













Это часть цифровой трансформации гиганта в сфере недвижимости. В целях конфиденциальности я не буду раскрывать никаких коммерческих данных, но вы получите подробное представление о нашем хранилище данных и наших стратегиях оптимизации.
Теперь давайте начнем.
Архитектура
Логически наша архитектура данных может быть разделена на четыре части.
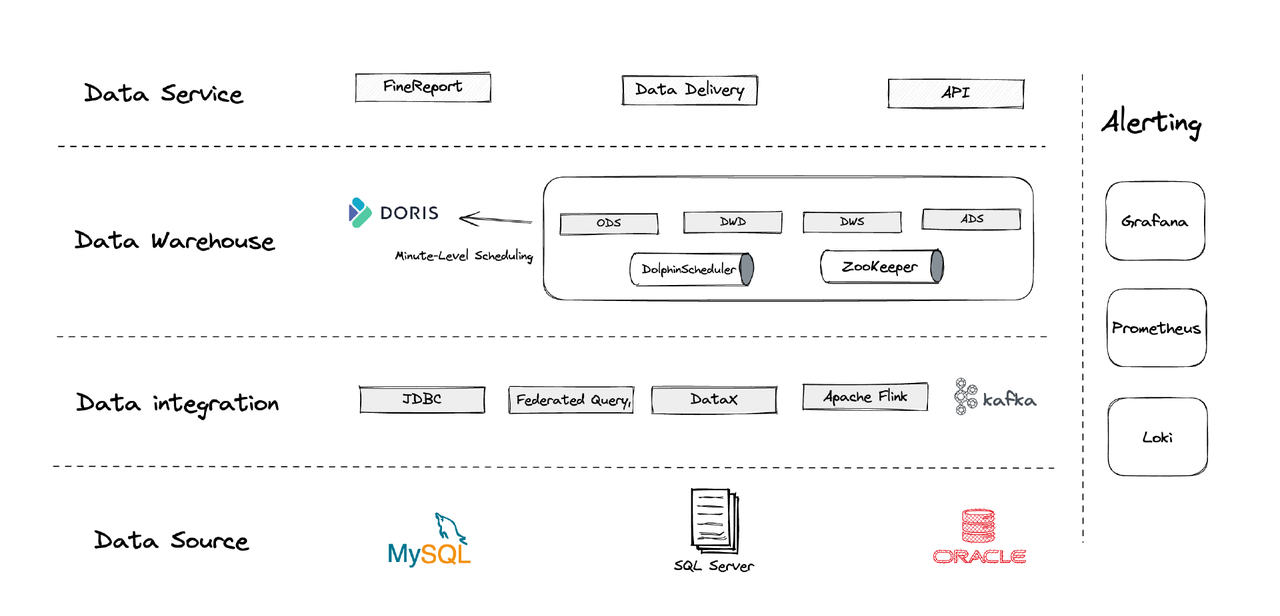
- Интеграция данных: Это обеспечивается с помощью Flink CDC, DataX и функции Multi-Catalog в Apache Doris.
- Управление данными: Мы используем Apache Dolphinscheduler для управления жизненным циклом скриптов, привилегиями в управлении мультитенантностью и мониторингом качества данных.
- Оповещения: Мы используем Grafana, Prometheus и Loki для мониторинга ресурсов компонентов и логов.
- Сервисы данных: Здесь в игру вступают инструменты BI для взаимодействия с пользователями, такие как запросы данных и анализ.
1. Таблицы
Мы создаем наши измерения таблиц и таблицы фактов, центрируя каждую операционную сущность в бизнесе, включая клиентов, дома и т. д. Если есть серия действий, связанных с той же операционной сущностью, они должны быть зарегистрированы одним полем. (Это урок, извлеченный из нашей предыдущей хаотичной системы управления данными.)
2. Уровни
Наше хранилище данных разделено на пять концептуальных уровней. Мы используем Apache Doris и Apache DolphinScheduler для планирования скриптов DAG между этими уровнями.

Каждый день слои проходят полное обновление, кроме инкрементальных обновлений в случае изменений в полях исторического статуса или неполной синхронизации данных таблиц ODS.
3. Стратегии инкрементального обновления
(1) Установите where >= "activity time -1 day or -1 hour" вместоwhere >= "activity time
Причина в том, чтобы предотвратить дрейф данных, вызванный временным лагом в расписании скриптов. Предположим, интервал выполнения установлен на 10 минут, и предположим, что скрипт выполняется в 23:58:00, а новое данные поступают в 23:59:00. Если мы установим where >= "activity time, этот кусок данных дня будет пропущен.
(2) Заберите ID наибольшего первичного ключа таблицы перед каждым выполнением скрипта, сохраните ID в вспомогательной таблице и установитеwhere >= "ID в вспомогательной таблице"
Это предотвращает дублирование данных. Дублирование может произойти, если вы используете модель Unique Key Apache Doris и назначаете набор первичных ключей, потому что если в исходной таблице произойдут какие-либо изменения в первичных ключах, эти изменения будут записаны, и соответствующие данные будут загружены. Этот метод может это исправить, но он применим только тогда, когда исходные таблицы имеют автоинкрементные первичные ключи.
(3) Разделите таблицы
Что касается данных с автоувеличением по времени, таких как журналы, историческая информация и статус могут изменяться реже, но объем данных велик, что может создавать значительную вычислительную нагрузку при общих обновлениях и создании снимков. Поэтому лучше разбить такие таблицы на части, чтобы при каждом внесении изменений нужно было заменить только одну часть. (Также стоит следить за дрейфом данных.)
4. Стратегии общего обновления
(1) Удаление таблицы
Очистить таблицу и затем загрузить все данные из исходной таблицы в нее. Это применимо для небольших таблиц и ситуаций, когда в полночь нет активности пользователей.
(2) ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
Это атомарная операция, и ее рекомендуется использовать для больших таблиц. Перед каждым выполнением скрипта создаем временную таблицу с такой же схемой, загружаем в нее все данные и заменяем оригинальную таблицу.
Применение
- Задача ETL: каждую минуту
- Настройка для первоначальной развертываемости: 8 узлов, 2 фронтенда, 8 бэкэндов, гибридное развертывание
- Конфигурация узла: 32C * 60GB * 2TB SSD
Это наша конфигурация для ТБ старых данных и ГБ инкрементальных данных. Вы можете использовать ее в качестве справки и масштабировать свой кластер на этой основе. Развертывание Apache Doris простое. Вам не нужны другие компоненты.
1. Для интеграции офлайн-данных и логов мы используем DataX, который поддерживает формат CSV и читает данные из множества реляционных баз данных, а Apache Doris предоставляет DataX-Doris-Writer.

2. Мы используем Flink CDC для синхронизации данных из исходных таблиц. Затем мы агрегируем реальные метрики с помощью Materialized View или Aggregate Model от Apache Doris. Поскольку нам нужно обрабатывать только часть метрик в реальном времени и мы не хотим создавать слишком много соединений с базой данных, мы используем одну задачу Flink для поддержки нескольких исходных таблиц CDC. Это реализовано благодаря функциям объединения нескольких источников и полной синхронизации базы данных в Dinky, либо вы можете самостоятельно реализовать задачу объединения нескольких источников в Flink DataStream. Следует отметить, что Flink CDC и Apache Doris поддерживают изменение схемы.
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. Мы используем SQL-скрипты или “Shell + SQL” скрипты и управляем жизненным циклом скриптов. На уровне ODS мы пишем общий файл задачи DataX и передаем параметры для каждой исходной таблицы, а не пишем задачу DataX для каждой таблицы. Таким образом, мы значительно упрощаем обслуживание. Мы управляем ETL-скриптами Apache Doris в DolphinScheduler, где также проводим управление версиями. В случае ошибок в производственной среде мы всегда можем откатиться.
4. После загрузки данных с помощью ETL-скриптов мы создаем страницу в нашем инструменте отчетности. Мы назначаем различные привилегии разным учетным записям с помощью SQL, включая привилегию изменения строк, полей и глобальных словарей. Apache Doris поддерживает контроль привилегий над учетными записями, что работает аналогично тому, как это делается в MySQL.
Мы также используем резервное копирование данных Apache Doris для аварийного восстановления, журналы аудита Apache Doris для мониторинга эффективности выполнения SQL, Grafana+Loki для оповещения о метриках кластера и Supervisor для мониторинга демон-процессов компонентов узла.
Оптимизация
Загрузка данных
Мы используем DataX для потоковой загрузки офлайн-данных. Это позволяет нам регулировать размер каждой партии. Метод Stream Load возвращает результаты синхронно, что удовлетворяет потребности нашей архитектуры. Если мы выполняем асинхронную импорт данных с использованием DolphinScheduler, система может предположить, что скрипт был выполнен, и это может вызвать беспорядок. Если вы используете другой метод, мы рекомендуем выполнить show load в скрипте оболочки и проверить статус фильтрации по регулярному выражению, чтобы увидеть, успешно ли выполнена загрузка.
Модель данных
Мы применяем модель Unique Key Apache Doris для большинства наших таблиц. Модель Unique Key обеспечивает идемпотентность скриптов данных и эффективно избегает дублирования данных из источника.
Чтение внешних данных
Мы используем функцию Multi-Catalog Apache Doris для подключения к внешним источникам данных. Она позволяет создавать сопоставления внешних данных на уровне Каталога.
Оптимизация запросов
Рекомендуем размещать наиболее часто используемые поля несимвольных типов (например, int и условия where) в первых 36 байтах, чтобы можно было фильтровать эти поля в течение миллисекунд при точечных запросах.
Словарь данных
Для нас важно создать словарь данных, так как это значительно снижает затраты на коммуникацию между сотрудниками, что может быть проблемой при большой команде. Мы используем information_schema в Apache Doris для создания словаря данных. С его помощью мы быстро получаем представление о всех таблицах и полях, что повышает эффективность разработки.
Производительность
Время ввода оффлайн-данных: В течение нескольких минут
Задержка запроса: Для таблиц, содержащих более 100 миллионов строк, Apache Doris отвечает на ad-hoc запросы в течение одной секунды и на сложные запросы в течение пяти секунд.
Расход ресурсов: Для построения этой базы данных требуется небольшое количество серверов. Коэффициент сжатия Apache Doris 70% позволяет экономить много места для хранения.
Опыт и выводы
На самом деле, прежде чем мы перешли к текущей архитектуре данных, мы пробовали Hive, Spark и Hadoop для создания оффлайн-базы данных. Оказалось, что Hadoop был излишне мощным для традиционной компании, подобного нам, поскольку у нас не было слишком много данных для обработки. Важно найти компонент, который подходит именно вам.
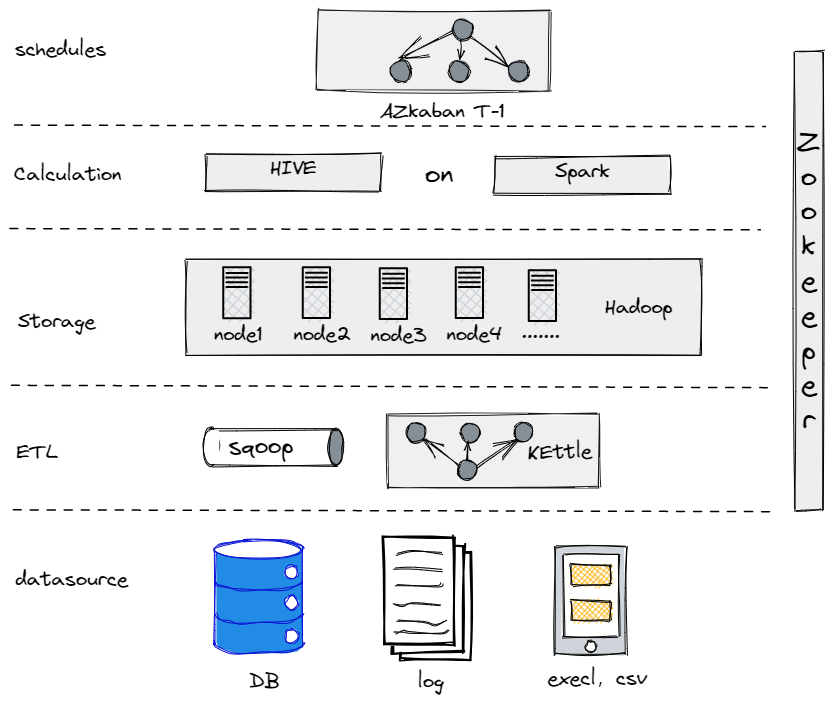
Наша Старая Оффлайн-Базы Данных
С другой стороны, для упрощения перехода к большим данным нам необходимо сделать нашу платформу данных максимально простой как в использовании, так и в обслуживании. Вот почему мы остановились на Apache Doris. Он совместим с протоколом MySQL и предлагает богатый набор функций, поэтому нам не нужно разрабатывать свои собственные UDF. Кроме того, он состоит всего из двух типов процессов: фронтенд и бэкенд, что упрощает масштабирование и отслеживание.
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry