の段階は、挿入または置換、もしくは両方のことです。
挿入プロセスは、挿入点を選び、redundancyを確認し、discourseの内部のcoherenceを確認して、coherencyとredundancyの排除を Ensureする必要があります。置換段階は、lead chunk内のbody phraseをsubstituteして、より多くの情報を提供します。
規則ベースの方法
この技術では、要約されるドキュメントは、クラスとaspectのリストのtermsで表されます。コンテンツ選択モジュールは、data extraction rulesによって生成された候補の中から最も有効なcandidateを選び、1つまたは複数のaspectに答えることができます。最後に、生成パターンは、outline sentencesの生成に使用されます。
Pierre-Etienne などが、意味的に関連した名詞と動詞を特定するために、情報抽出にたいする一套の基準を提唱しました。抽出されたデータは、混在候補を除去することを目指した内容選択段階に送られます。これは、文の構造や直接生成パターンに従って単語に使用されます。生成の後、内容指導的な要提高を行います。
グラフ基の手法
多くの研究者が言語文書を表現するためにグラフデータ構造を使用しています。グラフは言語学研究コミュニティで文書を表現するための一般的な選択肢です。システム内の各ノードは単語単位を表し、有向エッジと共に文の構造を定義します。要約の性能を向上させるために、Dingding Wang et al.は、セントロイドベースの方法やグラフベースの方法など、様々なベースライン組み合わせ方法を評価するための様々な戦略を用いるマルチドキュメント要約システムを提案しました。異なる要約戦略の結果を集めるために、独自の重み付けコンセンサス手法が開発されています。意味ベースのアプローチでは、文書または文書の言語的表現を自然言語生成(NLG)システムに供給します。この技術は、言語データによって名詞句および動詞句を特定することに特化しています。
意味ベースのアプローチ
意味ベースのアプローチは、文書の言語的表現を使用して自然言語生成(NLG)システムに供給します。この方法は、言語データを処理して名詞句および動詞句を特定します。
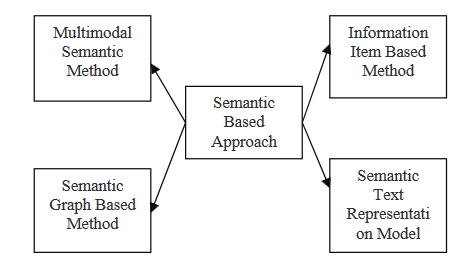
- マルチモーダルセマンティックモデル:この方法では、テキストや画像などのマルチモーダル文書の内容を説明するために、概念と考えの間の関係を捕らえる言語モデルを作成します。キーアイデアはいくつかの基準で評価され、選ばれた概念を句子として表現して要約を形成します。
- 情報アイテムベースの方法:このアプローチでは、供給文書の句子を使用する代わりに、それら文書の抽象的表現を使用して要約の内容を生成します。抽象的な表記は、テキスト内の一意の情報を表す最小单位的な一連の情報です。
- 意味 Structure Graph Model:この技術では、最初の文書に対して豊かな意味 Structure グラフ(RSG)を構築し、その後構築した言語 Structure グラフを缩約し、缩約後の言語 Structure グラフから最終的な要約的な概要を生成します。
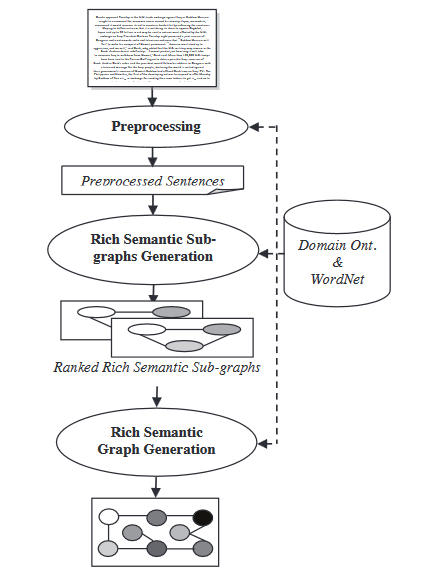
豊かな意味 Structure グラフ生成モジュールにおいて、生成された豊かな意味 Structure グラフに対して一組のヒューリスティックルールを適用し、グラフノードを合体、削除または統合することで缩約します。
- 意味 Text Representation Model:この技術では、入力テキストを、文の構造/スyntaxを syntax/Structure として使用する代わりに、単語の意味 Structure を使用して分析します。
ビジネスの事例研究
- コンピュータ言語プログラミング:AI技術には独自のコードやウェブサイトを開発することができるように多くの努力が投じられています。将来、プログラマーは新しいプロジェクトから重要な部分を抽出するためにSpecialized “code summarizers”を依頼することができるようになるかもしれません。
- 身体障害者の支援:聞こえ难しい人々は、音声からテキストに変換する技術が進化するにつれて、要約が内容に対してよりよく従っていくことができるかもしれません。
- 会議や他のビデオ会議:テレワークが拡大するにつれて、交流から重要なアイデアや内容を記録する能力が求められるようになりました。声をTEキストとしてメソッドを使用して、あなたのチームセッションを要約することが素晴らしいです。
- 特許の探求:関連する特許情報を見つけるのは時間を要するかもしれません。特許要約生成器は、市場インテリジェントリサーチを行うか新しい特許を登録する準備をする际に時間を節約するかもしれません。
- 本と文学:要約は便利で、本に入る内容について簡潔な概観を提供してくれます。購入する前に本について考えることができます。
- ソーシャルメディアを通じた広告:ホワイトピース、電子書籍、会社のブログを作成する組織は、要約を使用して、ツイッターやフェイスブックなどのプラットフォームで易しくdigestibleと共有することができます。
- 経済研究:投資銀行業界は、コンピュータ化された株式取引などの決断に使用するために、大量のお金をデータ取得に投資しています。市場データとニュースを一日中に取り組んでいる金融アナリストは、いつしか情報過剰状態に至ります。財務報表や財務ニュースなどの金融文書は、アナリストが素早く市場信号を抽出することができる要約システムによっても有益かもしれません。
-
ビジネスを促進するための搜索引擎最適化:搜索引擎最適化(SEO)評価は、ライバルのコンテンツにある議論の内容に熟悉など、深い知識が必要です。グーグルの最近のアルゴリズム変更およびそれに続く主題権威への重视により、最優先事項となります。複数の文書を素早く要約し、共通点を特定し、重要な情報を探す能力は、強力な研究ツールとなるかもしれません。
結論
抽象的な要約は、抽出行の手法よりも信頼性が低いかもしれませんが、人間が書くような要約を生成することに対する大きな可能性を秘めています。そのため、この分野では、多くの新しい計算、认知、そして言語技術が飛び出ることが予想されます。
参考文献
Source:
https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques