













Esto es parte de la transformación digital de un gigante inmobiliario. Por razones de confidencialidad, no revelaré ningún dato comercial, pero obtendrás una visión detallada de nuestro almacén de datos y nuestras estrategias de optimización.
Ahora comencemos.
Arquitectura
Lógicamente, nuestra arquitectura de datos se puede dividir en cuatro partes.
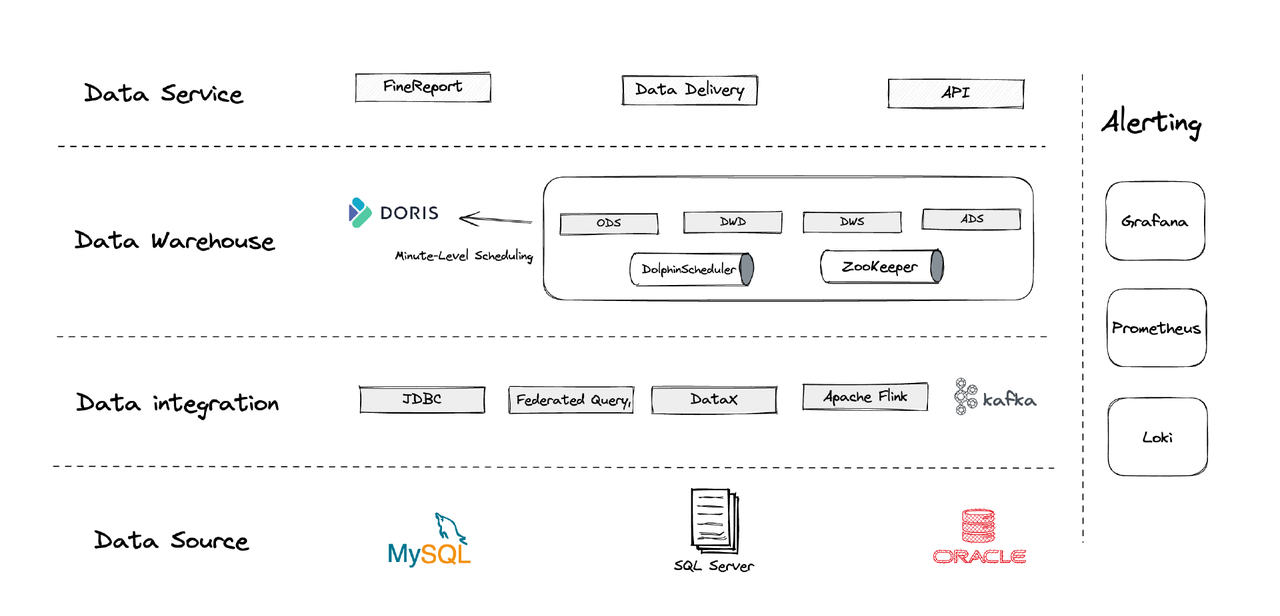
- Integración de datos: Esto está respaldado por Flink CDC, DataX y la función de Multi-Catalog de Apache Doris.
- Gestión de datos: Utilizamos Apache Dolphinscheduler para la gestión del ciclo de vida de los scripts, privilegios en la gestión de multi-inquilinos y monitoreo de calidad de datos.
- Alertas: Utilizamos Grafana, Prometheus y Loki para monitorear los recursos de los componentes y los registros.
- Servicios de datos: Aquí es donde entran en juego las herramientas BI para la interacción del usuario, como consultas y análisis de datos.
1. Tablas
Creamos nuestras tablas de dimensión y tablas de hechos centradas en cada entidad operativa en el negocio, incluidos los clientes, las casas, etc. Si hay una serie de actividades que involucran la misma entidad operativa, deben registrarse por un campo. (Esta es una lección aprendida de nuestro sistema anterior de gestión de datos caótico.)
2. Capas
Nuestro almacén de datos se divide en cinco capas conceptuales. Utilizamos Apache Doris y Apache DolphinScheduler para programar los scripts DAG entre estas capas.

Todos los días, las capas experimentan una actualización general además de actualizaciones incrementales en caso de cambios en los campos de estado históricos o sincronización de datos incompleta de las tablas ODS.
3. Estrategias de Actualización Incremental
(1) Establecer donde >= "tiempo de actividad -1 día o -1 hora" en lugar de donde >= "tiempo de actividad"
La razón para hacerlo es prevenir el deslizamiento de datos causado por la brecha de tiempo en los scripts de programación. Digamos que, con el intervalo de ejecución establecido en 10 minutos, supongamos que el script se ejecuta a las 23:58:00 y un nuevo dato llega a las 23:59:00. Si establecemos donde >= "tiempo de actividad", ese dato del día se perderá.
(2) Obtener el ID de la clave primaria más grande de la tabla antes de cada ejecución del script, almacenar el ID en la tabla auxiliar y establecer donde >= "ID en tabla auxiliar"
Esto es para evitar la duplicación de datos. La duplicación de datos podría ocurrir si se utiliza el modelo de Clave Única de Apache Doris y se designa un conjunto de claves primarias porque si hay cambios en las claves primarias en la tabla de origen, los cambios se registrarán y los datos relevantes se cargarán. Este método puede solucionarlo, pero solo es aplicable cuando las tablas de origen tienen claves primarias de autoincremento.
(3) Particionar las tablas
En cuanto a datos de autoincremento basados en el tiempo, como las tablas de registro, podrían haber menos cambios en los datos y el estado históricos, pero el volumen de datos es grande, por lo que podría haber una gran presión computacional en las actualizaciones globales y la creación de instantáneas. Por lo tanto, es mejor particionar estas tablas para que, con cada actualización incremental, solo necesitemos reemplazar una partición. (También es posible que debas tener cuidado con el deslizamiento de datos).
4. Estrategias de Actualización Global
(1) Truncar Tabla
Eliminar el contenido de la tabla y luego ingerir todos los datos desde la tabla fuente hacia ella. Esto es aplicable para tablas pequeñas y escenarios sin actividad de usuarios en las horas tempranas de la madrugada.
(2) ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
Esta es una operación atómica, y es recomendable para tablas grandes. Antes de ejecutar un script, creamos una tabla temporal con el mismo esquema, cargamos todos los datos en ella y reemplazamos la tabla original con ella.
Aplicación
- Trabajo ETL: cada minuto
- Configuración para despliegue inicial: 8 nodos, 2 frontales, 8 traseros, despliegue híbrido
- Configuración del nodo: 32C * 60GB * 2TB SSD
Esta es nuestra configuración para terabytes de datos legados y gigabytes de datos incrementales. Puedes usarlo como referencia y escalar tu clúster en base a esto. El despliegue de Apache Doris es simple. No necesitas otros componentes.
1. Para integrar datos offline y datos de registro, utilizamos DataX, que es compatible con el formato CSV y lectores de muchas bases de datos relacionales, y Apache Doris proporciona un DataX-Doris-Writer.

2. Utilizamos Flink CDC para sincronizar datos desde las tablas de origen. Luego, agregamos las métricas en tiempo real utilizando la Vista Materializada o el Modelo Agregado de Apache Doris. Dado que solo debemos procesar parte de las métricas de manera en tiempo real y no queremos generar demasiadas conexiones de base de datos, utilizamos un trabajo de Flink para mantener múltiples tablas de origen CDC. Esto se logra mediante las características de fusión de múltiples fuentes y sincronización completa de la base de datos de Dinky, o puede implementar una tarea de fusión de múltiples fuentes de Flink DataStream usted mismo. Vale la pena mencionar que Flink CDC y Apache Doris admiten Cambio de Esquema.
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. Utilizamos scripts SQL o “Shell + SQL” y realizamos la gestión del ciclo de vida de los scripts. En la capa ODS, escribimos un archivo de trabajo de DataX genérico y pasamos parámetros para cada ingesta de tabla de origen en lugar de escribir un trabajo de DataX para cada tabla de origen. De esta manera, facilitamos mucho la mantenibilidad. Gestionamos los scripts ETL de Apache Doris en DolphinScheduler, donde también realizamos control de versiones. En caso de errores en el entorno de producción, siempre podemos revertir.
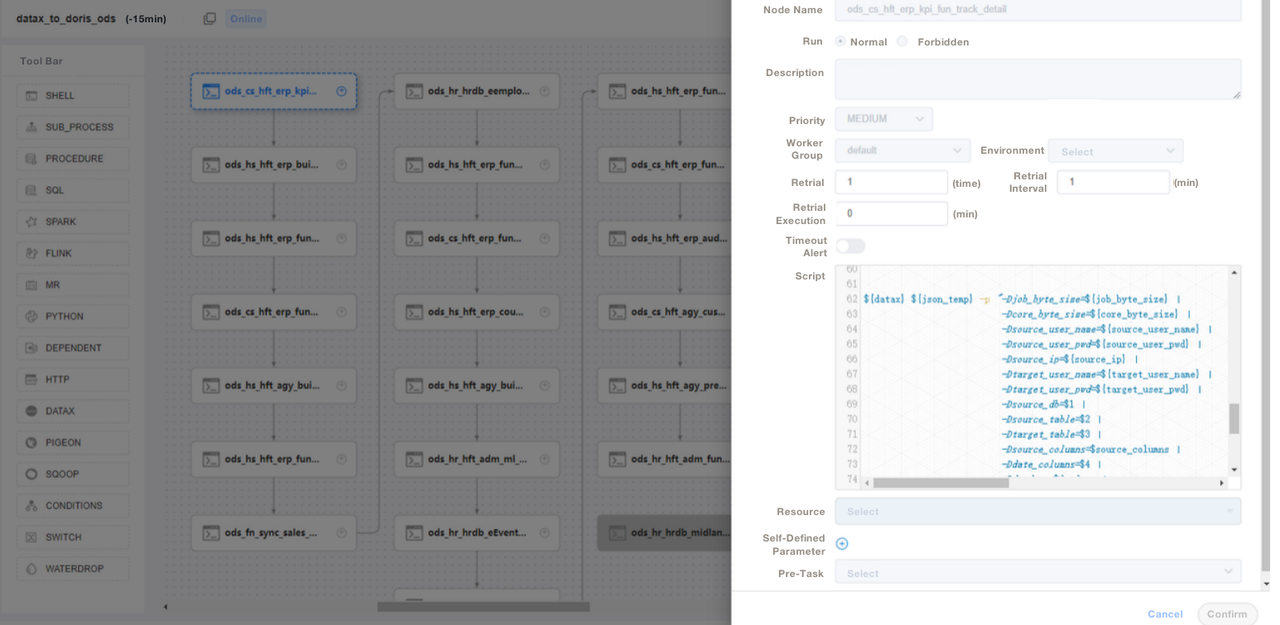
4. Después de ingerir datos con scripts ETL, creamos una página en nuestra herramienta de informes. Asignamos diferentes privilegios a diferentes cuentas utilizando SQL, incluidos los privilegios de modificar filas, campos y diccionarios globales. Apache Doris admite el control de privilegios sobre cuentas, que funciona de la misma manera que en MySQL.
También utilizamos la copia de seguridad de datos de Apache Doris para la recuperación ante desastres, los registros de auditoría de Apache Doris para monitorear la eficiencia de ejecución de SQL, Grafana+Loki para alertas de métricas de clúster, y Supervisor para monitorear los procesos demonio de los componentes de nodo.
Optimización
Ingestión de Datos
Utilizamos DataX para cargar datos offline en flujo. Nos permite ajustar el tamaño de cada lote. El método de carga en flujo devuelve resultados de manera sincrónica, lo que satisface las necesidades de nuestra arquitectura. Si ejecutamos la importación de datos asíncrona utilizando DolphinScheduler, el sistema podría asumir que el script ha sido ejecutado, lo que podría causar confusión. Si utilizas un método diferente, recomendamos que ejecutes show load en el script de shell, y verifiques el estado de filtrado de regex para ver si la ingesta tiene éxito.
Modelo de Datos
Adoptamos el modelo de Clave Única de Apache Doris para la mayoría de nuestras tablas. El modelo de Clave Única garantiza la idempotencia de los scripts de datos y evita eficazmente la duplicación de datos en la parte superior.
Lectura de Datos Externos
Utilizamos la función de Multi-Catalog de Apache Doris para conectarnos a fuentes de datos externas. Nos permite crear mapeos de datos externos a nivel de Catalog.
Optimización de Consultas
Sugerimos que coloques los campos de tipos no caracteres (como int y cláusulas where) más utilizados en los primeros 36 bytes, para que puedas filtrar estos campos en milisegundos en consultas puntuales.
Diccionari
Para nosotros, es fundamental crear un diccionario de datos ya que reduce en gran medida los costos de comunicación entre el personal, lo cual puede ser un dolor de cabeza cuando se tiene un equipo grande. Utilizamos el information_schema en Apache Doris para generar un diccionario de datos. Con él, podemos comprender rápidamente la estructura general de las tablas y los campos, lo que aumenta la eficiencia del desarrollo.
Rendimiento
Tiempo de ingesta de datos fuera de línea: En minutos
Latencia de consulta: Para tablas con más de 100 millones de filas, Apache Doris responde a consultas ad-hoc en un segundo y a consultas complejas en cinco segundos.
Consumo de recursos: Solo se necesita un pequeño número de servidores para construir este almacén de datos. La tasa de compresión del 70% de Apache Doris nos ahorra muchos recursos de almacenamiento.
Experiencia y Conclusión
De hecho, antes de evolucionar a nuestra actual arquitectura de datos, probamos Hive, Spark y Hadoop para construir un almacén de datos fuera de línea. Resultó que Hadoop era excesivo para una empresa tradicional como la nuestra, ya que no teníamos demasiados datos para procesar. Es crucial encontrar el componente que mejor se adapte a tus necesidades.
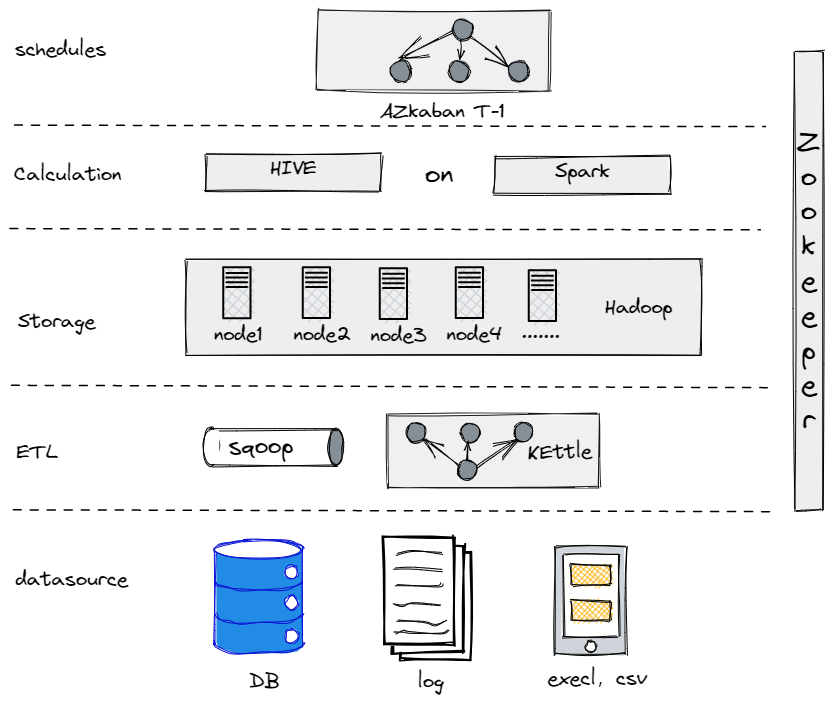
Nuestro Antiguo Almacén de Datos Fuera de Línea
Por otro lado, para facilitar nuestra transición a big data, necesitamos que nuestra plataforma de datos sea lo más sencilla posible en términos de uso y mantenimiento. Por eso optamos por Apache Doris. Es compatible con el protocolo MySQL y ofrece una amplia gama de funciones, por lo que no tenemos que desarrollar nuestras propias UDFs. Además, está compuesta solo por dos tipos de procesos: frontales y traseros, lo que facilita su escalabilidad y seguimiento.
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry