













זהו חלק מההתפתחות הדיגיטלית של ענף הנדל"ן הגדול הזה. לשם סודיות, אני לא אחשוף כל מידע עסקי, אך תקבלו תצוגה מפורטת של מאגר הנתונים שלנו ושיטות האופטימיזציה שלנו.
בואו נתחיל.
ארכיטקטורה
היררכית, ארכיטקטורת הנתונים שלנו נחלקת לארבעה חלקים.
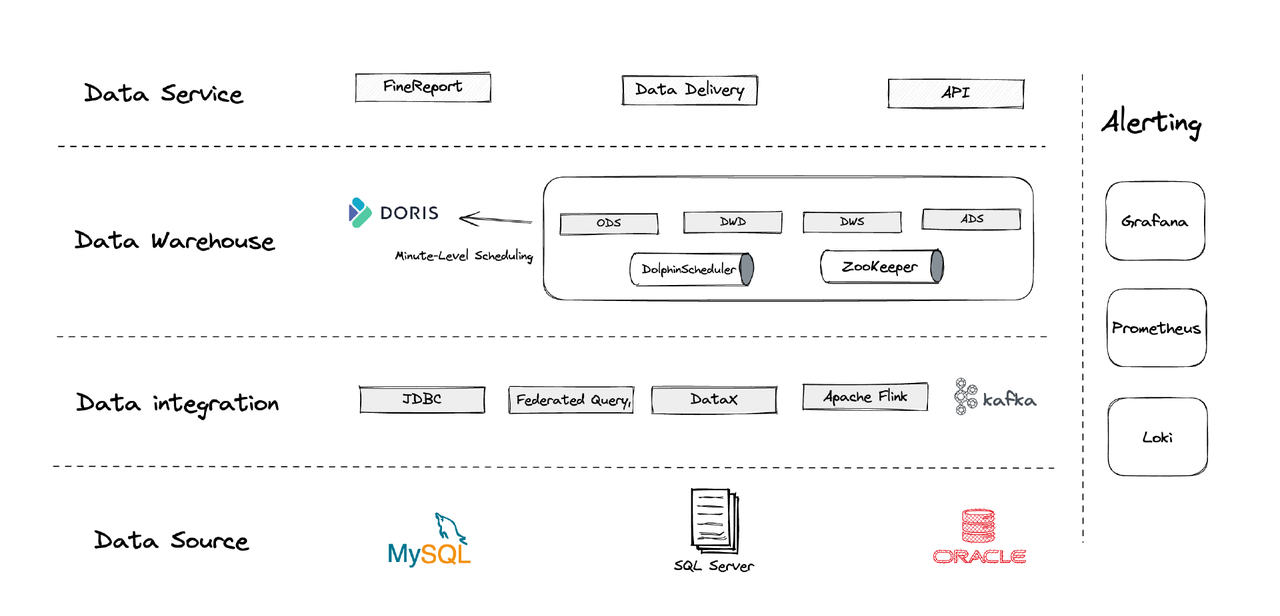
- אינטגרציה נתונים: זה נתמך על ידי Flink CDC, DataX ואת תכונת Multi-Catalog של Apache Doris.
- ניהול נתונים: אנו משתמשים ב-Apache Dolphinscheduler לניהול מחזור חיים של תוכנית, זכותות בניהול רב-שותפים וניטור איכות נתונים.
- אזהרה: אנו משתמשים ב-Grafana, Prometheus ו-Loki לניטור משאבי הרכיבים והיומן.
- שירותי נתונים: כאן כלי BI נכנסים לפעולה להרשמה משתמשים, כגון שאילתת נתונים וניתוח.
1. טבלאות
אנו יוצרים את הטבלאות הממדיות והעובדות שלנו מסביב ליתרון הפעולה בעסקים, כולל לקוחות, בתים וכד'. אם ישנם סדרות פעילויות הקשורות ליתרון הפעולה המשותף, עליהן להירשם על ידי שדה אחד. (זו לקמת למדנו ממערכת הניהול הנתונים הרשומה שלנו.)
2. שכבות
מאגר הנתונים שלנו מחולק לחמשת השכבות המושגיות הללו. אנו משתמשים ב-Apache Doris ו-Apache DolphinScheduler לסדרת DAG תוכנית בין השכבות הללו.

כל יום, השכבות עוברות עדכון כולל חוץ מעדכונים מצעדיים במקרה של שינויים בשדות סטטוס היסטוריים או סינכרון נתונים לא שלמים של טבלאות ODS.
3. אסטרטגיות עדכון מצעדיות
(1) הגדר where >= "זמן פעילות -1 יום או -1 שעה" במקוםwhere >= "זמן הפעילות"
הסיבה לכך היא למנוע הסחף נתונים שנגרם על ידי הפער הזמני של תוכניות הגירסה. נניח, עם פרק זמן ביצוע שנקבע ל-10 דקות, נניח שהתוכנית מבוצעת בשעה 23:58:00 וחתיכת נתונים חדשה מגיעה בשעה 23:59:00. אם נקבע where >= "זמן פעילות", חתיכת הנתונים של היום תחמק.
(2) שלוף את המפתח הראשי הגדול ביותר של הטבלה לפני כל ביצוע תוכנית, שמור את המפתח בטבלה עזר, וקבעwhere >= "מפתח בטבלה עזר"
זהו למנוע שיכפול נתונים. שיכפול נתונים עשוי לקרות אם אתה משתמש במודל מפתח ייחודי של אפטי דוריס ומציין קבוצה של מפתחות ראשיים כיוון שאם יש שינויים במפתחות הראשיים בטבלת המקור, השינויים יתועדו, והנתונים הרלוונטיים יטופלו. השיטה הזו יכולה לתקן זאת, אך היא רק יעילה כאשר לטבלות המקור יש מפתחות ראשיים שמגדילים אוטומטית.
(3) חלק את הטבלאות
כשמדובר בנתונים שמגדילים אוטומטית על פי זמן כמו טבלאות יומנים, יכולים להיות פחות שינויים בנתונים ההיסטוריים ובמצבם, אך נפח הנתונים הוא גדול, ולכן יכול להיות לחץ חישובי עצום על עדכונים כוללים ויצירת משאבה. לכן, עדיף לחלק טבלאות כאלה כך שלכל עדכון מצטבר, נדרשת רק החלפת חלון אחד. (אולי תצטרכו לשים לב גם להסחת דעת נתונים.)
4. אסטרטגיות עדכון כוללות
(1) חיסול טבלה
נקה את הטבלה ולאחר מכן הכנס את כל הנתונים מהטבלה המקורית אליה. זה מתאים עבור טבלאות קטנות ותרחישים שבהם אין פעילות משתמשים בשעות הבוקר.
(2)ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
זו פעולה אטומית, ומומלצת עבור טבלאות גדולות. לפני כל פעם שמבצעים תסריט, יוצרים טבלה זמנית עם אותו תוכנת, מטעינים אליה את כל הנתונים, ומחליפים את הטבלה המקורית בה.
יישום
- עבודת ETL: כל דקה
- התקנה לראשונה: 8 צמתים, 2 חזית, 8 מרכזים, פרוסה מהירה
- תיקון צמתים: 32C * 60GB * 2TB SSD
זו ההתקנה שלנו עבור נתונים ישנים בגודל של טרה-בייטים ונתונים מצטברים בגודל של גיגה-בייטים. אפשר להשתמש בה כמדגם ולהתקנת התקן של Apache Doris. אין צורך ברכיבים נוספים.
1. לשלב נתונים לאון קווי ונתוני יומן, אנו משתמשים ב-DataX, התומך בפורמט CSV ובקוראים של מסדי נתונים רלציונליים רבים, ו-Apache Doris מספק DataX-Doris-Writer.

2. אנו משתמשים ב-Flink CDC כדי לסנכרן נתונים מטבלות המקור. לאחר מכן אנו מצטברים את המדדים הממשיים באמצעות התצוגה המרושת או המודל המצטבר של Apache Doris. מאחר שעלינו לעבד רק חלק מהמדדים בצורה ממשית ואיננו רוצים לייצר מספר רב של קשרי מסד נתונים, אנו משתמשים במשימת Flink אחת לשמירה על מספר רב של טבלות מקור CDC. זה מושג על ידי תכונת המיזוג רב-מקור וסנכרון מלא של מסד נתונים של Dinky, או שאפשר ליישם משימת מיזוג רב-מקור של Flink DataStream בעצמך. �חשוב לציין ש-Flink CDC ו-Apache Doris תומכים בשינויי תבנית.
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. אנו משתמשים בתסריטי SQL או "Shell + SQL" ובכך מנהלים את מחזור החיים של התסריטים. בשכבת ODS, אנו כותבים קובץ משימה DataX כללי ומעבירים פרמטרים לכל טבלת המיזוג של המקור במקום לכתוב משימת DataX לכל טבלת המקור. בדרך זו אנו מקלים על התחזוקה של הדברים. אנו מנהלים את תסריטי ה-ETL של Apache Doris ב-DolphinScheduler, שם גם אנו מבצעים שליטה על גרסאות. במקרה של שגיאות בסביבת הייצור, תמיד אפשר לחזור אחורה.
4. לאחר שמיזוג הנתונים עם תסריטי ETL, אנו יוצרים דף בכלי הדוח שלנו. אנו מקצים זכויות שונות לחשבונות שונים באמצעות SQL, כולל את הזכות לערוך שורות, שדות ומיקרוגלים גלובליים. Apache Doris תומך בשליטה על זכויות של חשבונות, שזהה לזה ב-MySQL.
אנו גם משתמשים בגיבוב נתוני אפטשי Doris לשירותי הפלטה ושיקולית, ביומני אפטשי Doris לבקרת יעילות ביצוע SQL, ב-Grafana+Loki לאזעקות מדדי היעד, וב-Supervisor לבקרת תהליכי הדאמון של רכיבי הצמתים.
אופטימיזציה
הטמעת נתונים
אנו משתמשים ב-DataX לטמון נתונים לונדניים בזרימה. זה מאפשר לנו להתאים את גודל כל דודג'ם. שיטת הטמעת הזרימה מחזירה תוצאות סינכרוניות, מה שעומד בקנה מידה של המבנה שלנו. אם נבצע הטמעה אסינכרונית באמצעות DolphinScheduler, המערכת עשויה להניח שהתסריט נבצע, וזה יכול לגרום לבלגן. אם אתה משתמש בשיטה אחרת, אנו ממליצים לך לבצע show load בתסריט השלל, ולבדוק את סטטוס הסינון הרגיסטרי כדי לראות אם ההטמעה הצליחה.
מודל נתונים
אנו משתמשים במודל Unique Key של אפטשי Doris עבור רוב השולחנות שלנו. מודל Unique Key מבטיח אינדמפוזיציה של תסריטי נתונים ומנפק באופן יעיל את הימנעות משכפול נתונים מעלה.
קריאת נתונים חיצוניים
אנו משתמשים בתכונת Multi-Catalog של אפטשי Doris כדי להתחבר למקורות נתונים חיצוניים. זה מאפשר לנו ליצור מיפויים של נתונים חיצוניים ברמת הקטלוג.
אופטימיזציה שאילתא
אנו מציעים שתשים את השדות הנמצאים בשימוש הכי תדיר של סוגים שאינם דמויי תווים (כגון int ופסי בודקים) ב-36 התבנית הראשונים, כך שתוכל לסנן את השדות אלו תוך מיליוני השנייה בשאילתות נקודתיות.
מילון נתונים
עבורנו, חשוב ליצור מילון נתונים מכיוון שהוא מפחית באופן משמעותי את עלויות התקשורת של הצוותים, מה שיכול להיות בעייתי כשיש לך צוות גדול. אנו משתמשים ב-information_schema ב-Apache Doris כדי ליצור מילון נתונים. עם זה, אנו יכולים להבין במהירות את התמונה הכוללת של הטבלאות והשדות ובכך להגדיל את יעילות הפיתוח.
ביצועים
זמן הטעינה האופציונלית של הנתונים: תוך דקות
זמן ההגעה לשאילתות: עבור טבלאות המכילות יותר מ-100 מיליון שורות, Apache Doris מגיב לשאילתות מיידיות תוך שנייה אחת ולשאילתות מורכבות תוך חמש שניות.
צריכת משאבים: זה דורש מספר קטן של serves כדי לבנות את המאגר הנתונים הזה. יחס הCompresion של 70% של Apache Doris מציל לנו הרבה משאבי אחסון.
חוויה ומסקנות
למעשה, לפני שהתפתחנו לארכיטקטורת הנתונים הנוכחית שלנו, ניסינו לבנות מאגר נתונים אופציונלי באמצעות Hive, Spark, ו-Hadoop. התברר ש-Hadoop היה מוגזם עבור חברה מסוגננת כמונו מאחר שלא היה לנו מספיק נתונים לעבוד איתם. חשוב למצוא את הרכיב שמתאים לך ביותר.
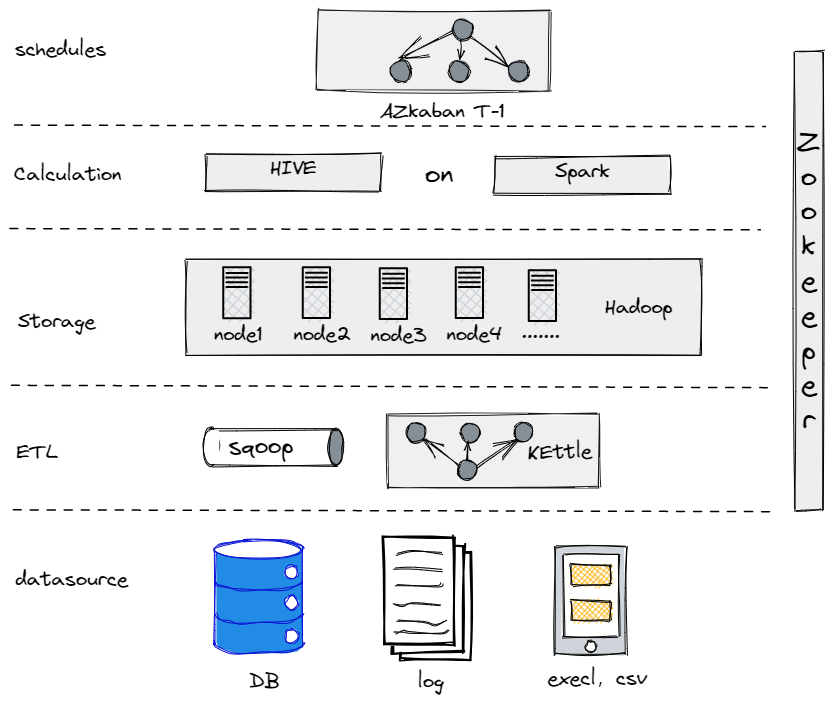
מאגר הנתונים האופציונלי הישן שלנו
מצד שני, כדי ליישר את המעבר לנתונים הגדולים שלנו, עלינו להפוך את פלטפורמת הנתונים שלנו לפשוטה ככל האפשר מבחינת השימוש והתחזוקה. זו הסיבה שהגענו ל-Apache Doris. היא תואמת את פרוטוקול MySQL ומספקת אוסף עשיר של פונקציות, כך שלא נצטרך לפתח UDFs משלנו. כמו כן, היא מורכבת משני סוגים של תהליכים בלבד: קדמיים ואחוריים, ולכן קל להתרחב ולעקוב אחריהם.
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry